 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Masked Pretraining for Multi-Agent Decision Making
Oct 18, 2023
Building a single generalist agent with zero-shot capability has recently sparked significant advancements in decision-making. However, extending this capability to multi-agent scenarios presents challenges. Most current works struggle with zero-shot capabilities, due to two challenges particular to the multi-agent settings: a mismatch between centralized pretraining and decentralized execution, and varying agent numbers and action spaces, making it difficult to create generalizable representations across diverse downstream tasks. To overcome these challenges, we propose a \textbf{Mask}ed pretraining framework for \textbf{M}ulti-\textbf{a}gent decision making (MaskMA). This model, based on transformer architecture, employs a mask-based collaborative learning strategy suited for decentralized execution with partial observation. Moreover, MaskMA integrates a generalizable action representation by dividing the action space into actions toward self-information and actions related to other entities. This flexibility allows MaskMA to tackle tasks with varying agent numbers and thus different action spaces. Extensive experiments in SMAC reveal MaskMA, with a single model pretrained on 11 training maps, can achieve an impressive 77.8% zero-shot win rate on 60 unseen test maps by decentralized execution, while also performing effectively on other types of downstream tasks (\textit{e.g.,} varied policies collaboration and ad hoc team play).
3DS-SLAM: A 3D Object Detection based Semantic SLAM towards Dynamic Indoor Environments
Oct 10, 2023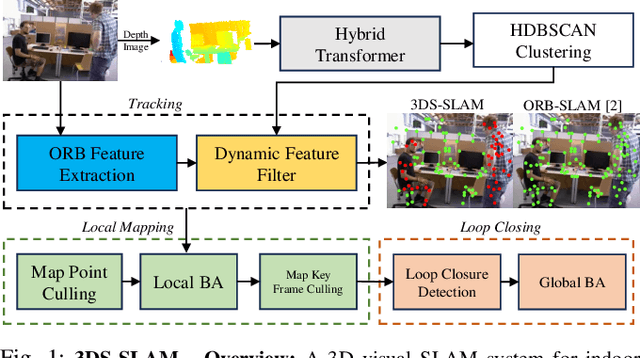
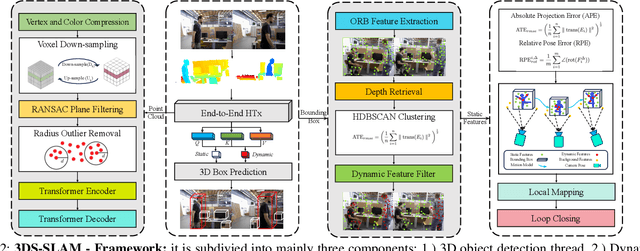


The existence of variable factors within the environment can cause a decline in camera localization accuracy, as it violates the fundamental assumption of a static environment in Simultaneous Localization and Mapping (SLAM) algorithms. Recent semantic SLAM systems towards dynamic environments either rely solely on 2D semantic information, or solely on geometric information, or combine their results in a loosely integrated manner. In this research paper, we introduce 3DS-SLAM, 3D Semantic SLAM, tailored for dynamic scenes with visual 3D object detection. The 3DS-SLAM is a tightly-coupled algorithm resolving both semantic and geometric constraints sequentially. We designed a 3D part-aware hybrid transformer for point cloud-based object detection to identify dynamic objects. Subsequently, we propose a dynamic feature filter based on HDBSCAN clustering to extract objects with significant absolute depth differences. When compared against ORB-SLAM2, 3DS-SLAM exhibits an average improvement of 98.01% across the dynamic sequences of the TUM RGB-D dataset. Furthermore, it surpasses the performance of the other four leading SLAM systems designed for dynamic environments.
Geom-Erasing: Geometry-Driven Removal of Implicit Concept in Diffusion Models
Oct 10, 2023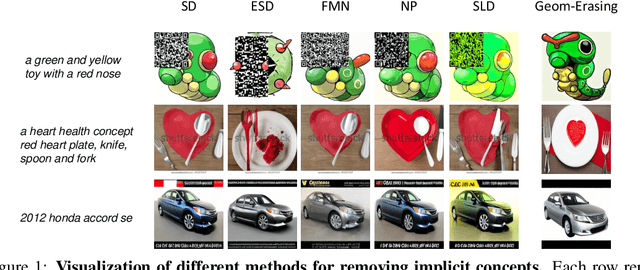

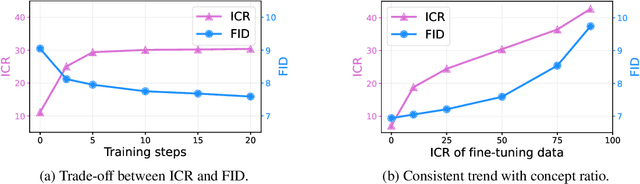
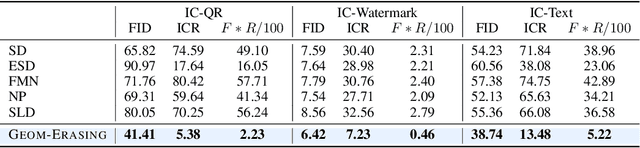
Fine-tuning diffusion models through personalized datasets is an acknowledged method for improving generation quality across downstream tasks, which, however, often inadvertently generates unintended concepts such as watermarks and QR codes, attributed to the limitations in image sources and collecting methods within specific downstream tasks. Existing solutions suffer from eliminating these unintentionally learned implicit concepts, primarily due to the dependency on the model's ability to recognize concepts that it actually cannot discern. In this work, we introduce Geom-Erasing, a novel approach that successfully removes the implicit concepts with either an additional accessible classifier or detector model to encode geometric information of these concepts into text domain. Moreover, we propose Implicit Concept, a novel image-text dataset imbued with three implicit concepts (i.e., watermarks, QR codes, and text) for training and evaluation. Experimental results demonstrate that Geom-Erasing not only identifies but also proficiently eradicates implicit concepts, revealing a significant improvement over the existing methods. The integration of geometric information marks a substantial progression in the precise removal of implicit concepts in diffusion models.
Geometry-Guided Ray Augmentation for Neural Surface Reconstruction with Sparse Views
Oct 16, 2023
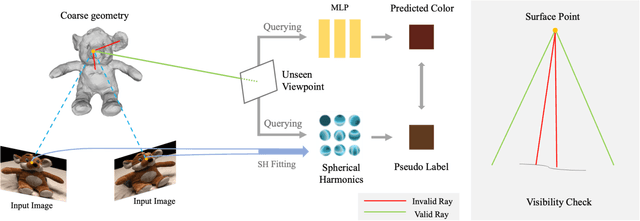
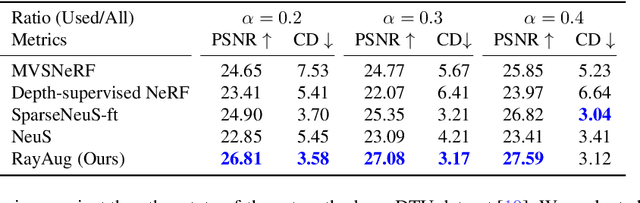

In this paper, we propose a novel method for 3D scene and object reconstruction from sparse multi-view images. Different from previous methods that leverage extra information such as depth or generalizable features across scenes, our approach leverages the scene properties embedded in the multi-view inputs to create precise pseudo-labels for optimization without any prior training. Specifically, we introduce a geometry-guided approach that improves surface reconstruction accuracy from sparse views by leveraging spherical harmonics to predict the novel radiance while holistically considering all color observations for a point in the scene. Also, our pipeline exploits proxy geometry and correctly handles the occlusion in generating the pseudo-labels of radiance, which previous image-warping methods fail to avoid. Our method, dubbed Ray Augmentation (RayAug), achieves superior results on DTU and Blender datasets without requiring prior training, demonstrating its effectiveness in addressing the problem of sparse view reconstruction. Our pipeline is flexible and can be integrated into other implicit neural reconstruction methods for sparse views.
GTA: A Geometry-Aware Attention Mechanism for Multi-View Transformers
Oct 16, 2023As transformers are equivariant to the permutation of input tokens, encoding the positional information of tokens is necessary for many tasks. However, since existing positional encoding schemes have been initially designed for NLP tasks, their suitability for vision tasks, which typically exhibit different structural properties in their data, is questionable. We argue that existing positional encoding schemes are suboptimal for 3D vision tasks, as they do not respect their underlying 3D geometric structure. Based on this hypothesis, we propose a geometry-aware attention mechanism that encodes the geometric structure of tokens as relative transformation determined by the geometric relationship between queries and key-value pairs. By evaluating on multiple novel view synthesis (NVS) datasets in the sparse wide-baseline multi-view setting, we show that our attention, called Geometric Transform Attention (GTA), improves learning efficiency and performance of state-of-the-art transformer-based NVS models without any additional learned parameters and only minor computational overhead.
Structural transfer learning of non-Gaussian DAG
Oct 16, 2023Directed acyclic graph (DAG) has been widely employed to represent directional relationships among a set of collected nodes. Yet, the available data in one single study is often limited for accurate DAG reconstruction, whereas heterogeneous data may be collected from multiple relevant studies. It remains an open question how to pool the heterogeneous data together for better DAG structure reconstruction in the target study. In this paper, we first introduce a novel set of structural similarity measures for DAG and then present a transfer DAG learning framework by effectively leveraging information from auxiliary DAGs of different levels of similarities. Our theoretical analysis shows substantial improvement in terms of DAG reconstruction in the target study, even when no auxiliary DAG is overall similar to the target DAG, which is in sharp contrast to most existing transfer learning methods. The advantage of the proposed transfer DAG learning is also supported by extensive numerical experiments on both synthetic data and multi-site brain functional connectivity network data.
Beyond Co-occurrence: Multi-modal Session-based Recommendation
Sep 29, 2023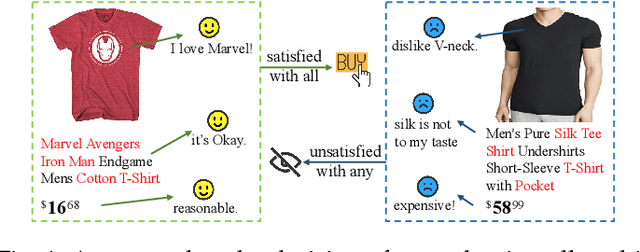

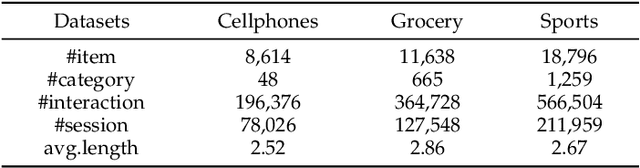
Session-based recommendation is devoted to characterizing preferences of anonymous users based on short sessions. Existing methods mostly focus on mining limited item co-occurrence patterns exposed by item ID within sessions, while ignoring what attracts users to engage with certain items is rich multi-modal information displayed on pages. Generally, the multi-modal information can be classified into two categories: descriptive information (e.g., item images and description text) and numerical information (e.g., price). In this paper, we aim to improve session-based recommendation by modeling the above multi-modal information holistically. There are mainly three issues to reveal user intent from multi-modal information: (1) How to extract relevant semantics from heterogeneous descriptive information with different noise? (2) How to fuse these heterogeneous descriptive information to comprehensively infer user interests? (3) How to handle probabilistic influence of numerical information on user behaviors? To solve above issues, we propose a novel multi-modal session-based recommendation (MMSBR) that models both descriptive and numerical information under a unified framework. Specifically, a pseudo-modality contrastive learning is devised to enhance the representation learning of descriptive information. Afterwards, a hierarchical pivot transformer is presented to fuse heterogeneous descriptive information. Moreover, we represent numerical information with Gaussian distribution and design a Wasserstein self-attention to handle the probabilistic influence mode. Extensive experiments on three real-world datasets demonstrate the effectiveness of the proposed MMSBR. Further analysis also proves that our MMSBR can alleviate the cold-start problem in SBR effectively.
Polarimetric Information for Multi-Modal 6D Pose Estimation of Photometrically Challenging Objects with Limited Data
Aug 21, 2023
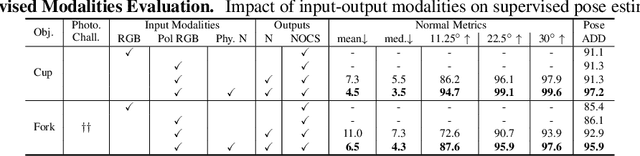
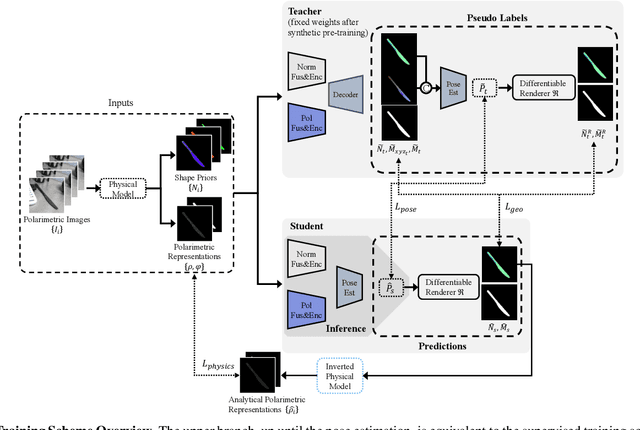
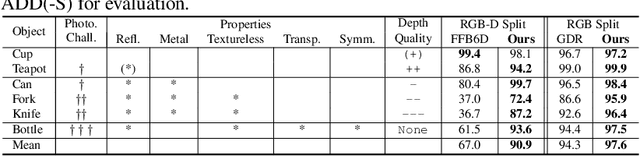
6D pose estimation pipelines that rely on RGB-only or RGB-D data show limitations for photometrically challenging objects with e.g. textureless surfaces, reflections or transparency. A supervised learning-based method utilising complementary polarisation information as input modality is proposed to overcome such limitations. This supervised approach is then extended to a self-supervised paradigm by leveraging physical characteristics of polarised light, thus eliminating the need for annotated real data. The methods achieve significant advancements in pose estimation by leveraging geometric information from polarised light and incorporating shape priors and invertible physical constraints.
Learn from the Past: A Proxy based Adversarial Defense Framework to Boost Robustness
Oct 19, 2023In light of the vulnerability of deep learning models to adversarial samples and the ensuing security issues, a range of methods, including Adversarial Training (AT) as a prominent representative, aimed at enhancing model robustness against various adversarial attacks, have seen rapid development. However, existing methods essentially assist the current state of target model to defend against parameter-oriented adversarial attacks with explicit or implicit computation burdens, which also suffers from unstable convergence behavior due to inconsistency of optimization trajectories. Diverging from previous work, this paper reconsiders the update rule of target model and corresponding deficiency to defend based on its current state. By introducing the historical state of the target model as a proxy, which is endowed with much prior information for defense, we formulate a two-stage update rule, resulting in a general adversarial defense framework, which we refer to as `LAST' ({\bf L}earn from the P{\bf ast}). Besides, we devise a Self Distillation (SD) based defense objective to constrain the update process of the proxy model without the introduction of larger teacher models. Experimentally, we demonstrate consistent and significant performance enhancements by refining a series of single-step and multi-step AT methods (e.g., up to $\bf 9.2\%$ and $\bf 20.5\%$ improvement of Robust Accuracy (RA) on CIFAR10 and CIFAR100 datasets, respectively) across various datasets, backbones and attack modalities, and validate its ability to enhance training stability and ameliorate catastrophic overfitting issues meanwhile.
Unveiling Energy Efficiency in Deep Learning: Measurement, Prediction, and Scoring across Edge Devices
Oct 19, 2023Today, deep learning optimization is primarily driven by research focused on achieving high inference accuracy and reducing latency. However, the energy efficiency aspect is often overlooked, possibly due to a lack of sustainability mindset in the field and the absence of a holistic energy dataset. In this paper, we conduct a threefold study, including energy measurement, prediction, and efficiency scoring, with an objective to foster transparency in power and energy consumption within deep learning across various edge devices. Firstly, we present a detailed, first-of-its-kind measurement study that uncovers the energy consumption characteristics of on-device deep learning. This study results in the creation of three extensive energy datasets for edge devices, covering a wide range of kernels, state-of-the-art DNN models, and popular AI applications. Secondly, we design and implement the first kernel-level energy predictors for edge devices based on our kernel-level energy dataset. Evaluation results demonstrate the ability of our predictors to provide consistent and accurate energy estimations on unseen DNN models. Lastly, we introduce two scoring metrics, PCS and IECS, developed to convert complex power and energy consumption data of an edge device into an easily understandable manner for edge device end-users. We hope our work can help shift the mindset of both end-users and the research community towards sustainability in edge computing, a principle that drives our research. Find data, code, and more up-to-date information at https://amai-gsu.github.io/DeepEn2023.