 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unified Browsing Models for Linear and Grid Layouts
Oct 19, 2023
Many information access systems operationalize their results in terms of rankings, which are then displayed to users in various ranking layouts such as linear lists or grids. User interaction with a retrieved item is highly dependent on the item's position in the layout, and users do not provide similar attention to every position in ranking (under any layout model). User attention is an important component in the evaluation process of ranking, due to its use in effectiveness metrics that estimate utility as well as fairness metrics that evaluate ranking based on social and ethical concerns. These metrics take user browsing behavior into account in their measurement strategies to estimate the attention the user is likely to provide to each item in ranking. Research on understanding user browsing behavior has proposed several user browsing models, and further observed that user browsing behavior differs with different ranking layouts. However, the underlying concepts of these browsing models are often similar, including varying components and parameter settings. We seek to leverage that similarity to represent multiple browsing models in a generalized, configurable framework which can be further extended to more complex ranking scenarios. In this paper, we describe a probabilistic user browsing model for linear rankings, show how they can be configured to yield models commonly used in current evaluation practice, and generalize this model to also account for browsing behaviors in grid-based layouts. This model provides configurable framework for estimating the attention that results from user browsing activity for a range of IR evaluation and measurement applications in multiple formats, and also identifies parameters that need to be estimated through user studies to provide realistic evaluation beyond ranked lists.
Conditional Generative Modeling for Images, 3D Animations, and Video
Oct 19, 2023
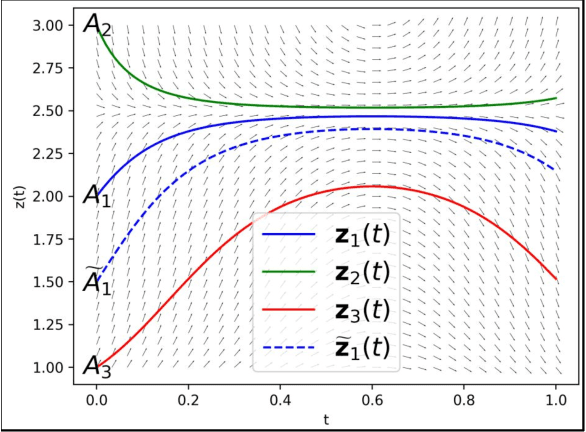

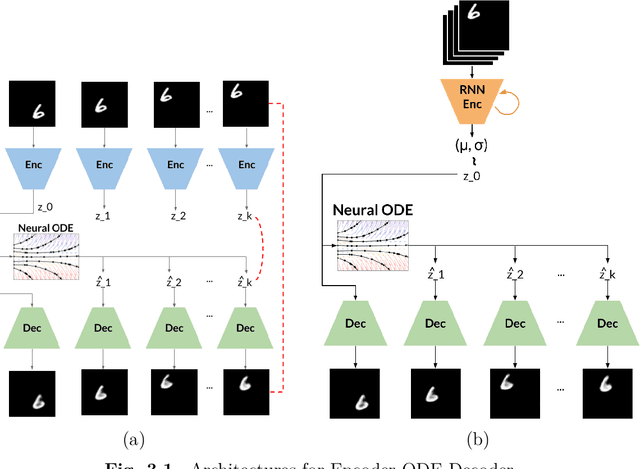
This dissertation attempts to drive innovation in the field of generative modeling for computer vision, by exploring novel formulations of conditional generative models, and innovative applications in images, 3D animations, and video. Our research focuses on architectures that offer reversible transformations of noise and visual data, and the application of encoder-decoder architectures for generative tasks and 3D content manipulation. In all instances, we incorporate conditional information to enhance the synthesis of visual data, improving the efficiency of the generation process as well as the generated content. We introduce the use of Neural ODEs to model video dynamics using an encoder-decoder architecture, demonstrating their ability to predict future video frames despite being trained solely to reconstruct current frames. Next, we propose a conditional variant of continuous normalizing flows that enables higher-resolution image generation based on lower-resolution input, achieving comparable image quality while reducing parameters and training time. Our next contribution presents a pipeline that takes human images as input, automatically aligns a user-specified 3D character with the pose of the human, and facilitates pose editing based on partial inputs. Next, we derive the relevant mathematical details for denoising diffusion models that use non-isotropic Gaussian processes, and show comparable generation quality. Finally, we devise a novel denoising diffusion framework capable of solving all three video tasks of prediction, generation, and interpolation. We perform ablation studies, and show SOTA results on multiple datasets. Our contributions are published articles at peer-reviewed venues. Overall, our research aims to make a meaningful contribution to the pursuit of more efficient and flexible generative models, with the potential to shape the future of computer vision.
Joint object detection and re-identification for 3D obstacle multi-camera systems
Oct 09, 2023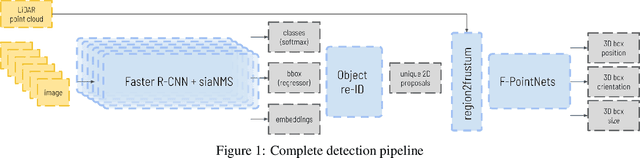
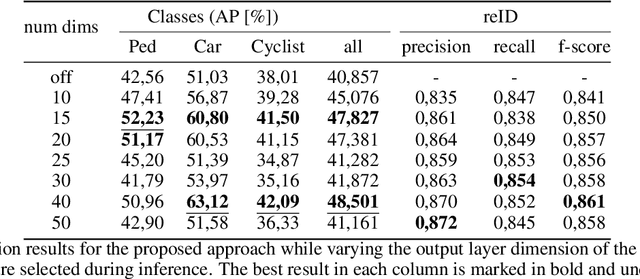
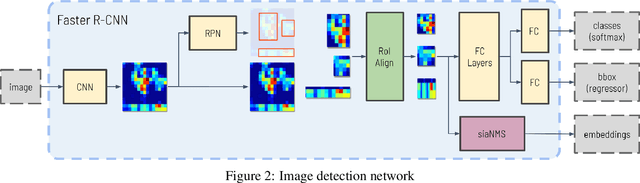
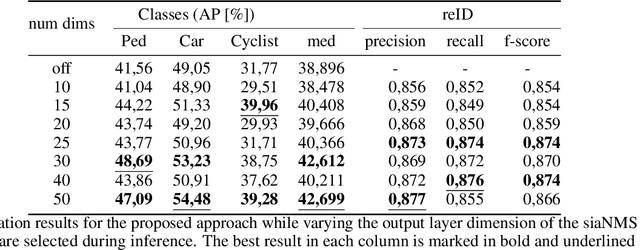
In recent years, the field of autonomous driving has witnessed remarkable advancements, driven by the integration of a multitude of sensors, including cameras and LiDAR systems, in different prototypes. However, with the proliferation of sensor data comes the pressing need for more sophisticated information processing techniques. This research paper introduces a novel modification to an object detection network that uses camera and lidar information, incorporating an additional branch designed for the task of re-identifying objects across adjacent cameras within the same vehicle while elevating the quality of the baseline 3D object detection outcomes. The proposed methodology employs a two-step detection pipeline: initially, an object detection network is employed, followed by a 3D box estimator that operates on the filtered point cloud generated from the network's detections. Extensive experimental evaluations encompassing both 2D and 3D domains validate the effectiveness of the proposed approach and the results underscore the superiority of this method over traditional Non-Maximum Suppression (NMS) techniques, with an improvement of more than 5\% in the car category in the overlapping areas.
IRAD: Implicit Representation-driven Image Resampling against Adversarial Attacks
Oct 18, 2023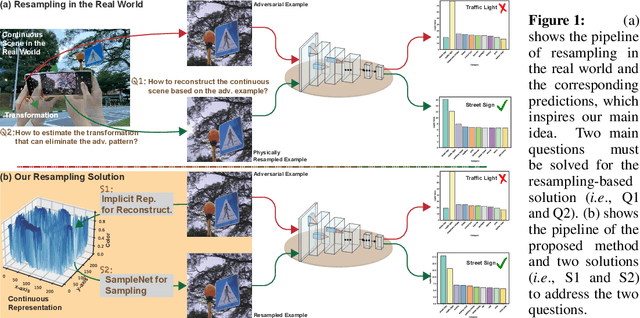
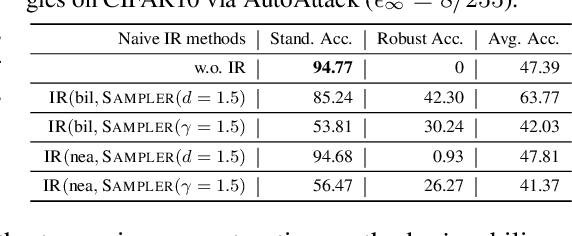
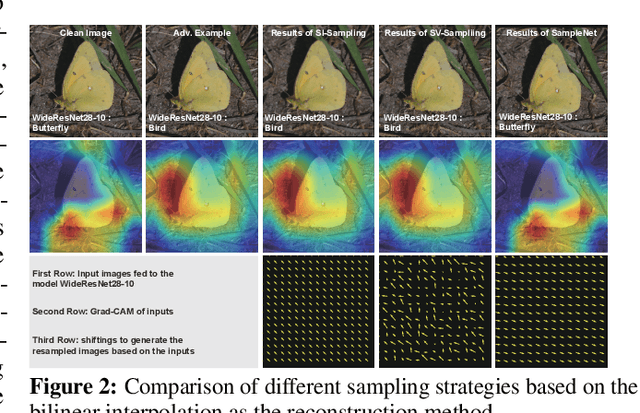
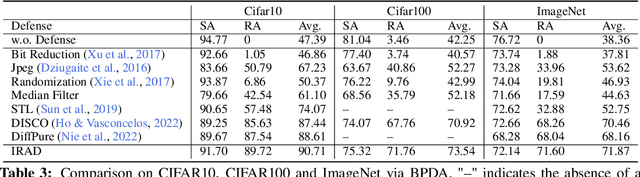
We introduce a novel approach to counter adversarial attacks, namely, image resampling. Image resampling transforms a discrete image into a new one, simulating the process of scene recapturing or rerendering as specified by a geometrical transformation. The underlying rationale behind our idea is that image resampling can alleviate the influence of adversarial perturbations while preserving essential semantic information, thereby conferring an inherent advantage in defending against adversarial attacks. To validate this concept, we present a comprehensive study on leveraging image resampling to defend against adversarial attacks. We have developed basic resampling methods that employ interpolation strategies and coordinate shifting magnitudes. Our analysis reveals that these basic methods can partially mitigate adversarial attacks. However, they come with apparent limitations: the accuracy of clean images noticeably decreases, while the improvement in accuracy on adversarial examples is not substantial. We propose implicit representation-driven image resampling (IRAD) to overcome these limitations. First, we construct an implicit continuous representation that enables us to represent any input image within a continuous coordinate space. Second, we introduce SampleNet, which automatically generates pixel-wise shifts for resampling in response to different inputs. Furthermore, we can extend our approach to the state-of-the-art diffusion-based method, accelerating it with fewer time steps while preserving its defense capability. Extensive experiments demonstrate that our method significantly enhances the adversarial robustness of diverse deep models against various attacks while maintaining high accuracy on clean images.
Perceptual Measurements, Distances and Metrics
Oct 18, 2023Perception is often viewed as a process that transforms physical variables, external to an observer, into internal psychological variables. Such a process can be modeled by a function coined perceptual scale. The perceptual scale can be deduced from psychophysical measurements that consist in comparing the relative differences between stimuli (i.e. difference scaling experiments). However, this approach is often overlooked by the modeling and experimentation communities. Here, we demonstrate the value of measuring the perceptual scale of classical (spatial frequency, orientation) and less classical physical variables (interpolation between textures) by embedding it in recent probabilistic modeling of perception. First, we show that the assumption that an observer has an internal representation of univariate parameters such as spatial frequency or orientation while stimuli are high-dimensional does not lead to contradictory predictions when following the theoretical framework. Second, we show that the measured perceptual scale corresponds to the transduction function hypothesized in this framework. In particular, we demonstrate that it is related to the Fisher information of the generative model that underlies perception and we test the predictions given by the generative model of different stimuli in a set a of difference scaling experiments. Our main conclusion is that the perceptual scale is mostly driven by the stimulus power spectrum. Finally, we propose that this measure of perceptual scale is a way to push further the notion of perceptual distances by estimating the perceptual geometry of images i.e. the path between images instead of simply the distance between those.
Federated Heterogeneous Graph Neural Network for Privacy-preserving Recommendation
Oct 18, 2023Heterogeneous information network (HIN), which contains rich semantics depicted by meta-paths, has become a powerful tool to alleviate data sparsity in recommender systems. Existing HIN-based recommendations hold the data centralized storage assumption and conduct centralized model training. However, the real-world data is often stored in a distributed manner for privacy concerns, resulting in the failure of centralized HIN-based recommendations. In this paper, we suggest the HIN is partitioned into private HINs stored in the client side and shared HINs in the server. Following this setting, we propose a federated heterogeneous graph neural network (FedHGNN) based framework, which can collaboratively train a recommendation model on distributed HINs without leaking user privacy. Specifically, we first formalize the privacy definition in the light of differential privacy for HIN-based federated recommendation, which aims to protect user-item interactions of private HIN as well as user's high-order patterns from shared HINs. To recover the broken meta-path based semantics caused by distributed data storage and satisfy the proposed privacy, we elaborately design a semantic-preserving user interactions publishing method, which locally perturbs user's high-order patterns as well as related user-item interactions for publishing. After that, we propose a HGNN model for recommendation, which conducts node- and semantic-level aggregations to capture recovered semantics. Extensive experiments on three datasets demonstrate our model outperforms existing methods by a large margin (up to 34% in HR@10 and 42% in NDCG@10) under an acceptable privacy budget.
Revisiting Mobility Modeling with Graph: A Graph Transformer Model for Next Point-of-Interest Recommendation
Oct 02, 2023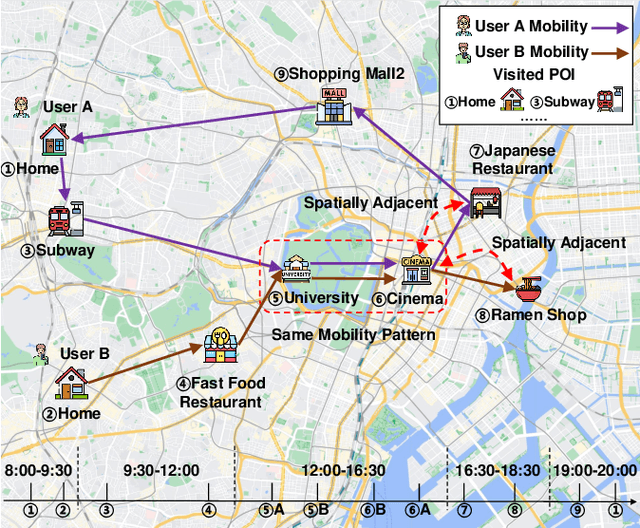
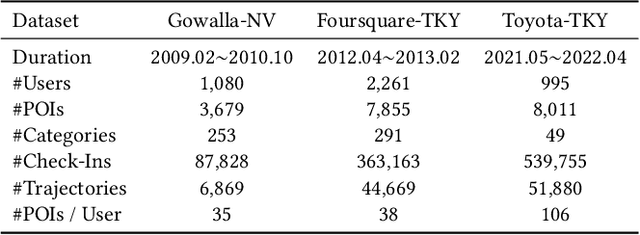
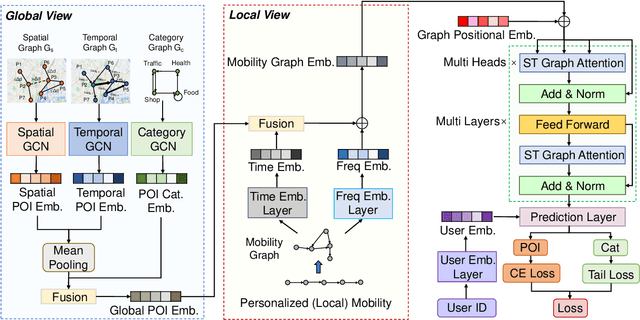
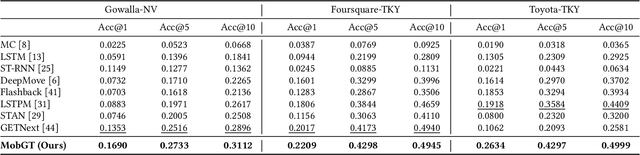
Next Point-of-Interest (POI) recommendation plays a crucial role in urban mobility applications. Recently, POI recommendation models based on Graph Neural Networks (GNN) have been extensively studied and achieved, however, the effective incorporation of both spatial and temporal information into such GNN-based models remains challenging. Extracting distinct fine-grained features unique to each piece of information is difficult since temporal information often includes spatial information, as users tend to visit nearby POIs. To address the challenge, we propose \textbf{\underline{Mob}}ility \textbf{\underline{G}}raph \textbf{\underline{T}}ransformer (MobGT) that enables us to fully leverage graphs to capture both the spatial and temporal features in users' mobility patterns. MobGT combines individual spatial and temporal graph encoders to capture unique features and global user-location relations. Additionally, it incorporates a mobility encoder based on Graph Transformer to extract higher-order information between POIs. To address the long-tailed problem in spatial-temporal data, MobGT introduces a novel loss function, Tail Loss. Experimental results demonstrate that MobGT outperforms state-of-the-art models on various datasets and metrics, achieving 24\% improvement on average. Our codes are available at \url{https://github.com/Yukayo/MobGT}.
Multi-Dimension-Embedding-Aware Modality Fusion Transformer for Psychiatric Disorder Clasification
Oct 04, 2023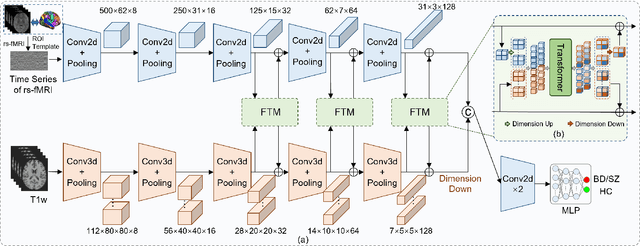
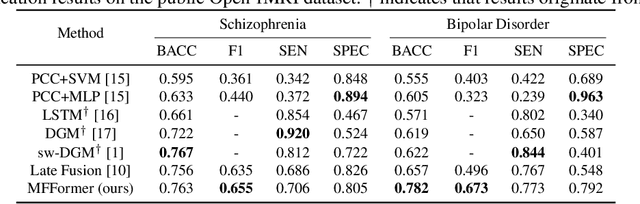
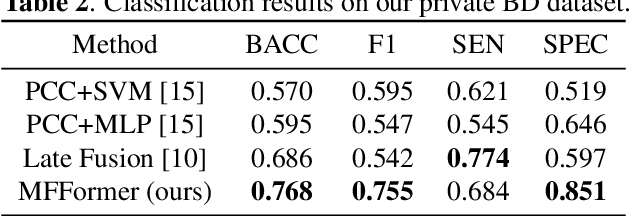
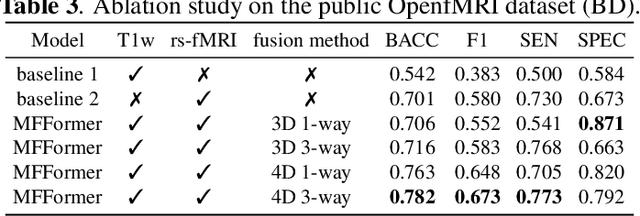
Deep learning approaches, together with neuroimaging techniques, play an important role in psychiatric disorders classification. Previous studies on psychiatric disorders diagnosis mainly focus on using functional connectivity matrices of resting-state functional magnetic resonance imaging (rs-fMRI) as input, which still needs to fully utilize the rich temporal information of the time series of rs-fMRI data. In this work, we proposed a multi-dimension-embedding-aware modality fusion transformer (MFFormer) for schizophrenia and bipolar disorder classification using rs-fMRI and T1 weighted structural MRI (T1w sMRI). Concretely, to fully utilize the temporal information of rs-fMRI and spatial information of sMRI, we constructed a deep learning architecture that takes as input 2D time series of rs-fMRI and 3D volumes T1w. Furthermore, to promote intra-modality attention and information fusion across different modalities, a fusion transformer module (FTM) is designed through extensive self-attention of hybrid feature maps of multi-modality. In addition, a dimension-up and dimension-down strategy is suggested to properly align feature maps of multi-dimensional from different modalities. Experimental results on our private and public OpenfMRI datasets show that our proposed MFFormer performs better than that using a single modality or multi-modality MRI on schizophrenia and bipolar disorder diagnosis.
Large Language Models Meet Knowledge Graphs to Answer Factoid Questions
Oct 03, 2023
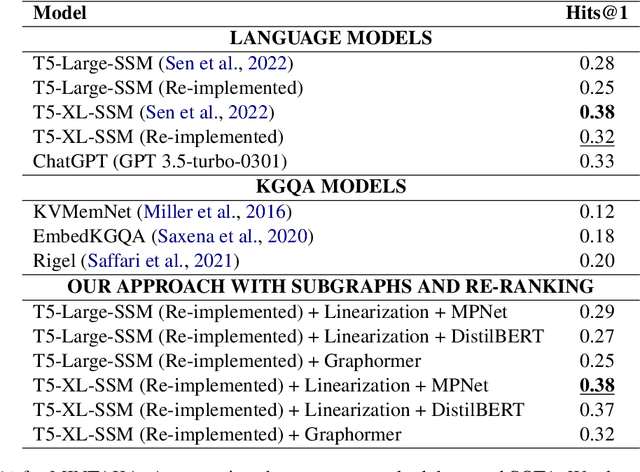
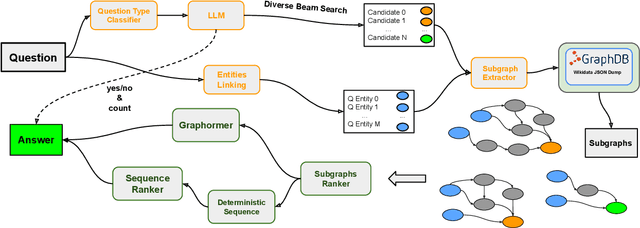
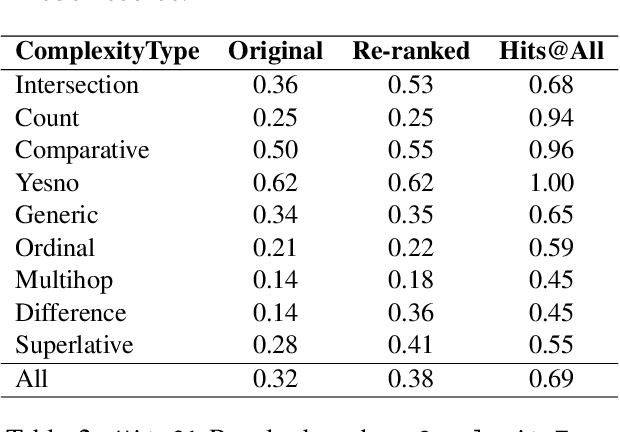
Recently, it has been shown that the incorporation of structured knowledge into Large Language Models significantly improves the results for a variety of NLP tasks. In this paper, we propose a method for exploring pre-trained Text-to-Text Language Models enriched with additional information from Knowledge Graphs for answering factoid questions. More specifically, we propose an algorithm for subgraphs extraction from a Knowledge Graph based on question entities and answer candidates. Then, we procure easily interpreted information with Transformer-based models through the linearization of the extracted subgraphs. Final re-ranking of the answer candidates with the extracted information boosts Hits@1 scores of the pre-trained text-to-text language models by 4-6%.
X-ray phase and dark-field computed tomography without optical elements
Oct 14, 2023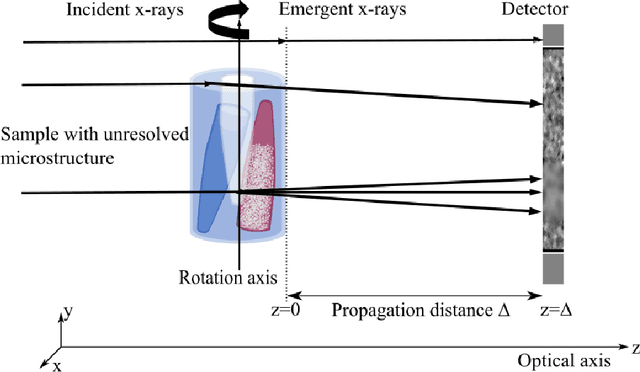
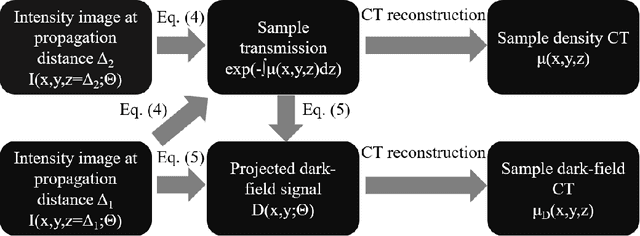
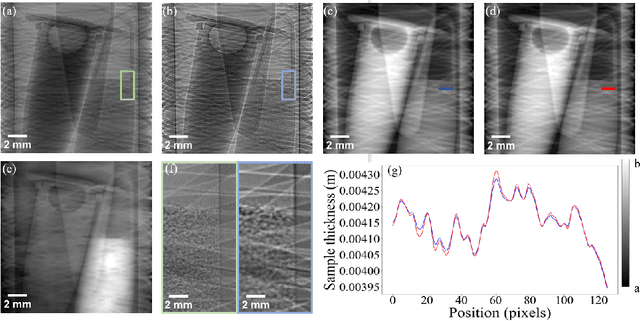
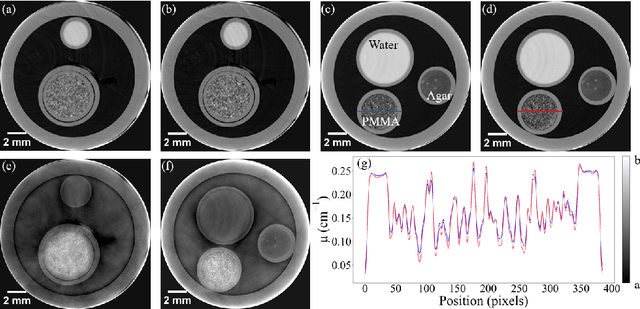
X-ray diffusive dark-field imaging, which allows spatially unresolved microstructure to be mapped across a sample, is an increasingly popular tool in an array of settings. Here, we present a new algorithm for phase and dark-field computed tomography based on the x-ray Fokker-Planck equation. Needing only a coherent x-ray source, sample, and detector, our propagation-based algorithm can map the sample density and dark-field/diffusion properties of the sample in 3D. Importantly, incorporating dark-field information in the density reconstruction process enables a higher spatial resolution reconstruction than possible with previous propagation-based approaches. Two sample exposures at each projection angle are sufficient for the successful reconstruction of both the sample density and dark-field Fokker-Planck diffusion coefficients. We anticipate that the proposed algorithm may be of benefit in biomedical imaging and industrial settings.