 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GeoLLM: Extracting Geospatial Knowledge from Large Language Models
Oct 10, 2023

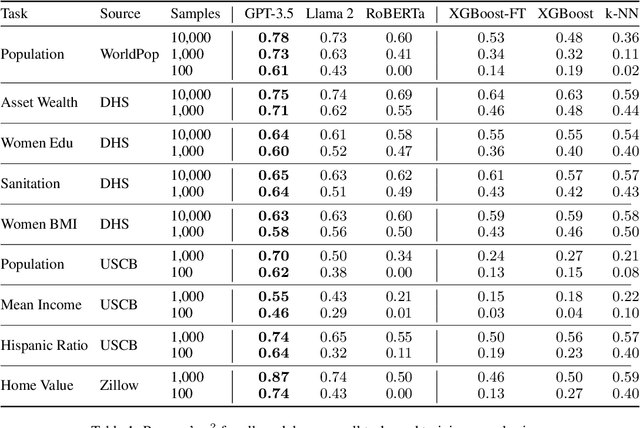

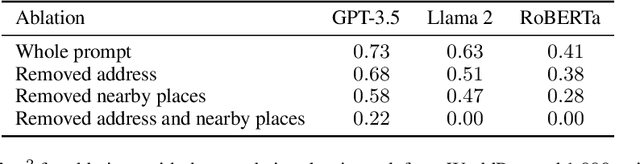
The application of machine learning (ML) in a range of geospatial tasks is increasingly common but often relies on globally available covariates such as satellite imagery that can either be expensive or lack predictive power. Here we explore the question of whether the vast amounts of knowledge found in Internet language corpora, now compressed within large language models (LLMs), can be leveraged for geospatial prediction tasks. We first demonstrate that LLMs embed remarkable spatial information about locations, but naively querying LLMs using geographic coordinates alone is ineffective in predicting key indicators like population density. We then present GeoLLM, a novel method that can effectively extract geospatial knowledge from LLMs with auxiliary map data from OpenStreetMap. We demonstrate the utility of our approach across multiple tasks of central interest to the international community, including the measurement of population density and economic livelihoods. Across these tasks, our method demonstrates a 70% improvement in performance (measured using Pearson's $r^2$) relative to baselines that use nearest neighbors or use information directly from the prompt, and performance equal to or exceeding satellite-based benchmarks in the literature. With GeoLLM, we observe that GPT-3.5 outperforms Llama 2 and RoBERTa by 19% and 51% respectively, suggesting that the performance of our method scales well with the size of the model and its pretraining dataset. Our experiments reveal that LLMs are remarkably sample-efficient, rich in geospatial information, and robust across the globe. Crucially, GeoLLM shows promise in mitigating the limitations of existing geospatial covariates and complementing them well.
CVE-driven Attack Technique Prediction with Semantic Information Extraction and a Domain-specific Language Model
Sep 06, 2023
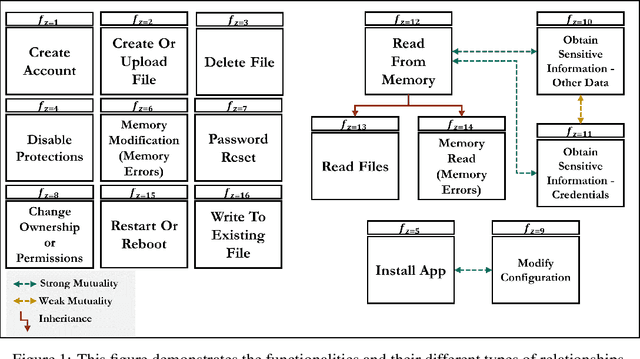
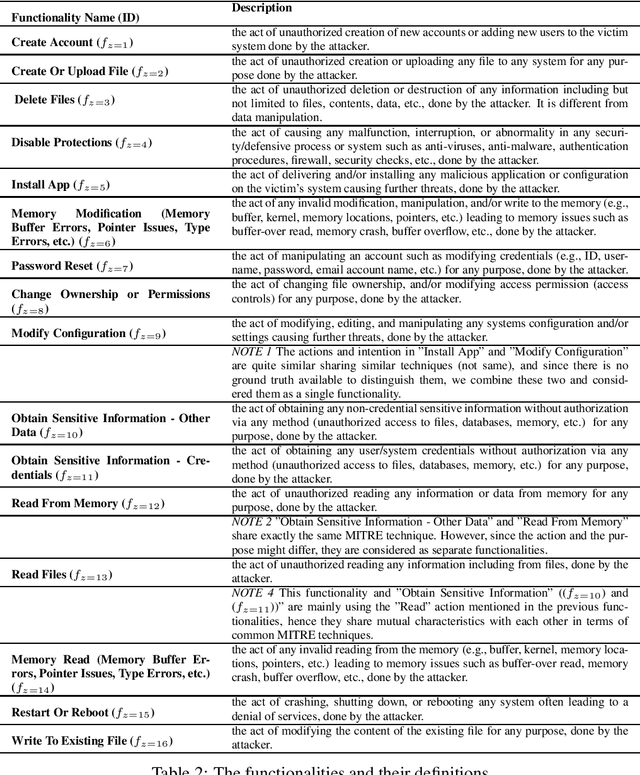

This paper addresses a critical challenge in cybersecurity: the gap between vulnerability information represented by Common Vulnerabilities and Exposures (CVEs) and the resulting cyberattack actions. CVEs provide insights into vulnerabilities, but often lack details on potential threat actions (tactics, techniques, and procedures, or TTPs) within the ATT&CK framework. This gap hinders accurate CVE categorization and proactive countermeasure initiation. The paper introduces the TTPpredictor tool, which uses innovative techniques to analyze CVE descriptions and infer plausible TTP attacks resulting from CVE exploitation. TTPpredictor overcomes challenges posed by limited labeled data and semantic disparities between CVE and TTP descriptions. It initially extracts threat actions from unstructured cyber threat reports using Semantic Role Labeling (SRL) techniques. These actions, along with their contextual attributes, are correlated with MITRE's attack functionality classes. This automated correlation facilitates the creation of labeled data, essential for categorizing novel threat actions into threat functionality classes and TTPs. The paper presents an empirical assessment, demonstrating TTPpredictor's effectiveness with accuracy rates of approximately 98% and F1-scores ranging from 95% to 98% in precise CVE classification to ATT&CK techniques. TTPpredictor outperforms state-of-the-art language model tools like ChatGPT. Overall, this paper offers a robust solution for linking CVEs to potential attack techniques, enhancing cybersecurity practitioners' ability to proactively identify and mitigate threats.
Balancing utility and cognitive cost in social representation
Oct 07, 2023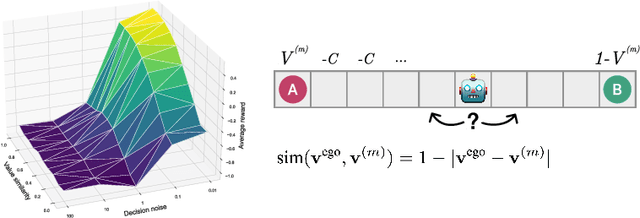
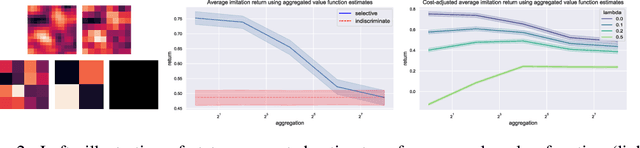
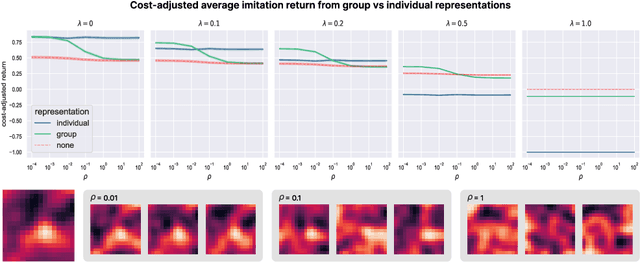
To successfully navigate its environment, an agent must construct and maintain representations of the other agents that it encounters. Such representations are useful for many tasks, but they are not without cost. As a result, agents must make decisions regarding how much information they choose to represent about the agents in their environment. Using selective imitation as an example task, we motivate the problem of finding agent representations that optimally trade off between downstream utility and information cost, and illustrate two example approaches to resource-constrained social representation.
ClusVPR: Efficient Visual Place Recognition with Clustering-based Weighted Transformer
Oct 06, 2023

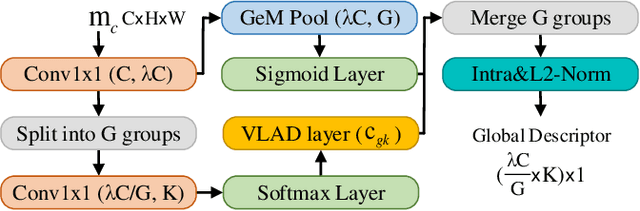
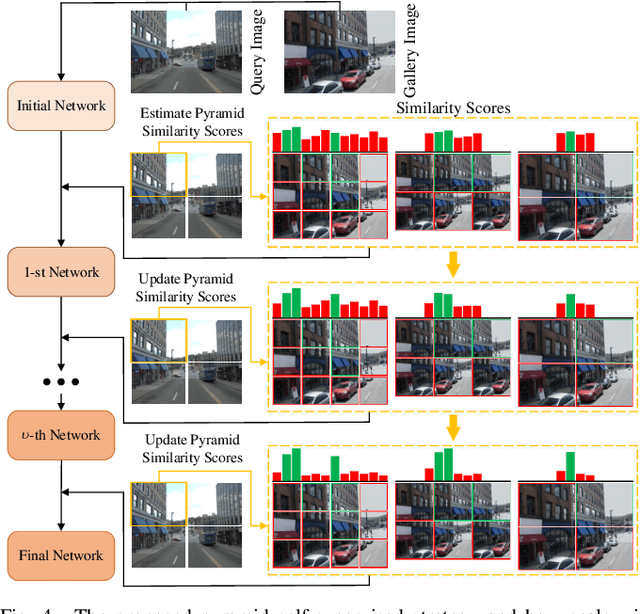
Visual place recognition (VPR) is a highly challenging task that has a wide range of applications, including robot navigation and self-driving vehicles. VPR is particularly difficult due to the presence of duplicate regions and the lack of attention to small objects in complex scenes, resulting in recognition deviations. In this paper, we present ClusVPR, a novel approach that tackles the specific issues of redundant information in duplicate regions and representations of small objects. Different from existing methods that rely on Convolutional Neural Networks (CNNs) for feature map generation, ClusVPR introduces a unique paradigm called Clustering-based Weighted Transformer Network (CWTNet). CWTNet leverages the power of clustering-based weighted feature maps and integrates global dependencies to effectively address visual deviations encountered in large-scale VPR problems. We also introduce the optimized-VLAD (OptLAD) layer that significantly reduces the number of parameters and enhances model efficiency. This layer is specifically designed to aggregate the information obtained from scale-wise image patches. Additionally, our pyramid self-supervised strategy focuses on extracting representative and diverse information from scale-wise image patches instead of entire images, which is crucial for capturing representative and diverse information in VPR. Extensive experiments on four VPR datasets show our model's superior performance compared to existing models while being less complex.
Will the Prince Get True Love's Kiss? On the Model Sensitivity to Gender Perturbation over Fairytale Texts
Oct 16, 2023Recent studies show that traditional fairytales are rife with harmful gender biases. To help mitigate these gender biases in fairytales, this work aims to assess learned biases of language models by evaluating their robustness against gender perturbations. Specifically, we focus on Question Answering (QA) tasks in fairytales. Using counterfactual data augmentation to the FairytaleQA dataset, we evaluate model robustness against swapped gender character information, and then mitigate learned biases by introducing counterfactual gender stereotypes during training time. We additionally introduce a novel approach that utilizes the massive vocabulary of language models to support text genres beyond fairytales. Our experimental results suggest that models are sensitive to gender perturbations, with significant performance drops compared to the original testing set. However, when first fine-tuned on a counterfactual training dataset, models are less sensitive to the later introduced anti-gender stereotyped text.
Whispering LLaMA: A Cross-Modal Generative Error Correction Framework for Speech Recognition
Oct 16, 2023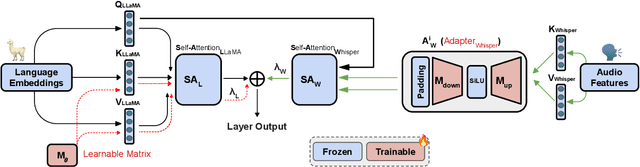
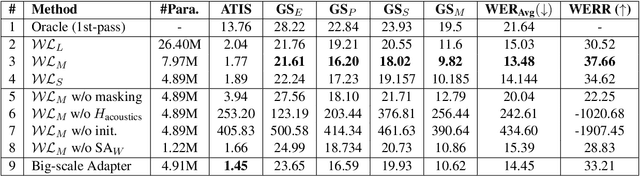
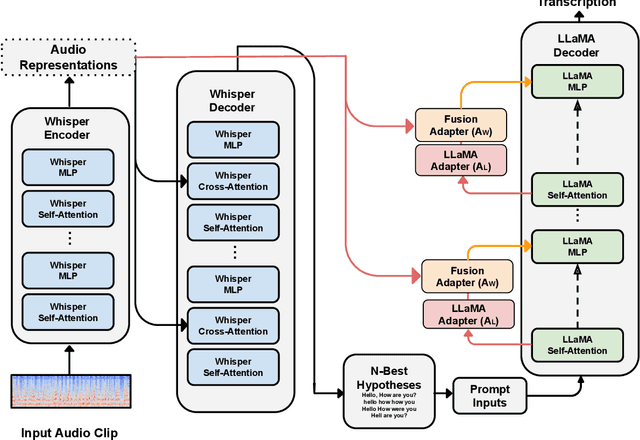
We introduce a new cross-modal fusion technique designed for generative error correction in automatic speech recognition (ASR). Our methodology leverages both acoustic information and external linguistic representations to generate accurate speech transcription contexts. This marks a step towards a fresh paradigm in generative error correction within the realm of n-best hypotheses. Unlike the existing ranking-based rescoring methods, our approach adeptly uses distinct initialization techniques and parameter-efficient algorithms to boost ASR performance derived from pre-trained speech and text models. Through evaluation across diverse ASR datasets, we evaluate the stability and reproducibility of our fusion technique, demonstrating its improved word error rate relative (WERR) performance in comparison to n-best hypotheses by relatively 37.66%. To encourage future research, we have made our code and pre-trained models open source at https://github.com/Srijith-rkr/Whispering-LLaMA.
Learning Language-guided Adaptive Hyper-modality Representation for Multimodal Sentiment Analysis
Oct 09, 2023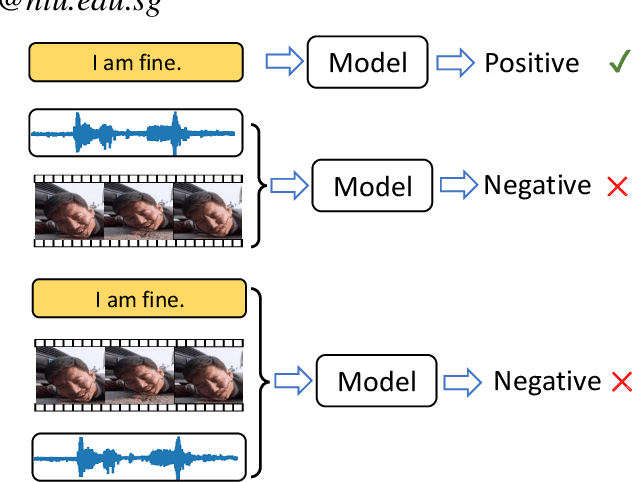
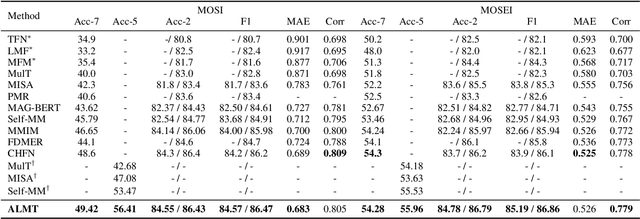
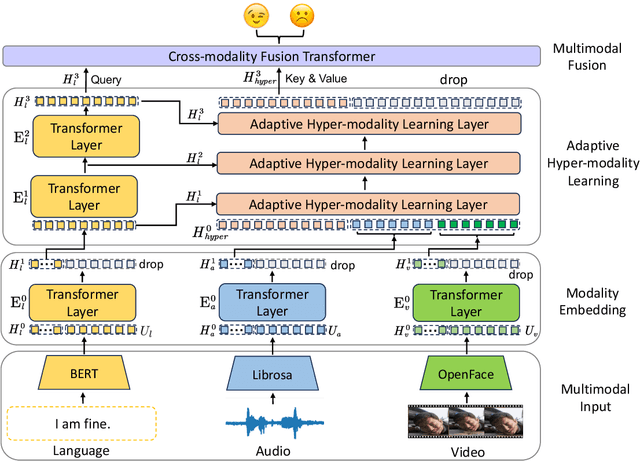
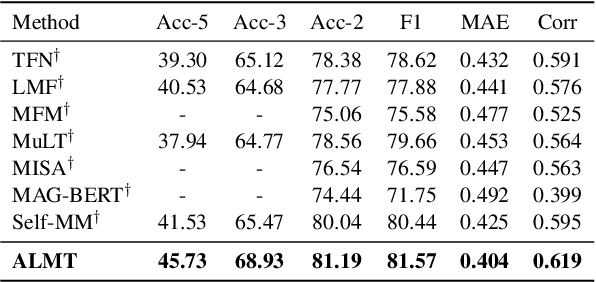
Though Multimodal Sentiment Analysis (MSA) proves effective by utilizing rich information from multiple sources (e.g., language, video, and audio), the potential sentiment-irrelevant and conflicting information across modalities may hinder the performance from being further improved. To alleviate this, we present Adaptive Language-guided Multimodal Transformer (ALMT), which incorporates an Adaptive Hyper-modality Learning (AHL) module to learn an irrelevance/conflict-suppressing representation from visual and audio features under the guidance of language features at different scales. With the obtained hyper-modality representation, the model can obtain a complementary and joint representation through multimodal fusion for effective MSA. In practice, ALMT achieves state-of-the-art performance on several popular datasets (e.g., MOSI, MOSEI and CH-SIMS) and an abundance of ablation demonstrates the validity and necessity of our irrelevance/conflict suppression mechanism.
Pre-trained Spatial Priors on Multichannel NMF for Music Source Separation
Oct 09, 2023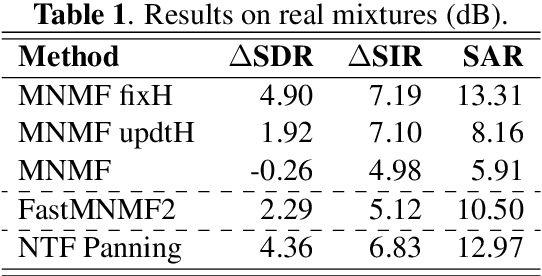
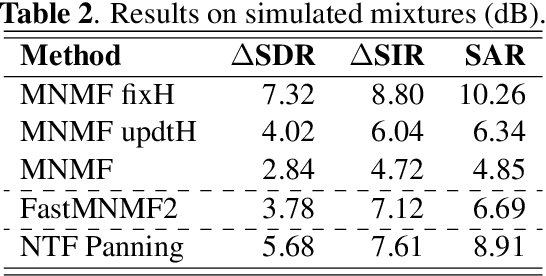
This paper presents a novel approach to sound source separation that leverages spatial information obtained during the recording setup. Our method trains a spatial mixing filter using solo passages to capture information about the room impulse response and transducer response at each sensor location. This pre-trained filter is then integrated into a multichannel non-negative matrix factorization (MNMF) scheme to better capture the variances of different sound sources. The recording setup used in our experiments is the typical setup for orchestra recordings, with a main microphone and a close "cardioid" or "supercardioid" microphone for each section of the orchestra. This makes the proposed method applicable to many existing recordings. Experiments on polyphonic ensembles demonstrate the effectiveness of the proposed framework in separating individual sound sources, improving performance compared to conventional MNMF methods.
Cultural Compass: Predicting Transfer Learning Success in Offensive Language Detection with Cultural Features
Oct 10, 2023The increasing ubiquity of language technology necessitates a shift towards considering cultural diversity in the machine learning realm, particularly for subjective tasks that rely heavily on cultural nuances, such as Offensive Language Detection (OLD). Current understanding underscores that these tasks are substantially influenced by cultural values, however, a notable gap exists in determining if cultural features can accurately predict the success of cross-cultural transfer learning for such subjective tasks. Addressing this, our study delves into the intersection of cultural features and transfer learning effectiveness. The findings reveal that cultural value surveys indeed possess a predictive power for cross-cultural transfer learning success in OLD tasks and that it can be further improved using offensive word distance. Based on these results, we advocate for the integration of cultural information into datasets. Additionally, we recommend leveraging data sources rich in cultural information, such as surveys, to enhance cultural adaptability. Our research signifies a step forward in the quest for more inclusive, culturally sensitive language technologies.
Document-Level Language Models for Machine Translation
Oct 18, 2023Despite the known limitations, most machine translation systems today still operate on the sentence-level. One reason for this is, that most parallel training data is only sentence-level aligned, without document-level meta information available. In this work, we set out to build context-aware translation systems utilizing document-level monolingual data instead. This can be achieved by combining any existing sentence-level translation model with a document-level language model. We improve existing approaches by leveraging recent advancements in model combination. Additionally, we propose novel weighting techniques that make the system combination more flexible and significantly reduce computational overhead. In a comprehensive evaluation on four diverse translation tasks, we show that our extensions improve document-targeted scores substantially and are also computationally more efficient. However, we also find that in most scenarios, back-translation gives even better results, at the cost of having to re-train the translation system. Finally, we explore language model fusion in the light of recent advancements in large language models. Our findings suggest that there might be strong potential in utilizing large language models via model combination.