 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Local-Global Information Interaction Debiasing for Dynamic Scene Graph Generation
Aug 10, 2023
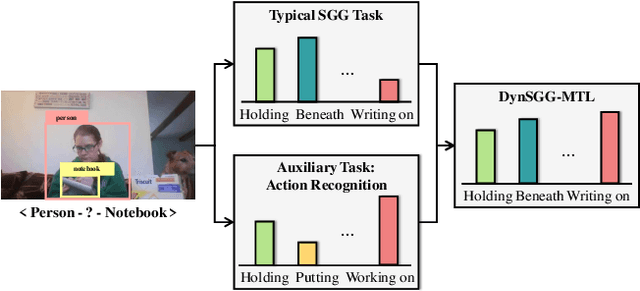
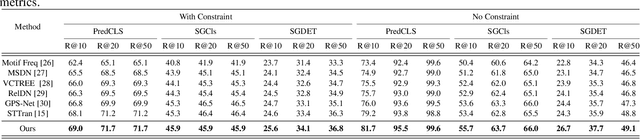
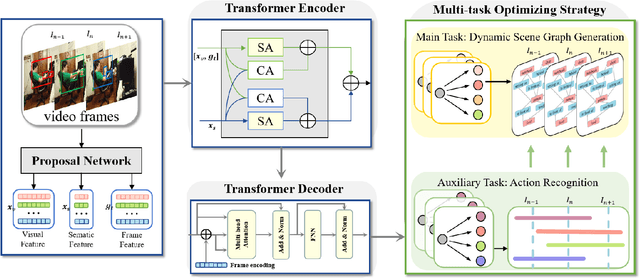
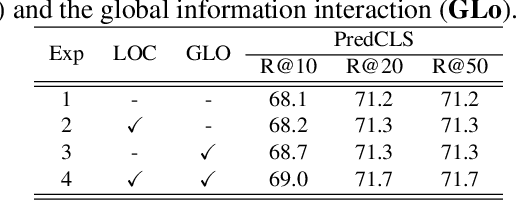
The task of dynamic scene graph generation (DynSGG) aims to generate scene graphs for given videos, which involves modeling the spatial-temporal information in the video. However, due to the long-tailed distribution of samples in the dataset, previous DynSGG models fail to predict the tail predicates. We argue that this phenomenon is due to previous methods that only pay attention to the local spatial-temporal information and neglect the consistency of multiple frames. To solve this problem, we propose a novel DynSGG model based on multi-task learning, DynSGG-MTL, which introduces the local interaction information and global human-action interaction information. The interaction between objects and frame features makes the model more fully understand the visual context of the single image. Long-temporal human actions supervise the model to generate multiple scene graphs that conform to the global constraints and avoid the model being unable to learn the tail predicates. Extensive experiments on Action Genome dataset demonstrate the efficacy of our proposed framework, which not only improves the dynamic scene graph generation but also alleviates the long-tail problem.
Training A Semantic Communication System with Federated Learning
Oct 20, 2023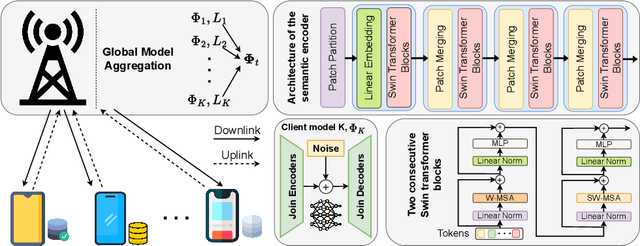
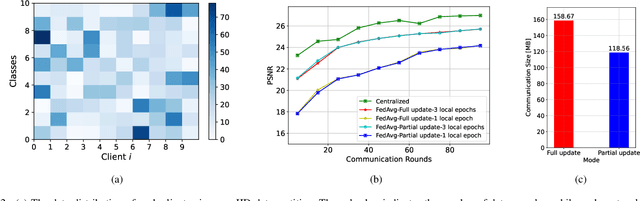
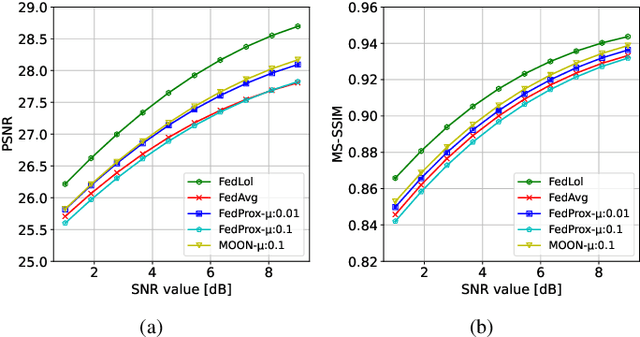

Semantic communication has emerged as a pillar for the next generation of communication systems due to its capabilities in alleviating data redundancy. Most semantic communication systems are built using advanced deep learning models whose performance heavily depends on data availability. These studies assume that an abundance of training data is available, which is unrealistic. In practice, data is mainly created on the user side. Due to privacy and security concerns, the transmission of data is restricted, which is necessary for conventional centralized training schemes. To address this challenge, we explore semantic communication in federated learning (FL) setting that utilizes user data without leaking privacy. Additionally, we design our system to tackle the communication overhead by reducing the quantity of information delivered in each global round. In this way, we can save significant bandwidth for resource-limited devices and reduce overall network traffic. Finally, we propose a mechanism to aggregate the global model from the clients, called FedLol. Extensive simulation results demonstrate the efficacy of our proposed technique compared to baseline methods.
Simultaneous Machine Translation with Tailored Reference
Oct 20, 2023
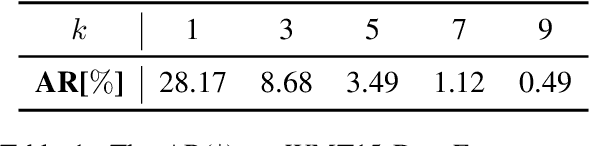
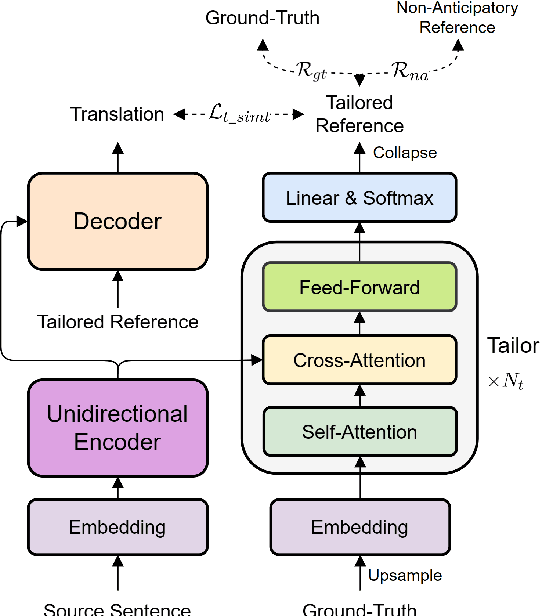

Simultaneous machine translation (SiMT) generates translation while reading the whole source sentence. However, existing SiMT models are typically trained using the same reference disregarding the varying amounts of available source information at different latency. Training the model with ground-truth at low latency may introduce forced anticipations, whereas utilizing reference consistent with the source word order at high latency results in performance degradation. Consequently, it is crucial to train the SiMT model with appropriate reference that avoids forced anticipations during training while maintaining high quality. In this paper, we propose a novel method that provides tailored reference for the SiMT models trained at different latency by rephrasing the ground-truth. Specifically, we introduce the tailor, induced by reinforcement learning, to modify ground-truth to the tailored reference. The SiMT model is trained with the tailored reference and jointly optimized with the tailor to enhance performance. Importantly, our method is applicable to a wide range of current SiMT approaches. Experiments on three translation tasks demonstrate that our method achieves state-of-the-art performance in both fixed and adaptive policies.
Calibrating Neural Simulation-Based Inference with Differentiable Coverage Probability
Oct 20, 2023Bayesian inference allows expressing the uncertainty of posterior belief under a probabilistic model given prior information and the likelihood of the evidence. Predominantly, the likelihood function is only implicitly established by a simulator posing the need for simulation-based inference (SBI). However, the existing algorithms can yield overconfident posteriors (Hermans *et al.*, 2022) defeating the whole purpose of credibility if the uncertainty quantification is inaccurate. We propose to include a calibration term directly into the training objective of the neural model in selected amortized SBI techniques. By introducing a relaxation of the classical formulation of calibration error we enable end-to-end backpropagation. The proposed method is not tied to any particular neural model and brings moderate computational overhead compared to the profits it introduces. It is directly applicable to existing computational pipelines allowing reliable black-box posterior inference. We empirically show on six benchmark problems that the proposed method achieves competitive or better results in terms of coverage and expected posterior density than the previously existing approaches.
Efficient and Effective Multi-View Subspace Clustering for Large-scale Data
Oct 15, 2023Recent multi-view subspace clustering achieves impressive results utilizing deep networks, where the self-expressive correlation is typically modeled by a fully connected (FC) layer. However, they still suffer from two limitations: i) it is under-explored to extract a unified representation from multiple views that simultaneously satisfy minimal sufficiency and discriminability. ii) the parameter scale of the FC layer is quadratic to the number of samples, resulting in high time and memory costs that significantly degrade their feasibility in large-scale datasets. In light of this, we propose a novel deep framework termed Efficient and Effective Large-scale Multi-View Subspace Clustering (E$^2$LMVSC). Specifically, to enhance the quality of the unified representation, a soft clustering assignment similarity constraint is devised for explicitly decoupling consistent, complementary, and superfluous information across multi-view data. Then, following information bottleneck theory, a sufficient yet minimal unified feature representation is obtained. Moreover, E$^2$LMVSC employs the maximal coding rate reduction principle to promote intra-cluster aggregation and inter-cluster separability within the unified representation. Finally, the self-expressive coefficients are learned by a Relation-Metric Net instead of a parameterized FC layer for greater efficiency. Extensive experiments show that E$^2$LMVSC yields comparable results to existing methods and achieves state-of-the-art clustering performance in large-scale multi-view datasets.
Dynamic Link Prediction for New Nodes in Temporal Graph Networks
Oct 15, 2023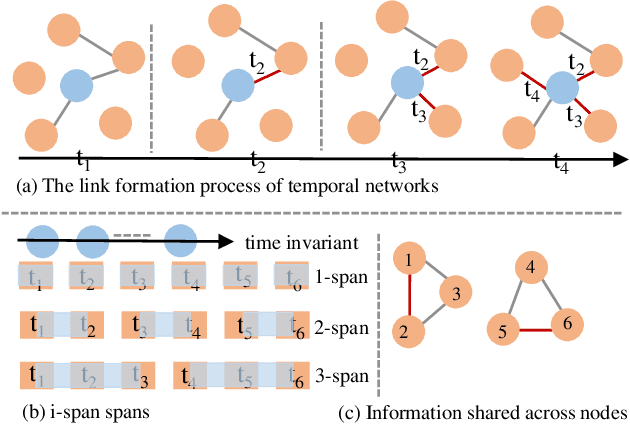
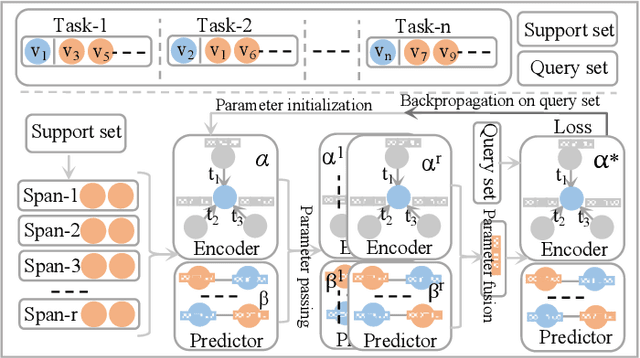

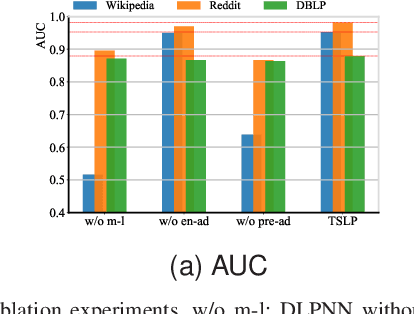
Modelling temporal networks for dynamic link prediction of new nodes has many real-world applications, such as providing relevant item recommendations to new customers in recommender systems and suggesting appropriate posts to new users on social platforms. Unlike old nodes, new nodes have few historical links, which poses a challenge for the dynamic link prediction task. Most existing dynamic models treat all nodes equally and are not specialized for new nodes, resulting in suboptimal performances. In this paper, we consider dynamic link prediction of new nodes as a few-shot problem and propose a novel model based on the meta-learning principle to effectively mitigate this problem. Specifically, we develop a temporal encoder with a node-level span memory to obtain a new node embedding, and then we use a predictor to determine whether the new node generates a link. To overcome the few-shot challenge, we incorporate the encoder-predictor into the meta-learning paradigm, which can learn two types of implicit information during the formation of the temporal network through span adaptation and node adaptation. The acquired implicit information can serve as model initialisation and facilitate rapid adaptation to new nodes through a fine-tuning process on just a few links. Experiments on three publicly available datasets demonstrate the superior performance of our model compared to existing state-of-the-art methods.
Leveraging Neural Radiance Fields for Uncertainty-Aware Visual Localization
Oct 10, 2023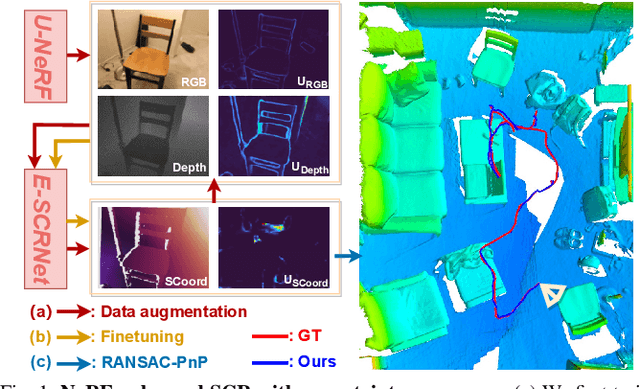
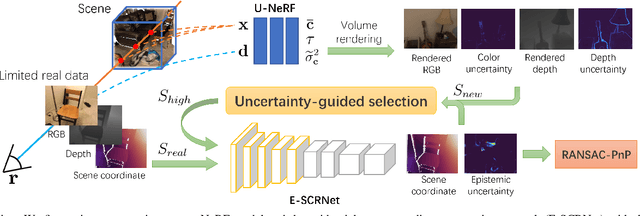
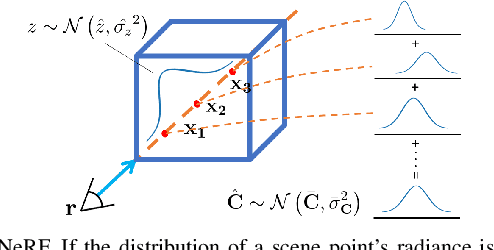

As a promising fashion for visual localization, scene coordinate regression (SCR) has seen tremendous progress in the past decade. Most recent methods usually adopt neural networks to learn the mapping from image pixels to 3D scene coordinates, which requires a vast amount of annotated training data. We propose to leverage Neural Radiance Fields (NeRF) to generate training samples for SCR. Despite NeRF's efficiency in rendering, many of the rendered data are polluted by artifacts or only contain minimal information gain, which can hinder the regression accuracy or bring unnecessary computational costs with redundant data. These challenges are addressed in three folds in this paper: (1) A NeRF is designed to separately predict uncertainties for the rendered color and depth images, which reveal data reliability at the pixel level. (2) SCR is formulated as deep evidential learning with epistemic uncertainty, which is used to evaluate information gain and scene coordinate quality. (3) Based on the three arts of uncertainties, a novel view selection policy is formed that significantly improves data efficiency. Experiments on public datasets demonstrate that our method could select the samples that bring the most information gain and promote the performance with the highest efficiency.
Classifying Whole Slide Images: What Matters?
Oct 05, 2023Recently there have been many algorithms proposed for the classification of very high resolution whole slide images (WSIs). These new algorithms are mostly focused on finding novel ways to combine the information from small local patches extracted from the slide, with an emphasis on effectively aggregating more global information for the final predictor. In this paper we thoroughly explore different key design choices for WSI classification algorithms to investigate what matters most for achieving high accuracy. Surprisingly, we found that capturing global context information does not necessarily mean better performance. A model that captures the most global information consistently performs worse than a model that captures less global information. In addition, a very simple multi-instance learning method that captures no global information performs almost as well as models that capture a lot of global information. These results suggest that the most important features for effective WSI classification are captured at the local small patch level, where cell and tissue micro-environment detail is most pronounced. Another surprising finding was that unsupervised pre-training on a larger set of 33 cancers gives significantly worse performance compared to pre-training on a smaller dataset of 7 cancers (including the target cancer). We posit that pre-training on a smaller, more focused dataset allows the feature extractor to make better use of the limited feature space to better discriminate between subtle differences in the input patch.
Sensing-assisted Accurate and Fast Beam Management for Cellular-connected mmWave UAV Network
Oct 12, 2023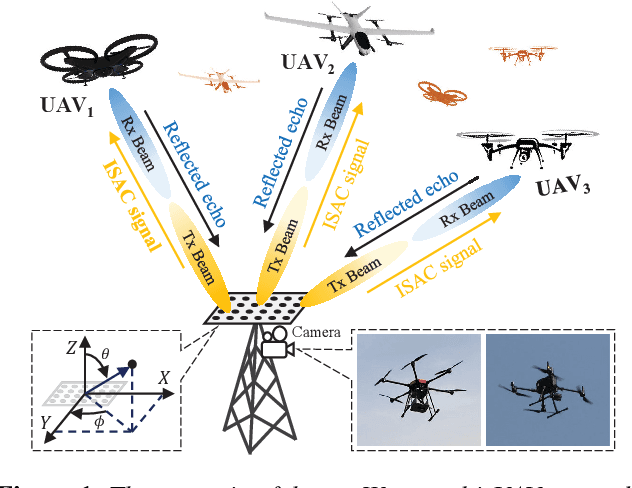
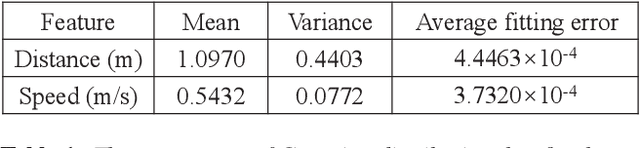
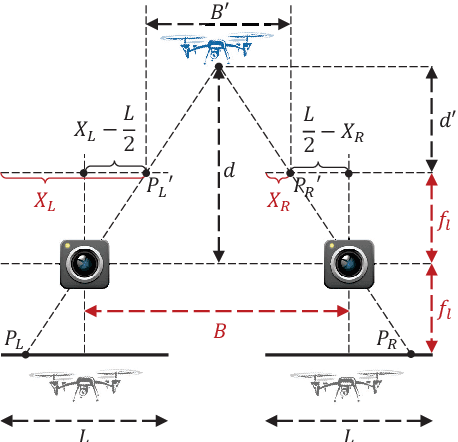
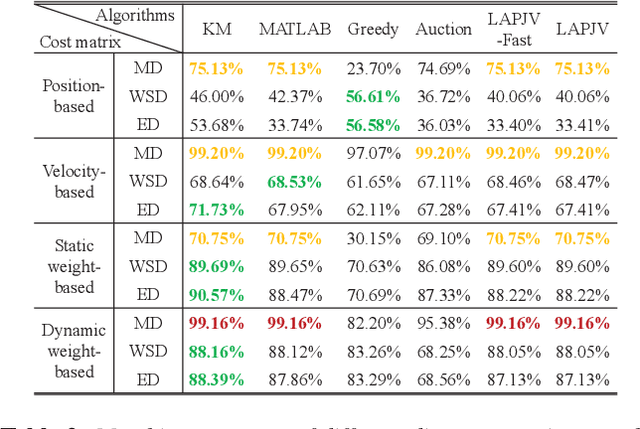
Beam management, including initial access (IA) and beam tracking, is essential to the millimeter-wave Unmanned Aerial Vehicle (UAV) network. However, conventional communication-only and feedback-based schemes suffer a high delay and low accuracy of beam alignment since they only enable the receiver to passively hear the information of the transmitter from the radio domain. This paper presents a novel sensing-assisted beam management approach, the first solution that fully utilizes the information from the visual domain to improve communication performance. We employ both integrated sensing and communication and computer vision techniques and design an extended Kalman filtering method for beam tracking and prediction. Besides, we also propose a novel dual identity association solution to distinguish multiple UAVs in dynamic environments. Real-world experiments and numerical results show that the proposed solution outperforms the conventional methods in IA delay, association accuracy, tracking error, and communication performance.
Exploring Large Language Models for Multi-Modal Out-of-Distribution Detection
Oct 12, 2023Out-of-distribution (OOD) detection is essential for reliable and trustworthy machine learning. Recent multi-modal OOD detection leverages textual information from in-distribution (ID) class names for visual OOD detection, yet it currently neglects the rich contextual information of ID classes. Large language models (LLMs) encode a wealth of world knowledge and can be prompted to generate descriptive features for each class. Indiscriminately using such knowledge causes catastrophic damage to OOD detection due to LLMs' hallucinations, as is observed by our analysis. In this paper, we propose to apply world knowledge to enhance OOD detection performance through selective generation from LLMs. Specifically, we introduce a consistency-based uncertainty calibration method to estimate the confidence score of each generation. We further extract visual objects from each image to fully capitalize on the aforementioned world knowledge. Extensive experiments demonstrate that our method consistently outperforms the state-of-the-art.