 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GMMFormer: Gaussian-Mixture-Model based Transformer for Efficient Partially Relevant Video Retrieval
Oct 08, 2023
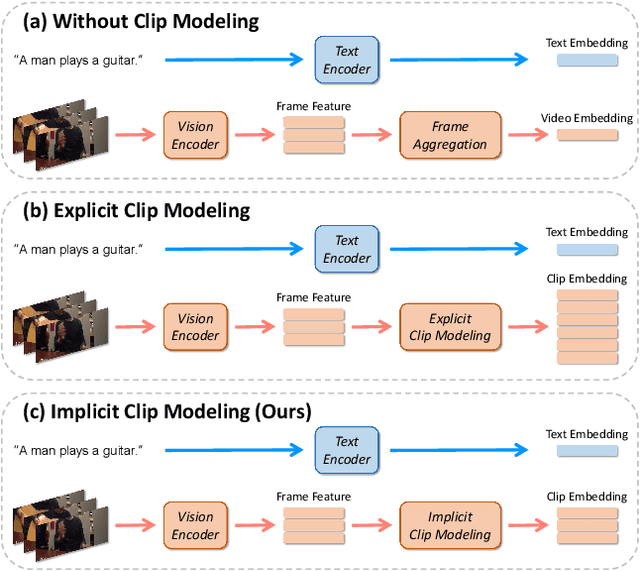
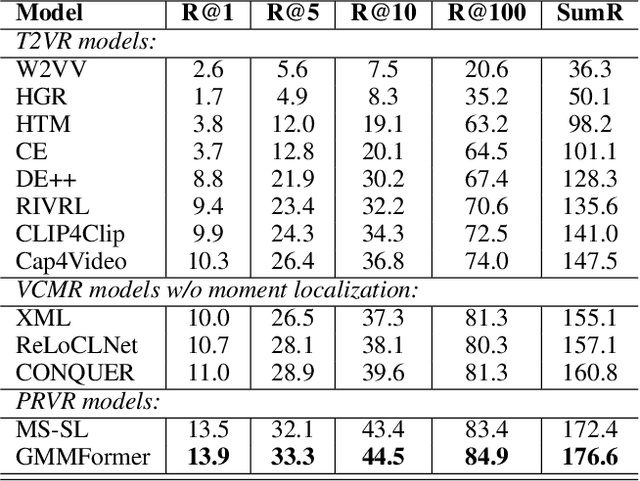
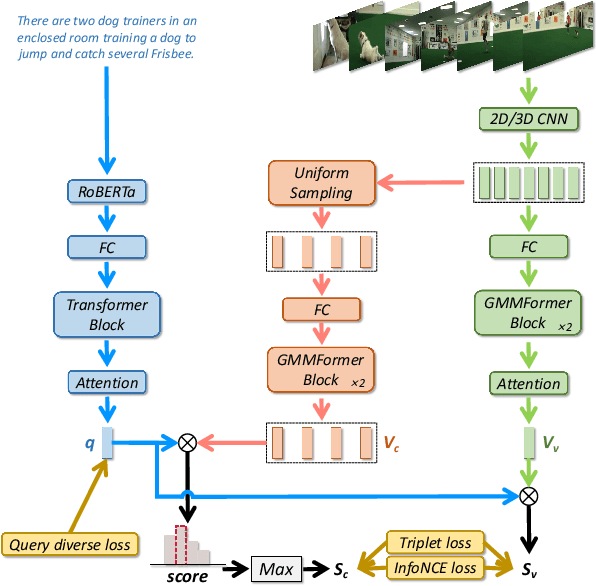
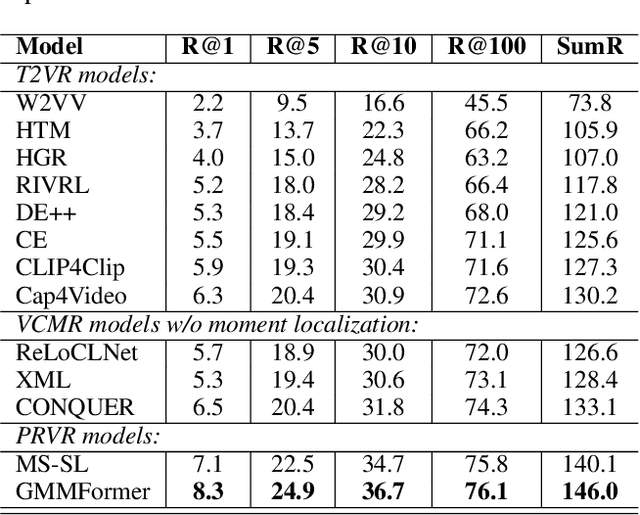
Given a text query, partially relevant video retrieval (PRVR) seeks to find untrimmed videos containing pertinent moments in a database. For PRVR, clip modeling is essential to capture the partial relationship between texts and videos. Current PRVR methods adopt scanning-based clip construction to achieve explicit clip modeling, which is information-redundant and requires a large storage overhead. To solve the efficiency problem of PRVR methods, this paper proposes GMMFormer, a \textbf{G}aussian-\textbf{M}ixture-\textbf{M}odel based Trans\textbf{former} which models clip representations implicitly. During frame interactions, we incorporate Gaussian-Mixture-Model constraints to focus each frame on its adjacent frames instead of the whole video. Then generated representations will contain multi-scale clip information, achieving implicit clip modeling. In addition, PRVR methods ignore semantic differences between text queries relevant to the same video, leading to a sparse embedding space. We propose a query diverse loss to distinguish these text queries, making the embedding space more intensive and contain more semantic information. Extensive experiments on three large-scale video datasets (\ie, TVR, ActivityNet Captions, and Charades-STA) demonstrate the superiority and efficiency of GMMFormer.
Locally Differentially Private Graph Embedding
Oct 17, 2023Graph embedding has been demonstrated to be a powerful tool for learning latent representations for nodes in a graph. However, despite its superior performance in various graph-based machine learning tasks, learning over graphs can raise significant privacy concerns when graph data involves sensitive information. To address this, in this paper, we investigate the problem of developing graph embedding algorithms that satisfy local differential privacy (LDP). We propose LDP-GE, a novel privacy-preserving graph embedding framework, to protect the privacy of node data. Specifically, we propose an LDP mechanism to obfuscate node data and adopt personalized PageRank as the proximity measure to learn node representations. Then, we theoretically analyze the privacy guarantees and utility of the LDP-GE framework. Extensive experiments conducted over several real-world graph datasets demonstrate that LDP-GE achieves favorable privacy-utility trade-offs and significantly outperforms existing approaches in both node classification and link prediction tasks.
DIAR: Deep Image Alignment and Reconstruction using Swin Transformers
Oct 17, 2023When taking images of some occluded content, one is often faced with the problem that every individual image frame contains unwanted artifacts, but a collection of images contains all relevant information if properly aligned and aggregated. In this paper, we attempt to build a deep learning pipeline that simultaneously aligns a sequence of distorted images and reconstructs them. We create a dataset that contains images with image distortions, such as lighting, specularities, shadows, and occlusion. We create perspective distortions with corresponding ground-truth homographies as labels. We use our dataset to train Swin transformer models to analyze sequential image data. The attention maps enable the model to detect relevant image content and differentiate it from outliers and artifacts. We further explore using neural feature maps as alternatives to classical key point detectors. The feature maps of trained convolutional layers provide dense image descriptors that can be used to find point correspondences between images. We utilize this to compute coarse image alignments and explore its limitations.
Multi-level Adaptive Contrastive Learning for Knowledge Internalization in Dialogue Generation
Oct 17, 2023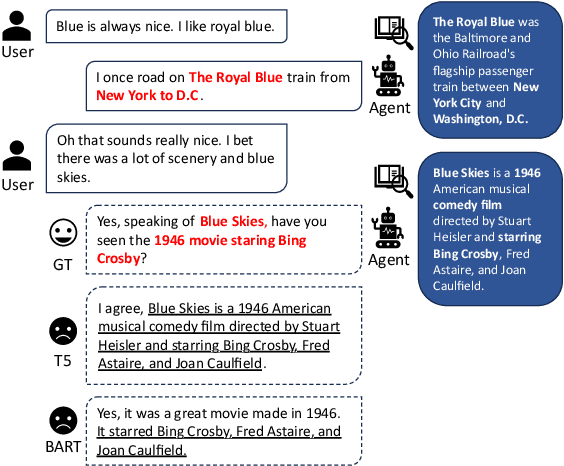
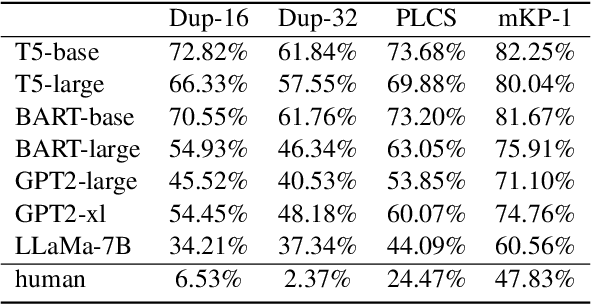
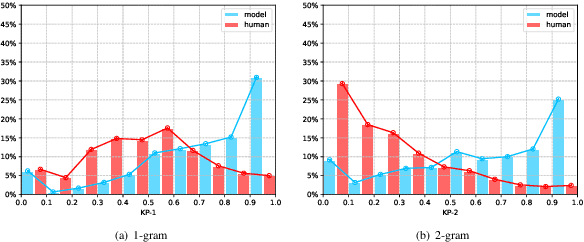
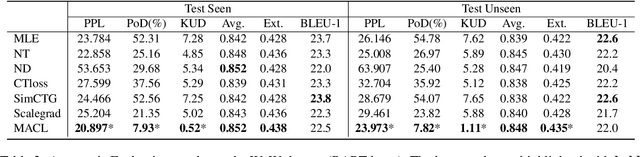
Knowledge-grounded dialogue generation aims to mitigate the issue of text degeneration by incorporating external knowledge to supplement the context. However, the model often fails to internalize this information into responses in a human-like manner. Instead, it simply inserts segments of the provided knowledge into generic responses. As a result, the generated responses tend to be tedious, incoherent, and in lack of interactivity which means the degeneration problem is still unsolved. In this work, we first find that such copying-style degeneration is primarily due to the weak likelihood objective, which allows the model to "cheat" the objective by merely duplicating knowledge segments in a superficial pattern matching based on overlap. To overcome this challenge, we then propose a Multi-level Adaptive Contrastive Learning (MACL) framework that dynamically samples negative examples and subsequently penalizes degeneration behaviors at both the token-level and sequence-level. Extensive experiments on the WoW dataset demonstrate the effectiveness of our approach across various pre-trained models.
Combat Urban Congestion via Collaboration: Heterogeneous GNN-based MARL for Coordinated Platooning and Traffic Signal Control
Oct 17, 2023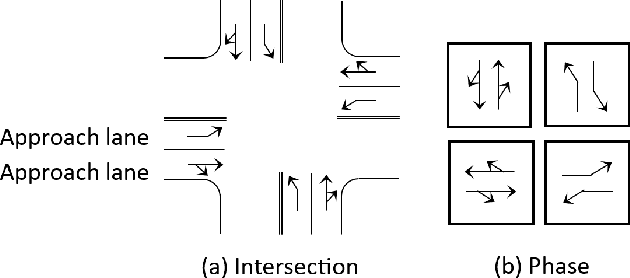
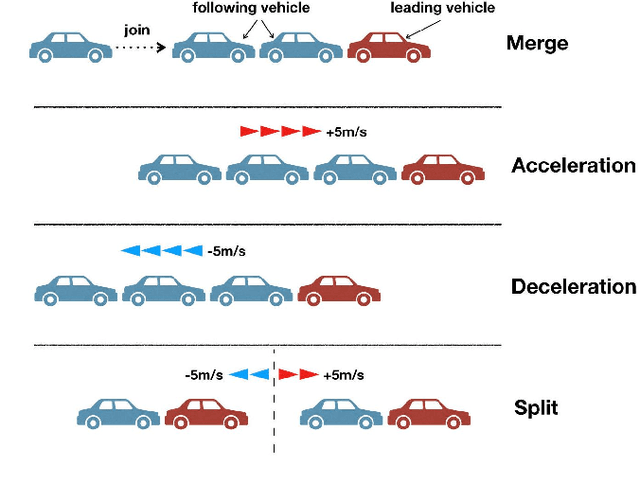
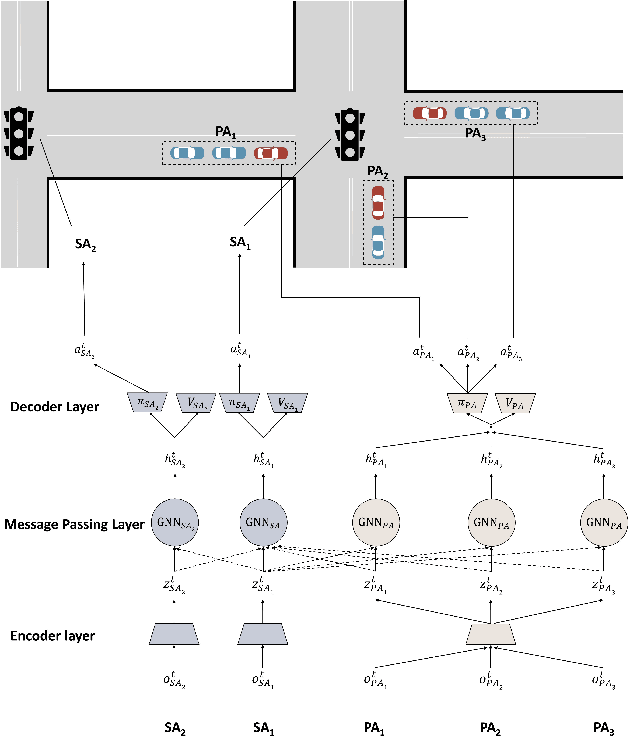
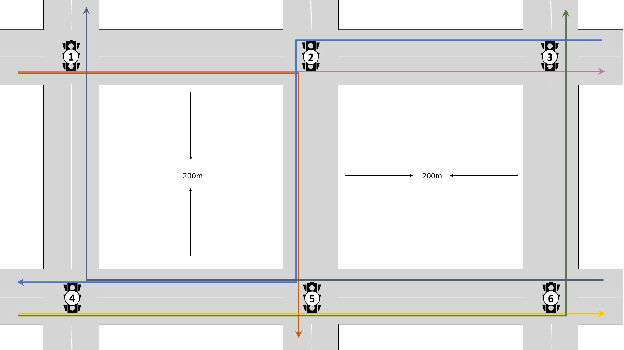
Over the years, reinforcement learning has emerged as a popular approach to develop signal control and vehicle platooning strategies either independently or in a hierarchical way. However, jointly controlling both in real-time to alleviate traffic congestion presents new challenges, such as the inherent physical and behavioral heterogeneity between signal control and platooning, as well as coordination between them. This paper proposes an innovative solution to tackle these challenges based on heterogeneous graph multi-agent reinforcement learning and traffic theories. Our approach involves: 1) designing platoon and signal control as distinct reinforcement learning agents with their own set of observations, actions, and reward functions to optimize traffic flow; 2) designing coordination by incorporating graph neural networks within multi-agent reinforcement learning to facilitate seamless information exchange among agents on a regional scale. We evaluate our approach through SUMO simulation, which shows a convergent result in terms of various transportation metrics and better performance over sole signal or platooning control.
Spatial HuBERT: Self-supervised Spatial Speech Representation Learning for a Single Talker from Multi-channel Audio
Oct 17, 2023Self-supervised learning has been used to leverage unlabelled data, improving accuracy and generalisation of speech systems through the training of representation models. While many recent works have sought to produce effective representations across a variety of acoustic domains, languages, modalities and even simultaneous speakers, these studies have all been limited to single-channel audio recordings. This paper presents Spatial HuBERT, a self-supervised speech representation model that learns both acoustic and spatial information pertaining to a single speaker in a potentially noisy environment by using multi-channel audio inputs. Spatial HuBERT learns representations that outperform state-of-the-art single-channel speech representations on a variety of spatial downstream tasks, particularly in reverberant and noisy environments. We also demonstrate the utility of the representations learned by Spatial HuBERT on a speech localisation downstream task. Along with this paper, we publicly release a new dataset of 100 000 simulated first-order ambisonics room impulse responses.
Uncovering Hidden Connections: Iterative Tracking and Reasoning for Video-grounded Dialog
Oct 11, 2023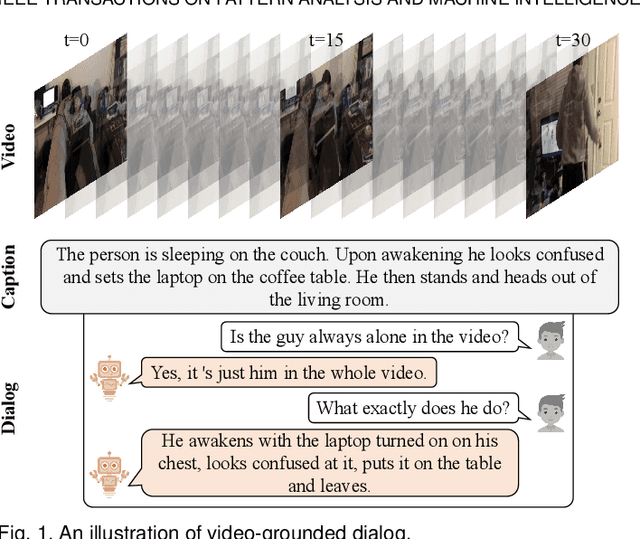
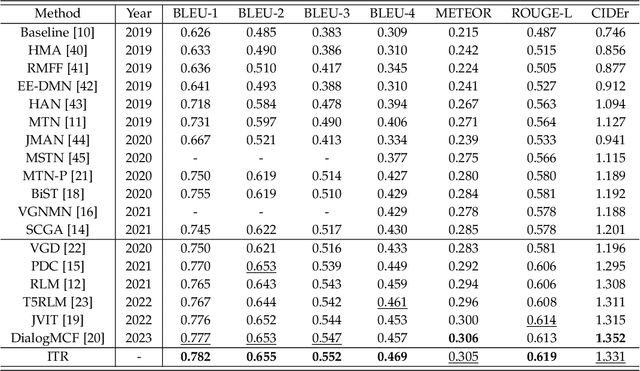
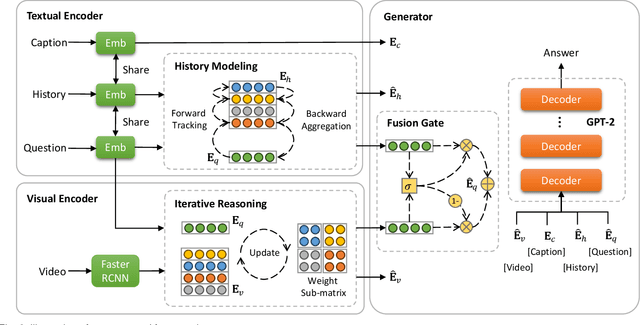
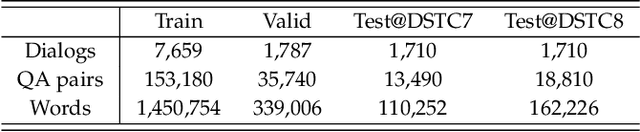
In contrast to conventional visual question answering, video-grounded dialog necessitates a profound understanding of both dialog history and video content for accurate response generation. Despite commendable strides made by existing methodologies, they often grapple with the challenges of incrementally understanding intricate dialog histories and assimilating video information. In response to this gap, we present an iterative tracking and reasoning strategy that amalgamates a textual encoder, a visual encoder, and a generator. At its core, our textual encoder is fortified with a path tracking and aggregation mechanism, adept at gleaning nuances from dialog history that are pivotal to deciphering the posed questions. Concurrently, our visual encoder harnesses an iterative reasoning network, meticulously crafted to distill and emphasize critical visual markers from videos, enhancing the depth of visual comprehension. Culminating this enriched information, we employ the pre-trained GPT-2 model as our response generator, stitching together coherent and contextually apt answers. Our empirical assessments, conducted on two renowned datasets, testify to the prowess and adaptability of our proposed design.
Adapting the adapters for code-switching in multilingual ASR
Oct 11, 2023Recently, large pre-trained multilingual speech models have shown potential in scaling Automatic Speech Recognition (ASR) to many low-resource languages. Some of these models employ language adapters in their formulation, which helps to improve monolingual performance and avoids some of the drawbacks of multi-lingual modeling on resource-rich languages. However, this formulation restricts the usability of these models on code-switched speech, where two languages are mixed together in the same utterance. In this work, we propose ways to effectively fine-tune such models on code-switched speech, by assimilating information from both language adapters at each language adaptation point in the network. We also model code-switching as a sequence of latent binary sequences that can be used to guide the flow of information from each language adapter at the frame level. The proposed approaches are evaluated on three code-switched datasets encompassing Arabic, Mandarin, and Hindi languages paired with English, showing consistent improvements in code-switching performance with at least 10\% absolute reduction in CER across all test sets.
GeoLLM: Extracting Geospatial Knowledge from Large Language Models
Oct 10, 2023
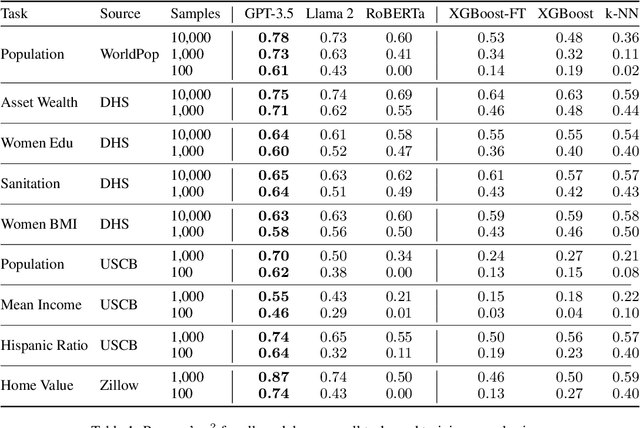

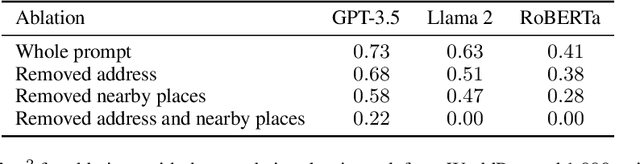
The application of machine learning (ML) in a range of geospatial tasks is increasingly common but often relies on globally available covariates such as satellite imagery that can either be expensive or lack predictive power. Here we explore the question of whether the vast amounts of knowledge found in Internet language corpora, now compressed within large language models (LLMs), can be leveraged for geospatial prediction tasks. We first demonstrate that LLMs embed remarkable spatial information about locations, but naively querying LLMs using geographic coordinates alone is ineffective in predicting key indicators like population density. We then present GeoLLM, a novel method that can effectively extract geospatial knowledge from LLMs with auxiliary map data from OpenStreetMap. We demonstrate the utility of our approach across multiple tasks of central interest to the international community, including the measurement of population density and economic livelihoods. Across these tasks, our method demonstrates a 70% improvement in performance (measured using Pearson's $r^2$) relative to baselines that use nearest neighbors or use information directly from the prompt, and performance equal to or exceeding satellite-based benchmarks in the literature. With GeoLLM, we observe that GPT-3.5 outperforms Llama 2 and RoBERTa by 19% and 51% respectively, suggesting that the performance of our method scales well with the size of the model and its pretraining dataset. Our experiments reveal that LLMs are remarkably sample-efficient, rich in geospatial information, and robust across the globe. Crucially, GeoLLM shows promise in mitigating the limitations of existing geospatial covariates and complementing them well.
ScaleLong: Towards More Stable Training of Diffusion Model via Scaling Network Long Skip Connection
Oct 20, 2023In diffusion models, UNet is the most popular network backbone, since its long skip connects (LSCs) to connect distant network blocks can aggregate long-distant information and alleviate vanishing gradient. Unfortunately, UNet often suffers from unstable training in diffusion models which can be alleviated by scaling its LSC coefficients smaller. However, theoretical understandings of the instability of UNet in diffusion models and also the performance improvement of LSC scaling remain absent yet. To solve this issue, we theoretically show that the coefficients of LSCs in UNet have big effects on the stableness of the forward and backward propagation and robustness of UNet. Specifically, the hidden feature and gradient of UNet at any layer can oscillate and their oscillation ranges are actually large which explains the instability of UNet training. Moreover, UNet is also provably sensitive to perturbed input, and predicts an output distant from the desired output, yielding oscillatory loss and thus oscillatory gradient. Besides, we also observe the theoretical benefits of the LSC coefficient scaling of UNet in the stableness of hidden features and gradient and also robustness. Finally, inspired by our theory, we propose an effective coefficient scaling framework ScaleLong that scales the coefficients of LSC in UNet and better improves the training stability of UNet. Experimental results on four famous datasets show that our methods are superior to stabilize training and yield about 1.5x training acceleration on different diffusion models with UNet or UViT backbones. Code: https://github.com/sail-sg/ScaleLong