 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Addressing the cold start problem in privacy preserving content-based recommender systems using hypercube graphs
Oct 13, 2023
The initial interaction of a user with a recommender system is problematic because, in such a so-called cold start situation, the recommender system has very little information about the user, if any. Moreover, in collaborative filtering, users need to share their preferences with the service provider by rating items while in content-based filtering there is no need for such information sharing. We have recently shown that a content-based model that uses hypercube graphs can determine user preferences with a very limited number of ratings while better preserving user privacy. In this paper, we confirm these findings on the basis of experiments with more than 1,000 users in the restaurant and movie domains. We show that the proposed method outperforms standard machine learning algorithms when the number of available ratings is at most 10, which often happens, and is competitive with larger training sets. In addition, training is simple and does not require large computational efforts.
Unsupervised Candidate Answer Extraction through Differentiable Masker-Reconstructor Model
Oct 19, 2023Question generation is a widely used data augmentation approach with extensive applications, and extracting qualified candidate answers from context passages is a critical step for most question generation systems. However, existing methods for candidate answer extraction are reliant on linguistic rules or annotated data that face the partial annotation issue and challenges in generalization. To overcome these limitations, we propose a novel unsupervised candidate answer extraction approach that leverages the inherent structure of context passages through a Differentiable Masker-Reconstructor (DMR) Model with the enforcement of self-consistency for picking up salient information tokens. We curated two datasets with exhaustively-annotated answers and benchmark a comprehensive set of supervised and unsupervised candidate answer extraction methods. We demonstrate the effectiveness of the DMR model by showing its performance is superior among unsupervised methods and comparable to supervised methods.
Time and Frequency Offset Estimation and Intercarrier Interference Cancellation for AFDM Systems
Oct 19, 2023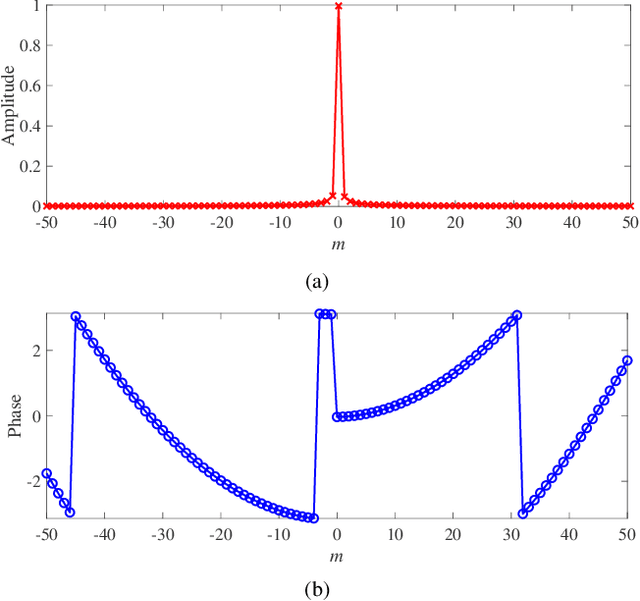

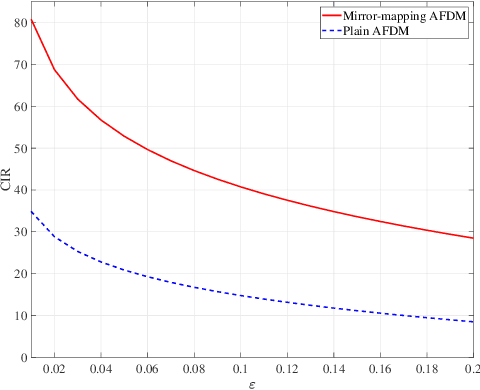
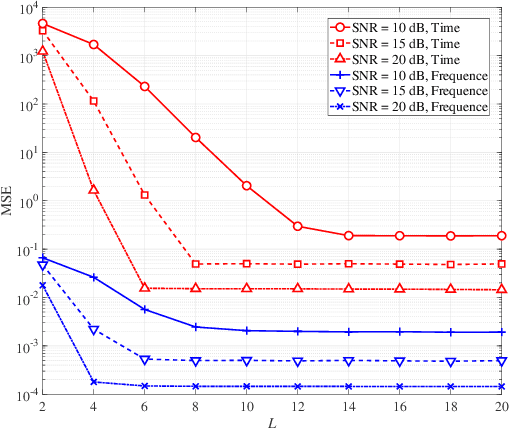
Affine frequency division multiplexing (AFDM) is an emerging multicarrier waveform that offers a potential solution for achieving reliable communication for time-varying channels. This paper proposes two maximum likelihood (ML) estimators of symbol time offset and carrier frequency offset for AFDM systems. The joint ML estimator evaluates the arrival time and frequency offset by comparing the correlations of samples. Moreover, we propose the stepwise ML estimator to reduce the complexity. The proposed estimators exploit the redundant information contained within the chirp-periodic prefix inherent in AFDM symbols, thus dispensing with any additional pilots. To further mitigate the intercarrier interference resulting from the residual frequency offset, we design a mirror-mappingbased scheme for AFDM systems. Numerical results verify the effectiveness of the proposed time and frequency offset estimation criteria and the mirror-mapping-based modulation for AFDM systems.
Know Where to Go: Make LLM a Relevant, Responsible, and Trustworthy Searcher
Oct 19, 2023The advent of Large Language Models (LLMs) has shown the potential to improve relevance and provide direct answers in web searches. However, challenges arise in validating the reliability of generated results and the credibility of contributing sources, due to the limitations of traditional information retrieval algorithms and the LLM hallucination problem. Aiming to create a "PageRank" for the LLM era, we strive to transform LLM into a relevant, responsible, and trustworthy searcher. We propose a novel generative retrieval framework leveraging the knowledge of LLMs to foster a direct link between queries and online sources. This framework consists of three core modules: Generator, Validator, and Optimizer, each focusing on generating trustworthy online sources, verifying source reliability, and refining unreliable sources, respectively. Extensive experiments and evaluations highlight our method's superior relevance, responsibility, and trustfulness against various SOTA methods.
Memory efficient location recommendation through proximity-aware representation
Oct 10, 2023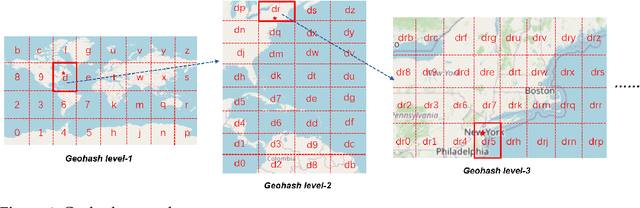
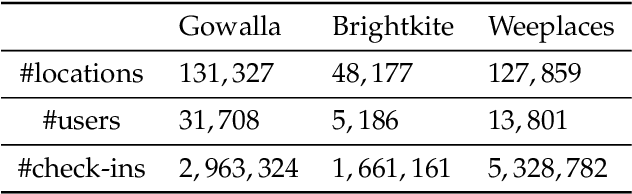
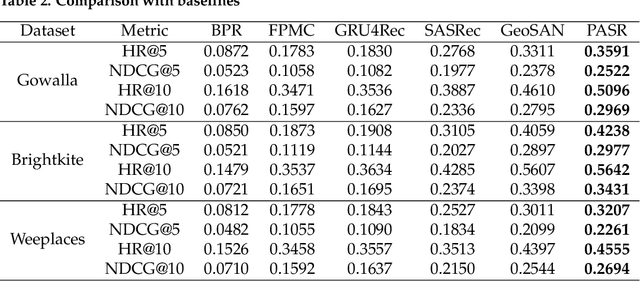
Sequential location recommendation plays a huge role in modern life, which can enhance user experience, bring more profit to businesses and assist in government administration. Although methods for location recommendation have evolved significantly thanks to the development of recommendation systems, there is still limited utilization of geographic information, along with the ongoing challenge of addressing data sparsity. In response, we introduce a Proximity-aware based region representation for Sequential Recommendation (PASR for short), built upon the Self-Attention Network architecture. We tackle the sparsity issue through a novel loss function employing importance sampling, which emphasizes informative negative samples during optimization. Moreover, PASR enhances the integration of geographic information by employing a self-attention-based geography encoder to the hierarchical grid and proximity grid at each GPS point. To further leverage geographic information, we utilize the proximity-aware negative samplers to enhance the quality of negative samples. We conducted evaluations using three real-world Location-Based Social Networking (LBSN) datasets, demonstrating that PASR surpasses state-of-the-art sequential location recommendation methods
Universal Multi-modal Entity Alignment via Iteratively Fusing Modality Similarity Paths
Oct 10, 2023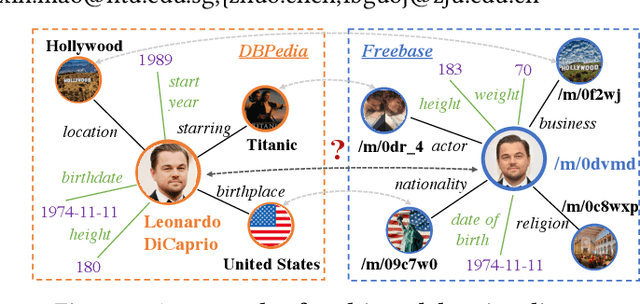
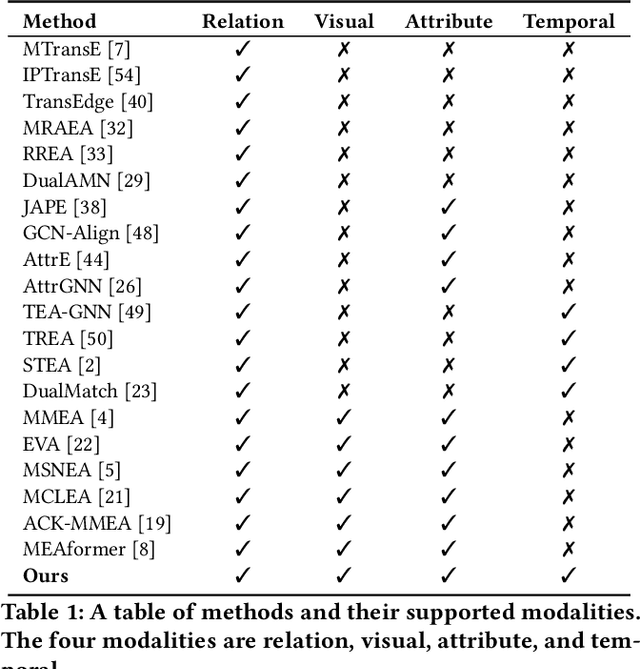

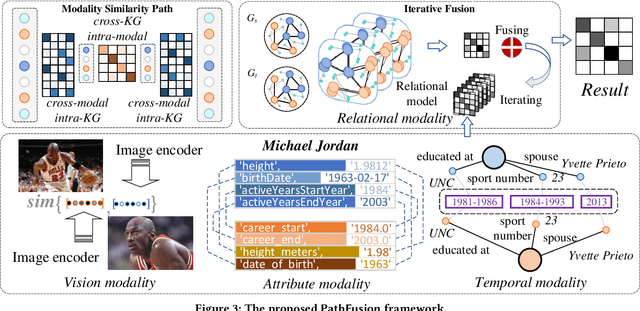
The objective of Entity Alignment (EA) is to identify equivalent entity pairs from multiple Knowledge Graphs (KGs) and create a more comprehensive and unified KG. The majority of EA methods have primarily focused on the structural modality of KGs, lacking exploration of multi-modal information. A few multi-modal EA methods have made good attempts in this field. Still, they have two shortcomings: (1) inconsistent and inefficient modality modeling that designs complex and distinct models for each modality; (2) ineffective modality fusion due to the heterogeneous nature of modalities in EA. To tackle these challenges, we propose PathFusion, consisting of two main components: (1) MSP, a unified modeling approach that simplifies the alignment process by constructing paths connecting entities and modality nodes to represent multiple modalities; (2) IRF, an iterative fusion method that effectively combines information from different modalities using the path as an information carrier. Experimental results on real-world datasets demonstrate the superiority of PathFusion over state-of-the-art methods, with 22.4%-28.9% absolute improvement on Hits@1, and 0.194-0.245 absolute improvement on MRR.
Leveraging Contextual Information for Effective Entity Salience Detection
Sep 14, 2023In text documents such as news articles, the content and key events usually revolve around a subset of all the entities mentioned in a document. These entities, often deemed as salient entities, provide useful cues of the aboutness of a document to a reader. Identifying the salience of entities was found helpful in several downstream applications such as search, ranking, and entity-centric summarization, among others. Prior work on salient entity detection mainly focused on machine learning models that require heavy feature engineering. We show that fine-tuning medium-sized language models with a cross-encoder style architecture yields substantial performance gains over feature engineering approaches. To this end, we conduct a comprehensive benchmarking of four publicly available datasets using models representative of the medium-sized pre-trained language model family. Additionally, we show that zero-shot prompting of instruction-tuned language models yields inferior results, indicating the task's uniqueness and complexity.
Omnidirectional Information Gathering for Knowledge Transfer-based Audio-Visual Navigation
Aug 20, 2023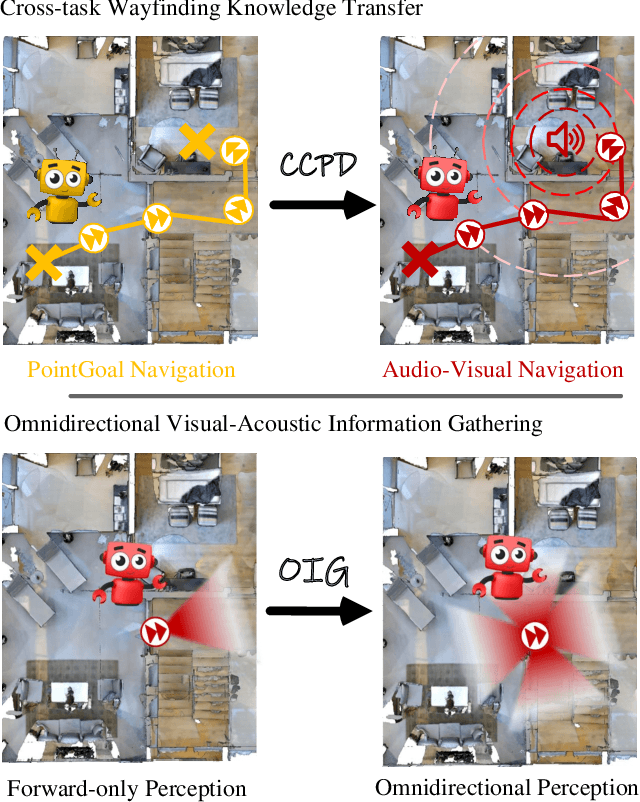
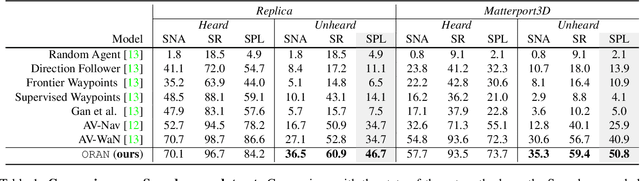
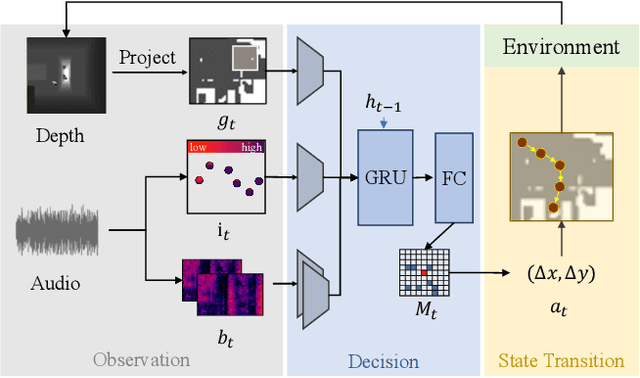

Audio-visual navigation is an audio-targeted wayfinding task where a robot agent is entailed to travel a never-before-seen 3D environment towards the sounding source. In this article, we present ORAN, an omnidirectional audio-visual navigator based on cross-task navigation skill transfer. In particular, ORAN sharpens its two basic abilities for a such challenging task, namely wayfinding and audio-visual information gathering. First, ORAN is trained with a confidence-aware cross-task policy distillation (CCPD) strategy. CCPD transfers the fundamental, point-to-point wayfinding skill that is well trained on the large-scale PointGoal task to ORAN, so as to help ORAN to better master audio-visual navigation with far fewer training samples. To improve the efficiency of knowledge transfer and address the domain gap, CCPD is made to be adaptive to the decision confidence of the teacher policy. Second, ORAN is equipped with an omnidirectional information gathering (OIG) mechanism, i.e., gleaning visual-acoustic observations from different directions before decision-making. As a result, ORAN yields more robust navigation behaviour. Taking CCPD and OIG together, ORAN significantly outperforms previous competitors. After the model ensemble, we got 1st in Soundspaces Challenge 2022, improving SPL and SR by 53% and 35% relatively.
Cheap Talking Algorithms
Oct 11, 2023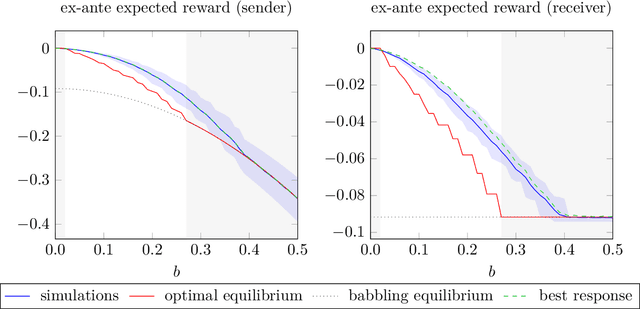
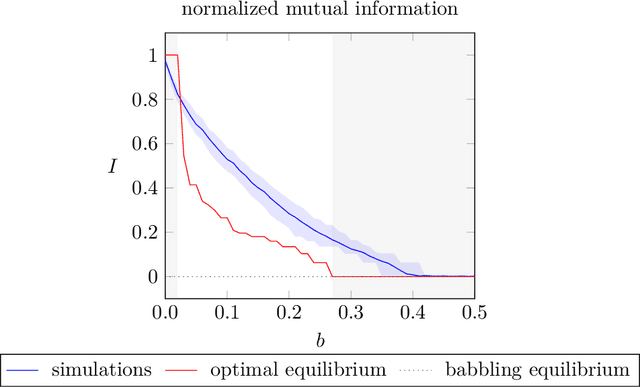
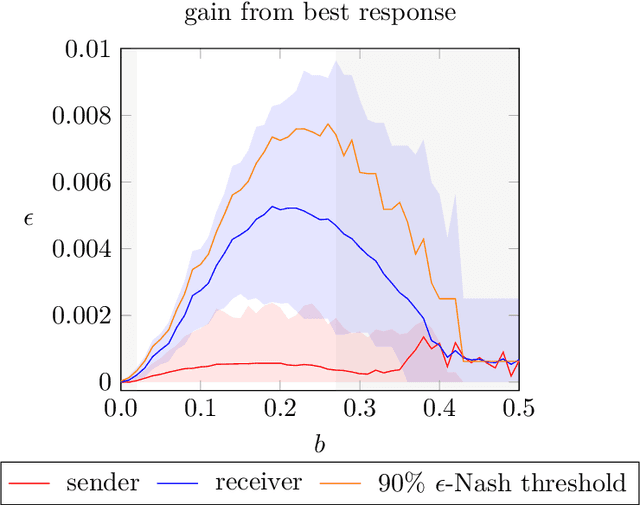
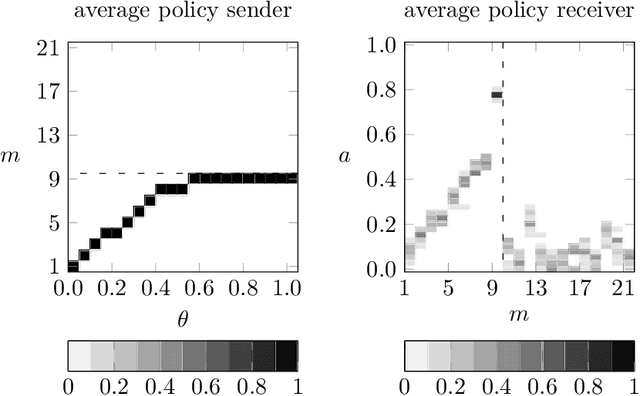
We simulate behaviour of independent reinforcement learning algorithms playing the Crawford and Sobel (1982) game of strategic information transmission. We show that a sender and a receiver training together converge to strategies close to the exante optimal equilibrium of the game. Hence, communication takes place to the largest extent predicted by Nash equilibrium given the degree of conflict of interest between agents. The conclusion is shown to be robust to alternative specifications of the hyperparameters and of the game. We discuss implications for theories of equilibrium selection in information transmission games, for work on emerging communication among algorithms in computer science and for the economics of collusions in markets populated by artificially intelligent agents.
Large Language Models for Information Retrieval: A Survey
Aug 15, 2023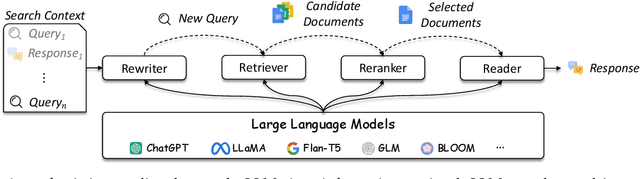
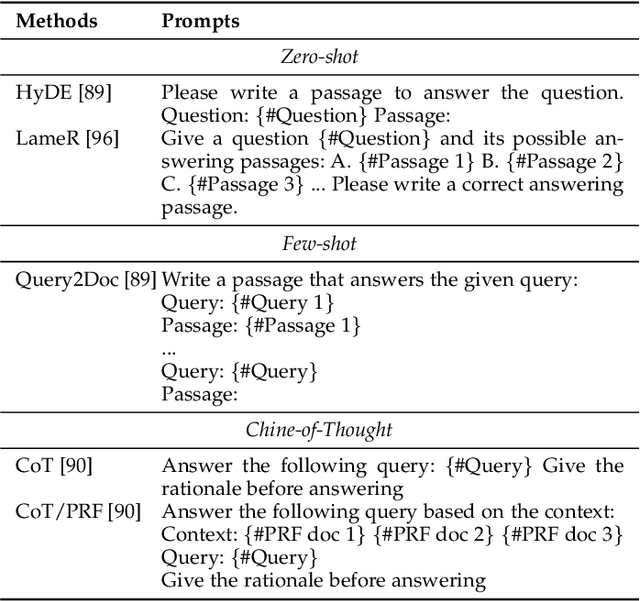
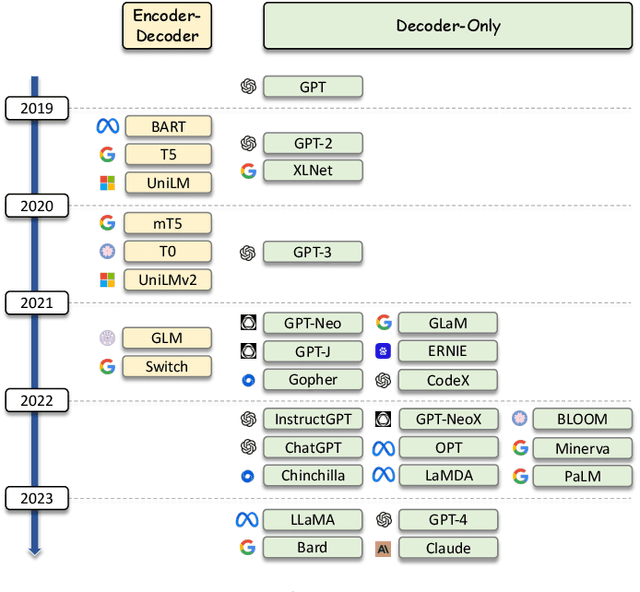
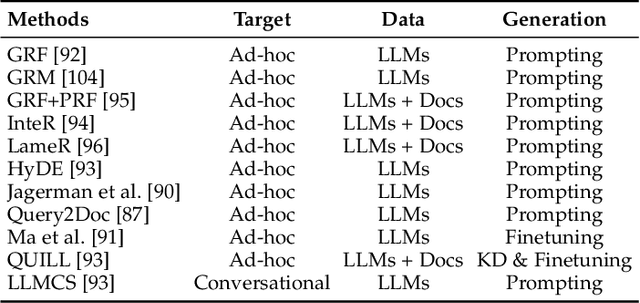
As a primary means of information acquisition, information retrieval (IR) systems, such as search engines, have integrated themselves into our daily lives. These systems also serve as components of dialogue, question-answering, and recommender systems. The trajectory of IR has evolved dynamically from its origins in term-based methods to its integration with advanced neural models. While the neural models excel at capturing complex contextual signals and semantic nuances, thereby reshaping the IR landscape, they still face challenges such as data scarcity, interpretability, and the generation of contextually plausible yet potentially inaccurate responses. This evolution requires a combination of both traditional methods (such as term-based sparse retrieval methods with rapid response) and modern neural architectures (such as language models with powerful language understanding capacity). Meanwhile, the emergence of large language models (LLMs), typified by ChatGPT and GPT-4, has revolutionized natural language processing due to their remarkable language understanding, generation, generalization, and reasoning abilities. Consequently, recent research has sought to leverage LLMs to improve IR systems. Given the rapid evolution of this research trajectory, it is necessary to consolidate existing methodologies and provide nuanced insights through a comprehensive overview. In this survey, we delve into the confluence of LLMs and IR systems, including crucial aspects such as query rewriters, retrievers, rerankers, and readers. Additionally, we explore promising directions within this expanding field.