 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MedSyn: Text-guided Anatomy-aware Synthesis of High-Fidelity 3D CT Images
Oct 16, 2023
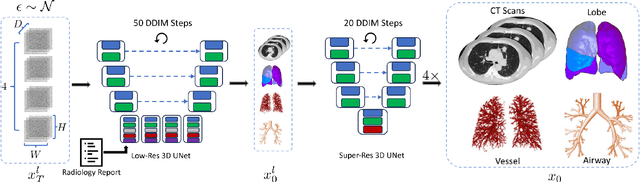
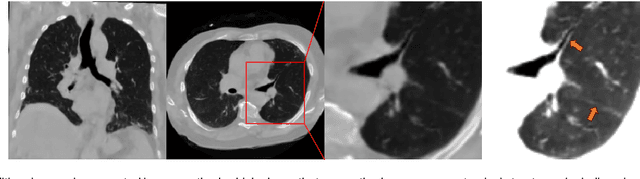
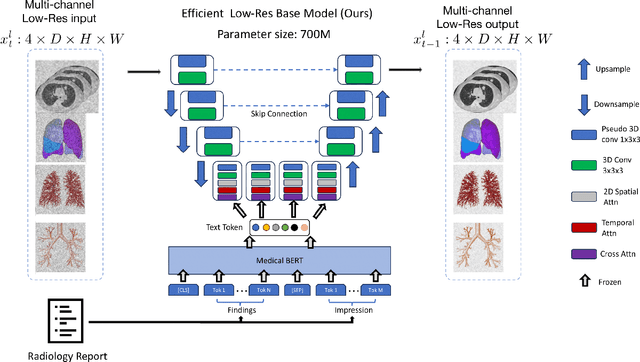
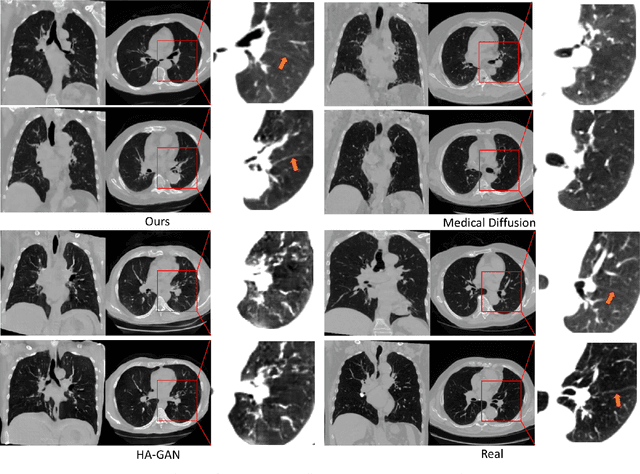
This paper introduces an innovative methodology for producing high-quality 3D lung CT images guided by textual information. While diffusion-based generative models are increasingly used in medical imaging, current state-of-the-art approaches are limited to low-resolution outputs and underutilize radiology reports' abundant information. The radiology reports can enhance the generation process by providing additional guidance and offering fine-grained control over the synthesis of images. Nevertheless, expanding text-guided generation to high-resolution 3D images poses significant memory and anatomical detail-preserving challenges. Addressing the memory issue, we introduce a hierarchical scheme that uses a modified UNet architecture. We start by synthesizing low-resolution images conditioned on the text, serving as a foundation for subsequent generators for complete volumetric data. To ensure the anatomical plausibility of the generated samples, we provide further guidance by generating vascular, airway, and lobular segmentation masks in conjunction with the CT images. The model demonstrates the capability to use textual input and segmentation tasks to generate synthesized images. The results of comparative assessments indicate that our approach exhibits superior performance compared to the most advanced models based on GAN and diffusion techniques, especially in accurately retaining crucial anatomical features such as fissure lines, airways, and vascular structures. This innovation introduces novel possibilities. This study focuses on two main objectives: (1) the development of a method for creating images based on textual prompts and anatomical components, and (2) the capability to generate new images conditioning on anatomical elements. The advancements in image generation can be applied to enhance numerous downstream tasks.
Key-phrase boosted unsupervised summary generation for FinTech organization
Oct 16, 2023With the recent advances in social media, the use of NLP techniques in social media data analysis has become an emerging research direction. Business organizations can particularly benefit from such an analysis of social media discourse, providing an external perspective on consumer behavior. Some of the NLP applications such as intent detection, sentiment classification, text summarization can help FinTech organizations to utilize the social media language data to find useful external insights and can be further utilized for downstream NLP tasks. Particularly, a summary which highlights the intents and sentiments of the users can be very useful for these organizations to get an external perspective. This external perspective can help organizations to better manage their products, offers, promotional campaigns, etc. However, certain challenges, such as a lack of labeled domain-specific datasets impede further exploration of these tasks in the FinTech domain. To overcome these challenges, we design an unsupervised phrase-based summary generation from social media data, using 'Action-Object' pairs (intent phrases). We evaluated the proposed method with other key-phrase based summary generation methods in the direction of contextual information of various Reddit discussion threads, available in the different summaries. We introduce certain "Context Metrics" such as the number of Unique words, Action-Object pairs, and Noun chunks to evaluate the contextual information retrieved from the source text in these phrase-based summaries. We demonstrate that our methods significantly outperform the baseline on these metrics, thus providing a qualitative and quantitative measure of their efficacy. Proposed framework has been leveraged as a web utility portal hosted within Amex.
Looping LOCI: Developing Object Permanence from Videos
Oct 16, 2023Recent compositional scene representation learning models have become remarkably good in segmenting and tracking distinct objects within visual scenes. Yet, many of these models require that objects are continuously, at least partially, visible. Moreover, they tend to fail on intuitive physics tests, which infants learn to solve over the first months of their life. Our goal is to advance compositional scene representation algorithms with an embedded algorithm that fosters the progressive learning of intuitive physics, akin to infant development. As a fundamental component for such an algorithm, we introduce Loci-Looped, which advances a recently published unsupervised object location, identification, and tracking neural network architecture (Loci, Traub et al., ICLR 2023) with an internal processing loop. The loop is designed to adaptively blend pixel-space information with anticipations yielding information-fused activities as percepts. Moreover, it is designed to learn compositional representations of both individual object dynamics and between-objects interaction dynamics. We show that Loci-Looped learns to track objects through extended periods of object occlusions, indeed simulating their hidden trajectories and anticipating their reappearance, without the need for an explicit history buffer. We even find that Loci-Looped surpasses state-of-the-art models on the ADEPT and the CLEVRER dataset, when confronted with object occlusions or temporary sensory data interruptions. This indicates that Loci-Looped is able to learn the physical concepts of object permanence and inertia in a fully unsupervised emergent manner. We believe that even further architectural advancements of the internal loop - also in other compositional scene representation learning models - can be developed in the near future.
Geom-Erasing: Geometry-Driven Removal of Implicit Concept in Diffusion Models
Oct 13, 2023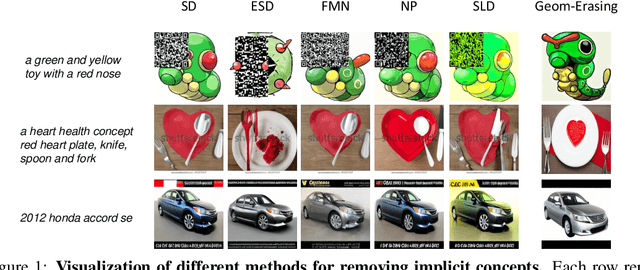

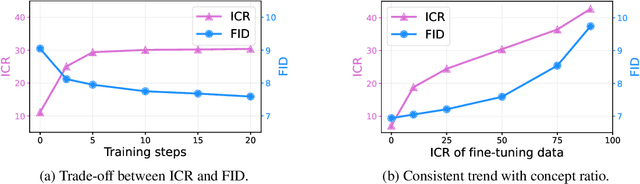
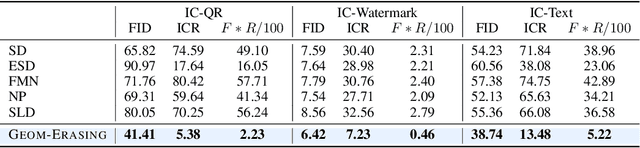
Fine-tuning diffusion models through personalized datasets is an acknowledged method for improving generation quality across downstream tasks, which, however, often inadvertently generates unintended concepts such as watermarks and QR codes, attributed to the limitations in image sources and collecting methods within specific downstream tasks. Existing solutions suffer from eliminating these unintentionally learned implicit concepts, primarily due to the dependency on the model's ability to recognize concepts that it actually cannot discern. In this work, we introduce Geom-Erasing, a novel approach that successfully removes the implicit concepts with either an additional accessible classifier or detector model to encode geometric information of these concepts into text domain. Moreover, we propose Implicit Concept, a novel image-text dataset imbued with three implicit concepts (i.e., watermarks, QR codes, and text) for training and evaluation. Experimental results demonstrate that Geom-Erasing not only identifies but also proficiently eradicates implicit concepts, revealing a significant improvement over the existing methods. The integration of geometric information marks a substantial progression in the precise removal of implicit concepts in diffusion models.
UniParser: Multi-Human Parsing with Unified Correlation Representation Learning
Oct 13, 2023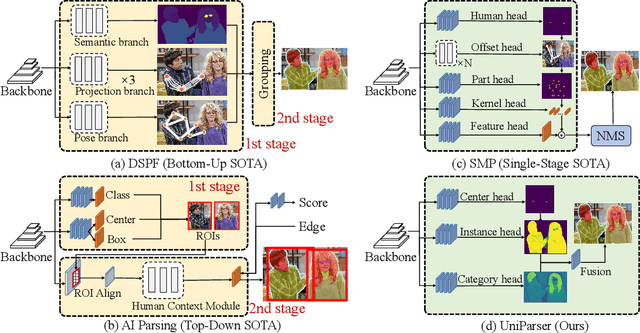
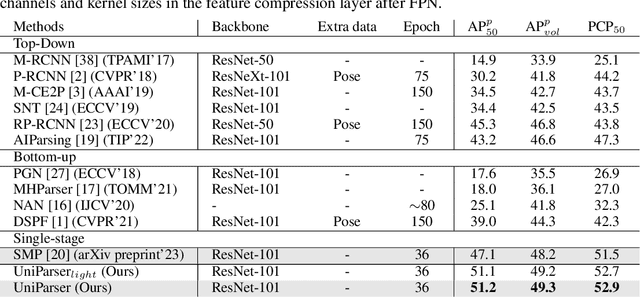
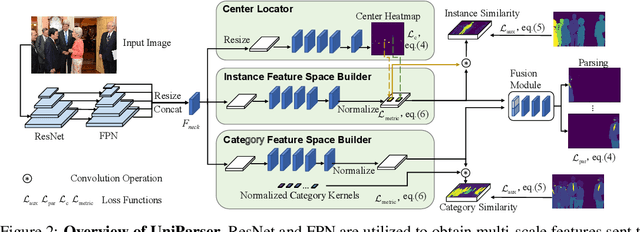
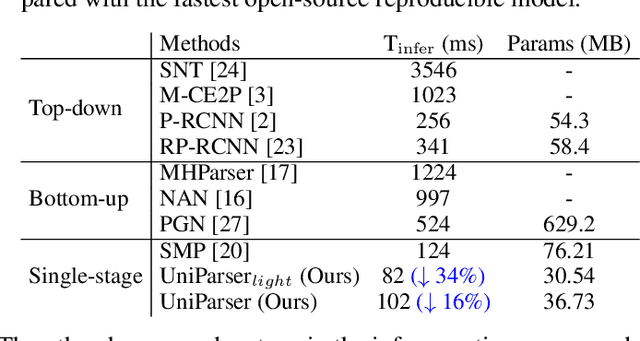
Multi-human parsing is an image segmentation task necessitating both instance-level and fine-grained category-level information. However, prior research has typically processed these two types of information through separate branches and distinct output formats, leading to inefficient and redundant frameworks. This paper introduces UniParser, which integrates instance-level and category-level representations in three key aspects: 1) we propose a unified correlation representation learning approach, allowing our network to learn instance and category features within the cosine space; 2) we unify the form of outputs of each modules as pixel-level segmentation results while supervising instance and category features using a homogeneous label accompanied by an auxiliary loss; and 3) we design a joint optimization procedure to fuse instance and category representations. By virtual of unifying instance-level and category-level output, UniParser circumvents manually designed post-processing techniques and surpasses state-of-the-art methods, achieving 49.3% AP on MHPv2.0 and 60.4% AP on CIHP. We will release our source code, pretrained models, and online demos to facilitate future studies.
Image Compression using only Attention based Neural Networks
Oct 17, 2023In recent research, Learned Image Compression has gained prominence for its capacity to outperform traditional handcrafted pipelines, especially at low bit-rates. While existing methods incorporate convolutional priors with occasional attention blocks to address long-range dependencies, recent advances in computer vision advocate for a transformative shift towards fully transformer-based architectures grounded in the attention mechanism. This paper investigates the feasibility of image compression exclusively using attention layers within our novel model, QPressFormer. We introduce the concept of learned image queries to aggregate patch information via cross-attention, followed by quantization and coding techniques. Through extensive evaluations, our work demonstrates competitive performance achieved by convolution-free architectures across the popular Kodak, DIV2K, and CLIC datasets.
Leveraging Hierarchical Feature Sharing for Efficient Dataset Condensation
Oct 11, 2023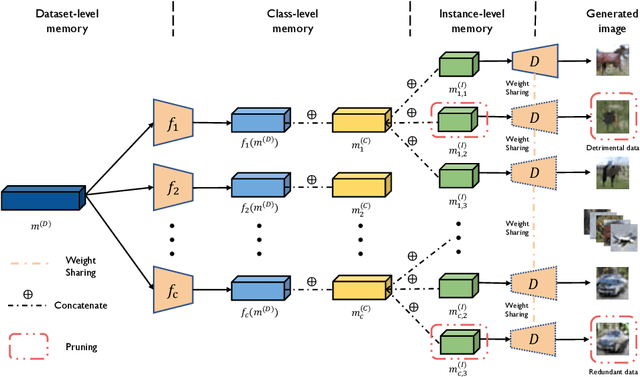
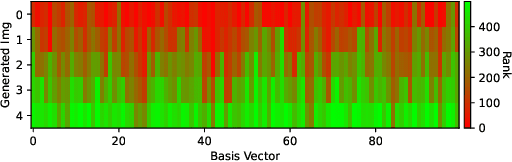
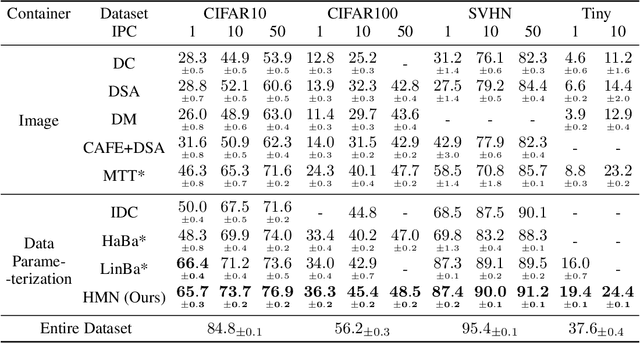
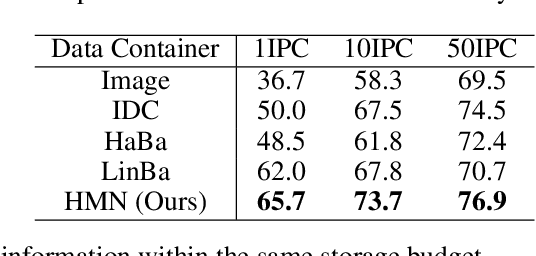
Given a real-world dataset, data condensation (DC) aims to synthesize a significantly smaller dataset that captures the knowledge of this dataset for model training with high performance. Recent works propose to enhance DC with data parameterization, which condenses data into parameterized data containers rather than pixel space. The intuition behind data parameterization is to encode shared features of images to avoid additional storage costs. In this paper, we recognize that images share common features in a hierarchical way due to the inherent hierarchical structure of the classification system, which is overlooked by current data parameterization methods. To better align DC with this hierarchical nature and encourage more efficient information sharing inside data containers, we propose a novel data parameterization architecture, Hierarchical Memory Network (HMN). HMN stores condensed data in a three-tier structure, representing the dataset-level, class-level, and instance-level features. Another helpful property of the hierarchical architecture is that HMN naturally ensures good independence among images despite achieving information sharing. This enables instance-level pruning for HMN to reduce redundant information, thereby further minimizing redundancy and enhancing performance. We evaluate HMN on four public datasets (SVHN, CIFAR10, CIFAR100, and Tiny-ImageNet) and compare HMN with eight DC baselines. The evaluation results show that our proposed method outperforms all baselines, even when trained with a batch-based loss consuming less GPU memory.
A Survey on Quantum Machine Learning: Current Trends, Challenges, Opportunities, and the Road Ahead
Oct 16, 2023Quantum Computing (QC) claims to improve the efficiency of solving complex problems, compared to classical computing. When QC is applied to Machine Learning (ML) applications, it forms a Quantum Machine Learning (QML) system. After discussing the basic concepts of QC and its advantages over classical computing, this paper reviews the key aspects of QML in a comprehensive manner. We discuss different QML algorithms and their domain applicability, quantum datasets, hardware technologies, software tools, simulators, and applications. In this survey, we provide valuable information and resources for readers to jumpstart into the current state-of-the-art techniques in the QML field.
CARLG: Leveraging Contextual Clues and Role Correlations for Improving Document-level Event Argument Extraction
Oct 08, 2023
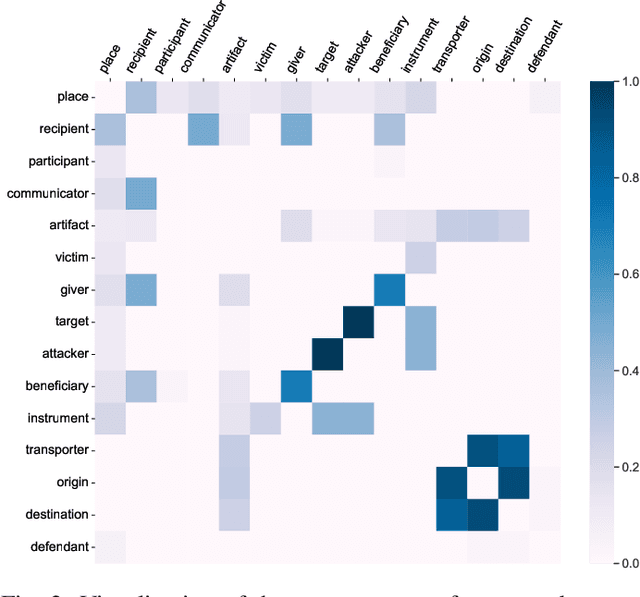
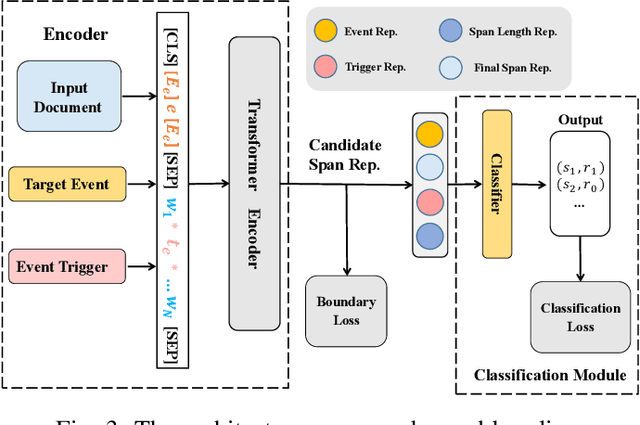
Document-level event argument extraction (EAE) is a crucial but challenging subtask in information extraction. Most existing approaches focus on the interaction between arguments and event triggers, ignoring two critical points: the information of contextual clues and the semantic correlations among argument roles. In this paper, we propose the CARLG model, which consists of two modules: Contextual Clues Aggregation (CCA) and Role-based Latent Information Guidance (RLIG), effectively leveraging contextual clues and role correlations for improving document-level EAE. The CCA module adaptively captures and integrates contextual clues by utilizing context attention weights from a pre-trained encoder. The RLIG module captures semantic correlations through role-interactive encoding and provides valuable information guidance with latent role representation. Notably, our CCA and RLIG modules are compact, transplantable and efficient, which introduce no more than 1% new parameters and can be easily equipped on other span-base methods with significant performance boost. Extensive experiments on the RAMS, WikiEvents, and MLEE datasets demonstrate the superiority of the proposed CARLG model. It outperforms previous state-of-the-art approaches by 1.26 F1, 1.22 F1, and 1.98 F1, respectively, while reducing the inference time by 31%. Furthermore, we provide detailed experimental analyses based on the performance gains and illustrate the interpretability of our model.
Conditional Density Estimations from Privacy-Protected Data
Oct 19, 2023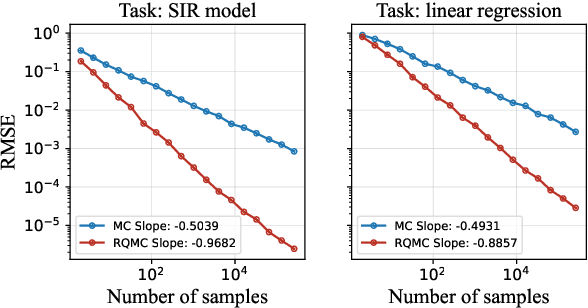
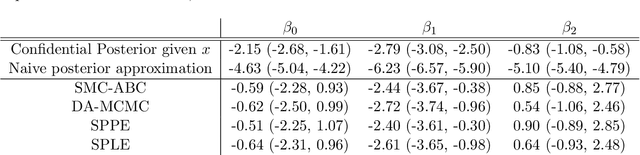
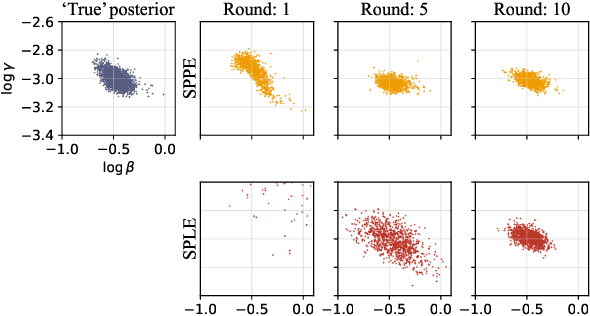
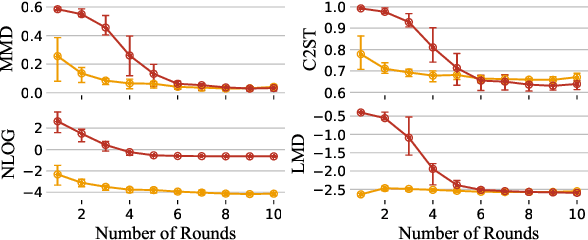
Many modern statistical analysis and machine learning applications require training models on sensitive user data. Differential privacy provides a formal guarantee that individual-level information about users does not leak. In this framework, randomized algorithms inject calibrated noise into the confidential data, resulting in privacy-protected datasets or queries. However, restricting access to only the privatized data during statistical analysis makes it computationally challenging to perform valid inferences on parameters underlying the confidential data. In this work, we propose simulation-based inference methods from privacy-protected datasets. Specifically, we use neural conditional density estimators as a flexible family of distributions to approximate the posterior distribution of model parameters given the observed private query results. We illustrate our methods on discrete time-series data under an infectious disease model and on ordinary linear regression models. Illustrating the privacy-utility trade-off, our experiments and analysis demonstrate the necessity and feasibility of designing valid statistical inference procedures to correct for biases introduced by the privacy-protection mechanisms.