 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Uncertainty in Automated Ontology Matching: Lessons Learned from an Empirical Experimentation
Oct 18, 2023
Data integration is considered a classic research field and a pressing need within the information science community. Ontologies play a critical role in such a process by providing well-consolidated support to link and semantically integrate datasets via interoperability. This paper approaches data integration from an application perspective, looking at techniques based on ontology matching. An ontology-based process may only be considered adequate by assuming manual matching of different sources of information. However, since the approach becomes unrealistic once the system scales up, automation of the matching process becomes a compelling need. Therefore, we have conducted experiments on actual data with the support of existing tools for automatic ontology matching from the scientific community. Even considering a relatively simple case study (i.e., the spatio-temporal alignment of global indicators), outcomes clearly show significant uncertainty resulting from errors and inaccuracies along the automated matching process. More concretely, this paper aims to test on real-world data a bottom-up knowledge-building approach, discuss the lessons learned from the experimental results of the case study, and draw conclusions about uncertainty and uncertainty management in an automated ontology matching process. While the most common evaluation metrics clearly demonstrate the unreliability of fully automated matching solutions, properly designed semi-supervised approaches seem to be mature for a more generalized application.
Normalizing flow-based deep variational Bayesian network for seismic multi-hazards and impacts estimation from InSAR imagery
Oct 20, 2023Onsite disasters like earthquakes can trigger cascading hazards and impacts, such as landslides and infrastructure damage, leading to catastrophic losses; thus, rapid and accurate estimates are crucial for timely and effective post-disaster responses. Interferometric Synthetic aperture radar (InSAR) data is important in providing high-resolution onsite information for rapid hazard estimation. Most recent methods using InSAR imagery signals predict a single type of hazard and thus often suffer low accuracy due to noisy and complex signals induced by co-located hazards, impacts, and irrelevant environmental changes (e.g., vegetation changes, human activities). We introduce a novel stochastic variational inference with normalizing flows derived to jointly approximate posteriors of multiple unobserved hazards and impacts from noisy InSAR imagery.
A Novel Benchmarking Paradigm and a Scale- and Motion-Aware Model for Egocentric Pedestrian Trajectory Prediction
Oct 16, 2023Predicting pedestrian behavior is one of the main challenges for intelligent driving systems. In this paper, we present a new paradigm for evaluating egocentric pedestrian trajectory prediction algorithms. Based on various contextual information, we extract driving scenarios for a meaningful and systematic approach to identifying challenges for prediction models. In this regard, we also propose a new metric for more effective ranking within the scenario-based evaluation. We conduct extensive empirical studies of existing models on these scenarios to expose shortcomings and strengths of different approaches. The scenario-based analysis highlights the importance of using multimodal sources of information and challenges caused by inadequate modeling of ego-motion and scale of pedestrians. To this end, we propose a novel egocentric trajectory prediction model that benefits from multimodal sources of data fused in an effective and efficient step-wise hierarchical fashion and two auxiliary tasks designed to learn more robust representation of scene dynamics. We show that our approach achieves significant improvement by up to 40% in challenging scenarios compared to the past arts via empirical evaluation on common benchmark datasets.
Emerging Challenges in Personalized Medicine: Assessing Demographic Effects on Biomedical Question Answering Systems
Oct 16, 2023

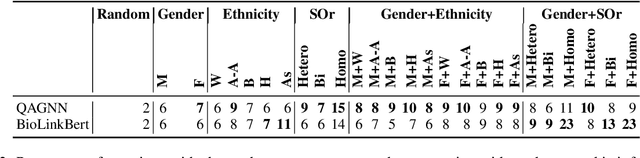
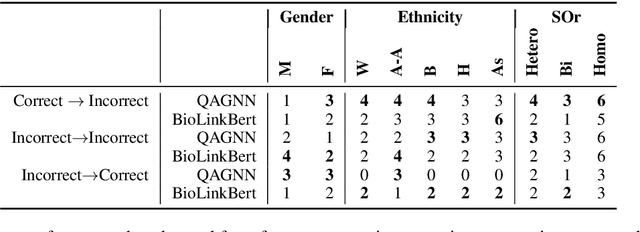
State-of-the-art question answering (QA) models exhibit a variety of social biases (e.g., with respect to sex or race), generally explained by similar issues in their training data. However, what has been overlooked so far is that in the critical domain of biomedicine, any unjustified change in model output due to patient demographics is problematic: it results in the unfair treatment of patients. Selecting only questions on biomedical topics whose answers do not depend on ethnicity, sex, or sexual orientation, we ask the following research questions: (RQ1) Do the answers of QA models change when being provided with irrelevant demographic information? (RQ2) Does the answer of RQ1 differ between knowledge graph (KG)-grounded and text-based QA systems? We find that irrelevant demographic information change up to 15% of the answers of a KG-grounded system and up to 23% of the answers of a text-based system, including changes that affect accuracy. We conclude that unjustified answer changes caused by patient demographics are a frequent phenomenon, which raises fairness concerns and should be paid more attention to.
A Mass-Conserving-Perceptron for Machine Learning-Based Modeling of Geoscientific Systems
Oct 24, 2023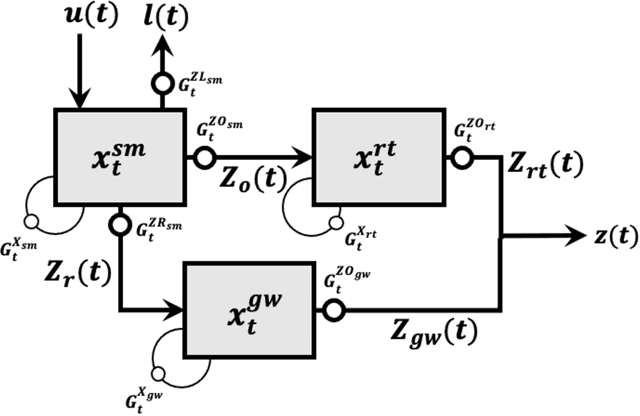
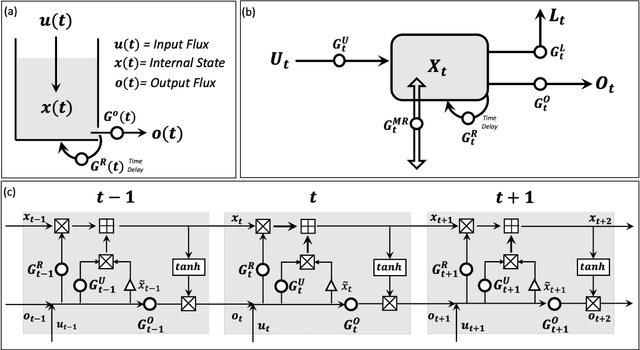
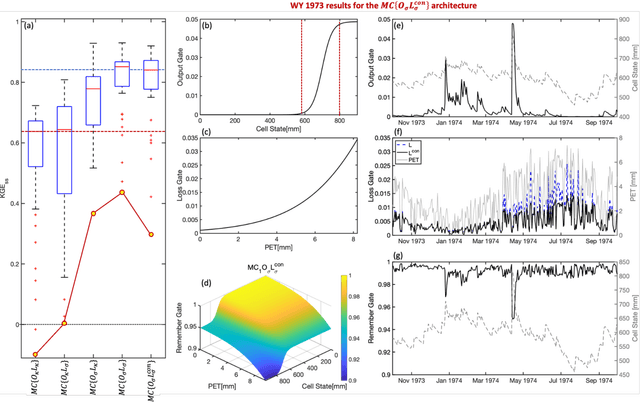
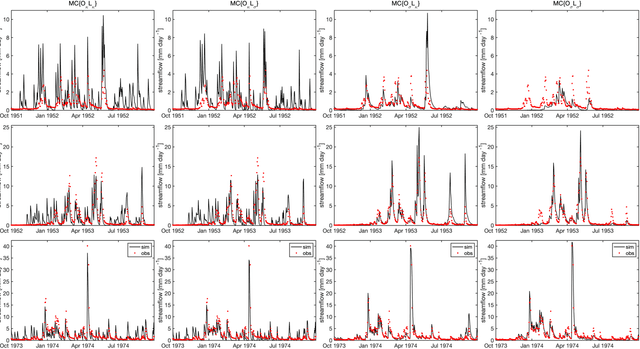
Although decades of effort have been devoted to building Physical-Conceptual (PC) models for predicting the time-series evolution of geoscientific systems, recent work shows that Machine Learning (ML) based Gated Recurrent Neural Network technology can be used to develop models that are much more accurate. However, the difficulty of extracting physical understanding from ML-based models complicates their utility for enhancing scientific knowledge regarding system structure and function. Here, we propose a physically-interpretable Mass Conserving Perceptron (MCP) as a way to bridge the gap between PC-based and ML-based modeling approaches. The MCP exploits the inherent isomorphism between the directed graph structures underlying both PC models and GRNNs to explicitly represent the mass-conserving nature of physical processes while enabling the functional nature of such processes to be directly learned (in an interpretable manner) from available data using off-the-shelf ML technology. As a proof of concept, we investigate the functional expressivity (capacity) of the MCP, explore its ability to parsimoniously represent the rainfall-runoff (RR) dynamics of the Leaf River Basin, and demonstrate its utility for scientific hypothesis testing. To conclude, we discuss extensions of the concept to enable ML-based physical-conceptual representation of the coupled nature of mass-energy-information flows through geoscientific systems.
GROVE: A Retrieval-augmented Complex Story Generation Framework with A Forest of Evidence
Oct 24, 2023Conditional story generation is significant in human-machine interaction, particularly in producing stories with complex plots. While Large language models (LLMs) perform well on multiple NLP tasks, including story generation, it is challenging to generate stories with both complex and creative plots. Existing methods often rely on detailed prompts to guide LLMs to meet target conditions, which inadvertently restrict the creative potential of the generated stories. We argue that leveraging information from exemplary human-written stories facilitates generating more diverse plotlines. Delving deeper into story details helps build complex and credible plots. In this paper, we propose a retrieval-au\textbf{G}mented sto\textbf{R}y generation framework with a f\textbf{O}rest of e\textbf{V}id\textbf{E}nce (GROVE) to enhance stories' complexity. We build a retrieval repository for target conditions to produce few-shot examples to prompt LLMs. Additionally, we design an ``asking-why'' prompting scheme that extracts a forest of evidence, providing compensation for the ambiguities that may occur in the generated story. This iterative process uncovers underlying story backgrounds. Finally, we select the most fitting chains of evidence from the evidence forest and integrate them into the generated story, thereby enhancing the narrative's complexity and credibility. Experimental results and numerous examples verify the effectiveness of our method.
Prevalence and prevention of large language model use in crowd work
Oct 24, 2023We show that the use of large language models (LLMs) is prevalent among crowd workers, and that targeted mitigation strategies can significantly reduce, but not eliminate, LLM use. On a text summarization task where workers were not directed in any way regarding their LLM use, the estimated prevalence of LLM use was around 30%, but was reduced by about half by asking workers to not use LLMs and by raising the cost of using them, e.g., by disabling copy-pasting. Secondary analyses give further insight into LLM use and its prevention: LLM use yields high-quality but homogeneous responses, which may harm research concerned with human (rather than model) behavior and degrade future models trained with crowdsourced data. At the same time, preventing LLM use may be at odds with obtaining high-quality responses; e.g., when requesting workers not to use LLMs, summaries contained fewer keywords carrying essential information. Our estimates will likely change as LLMs increase in popularity or capabilities, and as norms around their usage change. Yet, understanding the co-evolution of LLM-based tools and users is key to maintaining the validity of research done using crowdsourcing, and we provide a critical baseline before widespread adoption ensues.
Dialogue Chain-of-Thought Distillation for Commonsense-aware Conversational Agents
Oct 22, 2023

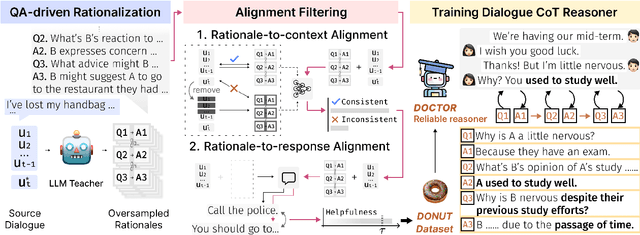
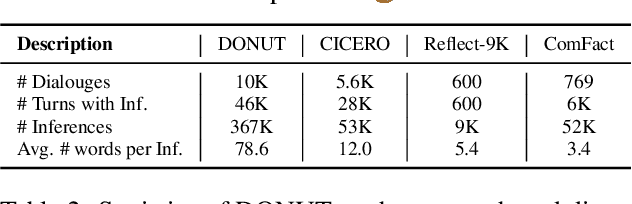
Human-like chatbots necessitate the use of commonsense reasoning in order to effectively comprehend and respond to implicit information present within conversations. Achieving such coherence and informativeness in responses, however, is a non-trivial task. Even for large language models (LLMs), the task of identifying and aggregating key evidence within a single hop presents a substantial challenge. This complexity arises because such evidence is scattered across multiple turns in a conversation, thus necessitating integration over multiple hops. Hence, our focus is to facilitate such multi-hop reasoning over a dialogue context, namely dialogue chain-of-thought (CoT) reasoning. To this end, we propose a knowledge distillation framework that leverages LLMs as unreliable teachers and selectively distills consistent and helpful rationales via alignment filters. We further present DOCTOR, a DialOgue Chain-of-ThOught Reasoner that provides reliable CoT rationales for response generation. We conduct extensive experiments to show that enhancing dialogue agents with high-quality rationales from DOCTOR significantly improves the quality of their responses.
$α$-Fair Contextual Bandits
Oct 22, 2023Contextual bandit algorithms are at the core of many applications, including recommender systems, clinical trials, and optimal portfolio selection. One of the most popular problems studied in the contextual bandit literature is to maximize the sum of the rewards in each round by ensuring a sublinear regret against the best-fixed context-dependent policy. However, in many applications, the cumulative reward is not the right objective - the bandit algorithm must be fair in order to avoid the echo-chamber effect and comply with the regulatory requirements. In this paper, we consider the $\alpha$-Fair Contextual Bandits problem, where the objective is to maximize the global $\alpha$-fair utility function - a non-decreasing concave function of the cumulative rewards in the adversarial setting. The problem is challenging due to the non-separability of the objective across rounds. We design an efficient algorithm that guarantees an approximately sublinear regret in the full-information and bandit feedback settings.
Glitter or Gold? Deriving Structured Insights from Sustainability Reports via Large Language Models
Oct 09, 2023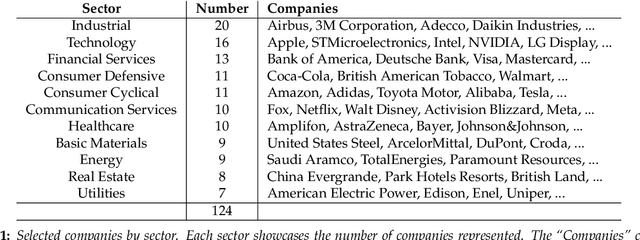
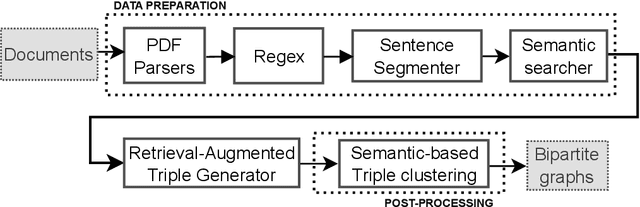
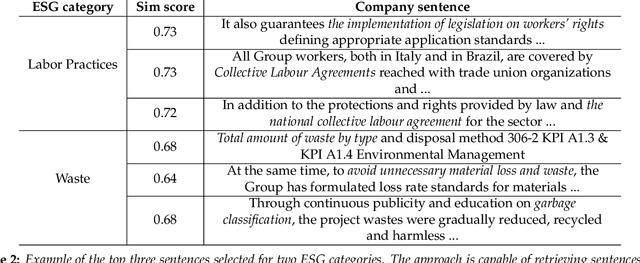

Over the last decade, several regulatory bodies have started requiring the disclosure of non-financial information from publicly listed companies, in light of the investors' increasing attention to Environmental, Social, and Governance (ESG) issues. Such information is publicly released in a variety of non-structured and multi-modal documentation. Hence, it is not straightforward to aggregate and consolidate such data in a cohesive framework to further derive insights about sustainability practices across companies and markets. Thus, it is natural to resort to Information Extraction (IE) techniques to provide concise, informative and actionable data to the stakeholders. Moving beyond traditional text processing techniques, in this work we leverage Large Language Models (LLMs), along with prominent approaches such as Retrieved Augmented Generation and in-context learning, to extract semantically structured information from sustainability reports. We then adopt graph-based representations to generate meaningful statistical, similarity and correlation analyses concerning the obtained findings, highlighting the prominent sustainability actions undertaken across industries and discussing emerging similarity and disclosing patterns at company, sector and region levels. Lastly, we investigate which factual aspects impact the most on companies' ESG scores using our findings and other company information.