 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
QR-Tag: Angular Measurement and Tracking with a QR-Design Marker
Oct 09, 2023
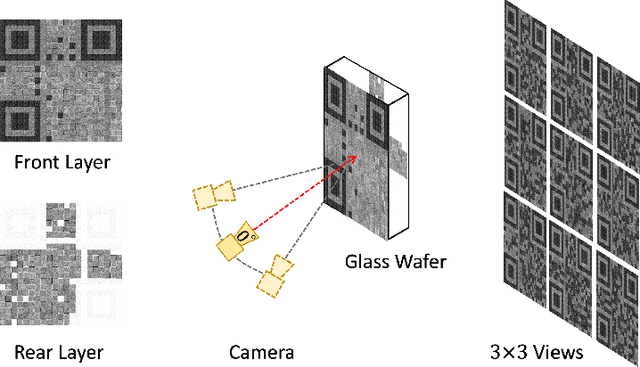
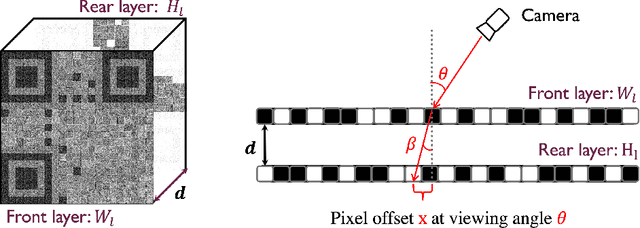
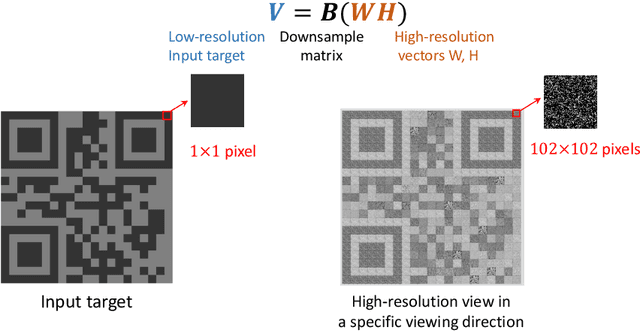
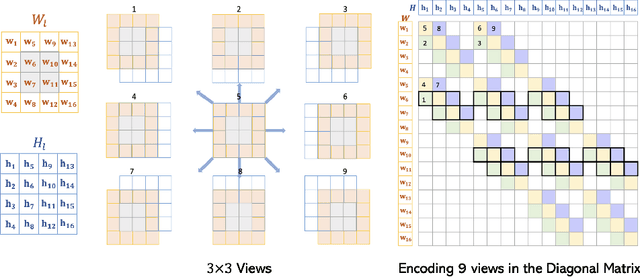
Directional information measurement has many applications in domains such as robotics, virtual and augmented reality, and industrial computer vision. Conventional methods either require pre-calibration or necessitate controlled environments. The state-of-the-art MoireTag approach exploits the Moire effect and QR-design to continuously track the angular shift precisely. However, it is still not a fully QR code design. To overcome the above challenges, we propose a novel snapshot method for discrete angular measurement and tracking with scannable QR-design patterns that are generated by binary structures printed on both sides of a glass plate. The QR codes, resulting from the parallax effect due to the geometry alignment between two layers, can be readily measured as angular information using a phone camera. The simulation results show that the proposed non-contact object tracking framework is computationally efficient with high accuracy.
Learning Graph Filters for Spectral GNNs via Newton Interpolation
Oct 16, 2023Spectral Graph Neural Networks (GNNs) are gaining attention because they can surpass the limitations of message-passing GNNs by learning spectral filters that capture essential frequency information in graph data through task supervision. However, previous research suggests that the choice of filter frequency is tied to the graph's homophily level, a connection that hasn't been thoroughly explored in existing spectral GNNs. To address this gap, the study conducts both theoretical and empirical analyses, revealing that low-frequency filters have a positive correlation with homophily, while high-frequency filters have a negative correlation. This leads to the introduction of a shape-aware regularization technique applied to a Newton Interpolation-based spectral filter, enabling the customization of polynomial spectral filters that align with desired homophily levels. Extensive experiments demonstrate that NewtonNet successfully achieves the desired filter shapes and exhibits superior performance on both homophilous and heterophilous datasets.
ADMEOOD: Out-of-Distribution Benchmark for Drug Property Prediction
Oct 11, 2023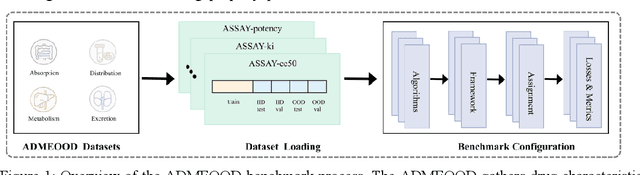
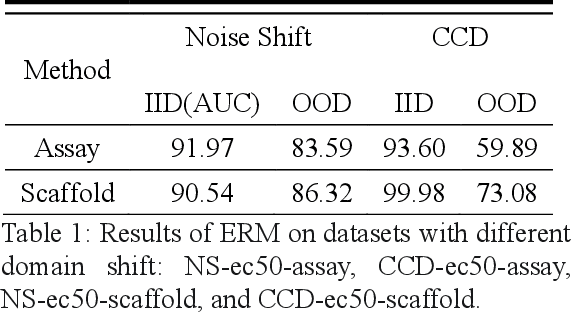
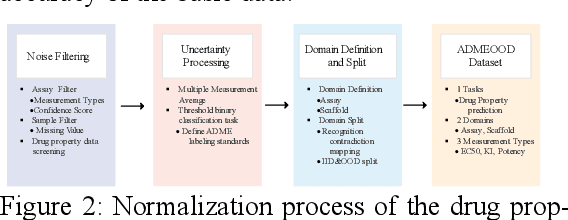
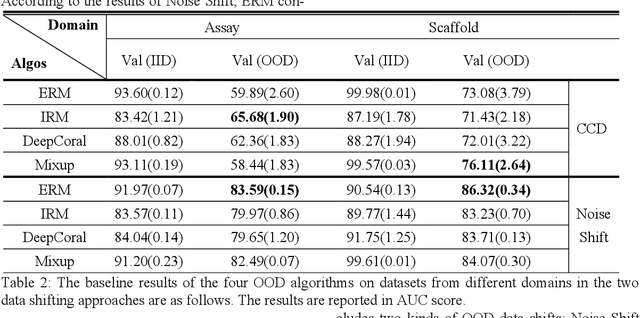
Obtaining accurate and valid information for drug molecules is a crucial and challenging task. However, chemical knowledge and information have been accumulated over the past 100 years from various regions, laboratories, and experimental purposes. Little has been explored in terms of the out-of-distribution (OOD) problem with noise and inconsistency, which may lead to weak robustness and unsatisfied performance. This study proposes a novel benchmark ADMEOOD, a systematic OOD dataset curator and benchmark specifically designed for drug property prediction. ADMEOOD obtained 27 ADME (Absorption, Distribution, Metabolism, Excretion) drug properties from Chembl and relevant literature. Additionally, it includes two kinds of OOD data shifts: Noise Shift and Concept Conflict Drift (CCD). Noise Shift responds to the noise level by categorizing the environment into different confidence levels. On the other hand, CCD describes the data which has inconsistent label among the original data. Finally, it tested on a variety of domain generalization models, and the experimental results demonstrate the effectiveness of the proposed partition method in ADMEOOD: ADMEOOD demonstrates a significant difference performance between in-distribution and out-of-distribution data. Moreover, ERM (Empirical Risk Minimization) and other models exhibit distinct trends in performance across different domains and measurement types.
Leader-Follower Neural Networks with Local Error Signals Inspired by Complex Collectives
Oct 11, 2023
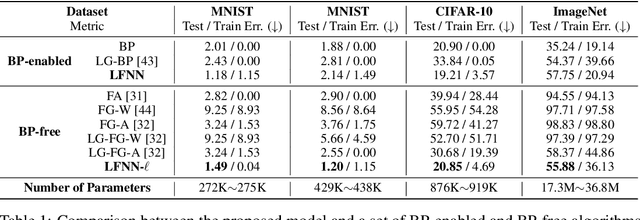
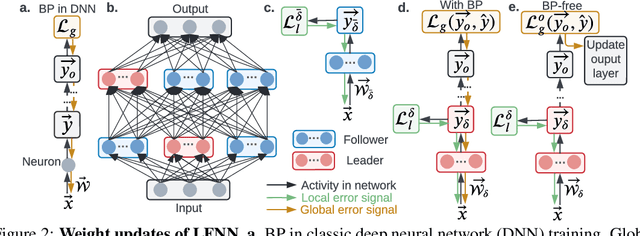
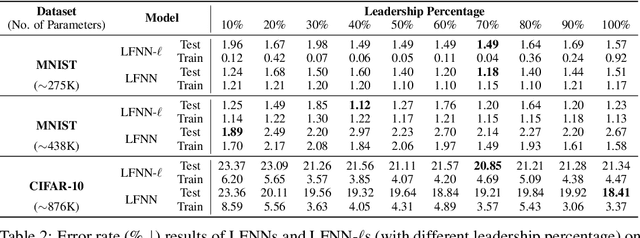
The collective behavior of a network with heterogeneous, resource-limited information processing units (e.g., group of fish, flock of birds, or network of neurons) demonstrates high self-organization and complexity. These emergent properties arise from simple interaction rules where certain individuals can exhibit leadership-like behavior and influence the collective activity of the group. Motivated by the intricacy of these collectives, we propose a neural network (NN) architecture inspired by the rules observed in nature's collective ensembles. This NN structure contains workers that encompass one or more information processing units (e.g., neurons, filters, layers, or blocks of layers). Workers are either leaders or followers, and we train a leader-follower neural network (LFNN) by leveraging local error signals and optionally incorporating backpropagation (BP) and global loss. We investigate worker behavior and evaluate LFNNs through extensive experimentation. Our LFNNs trained with local error signals achieve significantly lower error rates than previous BP-free algorithms on MNIST and CIFAR-10 and even surpass BP-enabled baselines. In the case of ImageNet, our LFNN-l demonstrates superior scalability and outperforms previous BP-free algorithms by a significant margin.
Video-Teller: Enhancing Cross-Modal Generation with Fusion and Decoupling
Oct 11, 2023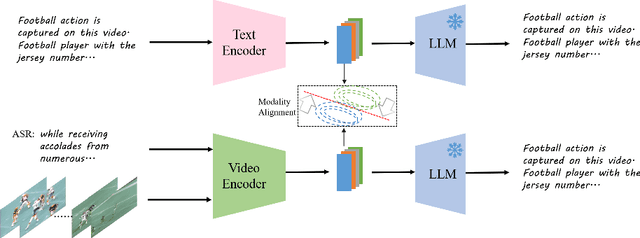
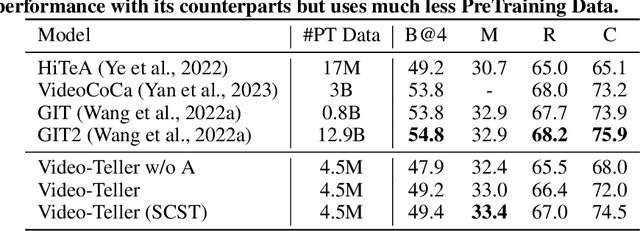
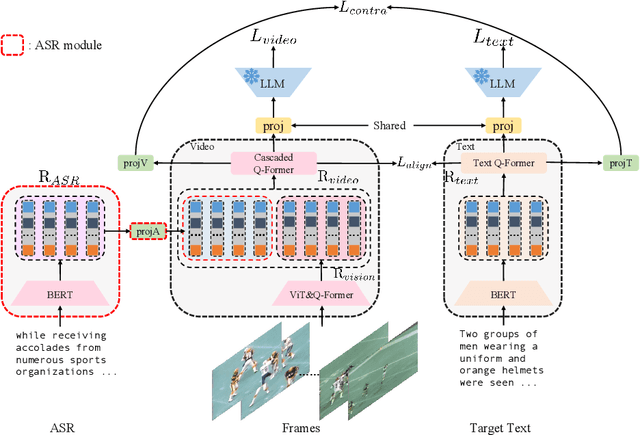

This paper proposes Video-Teller, a video-language foundation model that leverages multi-modal fusion and fine-grained modality alignment to significantly enhance the video-to-text generation task. Video-Teller boosts the training efficiency by utilizing frozen pretrained vision and language modules. It capitalizes on the robust linguistic capabilities of large language models, enabling the generation of both concise and elaborate video descriptions. To effectively integrate visual and auditory information, Video-Teller builds upon the image-based BLIP-2 model and introduces a cascaded Q-Former which fuses information across frames and ASR texts. To better guide video summarization, we introduce a fine-grained modality alignment objective, where the cascaded Q-Former's output embedding is trained to align with the caption/summary embedding created by a pretrained text auto-encoder. Experimental results demonstrate the efficacy of our proposed video-language foundation model in accurately comprehending videos and generating coherent and precise language descriptions. It is worth noting that the fine-grained alignment enhances the model's capabilities (4% improvement of CIDEr score on MSR-VTT) with only 13% extra parameters in training and zero additional cost in inference.
Causal discovery using dynamically requested knowledge
Oct 17, 2023
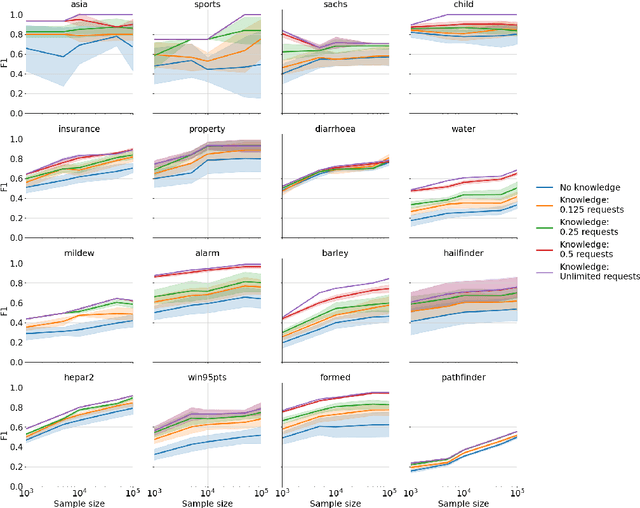
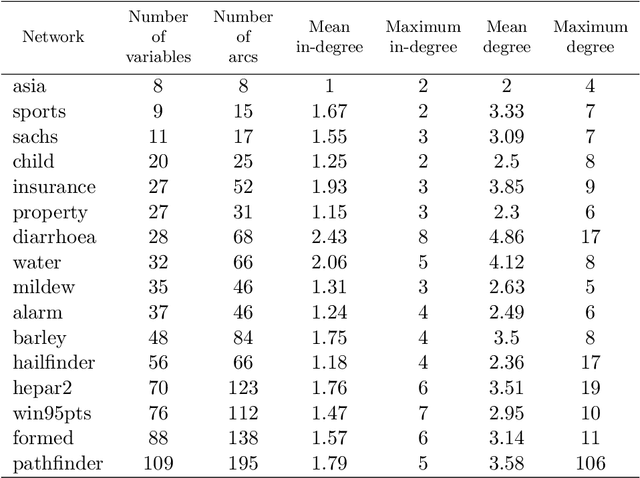
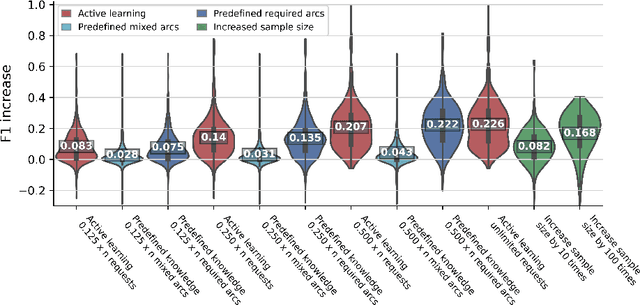
Causal Bayesian Networks (CBNs) are an important tool for reasoning under uncertainty in complex real-world systems. Determining the graphical structure of a CBN remains a key challenge and is undertaken either by eliciting it from humans, using machine learning to learn it from data, or using a combination of these two approaches. In the latter case, human knowledge is generally provided to the algorithm before it starts, but here we investigate a novel approach where the structure learning algorithm itself dynamically identifies and requests knowledge for relationships that the algorithm identifies as uncertain during structure learning. We integrate this approach into the Tabu structure learning algorithm and show that it offers considerable gains in structural accuracy, which are generally larger than those offered by existing approaches for integrating knowledge. We suggest that a variant which requests only arc orientation information may be particularly useful where the practitioner has little preexisting knowledge of the causal relationships. As well as offering improved accuracy, the approach can use human expertise more effectively and contributes to making the structure learning process more transparent.
MRI brain tumor segmentation using informative feature vectors and kernel dictionary learning
Oct 17, 2023This paper presents a method based on a kernel dictionary learning algorithm for segmenting brain tumor regions in magnetic resonance images (MRI). A set of first-order and second-order statistical feature vectors are extracted from patches of size 3 * 3 around pixels in the brain MRI scans. These feature vectors are utilized to train two kernel dictionaries separately for healthy and tumorous tissues. To enhance the efficiency of the dictionaries and reduce training time, a correlation-based sample selection technique is developed to identify the most informative and discriminative subset of feature vectors. This technique aims to improve the performance of the dictionaries by selecting a subset of feature vectors that provide valuable information for the segmentation task. Subsequently, a linear classifier is utilized to distinguish between healthy and unhealthy pixels based on the learned dictionaries. The results demonstrate that the proposed method outperforms other existing methods in terms of segmentation accuracy and significantly reduces both the time and memory required, resulting in a remarkably fast training process.
Zipformer: A faster and better encoder for automatic speech recognition
Oct 17, 2023The Conformer has become the most popular encoder model for automatic speech recognition (ASR). It adds convolution modules to a transformer to learn both local and global dependencies. In this work we describe a faster, more memory-efficient, and better-performing transformer, called Zipformer. Modeling changes include: 1) a U-Net-like encoder structure where middle stacks operate at lower frame rates; 2) reorganized block structure with more modules, within which we re-use attention weights for efficiency; 3) a modified form of LayerNorm called BiasNorm allows us to retain some length information; 4) new activation functions SwooshR and SwooshL work better than Swish. We also propose a new optimizer, called ScaledAdam, which scales the update by each tensor's current scale to keep the relative change about the same, and also explictly learns the parameter scale. It achieves faster convergence and better performance than Adam. Extensive experiments on LibriSpeech, Aishell-1, and WenetSpeech datasets demonstrate the effectiveness of our proposed Zipformer over other state-of-the-art ASR models. Our code is publicly available at https://github.com/k2-fsa/icefall.
Enhancing Neural Machine Translation with Semantic Units
Oct 17, 2023
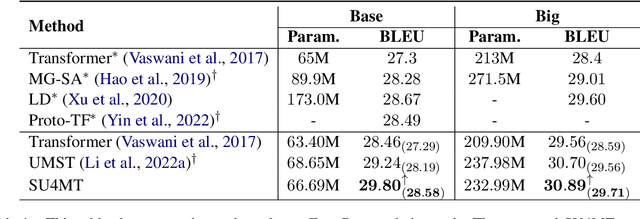
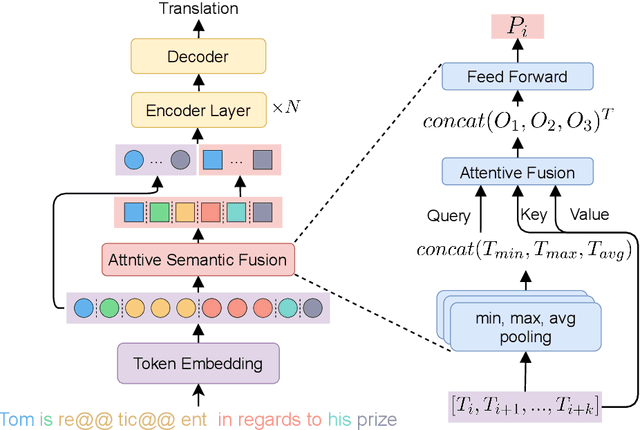
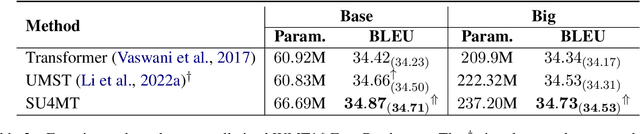
Conventional neural machine translation (NMT) models typically use subwords and words as the basic units for model input and comprehension. However, complete words and phrases composed of several tokens are often the fundamental units for expressing semantics, referred to as semantic units. To address this issue, we propose a method Semantic Units for Machine Translation (SU4MT) which models the integral meanings of semantic units within a sentence, and then leverages them to provide a new perspective for understanding the sentence. Specifically, we first propose Word Pair Encoding (WPE), a phrase extraction method to help identify the boundaries of semantic units. Next, we design an Attentive Semantic Fusion (ASF) layer to integrate the semantics of multiple subwords into a single vector: the semantic unit representation. Lastly, the semantic-unit-level sentence representation is concatenated to the token-level one, and they are combined as the input of encoder. Experimental results demonstrate that our method effectively models and leverages semantic-unit-level information and outperforms the strong baselines. The code is available at https://github.com/ictnlp/SU4MT.
Restricted Tweedie Stochastic Block Models
Oct 17, 2023The stochastic block model (SBM) is a widely used framework for community detection in networks, where the network structure is typically represented by an adjacency matrix. However, conventional SBMs are not directly applicable to an adjacency matrix that consists of non-negative zero-inflated continuous edge weights. To model the international trading network, where edge weights represent trading values between countries, we propose an innovative SBM based on a restricted Tweedie distribution. Additionally, we incorporate nodal information, such as the geographical distance between countries, and account for its dynamic effect on edge weights. Notably, we show that given a sufficiently large number of nodes, estimating this covariate effect becomes independent of community labels of each node when computing the maximum likelihood estimator of parameters in our model. This result enables the development of an efficient two-step algorithm that separates the estimation of covariate effects from other parameters. We demonstrate the effectiveness of our proposed method through extensive simulation studies and an application to real-world international trading data.