 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DetectGPT-SC: Improving Detection of Text Generated by Large Language Models through Self-Consistency with Masked Predictions
Oct 23, 2023
General large language models (LLMs) such as ChatGPT have shown remarkable success, but it has also raised concerns among people about the misuse of AI-generated texts. Therefore, an important question is how to detect whether the texts are generated by ChatGPT or by humans. Existing detectors are built on the assumption that there is a distribution gap between human-generated and AI-generated texts. These gaps are typically identified using statistical information or classifiers. In contrast to prior research methods, we find that large language models such as ChatGPT exhibit strong self-consistency in text generation and continuation. Self-consistency capitalizes on the intuition that AI-generated texts can still be reasoned with by large language models using the same logical reasoning when portions of the texts are masked, which differs from human-generated texts. Using this observation, we subsequently proposed a new method for AI-generated texts detection based on self-consistency with masked predictions to determine whether a text is generated by LLMs. This method, which we call DetectGPT-SC. We conducted a series of experiments to evaluate the performance of DetectGPT-SC. In these experiments, we employed various mask scheme, zero-shot, and simple prompt for completing masked texts and self-consistency predictions. The results indicate that DetectGPT-SC outperforms the current state-of-the-art across different tasks.
Handling Data Heterogeneity via Architectural Design for Federated Visual Recognition
Oct 23, 2023Federated Learning (FL) is a promising research paradigm that enables the collaborative training of machine learning models among various parties without the need for sensitive information exchange. Nonetheless, retaining data in individual clients introduces fundamental challenges to achieving performance on par with centrally trained models. Our study provides an extensive review of federated learning applied to visual recognition. It underscores the critical role of thoughtful architectural design choices in achieving optimal performance, a factor often neglected in the FL literature. Many existing FL solutions are tested on shallow or simple networks, which may not accurately reflect real-world applications. This practice restricts the transferability of research findings to large-scale visual recognition models. Through an in-depth analysis of diverse cutting-edge architectures such as convolutional neural networks, transformers, and MLP-mixers, we experimentally demonstrate that architectural choices can substantially enhance FL systems' performance, particularly when handling heterogeneous data. We study 19 visual recognition models from five different architectural families on four challenging FL datasets. We also re-investigate the inferior performance of convolution-based architectures in the FL setting and analyze the influence of normalization layers on the FL performance. Our findings emphasize the importance of architectural design for computer vision tasks in practical scenarios, effectively narrowing the performance gap between federated and centralized learning. Our source code is available at https://github.com/sarapieri/fed_het.git.
ESVAE: An Efficient Spiking Variational Autoencoder with Reparameterizable Poisson Spiking Sampling
Oct 23, 2023In recent years, studies on image generation models of spiking neural networks (SNNs) have gained the attention of many researchers. Variational autoencoders (VAEs), as one of the most popular image generation models, have attracted a lot of work exploring their SNN implementation. Due to the constrained binary representation in SNNs, existing SNN VAE methods implicitly construct the latent space by an elaborated autoregressive network and use the network outputs as the sampling variables. However, this unspecified implicit representation of the latent space will increase the difficulty of generating high-quality images and introduces additional network parameters. In this paper, we propose an efficient spiking variational autoencoder (ESVAE) that constructs an interpretable latent space distribution and design a reparameterizable spiking sampling method. Specifically, we construct the prior and posterior of the latent space as a Poisson distribution using the firing rate of the spiking neurons. Subsequently, we propose a reparameterizable Poisson spiking sampling method, which is free from the additional network. Comprehensive experiments have been conducted, and the experimental results show that the proposed ESVAE outperforms previous SNN VAE methods in reconstructed & generated images quality. In addition, experiments demonstrate that ESVAE's encoder is able to retain the original image information more efficiently, and the decoder is more robust. The source code is available at https://github.com/QgZhan/ESVAE.
Harnessing Attention Mechanisms: Efficient Sequence Reduction using Attention-based Autoencoders
Oct 23, 2023Many machine learning models use the manipulation of dimensions as a driving force to enable models to identify and learn important features in data. In the case of sequential data this manipulation usually happens on the token dimension level. Despite the fact that many tasks require a change in sequence length itself, the step of sequence length reduction usually happens out of necessity and in a single step. As far as we are aware, no model uses the sequence length reduction step as an additional opportunity to tune the models performance. In fact, sequence length manipulation as a whole seems to be an overlooked direction. In this study we introduce a novel attention-based method that allows for the direct manipulation of sequence lengths. To explore the method's capabilities, we employ it in an autoencoder model. The autoencoder reduces the input sequence to a smaller sequence in latent space. It then aims to reproduce the original sequence from this reduced form. In this setting, we explore the methods reduction performance for different input and latent sequence lengths. We are able to show that the autoencoder retains all the significant information when reducing the original sequence to half its original size. When reducing down to as low as a quarter of its original size, the autoencoder is still able to reproduce the original sequence with an accuracy of around 90%.
Investigating the Fairness of Large Language Models for Predictions on Tabular Data
Oct 23, 2023Recent literature has suggested the potential of using large language models (LLMs) to make predictions for tabular tasks. However, LLMs have been shown to exhibit harmful social biases that reflect the stereotypes and inequalities present in the society. To this end, as well as the widespread use of tabular data in many high-stake applications, it is imperative to explore the following questions: what sources of information do LLMs draw upon when making predictions for tabular tasks; whether and to what extent are LLM predictions for tabular tasks influenced by social biases and stereotypes; and what are the consequential implications for fairness? Through a series of experiments, we delve into these questions and show that LLMs tend to inherit social biases from their training data which significantly impact their fairness in tabular prediction tasks. Furthermore, our investigations show that in the context of bias mitigation, though in-context learning and fine-tuning have a moderate effect, the fairness metric gap between different subgroups is still larger than that in traditional machine learning models, such as Random Forest and shallow Neural Networks. This observation emphasizes that the social biases are inherent within the LLMs themselves and inherited from their pre-training corpus, not only from the downstream task datasets. Besides, we demonstrate that label-flipping of in-context examples can significantly reduce biases, further highlighting the presence of inherent bias within LLMs.
Robust Representation Learning for Unified Online Top-K Recommendation
Oct 24, 2023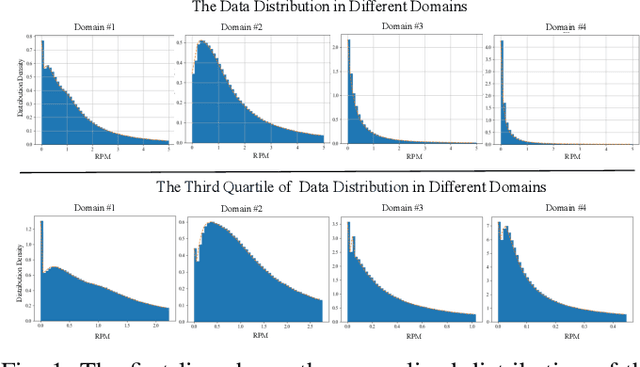
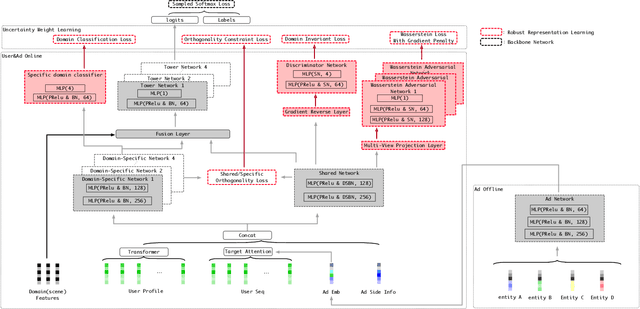
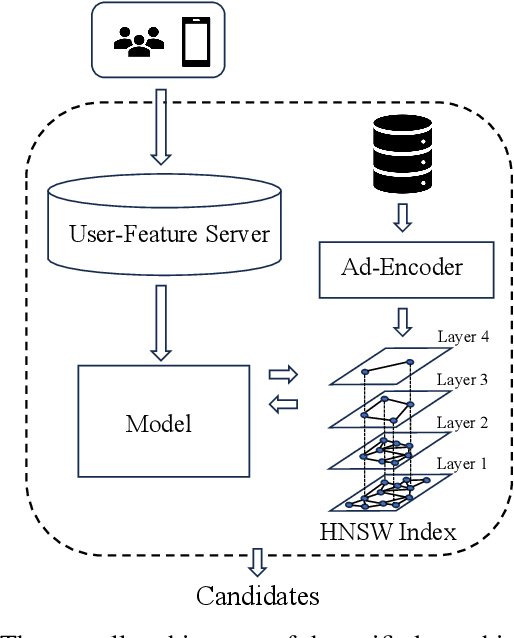
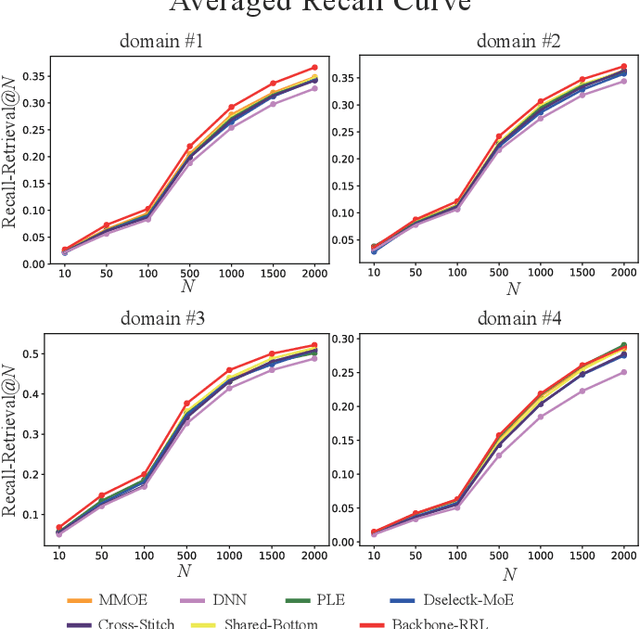
In large-scale industrial e-commerce, the efficiency of an online recommendation system is crucial in delivering highly relevant item/content advertising that caters to diverse business scenarios. However, most existing studies focus solely on item advertising, neglecting the significance of content advertising. This oversight results in inconsistencies within the multi-entity structure and unfair retrieval. Furthermore, the challenge of retrieving top-k advertisements from multi-entity advertisements across different domains adds to the complexity. Recent research proves that user-entity behaviors within different domains exhibit characteristics of differentiation and homogeneity. Therefore, the multi-domain matching models typically rely on the hybrid-experts framework with domain-invariant and domain-specific representations. Unfortunately, most approaches primarily focus on optimizing the combination mode of different experts, failing to address the inherent difficulty in optimizing the expert modules themselves. The existence of redundant information across different domains introduces interference and competition among experts, while the distinct learning objectives of each domain lead to varying optimization challenges among experts. To tackle these issues, we propose robust representation learning for the unified online top-k recommendation. Our approach constructs unified modeling in entity space to ensure data fairness. The robust representation learning employs domain adversarial learning and multi-view wasserstein distribution learning to learn robust representations. Moreover, the proposed method balances conflicting objectives through the homoscedastic uncertainty weights and orthogonality constraints. Various experiments validate the effectiveness and rationality of our proposed method, which has been successfully deployed online to serve real business scenarios.
Open-source Large Language Models are Strong Zero-shot Query Likelihood Models for Document Ranking
Oct 20, 2023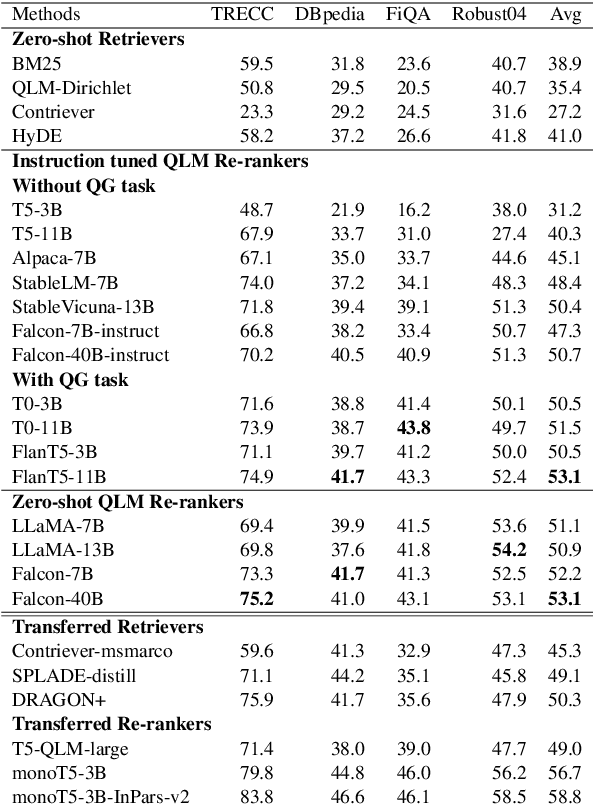
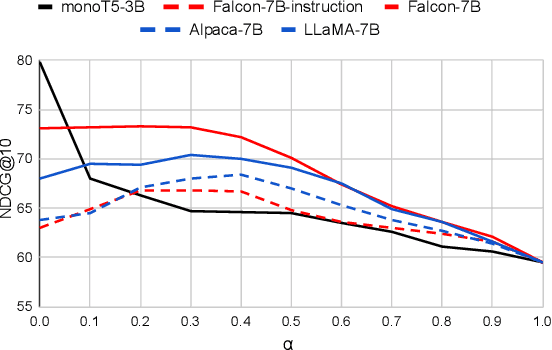
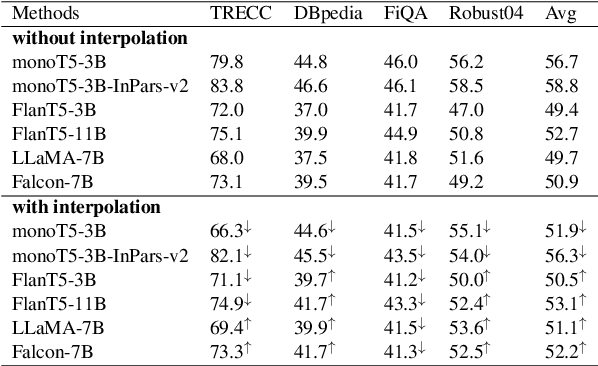
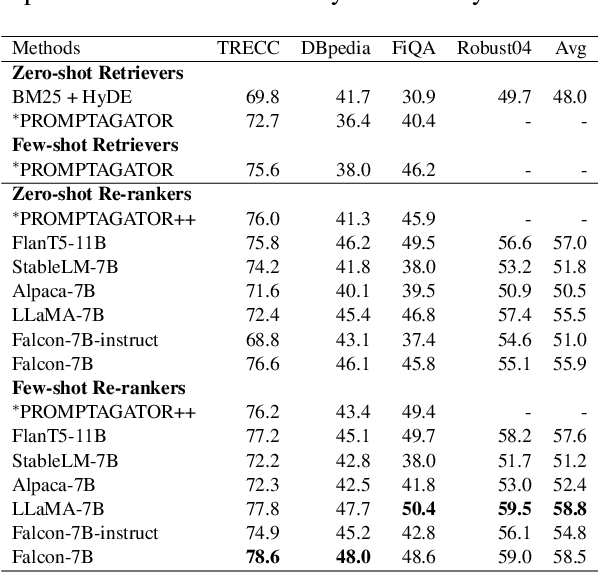
In the field of information retrieval, Query Likelihood Models (QLMs) rank documents based on the probability of generating the query given the content of a document. Recently, advanced large language models (LLMs) have emerged as effective QLMs, showcasing promising ranking capabilities. This paper focuses on investigating the genuine zero-shot ranking effectiveness of recent LLMs, which are solely pre-trained on unstructured text data without supervised instruction fine-tuning. Our findings reveal the robust zero-shot ranking ability of such LLMs, highlighting that additional instruction fine-tuning may hinder effectiveness unless a question generation task is present in the fine-tuning dataset. Furthermore, we introduce a novel state-of-the-art ranking system that integrates LLM-based QLMs with a hybrid zero-shot retriever, demonstrating exceptional effectiveness in both zero-shot and few-shot scenarios. We make our codebase publicly available at https://github.com/ielab/llm-qlm.
Assessing Privacy Risks in Language Models: A Case Study on Summarization Tasks
Oct 20, 2023Large language models have revolutionized the field of NLP by achieving state-of-the-art performance on various tasks. However, there is a concern that these models may disclose information in the training data. In this study, we focus on the summarization task and investigate the membership inference (MI) attack: given a sample and black-box access to a model's API, it is possible to determine if the sample was part of the training data. We exploit text similarity and the model's resistance to document modifications as potential MI signals and evaluate their effectiveness on widely used datasets. Our results demonstrate that summarization models are at risk of exposing data membership, even in cases where the reference summary is not available. Furthermore, we discuss several safeguards for training summarization models to protect against MI attacks and discuss the inherent trade-off between privacy and utility.
Unraveling the Enigma of Double Descent: An In-depth Analysis through the Lens of Learned Feature Space
Oct 20, 2023Double descent presents a counter-intuitive aspect within the machine learning domain, and researchers have observed its manifestation in various models and tasks. While some theoretical explanations have been proposed for this phenomenon in specific contexts, an accepted theory to account for its occurrence in deep learning remains yet to be established. In this study, we revisit the phenomenon of double descent and demonstrate that its occurrence is strongly influenced by the presence of noisy data. Through conducting a comprehensive analysis of the feature space of learned representations, we unveil that double descent arises in imperfect models trained with noisy data. We argue that double descent is a consequence of the model first learning the noisy data until interpolation and then adding implicit regularization via over-parameterization acquiring therefore capability to separate the information from the noise. We postulate that double descent should never occur in well-regularized models.
MeaeQ: Mount Model Extraction Attacks with Efficient Queries
Oct 21, 2023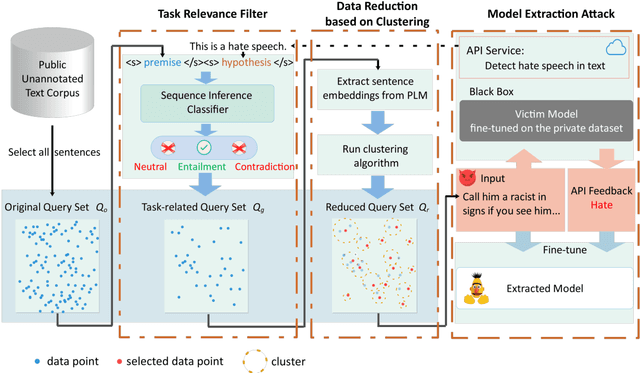
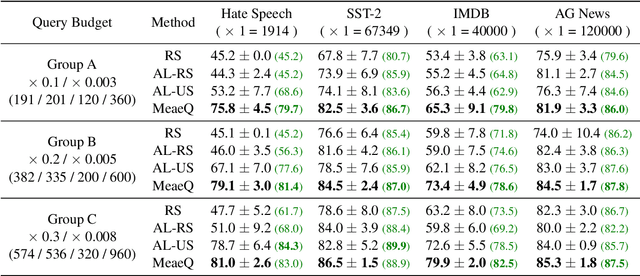
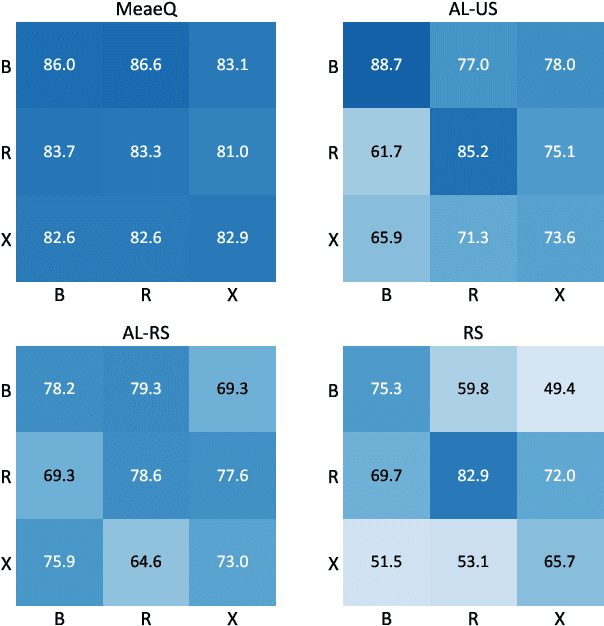

We study model extraction attacks in natural language processing (NLP) where attackers aim to steal victim models by repeatedly querying the open Application Programming Interfaces (APIs). Recent works focus on limited-query budget settings and adopt random sampling or active learning-based sampling strategies on publicly available, unannotated data sources. However, these methods often result in selected queries that lack task relevance and data diversity, leading to limited success in achieving satisfactory results with low query costs. In this paper, we propose MeaeQ (Model extraction attack with efficient Queries), a straightforward yet effective method to address these issues. Specifically, we initially utilize a zero-shot sequence inference classifier, combined with API service information, to filter task-relevant data from a public text corpus instead of a problem domain-specific dataset. Furthermore, we employ a clustering-based data reduction technique to obtain representative data as queries for the attack. Extensive experiments conducted on four benchmark datasets demonstrate that MeaeQ achieves higher functional similarity to the victim model than baselines while requiring fewer queries. Our code is available at https://github.com/C-W-D/MeaeQ.