 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Context-aware feature attribution through argumentation
Oct 24, 2023
Feature attribution is a fundamental task in both machine learning and data analysis, which involves determining the contribution of individual features or variables to a model's output. This process helps identify the most important features for predicting an outcome. The history of feature attribution methods can be traced back to General Additive Models (GAMs), which extend linear regression models by incorporating non-linear relationships between dependent and independent variables. In recent years, gradient-based methods and surrogate models have been applied to unravel complex Artificial Intelligence (AI) systems, but these methods have limitations. GAMs tend to achieve lower accuracy, gradient-based methods can be difficult to interpret, and surrogate models often suffer from stability and fidelity issues. Furthermore, most existing methods do not consider users' contexts, which can significantly influence their preferences. To address these limitations and advance the current state-of-the-art, we define a novel feature attribution framework called Context-Aware Feature Attribution Through Argumentation (CA-FATA). Our framework harnesses the power of argumentation by treating each feature as an argument that can either support, attack or neutralize a prediction. Additionally, CA-FATA formulates feature attribution as an argumentation procedure, and each computation has explicit semantics, which makes it inherently interpretable. CA-FATA also easily integrates side information, such as users' contexts, resulting in more accurate predictions.
Locally Differentially Private Gradient Tracking for Distributed Online Learning over Directed Graphs
Oct 24, 2023Distributed online learning has been proven extremely effective in solving large-scale machine learning problems involving streaming data. However, information sharing between learners in distributed learning also raises concerns about the potential leakage of individual learners' sensitive data. To mitigate this risk, differential privacy, which is widely regarded as the "gold standard" for privacy protection, has been widely employed in many existing results on distributed online learning. However, these results often face a fundamental tradeoff between learning accuracy and privacy. In this paper, we propose a locally differentially private gradient tracking based distributed online learning algorithm that successfully circumvents this tradeoff. Our analysis shows that the proposed algorithm converges in mean square to the exact optimal solution while ensuring rigorous local differential privacy, with the cumulative privacy budget guaranteed to be finite even when the number of iterations tends to infinity. The algorithm is applicable even when the communication graph among learners is directed. To the best of our knowledge, this is the first result that simultaneously ensures learning accuracy and rigorous local differential privacy in distributed online learning over directed graphs. We evaluate our algorithm's performance by using multiple benchmark machine-learning applications, including logistic regression on the "Mushrooms" dataset and CNN-based image classification on the "MNIST" and "CIFAR-10" datasets, respectively. The experimental results confirm that the proposed algorithm outperforms existing counterparts in both training and testing accuracies.
A Risk-Averse Framework for Non-Stationary Stochastic Multi-Armed Bandits
Oct 24, 2023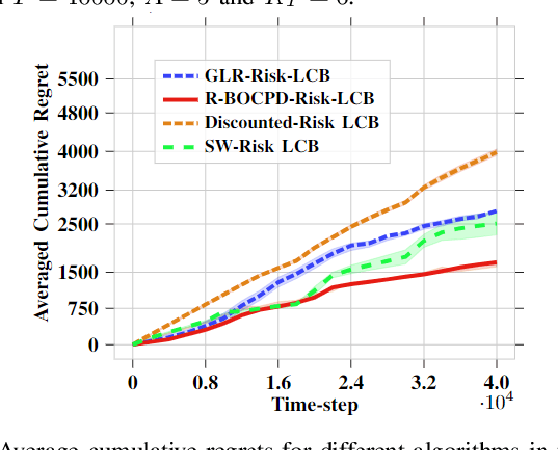
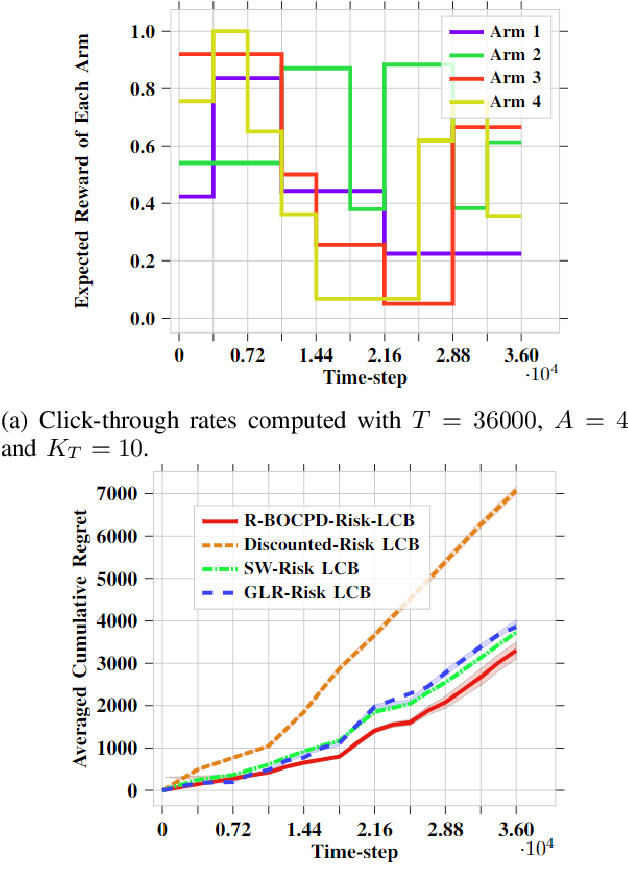
In a typical stochastic multi-armed bandit problem, the objective is often to maximize the expected sum of rewards over some time horizon $T$. While the choice of a strategy that accomplishes that is optimal with no additional information, it is no longer the case when provided additional environment-specific knowledge. In particular, in areas of high volatility like healthcare or finance, a naive reward maximization approach often does not accurately capture the complexity of the learning problem and results in unreliable solutions. To tackle problems of this nature, we propose a framework of adaptive risk-aware strategies that operate in non-stationary environments. Our framework incorporates various risk measures prevalent in the literature to map multiple families of multi-armed bandit algorithms into a risk-sensitive setting. In addition, we equip the resulting algorithms with the Restarted Bayesian Online Change-Point Detection (R-BOCPD) algorithm and impose a (tunable) forced exploration strategy to detect local (per-arm) switches. We provide finite-time theoretical guarantees and an asymptotic regret bound of order $\tilde O(\sqrt{K_T T})$ up to time horizon $T$ with $K_T$ the total number of change-points. In practice, our framework compares favorably to the state-of-the-art in both synthetic and real-world environments and manages to perform efficiently with respect to both risk-sensitivity and non-stationarity.
Detecting Pretraining Data from Large Language Models
Oct 25, 2023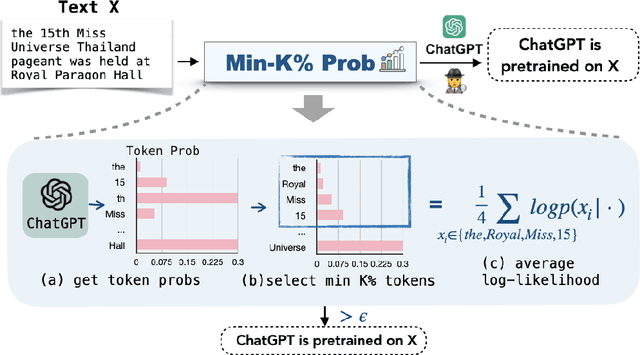
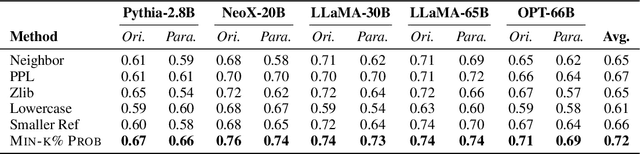
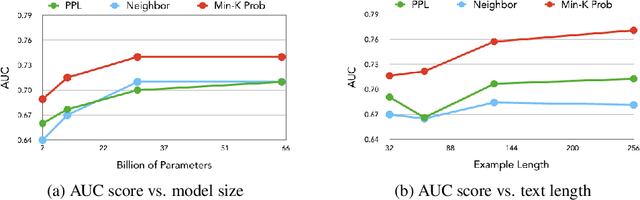

Although large language models (LLMs) are widely deployed, the data used to train them is rarely disclosed. Given the incredible scale of this data, up to trillions of tokens, it is all but certain that it includes potentially problematic text such as copyrighted materials, personally identifiable information, and test data for widely reported reference benchmarks. However, we currently have no way to know which data of these types is included or in what proportions. In this paper, we study the pretraining data detection problem: given a piece of text and black-box access to an LLM without knowing the pretraining data, can we determine if the model was trained on the provided text? To facilitate this study, we introduce a dynamic benchmark WIKIMIA that uses data created before and after model training to support gold truth detection. We also introduce a new detection method Min-K% Prob based on a simple hypothesis: an unseen example is likely to contain a few outlier words with low probabilities under the LLM, while a seen example is less likely to have words with such low probabilities. Min-K% Prob can be applied without any knowledge about the pretraining corpus or any additional training, departing from previous detection methods that require training a reference model on data that is similar to the pretraining data. Moreover, our experiments demonstrate that Min-K% Prob achieves a 7.4% improvement on WIKIMIA over these previous methods. We apply Min-K% Prob to two real-world scenarios, copyrighted book detection, and contaminated downstream example detection, and find it a consistently effective solution.
A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation
Oct 25, 2023Text-to-image diffusion models achieved a remarkable leap in capabilities over the last few years, enabling high-quality and diverse synthesis of images from a textual prompt. However, even the most advanced models often struggle to precisely follow all of the directions in their prompts. The vast majority of these models are trained on datasets consisting of (image, caption) pairs where the images often come from the web, and the captions are their HTML alternate text. A notable example is the LAION dataset, used by Stable Diffusion and other models. In this work we observe that these captions are often of low quality, and argue that this significantly affects the model's capability to understand nuanced semantics in the textual prompts. We show that by relabeling the corpus with a specialized automatic captioning model and training a text-to-image model on the recaptioned dataset, the model benefits substantially across the board. First, in overall image quality: e.g. FID 14.84 vs. the baseline of 17.87, and 64.3% improvement in faithful image generation according to human evaluation. Second, in semantic alignment, e.g. semantic object accuracy 84.34 vs. 78.90, counting alignment errors 1.32 vs. 1.44 and positional alignment 62.42 vs. 57.60. We analyze various ways to relabel the corpus and provide evidence that this technique, which we call RECAP, both reduces the train-inference discrepancy and provides the model with more information per example, increasing sample efficiency and allowing the model to better understand the relations between captions and images.
Merging Generated and Retrieved Knowledge for Open-Domain QA
Oct 22, 2023
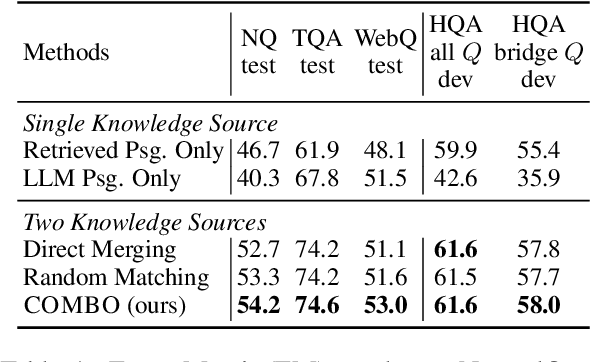
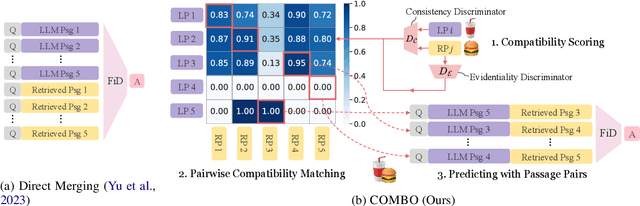

Open-domain question answering (QA) systems are often built with retrieval modules. However, retrieving passages from a given source is known to suffer from insufficient knowledge coverage. Alternatively, prompting large language models (LLMs) to generate contextual passages based on their parametric knowledge has been shown to improve QA performance. Yet, LLMs tend to "hallucinate" content that conflicts with the retrieved knowledge. Based on the intuition that answers supported by both sources are more likely to be correct, we propose COMBO, a Compatibility-Oriented knowledge Merging for Better Open-domain QA framework, to effectively leverage the two sources of information. Concretely, we match LLM-generated passages with retrieved counterparts into compatible pairs, based on discriminators trained with silver compatibility labels. Then a Fusion-in-Decoder-based reader model handles passage pairs to arrive at the final answer. Experiments show that COMBO outperforms competitive baselines on three out of four tested open-domain QA benchmarks. Further analysis reveals that our proposed framework demonstrates greater efficacy in scenarios with a higher degree of knowledge conflicts.
From Chaos to Clarity: Claim Normalization to Empower Fact-Checking
Oct 22, 2023With the proliferation of social media platforms, users are exposed to vast information, including posts containing misleading claims. However, the pervasive noise inherent in these posts presents a challenge in identifying precise and prominent claims that require verification. Extracting the core assertions from such posts is arduous and time-consuming. We introduce a novel task called Claim Normalization (aka ClaimNorm) that aims to decompose complex and noisy social media posts into more straightforward and understandable forms, termed normalized claims. We propose CACN, a pioneering approach that leverages chain-of-thought and claim check-worthiness estimation, mimicking human reasoning processes, to comprehend intricate claims. Moreover, we capitalize on large language models' powerful in-context learning abilities to provide guidance and improve the claim normalization process. To evaluate the effectiveness of our proposed model, we meticulously compile a comprehensive real-world dataset, CLAN, comprising more than 6k instances of social media posts alongside their respective normalized claims. Experimentation demonstrates that CACN outperforms several baselines across various evaluation measures. A rigorous error analysis validates CACN's capabilities and pitfalls.
PPFL: A Personalized Federated Learning Framework for Heterogeneous Population
Oct 22, 2023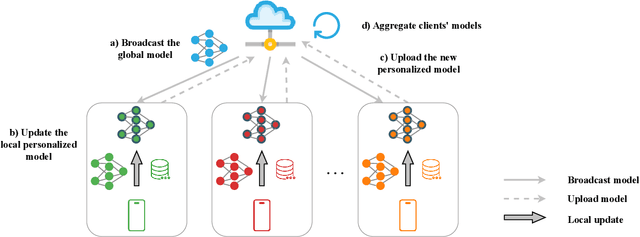

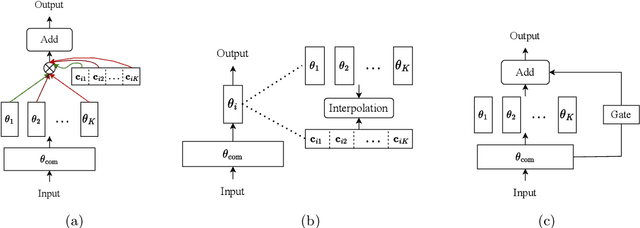

Personalization aims to characterize individual preferences and is widely applied across many fields. However, conventional personalized methods operate in a centralized manner and potentially expose the raw data when pooling individual information. In this paper, with privacy considerations, we develop a flexible and interpretable personalized framework within the paradigm of Federated Learning, called PPFL (Population Personalized Federated Learning). By leveraging canonical models to capture fundamental characteristics among the heterogeneous population and employing membership vectors to reveal clients' preferences, it models the heterogeneity as clients' varying preferences for these characteristics and provides substantial insights into client characteristics, which is lacking in existing Personalized Federated Learning (PFL) methods. Furthermore, we explore the relationship between our method and three main branches of PFL methods: multi-task PFL, clustered FL, and decoupling PFL, and demonstrate the advantages of PPFL. To solve PPFL (a non-convex constrained optimization problem), we propose a novel random block coordinate descent algorithm and present the convergence property. We conduct experiments on both pathological and practical datasets, and the results validate the effectiveness of PPFL.
Accelerating Scalable Graph Neural Network Inference with Node-Adaptive Propagation
Oct 17, 2023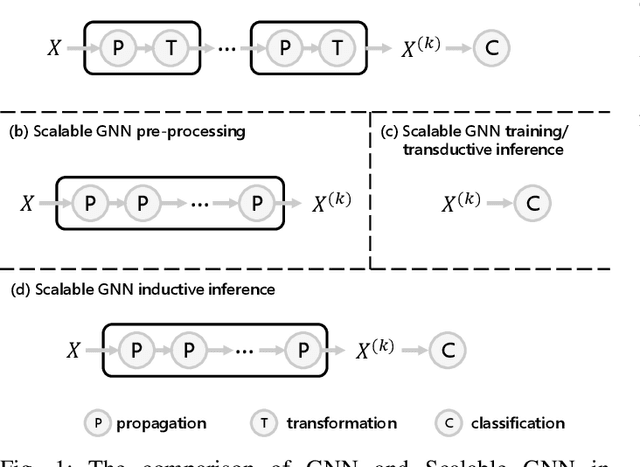
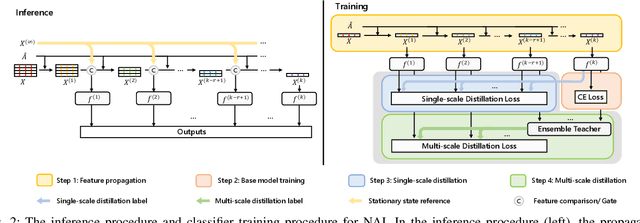
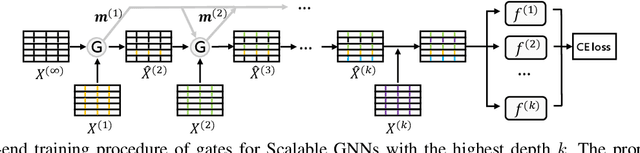
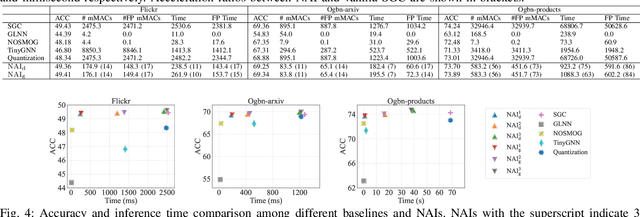
Graph neural networks (GNNs) have exhibited exceptional efficacy in a diverse array of applications. However, the sheer size of large-scale graphs presents a significant challenge to real-time inference with GNNs. Although existing Scalable GNNs leverage linear propagation to preprocess the features and accelerate the training and inference procedure, these methods still suffer from scalability issues when making inferences on unseen nodes, as the feature preprocessing requires the graph to be known and fixed. To further accelerate Scalable GNNs inference in this inductive setting, we propose an online propagation framework and two novel node-adaptive propagation methods that can customize the optimal propagation depth for each node based on its topological information and thereby avoid redundant feature propagation. The trade-off between accuracy and latency can be flexibly managed through simple hyper-parameters to accommodate various latency constraints. Moreover, to compensate for the inference accuracy loss caused by the potential early termination of propagation, we further propose Inception Distillation to exploit the multi-scale receptive field information within graphs. The rigorous and comprehensive experimental study on public datasets with varying scales and characteristics demonstrates that the proposed inference acceleration framework outperforms existing state-of-the-art graph inference acceleration methods in terms of accuracy and efficiency. Particularly, the superiority of our approach is notable on datasets with larger scales, yielding a 75x inference speedup on the largest Ogbn-products dataset.
Dual Cognitive Architecture: Incorporating Biases and Multi-Memory Systems for Lifelong Learning
Oct 17, 2023Artificial neural networks (ANNs) exhibit a narrow scope of expertise on stationary independent data. However, the data in the real world is continuous and dynamic, and ANNs must adapt to novel scenarios while also retaining the learned knowledge to become lifelong learners. The ability of humans to excel at these tasks can be attributed to multiple factors ranging from cognitive computational structures, cognitive biases, and the multi-memory systems in the brain. We incorporate key concepts from each of these to design a novel framework, Dual Cognitive Architecture (DUCA), which includes multiple sub-systems, implicit and explicit knowledge representation dichotomy, inductive bias, and a multi-memory system. The inductive bias learner within DUCA is instrumental in encoding shape information, effectively countering the tendency of ANNs to learn local textures. Simultaneously, the inclusion of a semantic memory submodule facilitates the gradual consolidation of knowledge, replicating the dynamics observed in fast and slow learning systems, reminiscent of the principles underpinning the complementary learning system in human cognition. DUCA shows improvement across different settings and datasets, and it also exhibits reduced task recency bias, without the need for extra information. To further test the versatility of lifelong learning methods on a challenging distribution shift, we introduce a novel domain-incremental dataset DN4IL. In addition to improving performance on existing benchmarks, DUCA also demonstrates superior performance on this complex dataset.