 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Neuro-Inspired Hierarchical Multimodal Learning
Sep 27, 2023
Integrating and processing information from various sources or modalities are critical for obtaining a comprehensive and accurate perception of the real world. Drawing inspiration from neuroscience, we develop the Information-Theoretic Hierarchical Perception (ITHP) model, which utilizes the concept of information bottleneck. Distinct from most traditional fusion models that aim to incorporate all modalities as input, our model designates the prime modality as input, while the remaining modalities act as detectors in the information pathway. Our proposed perception model focuses on constructing an effective and compact information flow by achieving a balance between the minimization of mutual information between the latent state and the input modal state, and the maximization of mutual information between the latent states and the remaining modal states. This approach leads to compact latent state representations that retain relevant information while minimizing redundancy, thereby substantially enhancing the performance of downstream tasks. Experimental evaluations on both the MUStARD and CMU-MOSI datasets demonstrate that our model consistently distills crucial information in multimodal learning scenarios, outperforming state-of-the-art benchmarks.
Enhanced Graph Neural Networks with Ego-Centric Spectral Subgraph Embeddings Augmentation
Oct 10, 2023Graph Neural Networks (GNNs) have shown remarkable merit in performing various learning-based tasks in complex networks. The superior performance of GNNs often correlates with the availability and quality of node-level features in the input networks. However, for many network applications, such node-level information may be missing or unreliable, thereby limiting the applicability and efficacy of GNNs. To address this limitation, we present a novel approach denoted as Ego-centric Spectral subGraph Embedding Augmentation (ESGEA), which aims to enhance and design node features, particularly in scenarios where information is lacking. Our method leverages the topological structure of the local subgraph to create topology-aware node features. The subgraph features are generated using an efficient spectral graph embedding technique, and they serve as node features that capture the local topological organization of the network. The explicit node features, if present, are then enhanced with the subgraph embeddings in order to improve the overall performance. ESGEA is compatible with any GNN-based architecture and is effective even in the absence of node features. We evaluate the proposed method in a social network graph classification task where node attributes are unavailable, as well as in a node classification task where node features are corrupted or even absent. The evaluation results on seven datasets and eight baseline models indicate up to a 10% improvement in AUC and a 7% improvement in accuracy for graph and node classification tasks, respectively.
A Multi-Perspective Learning to Rank Approach to Support Children's Information Seeking in the Classroom
Aug 29, 2023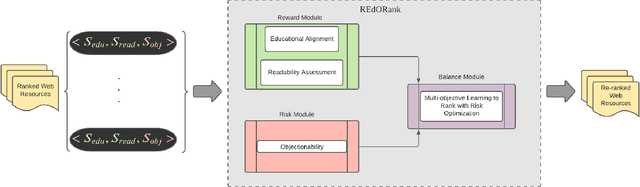
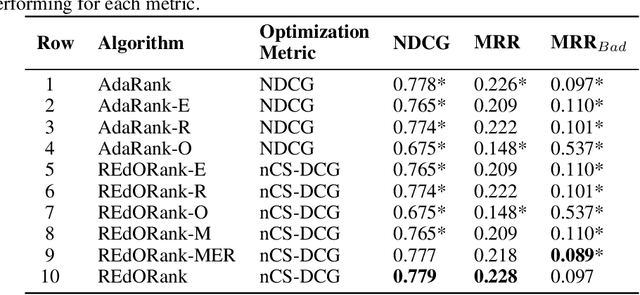
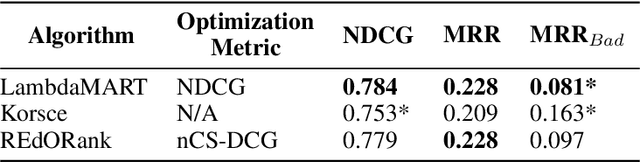
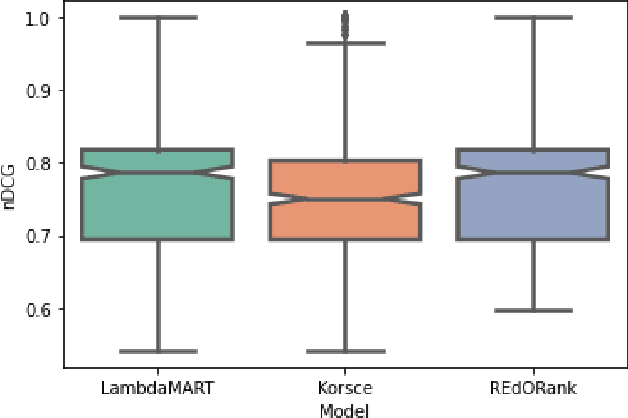
We introduce a novel re-ranking model that aims to augment the functionality of standard search engines to support classroom search activities for children (ages 6 to 11). This model extends the known listwise learning-to-rank framework by balancing risk and reward. Doing so enables the model to prioritize Web resources of high educational alignment, appropriateness, and adequate readability by analyzing the URLs, snippets, and page titles of Web resources retrieved by a given mainstream search engine. Experimental results, including an ablation study and comparisons with existing baselines, showcase the correctness of the proposed model. The outcomes of this work demonstrate the value of considering multiple perspectives inherent to the classroom setting, e.g., educational alignment, readability, and objectionability, when applied to the design of algorithms that can better support children's information discovery.
Lattice real-time simulations with learned optimal kernels
Oct 12, 2023We present a simulation strategy for the real-time dynamics of quantum fields, inspired by reinforcement learning. It builds on the complex Langevin approach, which it amends with system specific prior information, a necessary prerequisite to overcome this exceptionally severe sign problem. The optimization process underlying our machine learning approach is made possible by deploying inherently stable solvers of the complex Langevin stochastic process and a novel optimality criterion derived from insight into so-called boundary terms. This conceptual and technical progress allows us to both significantly extend the range of real-time simulations in 1+1d scalar field theory beyond the state-of-the-art and to avoid discretization artifacts that plagued previous real-time field theory simulations. Limitations of and promising future directions are discussed.
UniTime: A Language-Empowered Unified Model for Cross-Domain Time Series Forecasting
Oct 15, 2023
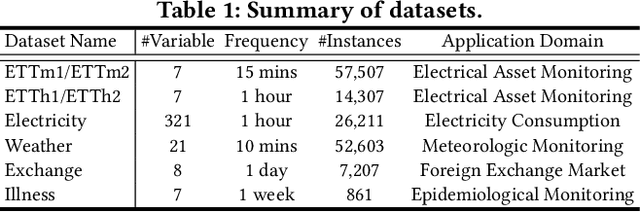
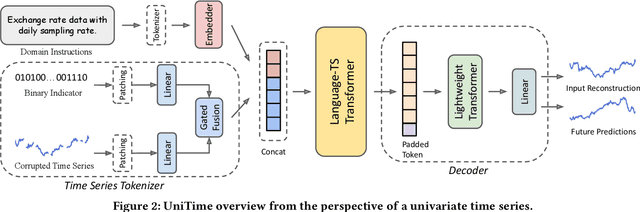
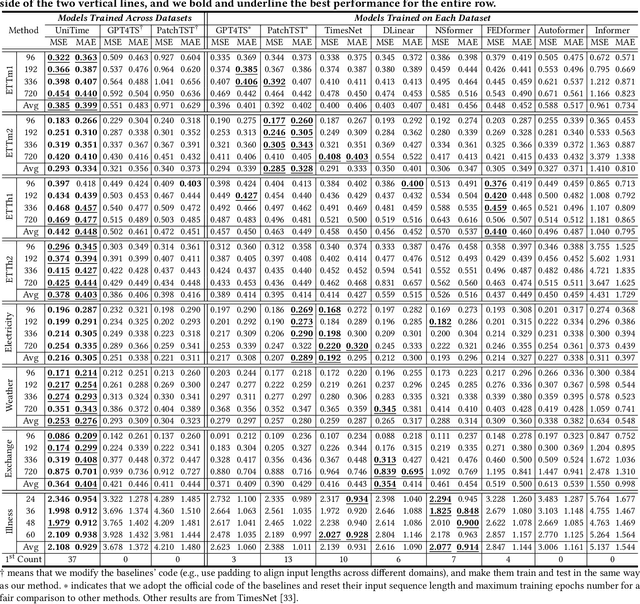
Multivariate time series forecasting plays a pivotal role in contemporary web technologies. In contrast to conventional methods that involve creating dedicated models for specific time series application domains, this research advocates for a unified model paradigm that transcends domain boundaries. However, learning an effective cross-domain model presents the following challenges. First, various domains exhibit disparities in data characteristics, e.g., the number of variables, posing hurdles for existing models that impose inflexible constraints on these factors. Second, the model may encounter difficulties in distinguishing data from various domains, leading to suboptimal performance in our assessments. Third, the diverse convergence rates of time series domains can also result in compromised empirical performance. To address these issues, we propose UniTime for effective cross-domain time series learning. Concretely, UniTime can flexibly adapt to data with varying characteristics. It also uses domain instructions and a Language-TS Transformer to offer identification information and align two modalities. In addition, UniTime employs masking to alleviate domain convergence speed imbalance issues. Our extensive experiments demonstrate the effectiveness of UniTime in advancing state-of-the-art forecasting performance and zero-shot transferability.
Probabilistically Rewired Message-Passing Neural Networks
Oct 15, 2023Message-passing graph neural networks (MPNNs) emerged as powerful tools for processing graph-structured input. However, they operate on a fixed input graph structure, ignoring potential noise and missing information. Furthermore, their local aggregation mechanism can lead to problems such as over-squashing and limited expressive power in capturing relevant graph structures. Existing solutions to these challenges have primarily relied on heuristic methods, often disregarding the underlying data distribution. Hence, devising principled approaches for learning to infer graph structures relevant to the given prediction task remains an open challenge. In this work, leveraging recent progress in exact and differentiable $k$-subset sampling, we devise probabilistically rewired MPNNs (PR-MPNNs), which learn to add relevant edges while omitting less beneficial ones. For the first time, our theoretical analysis explores how PR-MPNNs enhance expressive power, and we identify precise conditions under which they outperform purely randomized approaches. Empirically, we demonstrate that our approach effectively mitigates issues like over-squashing and under-reaching. In addition, on established real-world datasets, our method exhibits competitive or superior predictive performance compared to traditional MPNN models and recent graph transformer architectures.
A generalization of the achievable rate of a MISO system using Bode-Fano wideband matching theory
Oct 15, 2023Impedance-matching networks affect power transfer from the radio frequency (RF) chains to the antennas. Their design impacts the signal to noise ratio (SNR) and the achievable rate. In this paper, we maximize the information-theoretic achievable rate of a multiple-input-single-output (MISO) system with wideband matching constraints. Using a multiport circuit theory approach with frequency-selective scattering parameters, we propose a general framework for optimizing the MISO achievable rate that incorporates Bode-Fano wideband matching theory. We express the solution to the achievable rate optimization problem in terms of the optimized transmission coefficient and the Lagrangian parameters corresponding to the Bode-Fano inequality constraints. We apply this framework to a single electric Chu's antenna and an array of two electric Chu's antennas. We compare the optimized achievable rate obtained numerically with other benchmarks like the ideal achievable rate computed by disregarding matching constraints and the achievable rate obtained by using sub-optimal matching strategies like conjugate matching and frequency-flat transmission. We also propose a practical methodology to approximate the achievable rate bound by using the optimal transmission coefficient to derive a physically realizable matching network through the ADS software.
MoEmo Vision Transformer: Integrating Cross-Attention and Movement Vectors in 3D Pose Estimation for HRI Emotion Detection
Oct 15, 2023Emotion detection presents challenges to intelligent human-robot interaction (HRI). Foundational deep learning techniques used in emotion detection are limited by information-constrained datasets or models that lack the necessary complexity to learn interactions between input data elements, such as the the variance of human emotions across different contexts. In the current effort, we introduce 1) MoEmo (Motion to Emotion), a cross-attention vision transformer (ViT) for human emotion detection within robotics systems based on 3D human pose estimations across various contexts, and 2) a data set that offers full-body videos of human movement and corresponding emotion labels based on human gestures and environmental contexts. Compared to existing approaches, our method effectively leverages the subtle connections between movement vectors of gestures and environmental contexts through the use of cross-attention on the extracted movement vectors of full-body human gestures/poses and feature maps of environmental contexts. We implement a cross-attention fusion model to combine movement vectors and environment contexts into a joint representation to derive emotion estimation. Leveraging our Naturalistic Motion Database, we train the MoEmo system to jointly analyze motion and context, yielding emotion detection that outperforms the current state-of-the-art.
* IEEE/RSJ International Conference on Intelligent Robots (IROS), Detroit, Michigan
Integrated Communication, Sensing, and Computation Framework for 6G Networks
Oct 05, 2023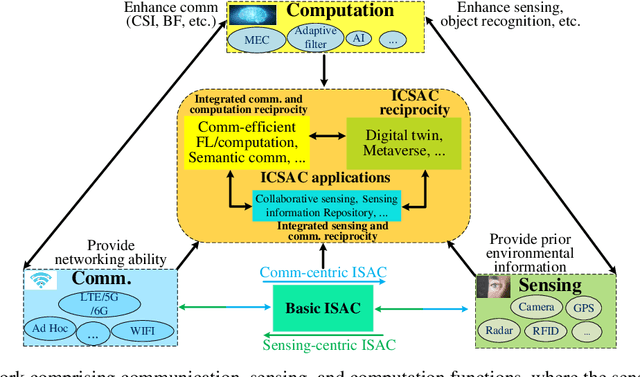
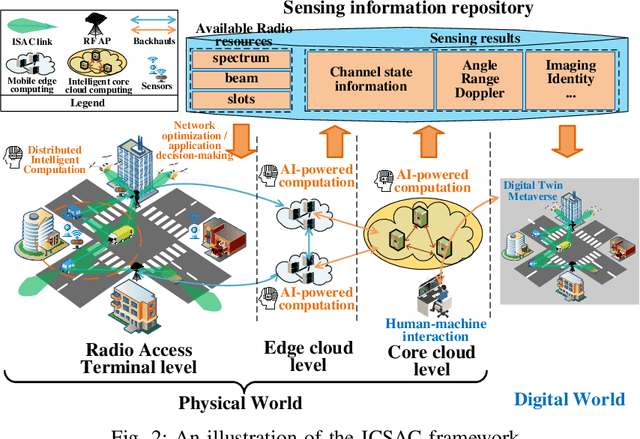
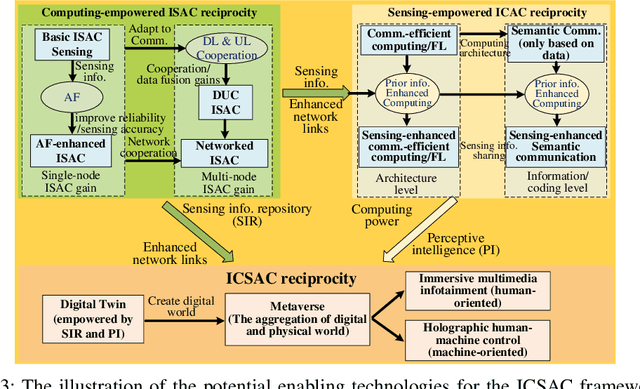
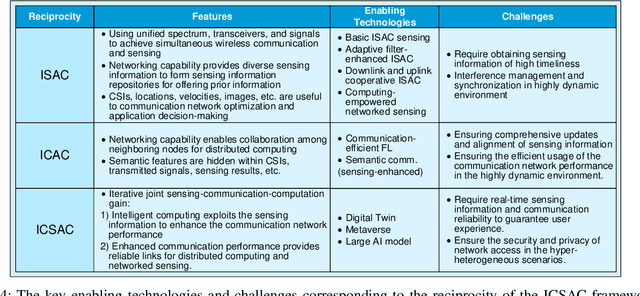
In the sixth generation (6G) era, intelligent machine network (IMN) applications, such as intelligent transportation, require collaborative machines with communication, sensing, and computation (CSC) capabilities. This article proposes an integrated communication, sensing, and computation (ICSAC) framework for 6G to achieve the reciprocity among CSC functions to enhance the reliability and latency of communication, accuracy and timeliness of sensing information acquisition, and privacy and security of computing to realize the IMN applications. Specifically, the sensing and communication functions can merge into unified platforms using the same transmit signals, and the acquired real-time sensing information can be exploited as prior information for intelligent algorithms to enhance the performance of communication networks. This is called the computing-empowered integrated sensing and communications (ISAC) reciprocity. Such reciprocity can further improve the performance of distributed computation with the assistance of networked sensing capability, which is named the sensing-empowered integrated communications and computation (ICAC) reciprocity. The above ISAC and ICAC reciprocities can enhance each other iteratively and finally lead to the ICSAC reciprocity. To achieve these reciprocities, we explore the potential enabling technologies for the ICSAC framework. Finally, we present the evaluation results of crucial enabling technologies to show the feasibility of the ICSAC framework.
A Branched Deep Convolutional Network for Forecasting the Occurrence of Hazes in Paris using Meteorological Maps with Different Characteristic Spatial Scales
Oct 11, 2023A deep learning platform has been developed to forecast the occurrence of the low visibility events or hazes. It is trained by using multi-decadal daily regional maps of various meteorological and hydrological variables as input features and surface visibility observations as the targets. To better preserve the characteristic spatial information of different input features for training, two branched architectures have recently been developed for the case of Paris hazes. These new architectures have improved the performance of the network, producing reasonable scores in both validation and a blind forecasting evaluation using the data of 2021 and 2022 that have not been used in the training and validation.