 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MoPe: Model Perturbation-based Privacy Attacks on Language Models
Oct 22, 2023
Recent work has shown that Large Language Models (LLMs) can unintentionally leak sensitive information present in their training data. In this paper, we present Model Perturbations (MoPe), a new method to identify with high confidence if a given text is in the training data of a pre-trained language model, given white-box access to the models parameters. MoPe adds noise to the model in parameter space and measures the drop in log-likelihood at a given point $x$, a statistic we show approximates the trace of the Hessian matrix with respect to model parameters. Across language models ranging from $70$M to $12$B parameters, we show that MoPe is more effective than existing loss-based attacks and recently proposed perturbation-based methods. We also examine the role of training point order and model size in attack success, and empirically demonstrate that MoPe accurately approximate the trace of the Hessian in practice. Our results show that the loss of a point alone is insufficient to determine extractability -- there are training points we can recover using our method that have average loss. This casts some doubt on prior works that use the loss of a point as evidence of memorization or unlearning.
Neural Text Sanitization with Privacy Risk Indicators: An Empirical Analysis
Oct 22, 2023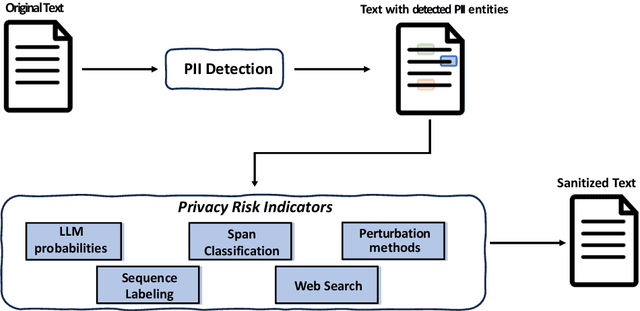


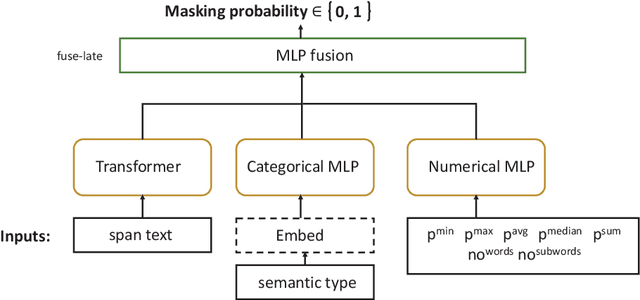
Text sanitization is the task of redacting a document to mask all occurrences of (direct or indirect) personal identifiers, with the goal of concealing the identity of the individual(s) referred in it. In this paper, we consider a two-step approach to text sanitization and provide a detailed analysis of its empirical performance on two recently published datasets: the Text Anonymization Benchmark (Pil\'an et al., 2022) and a collection of Wikipedia biographies (Papadopoulou et al., 2022). The text sanitization process starts with a privacy-oriented entity recognizer that seeks to determine the text spans expressing identifiable personal information. This privacy-oriented entity recognizer is trained by combining a standard named entity recognition model with a gazetteer populated by person-related terms extracted from Wikidata. The second step of the text sanitization process consists in assessing the privacy risk associated with each detected text span, either isolated or in combination with other text spans. We present five distinct indicators of the re-identification risk, respectively based on language model probabilities, text span classification, sequence labelling, perturbations, and web search. We provide a contrastive analysis of each privacy indicator and highlight their benefits and limitations, notably in relation to the available labeled data.
Can You Follow Me? Testing Situational Understanding in ChatGPT
Oct 24, 2023Understanding sentence meanings and updating information states appropriately across time -- what we call "situational understanding" (SU) -- is a critical ability for human-like AI agents. SU is essential in particular for chat models, such as ChatGPT, to enable consistent, coherent, and effective dialogue between humans and AI. Previous works have identified certain SU limitations in non-chatbot Large Language models (LLMs), but the extent and causes of these limitations are not well understood, and capabilities of current chat-based models in this domain have not been explored. In this work we tackle these questions, proposing a novel synthetic environment for SU testing which allows us to do controlled and systematic testing of SU in chat-oriented models, through assessment of models' ability to track and enumerate environment states. Our environment also allows for close analysis of dynamics of model performance, to better understand underlying causes for performance patterns. We apply our test to ChatGPT, the state-of-the-art chatbot, and find that despite the fundamental simplicity of the task, the model's performance reflects an inability to retain correct environment states across time. Our follow-up analyses suggest that performance degradation is largely because ChatGPT has non-persistent in-context memory (although it can access the full dialogue history) and it is susceptible to hallucinated updates -- including updates that artificially inflate accuracies. Our findings suggest overall that ChatGPT is not currently equipped for robust tracking of situation states, and that trust in the impressive dialogue performance of ChatGPT comes with risks. We release the codebase for reproducing our test environment, as well as all prompts and API responses from ChatGPT, at https://github.com/yangalan123/SituationalTesting.
Clinical Decision Support System for Unani Medicine Practitioners
Oct 24, 2023
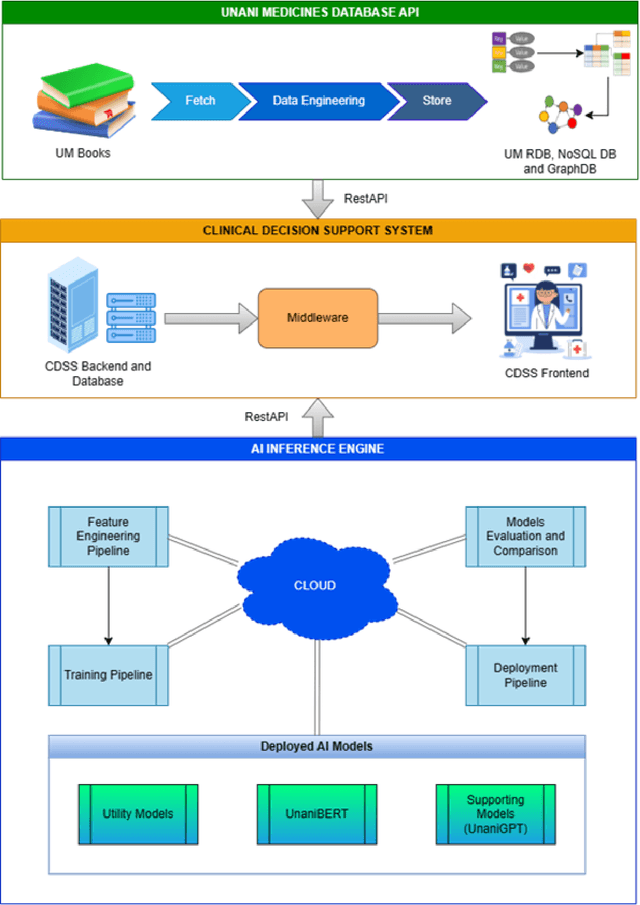
Like other fields of Traditional Medicines, Unani Medicines have been found as an effective medical practice for ages. It is still widely used in the subcontinent, particularly in Pakistan and India. However, Unani Medicines Practitioners are lacking modern IT applications in their everyday clinical practices. An Online Clinical Decision Support System may address this challenge to assist apprentice Unani Medicines practitioners in their diagnostic processes. The proposed system provides a web-based interface to enter the patient's symptoms, which are then automatically analyzed by our system to generate a list of probable diseases. The system allows practitioners to choose the most likely disease and inform patients about the associated treatment options remotely. The system consists of three modules: an Online Clinical Decision Support System, an Artificial Intelligence Inference Engine, and a comprehensive Unani Medicines Database. The system employs advanced AI techniques such as Decision Trees, Deep Learning, and Natural Language Processing. For system development, the project team used a technology stack that includes React, FastAPI, and MySQL. Data and functionality of the application is exposed using APIs for integration and extension with similar domain applications. The novelty of the project is that it addresses the challenge of diagnosing diseases accurately and efficiently in the context of Unani Medicines principles. By leveraging the power of technology, the proposed Clinical Decision Support System has the potential to ease access to healthcare services and information, reduce cost, boost practitioner and patient satisfaction, improve speed and accuracy of the diagnostic process, and provide effective treatments remotely. The application will be useful for Unani Medicines Practitioners, Patients, Government Drug Regulators, Software Developers, and Medical Researchers.
Rethinking Scale Imbalance in Semi-supervised Object Detection for Aerial Images
Oct 23, 2023This paper focuses on the scale imbalance problem of semi-supervised object detection(SSOD) in aerial images. Compared to natural images, objects in aerial images show smaller sizes and larger quantities per image, increasing the difficulty of manual annotation. Meanwhile, the advanced SSOD technique can train superior detectors by leveraging limited labeled data and massive unlabeled data, saving annotation costs. However, as an understudied task in aerial images, SSOD suffers from a drastic performance drop when facing a large proportion of small objects. By analyzing the predictions between small and large objects, we identify three imbalance issues caused by the scale bias, i.e., pseudo-label imbalance, label assignment imbalance, and negative learning imbalance. To tackle these issues, we propose a novel Scale-discriminative Semi-Supervised Object Detection (S^3OD) learning pipeline for aerial images. In our S^3OD, three key components, Size-aware Adaptive Thresholding (SAT), Size-rebalanced Label Assignment (SLA), and Teacher-guided Negative Learning (TNL), are proposed to warrant scale unbiased learning. Specifically, SAT adaptively selects appropriate thresholds to filter pseudo-labels for objects at different scales. SLA balances positive samples of objects at different scales through resampling and reweighting. TNL alleviates the imbalance in negative samples by leveraging information generated by a teacher model. Extensive experiments conducted on the DOTA-v1.5 benchmark demonstrate the superiority of our proposed methods over state-of-the-art competitors. Codes will be released soon.
P2AT: Pyramid Pooling Axial Transformer for Real-time Semantic Segmentation
Oct 23, 2023Recently, Transformer-based models have achieved promising results in various vision tasks, due to their ability to model long-range dependencies. However, transformers are computationally expensive, which limits their applications in real-time tasks such as autonomous driving. In addition, an efficient local and global feature selection and fusion are vital for accurate dense prediction, especially driving scene understanding tasks. In this paper, we propose a real-time semantic segmentation architecture named Pyramid Pooling Axial Transformer (P2AT). The proposed P2AT takes a coarse feature from the CNN encoder to produce scale-aware contextual features, which are then combined with the multi-level feature aggregation scheme to produce enhanced contextual features. Specifically, we introduce a pyramid pooling axial transformer to capture intricate spatial and channel dependencies, leading to improved performance on semantic segmentation. Then, we design a Bidirectional Fusion module (BiF) to combine semantic information at different levels. Meanwhile, a Global Context Enhancer is introduced to compensate for the inadequacy of concatenating different semantic levels. Finally, a decoder block is proposed to help maintain a larger receptive field. We evaluate P2AT variants on three challenging scene-understanding datasets. In particular, our P2AT variants achieve state-of-art results on the Camvid dataset 80.5%, 81.0%, 81.1% for P2AT-S, P2ATM, and P2AT-L, respectively. Furthermore, our experiment on Cityscapes and Pascal VOC 2012 have demonstrated the efficiency of the proposed architecture, with results showing that P2AT-M, achieves 78.7% on Cityscapes. The source code will be available at
Explainable Depression Symptom Detection in Social Media
Oct 23, 2023Users of social platforms often perceive these sites as supportive spaces to post about their mental health issues. Those conversations contain important traces about individuals' health risks. Recently, researchers have exploited this online information to construct mental health detection models, which aim to identify users at risk on platforms like Twitter, Reddit or Facebook. Most of these models are centred on achieving good classification results, ignoring the explainability and interpretability of the decisions. Recent research has pointed out the importance of using clinical markers, such as the use of symptoms, to improve trust in the computational models by health professionals. In this paper, we propose using transformer-based architectures to detect and explain the appearance of depressive symptom markers in the users' writings. We present two approaches: i) train a model to classify, and another one to explain the classifier's decision separately and ii) unify the two tasks simultaneously using a single model. Additionally, for this latter manner, we also investigated the performance of recent conversational LLMs when using in-context learning. Our natural language explanations enable clinicians to interpret the models' decisions based on validated symptoms, enhancing trust in the automated process. We evaluate our approach using recent symptom-based datasets, employing both offline and expert-in-the-loop metrics to assess the quality of the explanations generated by our models. The experimental results show that it is possible to achieve good classification results while generating interpretable symptom-based explanations.
HetGPT: Harnessing the Power of Prompt Tuning in Pre-Trained Heterogeneous Graph Neural Networks
Oct 23, 2023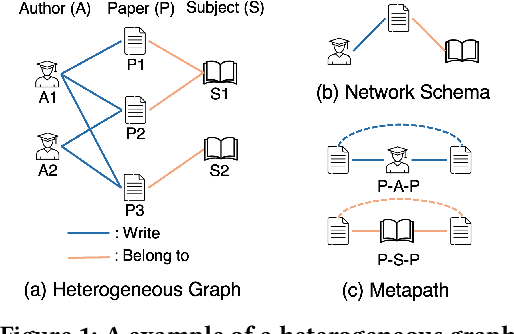
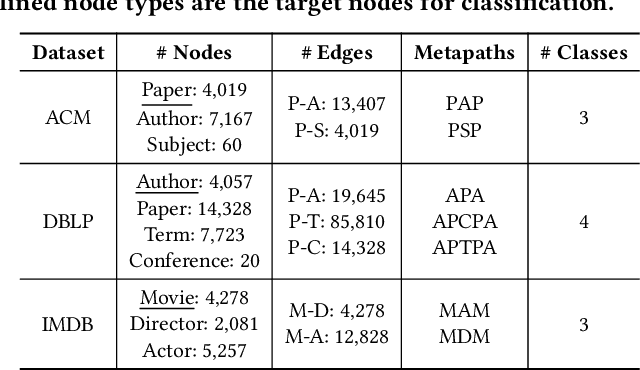

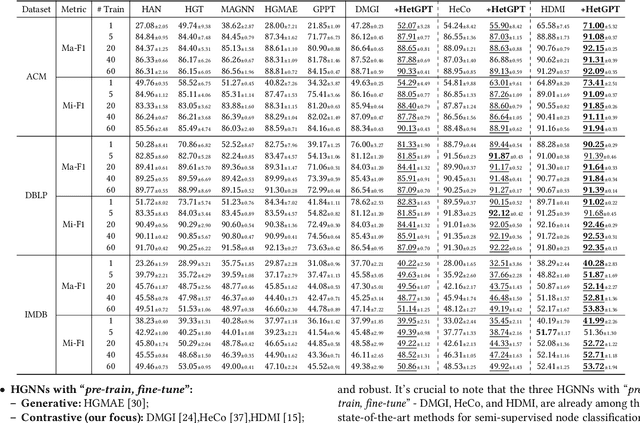
Graphs have emerged as a natural choice to represent and analyze the intricate patterns and rich information of the Web, enabling applications such as online page classification and social recommendation. The prevailing "pre-train, fine-tune" paradigm has been widely adopted in graph machine learning tasks, particularly in scenarios with limited labeled nodes. However, this approach often exhibits a misalignment between the training objectives of pretext tasks and those of downstream tasks. This gap can result in the "negative transfer" problem, wherein the knowledge gained from pre-training adversely affects performance in the downstream tasks. The surge in prompt-based learning within Natural Language Processing (NLP) suggests the potential of adapting a "pre-train, prompt" paradigm to graphs as an alternative. However, existing graph prompting techniques are tailored to homogeneous graphs, neglecting the inherent heterogeneity of Web graphs. To bridge this gap, we propose HetGPT, a general post-training prompting framework to improve the predictive performance of pre-trained heterogeneous graph neural networks (HGNNs). The key is the design of a novel prompting function that integrates a virtual class prompt and a heterogeneous feature prompt, with the aim to reformulate downstream tasks to mirror pretext tasks. Moreover, HetGPT introduces a multi-view neighborhood aggregation mechanism, capturing the complex neighborhood structure in heterogeneous graphs. Extensive experiments on three benchmark datasets demonstrate HetGPT's capability to enhance the performance of state-of-the-art HGNNs on semi-supervised node classification.
Inferring Power Grid Information with Power Line Communications: Review and Insights
Aug 21, 2023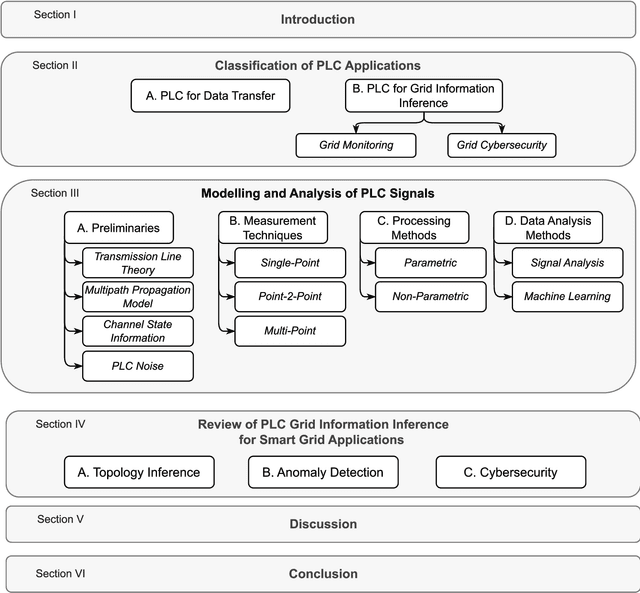
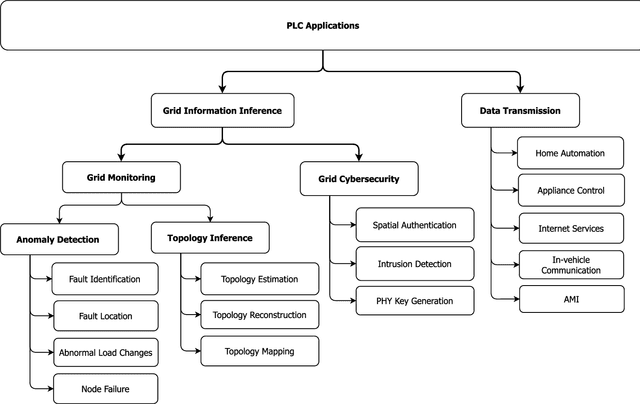
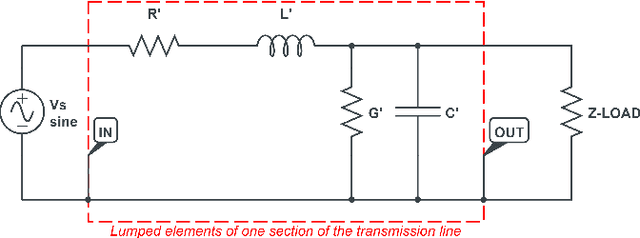
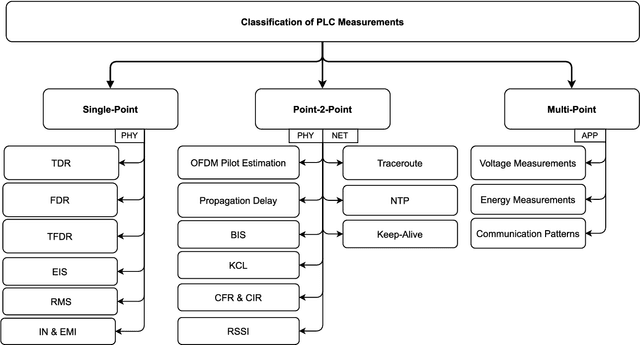
High-frequency signals were widely studied in the last decade to identify grid and channel conditions in PLNs. PLMs operating on the grid's physical layer are capable of transmitting such signals to infer information about the grid. Hence, PLC is a suitable communication technology for SG applications, especially suited for grid monitoring and surveillance. In this paper, we provide several contributions: 1) a classification of PLC-based applications; 2) a taxonomy of the related methodologies; 3) a review of the literature in the area of PLC Grid Information Inference (GII); and, insights that can be leveraged to further advance the field. We found research contributions addressing PLMs for three main PLC-GII applications: topology inference, anomaly detection, and physical layer key generation. In addition, various PLC-GII measurement, processing, and analysis approaches were found to provide distinctive features in measurement resolution, computation complexity, and analysis accuracy. We utilize the outcome of our review to shed light on the current limitations of the research contributions and suggest future research directions in this field.
Worst-Case Analysis is Maximum-A-Posteriori Estimation
Oct 15, 2023The worst-case resource usage of a program can provide useful information for many software-engineering tasks, such as performance optimization and algorithmic-complexity-vulnerability discovery. This paper presents a generic, adaptive, and sound fuzzing framework, called DSE-SMC, for estimating worst-case resource usage. DSE-SMC is generic because it is black-box as long as the user provides an interface for retrieving resource-usage information on a given input; adaptive because it automatically balances between exploration and exploitation of candidate inputs; and sound because it is guaranteed to converge to the true resource-usage distribution of the analyzed program. DSE-SMC is built upon a key observation: resource accumulation in a program is isomorphic to the soft-conditioning mechanism in Bayesian probabilistic programming; thus, worst-case resource analysis is isomorphic to the maximum-a-posteriori-estimation problem of Bayesian statistics. DSE-SMC incorporates sequential Monte Carlo (SMC) -- a generic framework for Bayesian inference -- with adaptive evolutionary fuzzing algorithms, in a sound manner, i.e., DSE-SMC asymptotically converges to the posterior distribution induced by resource-usage behavior of the analyzed program. Experimental evaluation on Java applications demonstrates that DSE-SMC is significantly more effective than existing black-box fuzzing methods for worst-case analysis.