 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Democratizing LLMs: An Exploration of Cost-Performance Trade-offs in Self-Refined Open-Source Models
Oct 11, 2023
The dominance of proprietary LLMs has led to restricted access and raised information privacy concerns. High-performing open-source alternatives are crucial for information-sensitive and high-volume applications but often lag behind in performance. To address this gap, we propose (1) A untargeted variant of iterative self-critique and self-refinement devoid of external influence. (2) A novel ranking metric - Performance, Refinement, and Inference Cost Score (PeRFICS) - to find the optimal model for a given task considering refined performance and cost. Our experiments show that SoTA open source models of varying sizes from 7B - 65B, on average, improve 8.2% from their baseline performance. Strikingly, even models with extremely small memory footprints, such as Vicuna-7B, show a 11.74% improvement overall and up to a 25.39% improvement in high-creativity, open ended tasks on the Vicuna benchmark. Vicuna-13B takes it a step further and outperforms ChatGPT post-refinement. This work has profound implications for resource-constrained and information-sensitive environments seeking to leverage LLMs without incurring prohibitive costs, compromising on performance and privacy. The domain-agnostic self-refinement process coupled with our novel ranking metric facilitates informed decision-making in model selection, thereby reducing costs and democratizing access to high-performing language models, as evidenced by case studies.
Contrast Everything: A Hierarchical Contrastive Framework for Medical Time-Series
Oct 21, 2023

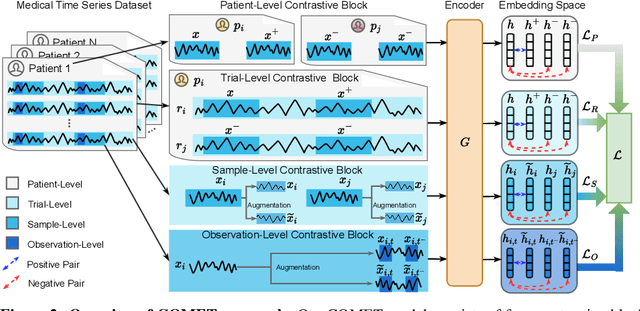
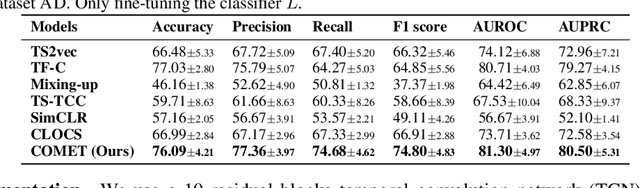
Contrastive representation learning is crucial in medical time series analysis as it alleviates dependency on labor-intensive, domain-specific, and scarce expert annotations. However, existing contrastive learning methods primarily focus on one single data level, which fails to fully exploit the intricate nature of medical time series. To address this issue, we present COMET, an innovative hierarchical framework that leverages data consistencies at all inherent levels in medical time series. Our meticulously designed model systematically captures data consistency from four potential levels: observation, sample, trial, and patient levels. By developing contrastive loss at multiple levels, we can learn effective representations that preserve comprehensive data consistency, maximizing information utilization in a self-supervised manner. We conduct experiments in the challenging patient-independent setting. We compare COMET against six baselines using three diverse datasets, which include ECG signals for myocardial infarction and EEG signals for Alzheimer's and Parkinson's diseases. The results demonstrate that COMET consistently outperforms all baselines, particularly in setup with 10% and 1% labeled data fractions across all datasets. These results underscore the significant impact of our framework in advancing contrastive representation learning techniques for medical time series. The source code is available at https://github.com/DL4mHealth/COMET.
* Accepted by NeruIPS 2023; 24pages (13 pages main paper + 11 pages supplementary materials)
From Nuisance to News Sense: Augmenting the News with Cross-Document Evidence and Context
Oct 06, 2023Reading and understanding the stories in the news is increasingly difficult. Reporting on stories evolves rapidly, politicized news venues offer different perspectives (and sometimes different facts), and misinformation is rampant. However, existing solutions merely aggregate an overwhelming amount of information from heterogenous sources, such as different news outlets, social media, and news bias rating agencies. We present NEWSSENSE, a novel sensemaking tool and reading interface designed to collect and integrate information from multiple news articles on a central topic, using a form of reference-free fact verification. NEWSSENSE augments a central, grounding article of the user's choice by linking it to related articles from different sources, providing inline highlights on how specific claims in the chosen article are either supported or contradicted by information from other articles. Using NEWSSENSE, users can seamlessly digest and cross-check multiple information sources without disturbing their natural reading flow. Our pilot study shows that NEWSSENSE has the potential to help users identify key information, verify the credibility of news articles, and explore different perspectives.
Contextualized Machine Learning
Oct 17, 2023We examine Contextualized Machine Learning (ML), a paradigm for learning heterogeneous and context-dependent effects. Contextualized ML estimates heterogeneous functions by applying deep learning to the meta-relationship between contextual information and context-specific parametric models. This is a form of varying-coefficient modeling that unifies existing frameworks including cluster analysis and cohort modeling by introducing two reusable concepts: a context encoder which translates sample context into model parameters, and sample-specific model which operates on sample predictors. We review the process of developing contextualized models, nonparametric inference from contextualized models, and identifiability conditions of contextualized models. Finally, we present the open-source PyTorch package ContextualizedML.
Multimodal Graph Learning for Generative Tasks
Oct 12, 2023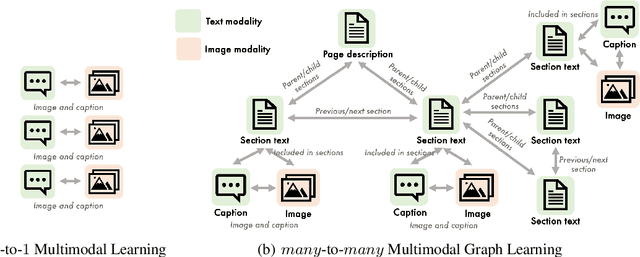
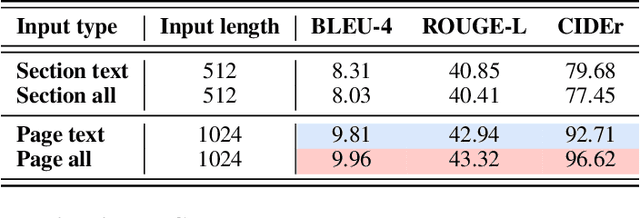
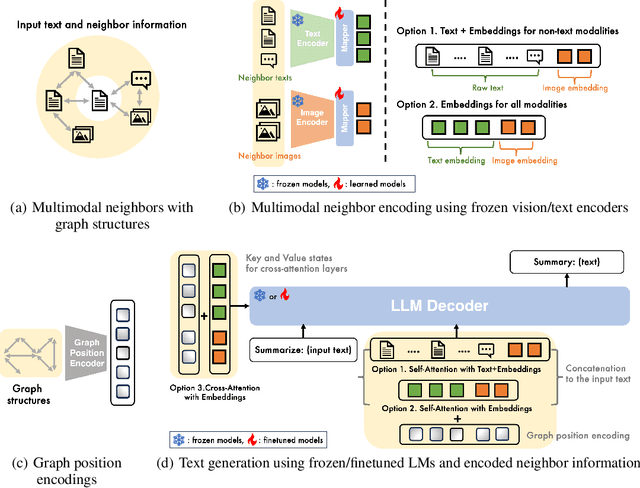
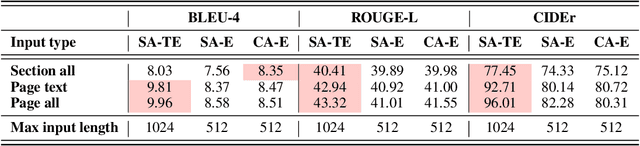
Multimodal learning combines multiple data modalities, broadening the types and complexity of data our models can utilize: for example, from plain text to image-caption pairs. Most multimodal learning algorithms focus on modeling simple one-to-one pairs of data from two modalities, such as image-caption pairs, or audio-text pairs. However, in most real-world settings, entities of different modalities interact with each other in more complex and multifaceted ways, going beyond one-to-one mappings. We propose to represent these complex relationships as graphs, allowing us to capture data with any number of modalities, and with complex relationships between modalities that can flexibly vary from one sample to another. Toward this goal, we propose Multimodal Graph Learning (MMGL), a general and systematic framework for capturing information from multiple multimodal neighbors with relational structures among them. In particular, we focus on MMGL for generative tasks, building upon pretrained Language Models (LMs), aiming to augment their text generation with multimodal neighbor contexts. We study three research questions raised by MMGL: (1) how can we infuse multiple neighbor information into the pretrained LMs, while avoiding scalability issues? (2) how can we infuse the graph structure information among multimodal neighbors into the LMs? and (3) how can we finetune the pretrained LMs to learn from the neighbor context in a parameter-efficient manner? We conduct extensive experiments to answer these three questions on MMGL and analyze the empirical results to pave the way for future MMGL research.
ALPHA: Attention-based Long-horizon Pathfinding in Highly-structured Areas
Oct 12, 2023The multi-agent pathfinding (MAPF) problem seeks collision-free paths for a team of agents from their current positions to their pre-set goals in a known environment, and is an essential problem found at the core of many logistics, transportation, and general robotics applications. Existing learning-based MAPF approaches typically only let each agent make decisions based on a limited field-of-view (FOV) around its position, as a natural means to fix the input dimensions of its policy network. However, this often makes policies short-sighted, since agents lack the ability to perceive and plan for obstacles/agents beyond their FOV. To address this challenge, we propose ALPHA, a new framework combining the use of ground truth proximal (local) information and fuzzy distal (global) information to let agents sequence local decisions based on the full current state of the system, and avoid such myopicity. We further allow agents to make short-term predictions about each others' paths, as a means to reason about each others' path intentions, thereby enhancing the level of cooperation among agents at the whole system level. Our neural structure relies on a Graph Transformer architecture to allow agents to selectively combine these different sources of information and reason about their inter-dependencies at different spatial scales. Our simulation experiments demonstrate that ALPHA outperforms both globally-guided MAPF solvers and communication-learning based ones, showcasing its potential towards scalability in realistic deployments.
Omnidirectional Information Gathering for Knowledge Transfer-based Audio-Visual Navigation
Aug 20, 2023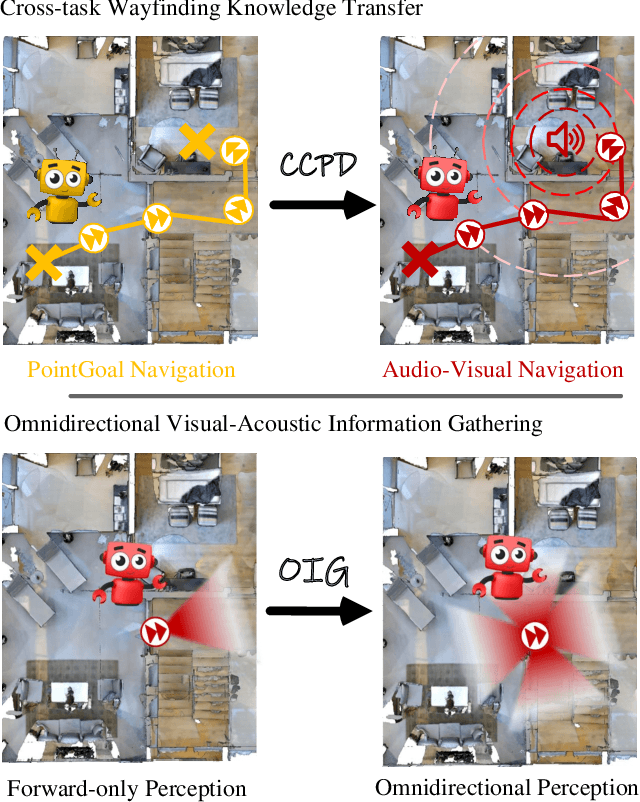
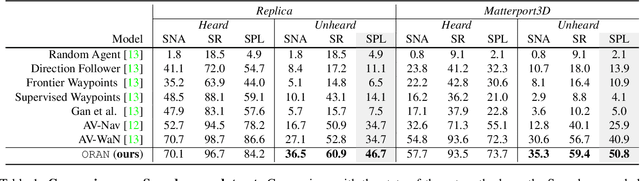
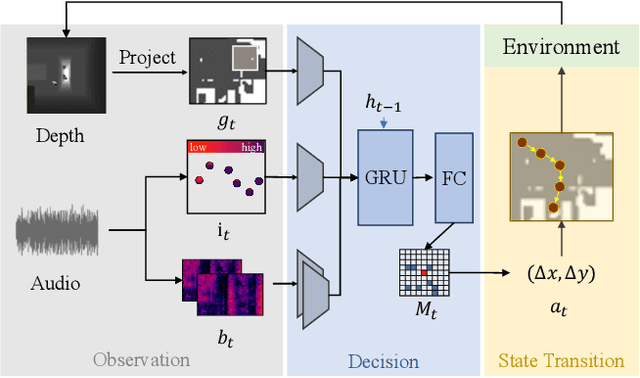

Audio-visual navigation is an audio-targeted wayfinding task where a robot agent is entailed to travel a never-before-seen 3D environment towards the sounding source. In this article, we present ORAN, an omnidirectional audio-visual navigator based on cross-task navigation skill transfer. In particular, ORAN sharpens its two basic abilities for a such challenging task, namely wayfinding and audio-visual information gathering. First, ORAN is trained with a confidence-aware cross-task policy distillation (CCPD) strategy. CCPD transfers the fundamental, point-to-point wayfinding skill that is well trained on the large-scale PointGoal task to ORAN, so as to help ORAN to better master audio-visual navigation with far fewer training samples. To improve the efficiency of knowledge transfer and address the domain gap, CCPD is made to be adaptive to the decision confidence of the teacher policy. Second, ORAN is equipped with an omnidirectional information gathering (OIG) mechanism, i.e., gleaning visual-acoustic observations from different directions before decision-making. As a result, ORAN yields more robust navigation behaviour. Taking CCPD and OIG together, ORAN significantly outperforms previous competitors. After the model ensemble, we got 1st in Soundspaces Challenge 2022, improving SPL and SR by 53% and 35% relatively.
Large Language Models for Information Retrieval: A Survey
Aug 15, 2023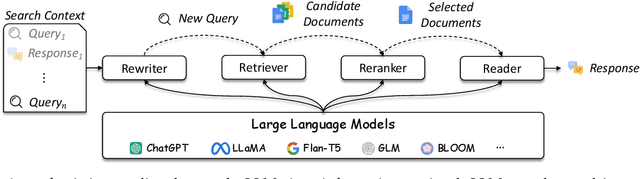
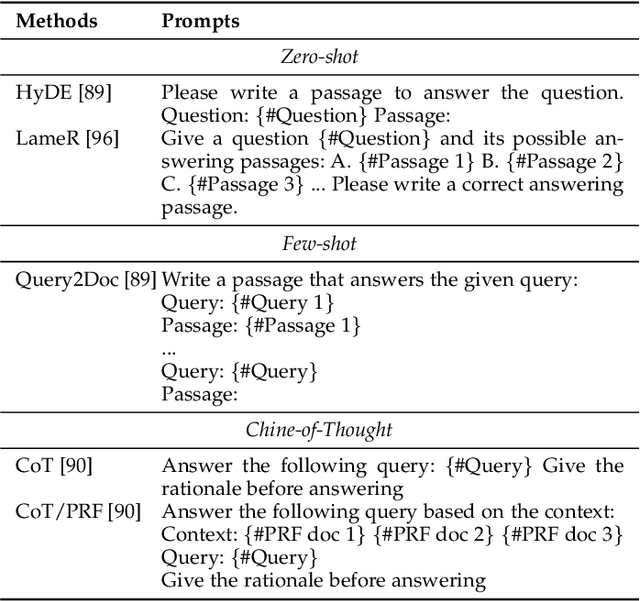
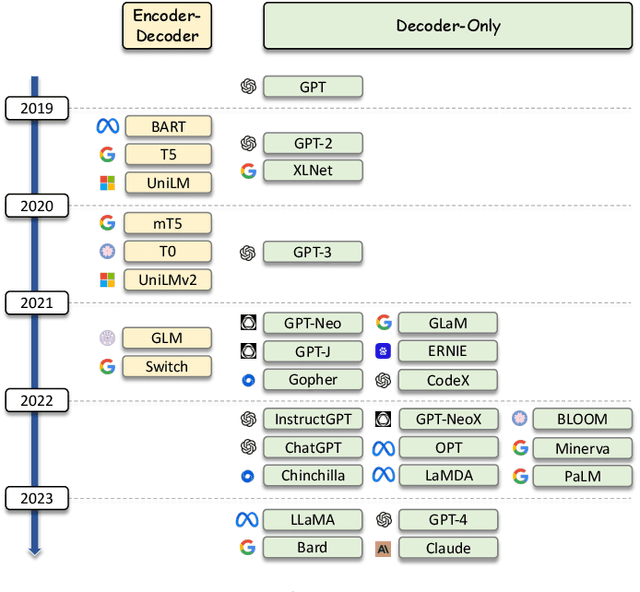
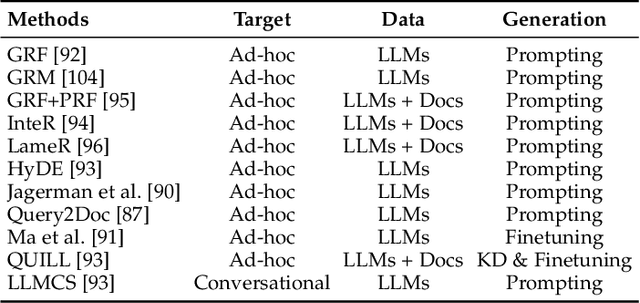
As a primary means of information acquisition, information retrieval (IR) systems, such as search engines, have integrated themselves into our daily lives. These systems also serve as components of dialogue, question-answering, and recommender systems. The trajectory of IR has evolved dynamically from its origins in term-based methods to its integration with advanced neural models. While the neural models excel at capturing complex contextual signals and semantic nuances, thereby reshaping the IR landscape, they still face challenges such as data scarcity, interpretability, and the generation of contextually plausible yet potentially inaccurate responses. This evolution requires a combination of both traditional methods (such as term-based sparse retrieval methods with rapid response) and modern neural architectures (such as language models with powerful language understanding capacity). Meanwhile, the emergence of large language models (LLMs), typified by ChatGPT and GPT-4, has revolutionized natural language processing due to their remarkable language understanding, generation, generalization, and reasoning abilities. Consequently, recent research has sought to leverage LLMs to improve IR systems. Given the rapid evolution of this research trajectory, it is necessary to consolidate existing methodologies and provide nuanced insights through a comprehensive overview. In this survey, we delve into the confluence of LLMs and IR systems, including crucial aspects such as query rewriters, retrievers, rerankers, and readers. Additionally, we explore promising directions within this expanding field.
Self-Detoxifying Language Models via Toxification Reversal
Oct 14, 2023Language model detoxification aims to minimize the risk of generating offensive or harmful content in pretrained language models (PLMs) for safer deployment. Existing methods can be roughly categorized as finetuning-based and decoding-based. However, the former is often resource-intensive, while the latter relies on additional components and potentially compromises the generation fluency. In this paper, we propose a more lightweight approach that enables the PLM itself to achieve "self-detoxification". Our method is built upon the observation that prepending a negative steering prompt can effectively induce PLMs to generate toxic content. At the same time, we are inspired by the recent research in the interpretability field, which formulates the evolving contextualized representations within the PLM as an information stream facilitated by the attention layers. Drawing on this idea, we devise a method to identify the toxification direction from the normal generation process to the one prompted with the negative prefix, and then steer the generation to the reversed direction by manipulating the information movement within the attention layers. Experimental results show that our approach, without any fine-tuning or extra components, can achieve comparable performance with state-of-the-art methods.
Augmenting End-to-End Steering Angle Prediction with CAN Bus Data
Oct 22, 2023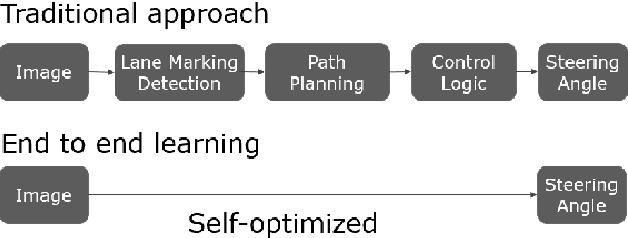
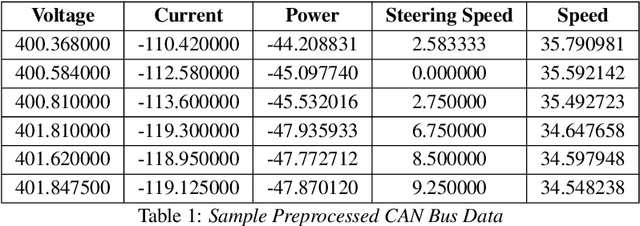
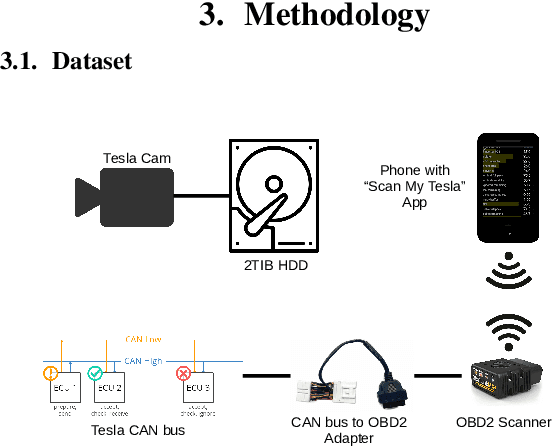
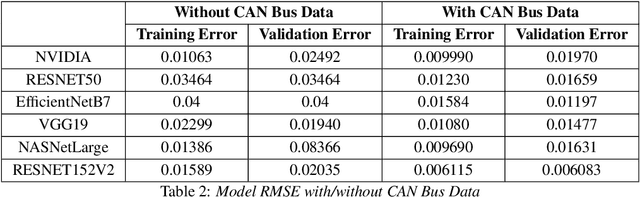
In recent years, end to end steering prediction for autonomous vehicles has become a major area of research. The primary method for achieving end to end steering was to use computer vision models on a live feed of video data. However, to further increase accuracy, many companies have added data from light detection and ranging (LiDAR) and or radar sensors through sensor fusion. However, the addition of lasers and sensors comes at a high financial cost. In this paper, I address both of these issues by increasing the accuracy of the computer vision models without the increased cost of using LiDAR and or sensors. I achieved this by improving the accuracy of computer vision models by sensor fusing CAN bus data, a vehicle protocol, with video data. CAN bus data is a rich source of information about the vehicle's state, including its speed, steering angle, and acceleration. By fusing this data with video data, the accuracy of the computer vision model's predictions can be improved. When I trained the model without CAN bus data, I obtained an RMSE of 0.02492, while the model trained with the CAN bus data achieved an RMSE of 0.01970. This finding indicates that fusing CAN Bus data with video data can reduce the computer vision model's prediction error by 20% with some models decreasing the error by 80%.