 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ShadowSense: Unsupervised Domain Adaptation and Feature Fusion for Shadow-Agnostic Tree Crown Detection from RGB-Thermal Drone Imagery
Oct 24, 2023
Accurate detection of individual tree crowns from remote sensing data poses a significant challenge due to the dense nature of forest canopy and the presence of diverse environmental variations, e.g., overlapping canopies, occlusions, and varying lighting conditions. Additionally, the lack of data for training robust models adds another limitation in effectively studying complex forest conditions. This paper presents a novel method for detecting shadowed tree crowns and provides a challenging dataset comprising roughly 50k paired RGB-thermal images to facilitate future research for illumination-invariant detection. The proposed method (ShadowSense) is entirely self-supervised, leveraging domain adversarial training without source domain annotations for feature extraction and foreground feature alignment for feature pyramid networks to adapt domain-invariant representations by focusing on visible foreground regions, respectively. It then fuses complementary information of both modalities to effectively improve upon the predictions of an RGB-trained detector and boost the overall accuracy. Extensive experiments demonstrate the superiority of the proposed method over both the baseline RGB-trained detector and state-of-the-art techniques that rely on unsupervised domain adaptation or early image fusion. Our code and data are available: https://github.com/rudrakshkapil/ShadowSense
Synergizing Data Imputation and Electronic Health Records for Advancing Prostate Cancer Research: Challenges, and Practical Applications
Oct 24, 2023The presence of detailed clinical information in electronic health record (EHR) systems presents promising prospects for enhancing patient care through automated retrieval techniques. Nevertheless, it is widely acknowledged that accessing data within EHRs is hindered by various methodological challenges. Specifically, the clinical notes stored in EHRs are composed in a narrative form, making them prone to ambiguous formulations and highly unstructured data presentations, while structured reports commonly suffer from missing and/or erroneous data entries. This inherent complexity poses significant challenges when attempting automated large-scale medical knowledge extraction tasks, necessitating the application of advanced tools, such as natural language processing (NLP), as well as data audit techniques. This work aims to address these obstacles by creating and validating a novel pipeline designed to extract relevant data pertaining to prostate cancer patients. The objective is to exploit the inherent redundancies available within the integrated structured and unstructured data entries within EHRs in order to generate comprehensive and reliable medical databases, ready to be used in advanced research studies. Additionally, the study explores potential opportunities arising from these data, offering valuable prospects for advancing research in prostate cancer.
Universal Multi-modal Entity Alignment via Iteratively Fusing Modality Similarity Paths
Oct 13, 2023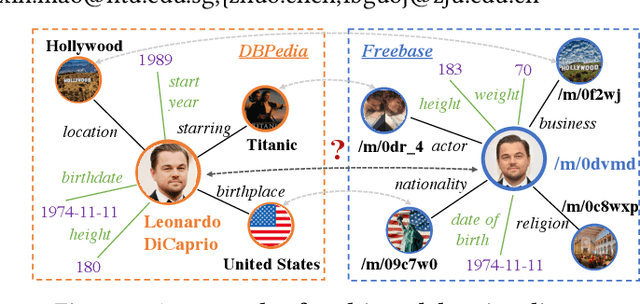
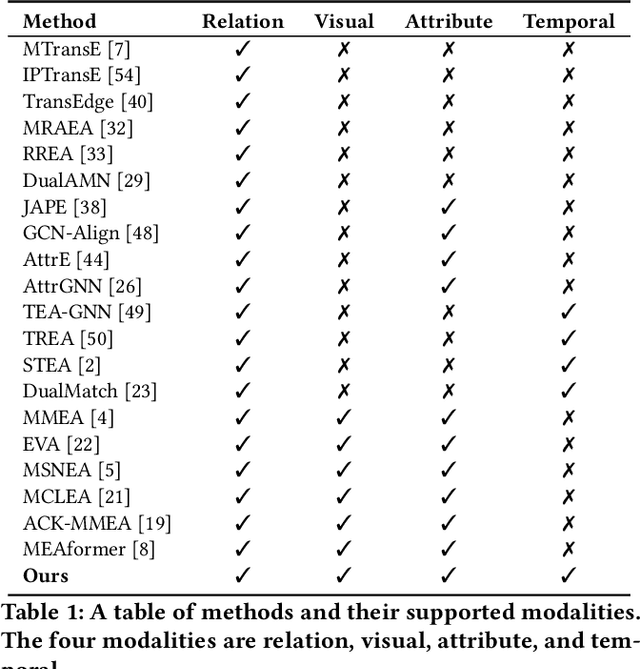

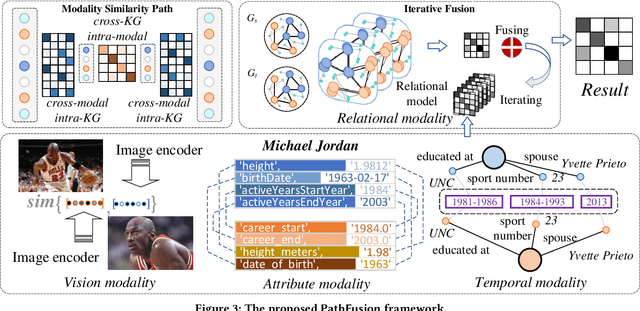
The objective of Entity Alignment (EA) is to identify equivalent entity pairs from multiple Knowledge Graphs (KGs) and create a more comprehensive and unified KG. The majority of EA methods have primarily focused on the structural modality of KGs, lacking exploration of multi-modal information. A few multi-modal EA methods have made good attempts in this field. Still, they have two shortcomings: (1) inconsistent and inefficient modality modeling that designs complex and distinct models for each modality; (2) ineffective modality fusion due to the heterogeneous nature of modalities in EA. To tackle these challenges, we propose PathFusion, consisting of two main components: (1) MSP, a unified modeling approach that simplifies the alignment process by constructing paths connecting entities and modality nodes to represent multiple modalities; (2) IRF, an iterative fusion method that effectively combines information from different modalities using the path as an information carrier. Experimental results on real-world datasets demonstrate the superiority of PathFusion over state-of-the-art methods, with 22.4%-28.9% absolute improvement on Hits@1, and 0.194-0.245 absolute improvement on MRR.
Bayesian Learning for Dynamic Target Localization with Human-provided Spatial Information
Aug 24, 2023
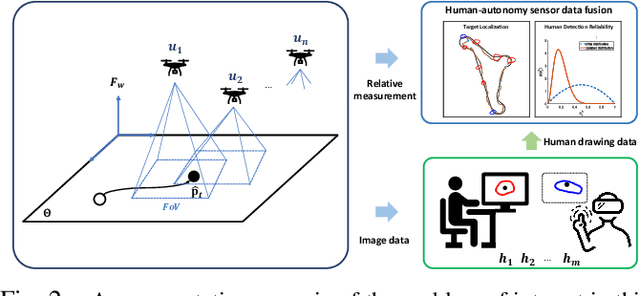
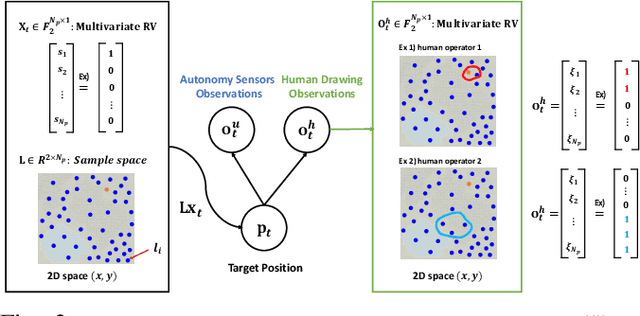
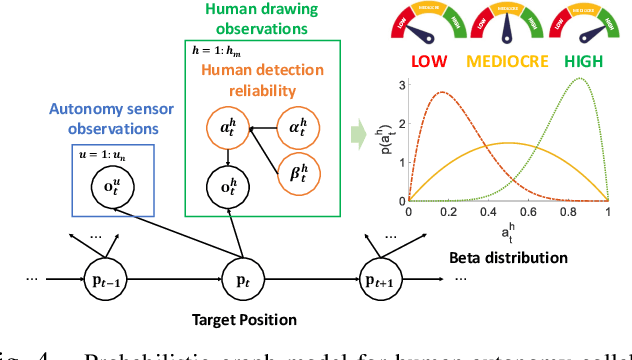
This paper considers a human-autonomy collaborative sensor data fusion for dynamic target localization in a Bayesian framework. To compensate for the shortcomings of an autonomous tracking system, we propose to collect spatial sensing information from human operators who visually monitor the target and can provide target localization information in the form of free sketches encircling the area where the target is located. Our focus in this paper is to construct an adaptive probabilistic model for human-provided inputs where the adaption terms capture the level of reliability of the human inputs. The next contribution of this paper is a novel joint Bayesian learning method to fuse human and autonomous sensor inputs in a manner that the dynamic changes in human detection reliability are also captured and accounted for. A unique aspect of this Bayesian modeling framework is its analytical closed-form update equations, endowing our method with significant computational efficiency. Simulations demonstrate our results.
Not all Fake News is Written: A Dataset and Analysis of Misleading Video Headlines
Oct 20, 2023
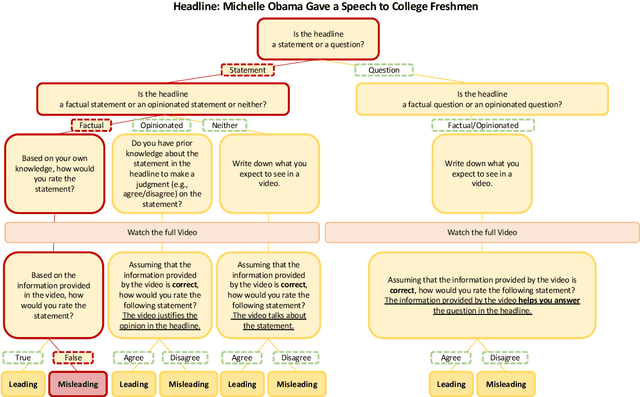
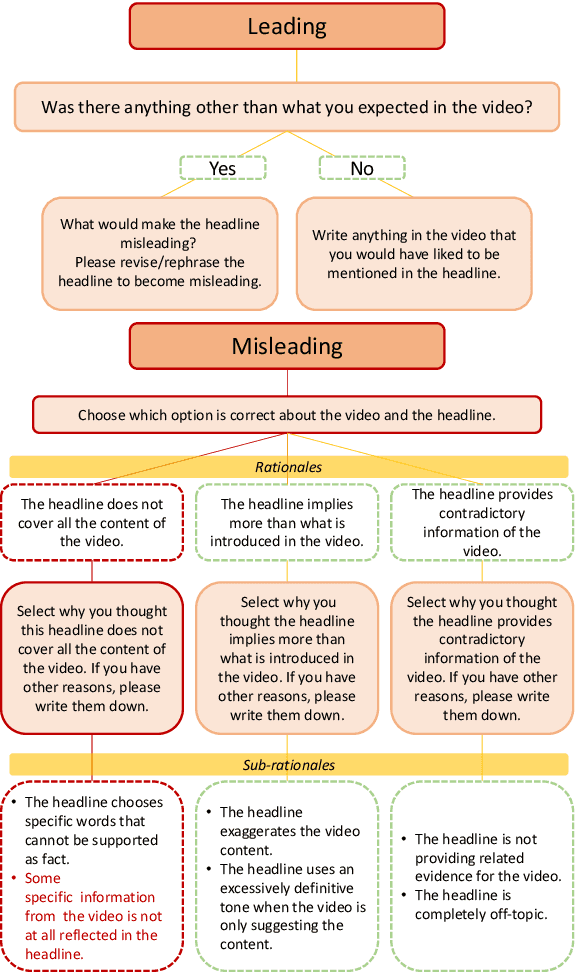
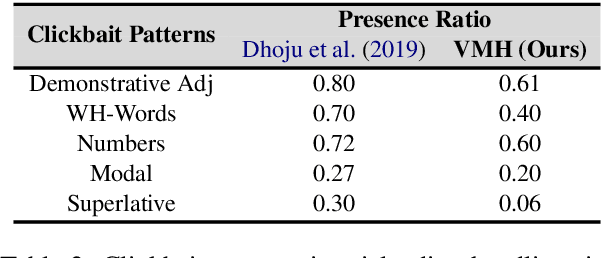
Polarization and the marketplace for impressions have conspired to make navigating information online difficult for users, and while there has been a significant effort to detect false or misleading text, multimodal datasets have received considerably less attention. To complement existing resources, we present multimodal Video Misleading Headline (VMH), a dataset that consists of videos and whether annotators believe the headline is representative of the video's contents. After collecting and annotating this dataset, we analyze multimodal baselines for detecting misleading headlines. Our annotation process also focuses on why annotators view a video as misleading, allowing us to better understand the interplay of annotators' background and the content of the videos.
Fundamental Limits of Membership Inference Attacks on Machine Learning Models
Oct 20, 2023Membership inference attacks (MIA) can reveal whether a particular data point was part of the training dataset, potentially exposing sensitive information about individuals. This article explores the fundamental statistical limitations associated with MIAs on machine learning models. More precisely, we first derive the statistical quantity that governs the effectiveness and success of such attacks. Then, we investigate several situations for which we provide bounds on this quantity of interest. This allows us to infer the accuracy of potential attacks as a function of the number of samples and other structural parameters of learning models, which in some cases can be directly estimated from the dataset.
AI Agent as Urban Planner: Steering Stakeholder Dynamics in Urban Planning via Consensus-based Multi-Agent Reinforcement Learning
Oct 25, 2023In urban planning, land use readjustment plays a pivotal role in aligning land use configurations with the current demands for sustainable urban development. However, present-day urban planning practices face two main issues. Firstly, land use decisions are predominantly dependent on human experts. Besides, while resident engagement in urban planning can promote urban sustainability and livability, it is challenging to reconcile the diverse interests of stakeholders. To address these challenges, we introduce a Consensus-based Multi-Agent Reinforcement Learning framework for real-world land use readjustment. This framework serves participatory urban planning, allowing diverse intelligent agents as stakeholder representatives to vote for preferred land use types. Within this framework, we propose a novel consensus mechanism in reward design to optimize land utilization through collective decision making. To abstract the structure of the complex urban system, the geographic information of cities is transformed into a spatial graph structure and then processed by graph neural networks. Comprehensive experiments on both traditional top-down planning and participatory planning methods from real-world communities indicate that our computational framework enhances global benefits and accommodates diverse interests, leading to improved satisfaction across different demographic groups. By integrating Multi-Agent Reinforcement Learning, our framework ensures that participatory urban planning decisions are more dynamic and adaptive to evolving community needs and provides a robust platform for automating complex real-world urban planning processes.
R$^3$ Prompting: Review, Rephrase and Resolve for Chain-of-Thought Reasoning in Large Language Models under Noisy Context
Oct 25, 2023With the help of Chain-of-Thought (CoT) prompting, Large Language Models (LLMs) have achieved remarkable performance on various reasoning tasks. However, most of them have been evaluated under noise-free context and the dilemma for LLMs to produce inaccurate results under the noisy context has not been fully investigated. Existing studies utilize trigger sentences to encourage LLMs to concentrate on the relevant information but the trigger has limited effect on final answer prediction. Inspired by interactive CoT method, where intermediate reasoning steps are promoted by multiple rounds of interaction between users and LLMs, we propose a novel prompting method, namely R$^3$ prompting, for CoT reasoning under noisy context. Specifically, R$^3$ prompting interacts with LLMs to perform key sentence extraction, variable declaration and answer prediction, which corresponds to a thought process of reviewing, rephrasing and resolving. The responses generated at the last interaction will perform as hints to guide toward the responses of the next interaction. Our experiments show that R$^3$ prompting significantly outperforms existing CoT prompting methods on five reasoning tasks under noisy context. With GPT-3.5-turbo, we observe 3.7% accuracy improvement on average on the reasoning tasks under noisy context compared to the most competitive prompting baseline. More analyses and ablation studies show the robustness and generalization of R$^3$ prompting method in solving reasoning tasks in LLMs under noisy context.
Balancing Augmentation with Edge-Utility Filter for Signed GNNs
Oct 25, 2023Signed graph neural networks (SGNNs) has recently drawn more attention as many real-world networks are signed networks containing two types of edges: positive and negative. The existence of negative edges affects the SGNN robustness on two aspects. One is the semantic imbalance as the negative edges are usually hard to obtain though they can provide potentially useful information. The other is the structural unbalance, e.g. unbalanced triangles, an indication of incompatible relationship among nodes. In this paper, we propose a balancing augmentation method to address the above two aspects for SGNNs. Firstly, the utility of each negative edge is measured by calculating its occurrence in unbalanced structures. Secondly, the original signed graph is selectively augmented with the use of (1) an edge perturbation regulator to balance the number of positive and negative edges and to determine the ratio of perturbed edges to original edges and (2) an edge utility filter to remove the negative edges with low utility to make the graph structure more balanced. Finally, a SGNN is trained on the augmented graph which effectively explores the credible relationships. A detailed theoretical analysis is also conducted to prove the effectiveness of each module. Experiments on five real-world datasets in link prediction demonstrate that our method has the advantages of effectiveness and generalization and can significantly improve the performance of SGNN backbones.
A Causal Disentangled Multi-Granularity Graph Classification Method
Oct 25, 2023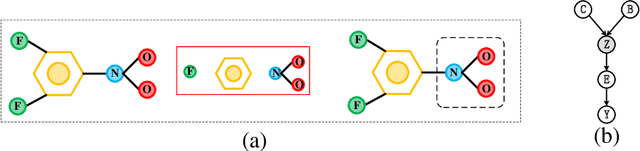

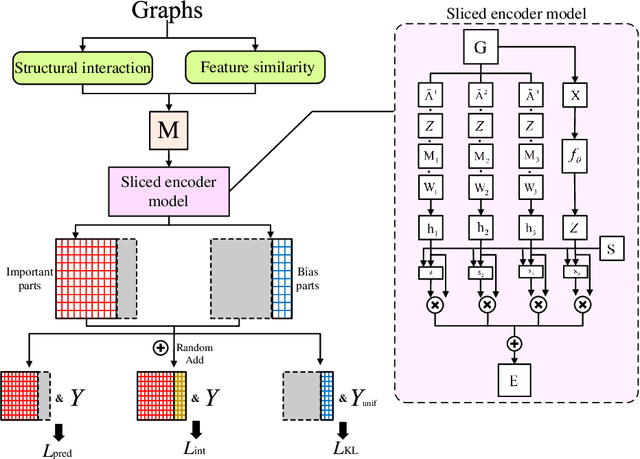
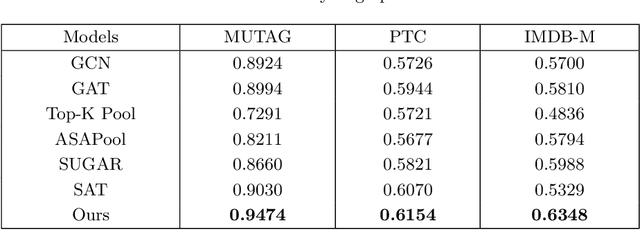
Graph data widely exists in real life, with large amounts of data and complex structures. It is necessary to map graph data to low-dimensional embedding. Graph classification, a critical graph task, mainly relies on identifying the important substructures within the graph. At present, some graph classification methods do not combine the multi-granularity characteristics of graph data. This lack of granularity distinction in modeling leads to a conflation of key information and false correlations within the model. So, achieving the desired goal of a credible and interpretable model becomes challenging. This paper proposes a causal disentangled multi-granularity graph representation learning method (CDM-GNN) to solve this challenge. The CDM-GNN model disentangles the important substructures and bias parts within the graph from a multi-granularity perspective. The disentanglement of the CDM-GNN model reveals important and bias parts, forming the foundation for its classification task, specifically, model interpretations. The CDM-GNN model exhibits strong classification performance and generates explanatory outcomes aligning with human cognitive patterns. In order to verify the effectiveness of the model, this paper compares the three real-world datasets MUTAG, PTC, and IMDM-M. Six state-of-the-art models, namely GCN, GAT, Top-k, ASAPool, SUGAR, and SAT are employed for comparison purposes. Additionally, a qualitative analysis of the interpretation results is conducted.