 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Local Non-Cooperative Games with Principled Player Selection for Scalable Motion Planning
Oct 19, 2023
Game-theoretic motion planners are a powerful tool for the control of interactive multi-agent robot systems. Indeed, contrary to predict-then-plan paradigms, game-theoretic planners do not ignore the interactive nature of the problem, and simultaneously predict the behaviour of other agents while considering change in one's policy. This, however, comes at the expense of computational complexity, especially as the number of agents considered grows. In fact, planning with more than a handful of agents can quickly become intractable, disqualifying game-theoretic planners as possible candidates for large scale planning. In this paper, we propose a planning algorithm enabling the use of game-theoretic planners in robot systems with a large number of agents. Our planner is based on the reality of locality of information and thus deploys local games with a selected subset of agents in a receding horizon fashion to plan collision avoiding trajectories. We propose five different principled schemes for selecting game participants and compare their collision avoidance performance. We observe that the use of Control Barrier Functions for priority ranking is a potent solution to the player selection problem for motion planning.
MolCA: Molecular Graph-Language Modeling with Cross-Modal Projector and Uni-Modal Adapter
Oct 19, 2023Language Models (LMs) have demonstrated impressive molecule understanding ability on various 1D text-related tasks. However, they inherently lack 2D graph perception - a critical ability of human professionals in comprehending molecules' topological structures. To bridge this gap, we propose MolCA: Molecular Graph-Language Modeling with Cross-Modal Projector and Uni-Modal Adapter. MolCA enables an LM (e.g., Galactica) to understand both text- and graph-based molecular contents via the cross-modal projector. Specifically, the cross-modal projector is implemented as a Q-Former to connect a graph encoder's representation space and an LM's text space. Further, MolCA employs a uni-modal adapter (i.e., LoRA) for the LM's efficient adaptation to downstream tasks. Unlike previous studies that couple an LM with a graph encoder via cross-modal contrastive learning, MolCA retains the LM's ability of open-ended text generation and augments it with 2D graph information. To showcase its effectiveness, we extensively benchmark MolCA on tasks of molecule captioning, IUPAC name prediction, and molecule-text retrieval, on which MolCA significantly outperforms the baselines. Our codes and checkpoints can be found at https://github.com/acharkq/MolCA.
Co-Learning Semantic-aware Unsupervised Segmentation for Pathological Image Registration
Oct 19, 2023The registration of pathological images plays an important role in medical applications. Despite its significance, most researchers in this field primarily focus on the registration of normal tissue into normal tissue. The negative impact of focal tissue, such as the loss of spatial correspondence information and the abnormal distortion of tissue, are rarely considered. In this paper, we propose GIRNet, a novel unsupervised approach for pathological image registration by incorporating segmentation and inpainting through the principles of Generation, Inpainting, and Registration (GIR). The registration, segmentation, and inpainting modules are trained simultaneously in a co-learning manner so that the segmentation of the focal area and the registration of inpainted pairs can improve collaboratively. Overall, the registration of pathological images is achieved in a completely unsupervised learning framework. Experimental results on multiple datasets, including Magnetic Resonance Imaging (MRI) of T1 sequences, demonstrate the efficacy of our proposed method. Our results show that our method can accurately achieve the registration of pathological images and identify lesions even in challenging imaging modalities. Our unsupervised approach offers a promising solution for the efficient and cost-effective registration of pathological images. Our code is available at https://github.com/brain-intelligence-lab/GIRNet.
* 13 pages, 7 figures, published in Medical Image Computing and Computer Assisted Intervention (MICCAI) 2023
Interpreting and Controlling Vision Foundation Models via Text Explanations
Oct 16, 2023Large-scale pre-trained vision foundation models, such as CLIP, have become de facto backbones for various vision tasks. However, due to their black-box nature, understanding the underlying rules behind these models' predictions and controlling model behaviors have remained open challenges. We present a framework for interpreting vision transformer's latent tokens with natural language. Given a latent token, our framework retains its semantic information to the final layer using transformer's local operations and retrieves the closest text for explanation. Our approach enables understanding of model visual reasoning procedure without needing additional model training or data collection. Based on the obtained interpretations, our framework allows for model editing that controls model reasoning behaviors and improves model robustness against biases and spurious correlations.
End-to-end Multichannel Speaker-Attributed ASR: Speaker Guided Decoder and Input Feature Analysis
Oct 16, 2023We present an end-to-end multichannel speaker-attributed automatic speech recognition (MC-SA-ASR) system that combines a Conformer-based encoder with multi-frame crosschannel attention and a speaker-attributed Transformer-based decoder. To the best of our knowledge, this is the first model that efficiently integrates ASR and speaker identification modules in a multichannel setting. On simulated mixtures of LibriSpeech data, our system reduces the word error rate (WER) by up to 12% and 16% relative compared to previously proposed single-channel and multichannel approaches, respectively. Furthermore, we investigate the impact of different input features, including multichannel magnitude and phase information, on the ASR performance. Finally, our experiments on the AMI corpus confirm the effectiveness of our system for real-world multichannel meeting transcription.
Spatial Sigma-Delta Modulation for Coarsely Quantized Massive MIMO Downlink: Flexible Designs by Convex Optimization
Oct 22, 2023This paper considers the context of multiuser massive MIMO downlink precoding with low-resolution digital-to-analog converters (DACs) at the transmitter. This subject is motivated by the consideration that it is expensive to employ high-resolution DACs for practical massive MIMO implementations. The challenge with using low-resolution DACs is to overcome the detrimental quantization error effects. Recently, spatial Sigma-Delta modulation has arisen as a viable way to put quantization errors under control. This approach takes insight from temporal Sigma-Delta modulation in classical DAC studies. Assuming a 1D uniform linear transmit antenna array, the principle is to shape the quantization errors in space such that the shaped quantization errors are pushed away from the user-serving angle sector. In the previous studies, spatial Sigma-Delta modulation was performed by direct application of the basic first- and second-order modulators from the Sigma-Delta literature. In this paper, we develop a general Sigma-Delta modulator design framework for any given order, for any given number of quantization levels, and for any given angle sector. We formulate our design as a problem of maximizing the signal-to-quantization-and-noise ratios experienced by the users. The formulated problem is convex and can be efficiently solved by available solvers. Our proposed framework offers the alternative option of focused quantization error suppression in accordance with channel state information. Our framework can also be extended to 2D planar transmit antenna arrays. We perform numerical study under different operating conditions, and the numerical results suggest that, given a moderate number of quantization levels, say, 5 to 7 levels, our optimization-based Sigma-Delta modulation schemes can lead to bit error rate performance close to that of the unquantized counterpart.
Decoding the Silent Majority: Inducing Belief Augmented Social Graph with Large Language Model for Response Forecasting
Oct 20, 2023Automatic response forecasting for news media plays a crucial role in enabling content producers to efficiently predict the impact of news releases and prevent unexpected negative outcomes such as social conflict and moral injury. To effectively forecast responses, it is essential to develop measures that leverage the social dynamics and contextual information surrounding individuals, especially in cases where explicit profiles or historical actions of the users are limited (referred to as lurkers). As shown in a previous study, 97% of all tweets are produced by only the most active 25% of users. However, existing approaches have limited exploration of how to best process and utilize these important features. To address this gap, we propose a novel framework, named SocialSense, that leverages a large language model to induce a belief-centered graph on top of an existent social network, along with graph-based propagation to capture social dynamics. We hypothesize that the induced graph that bridges the gap between distant users who share similar beliefs allows the model to effectively capture the response patterns. Our method surpasses existing state-of-the-art in experimental evaluations for both zero-shot and supervised settings, demonstrating its effectiveness in response forecasting. Moreover, the analysis reveals the framework's capability to effectively handle unseen user and lurker scenarios, further highlighting its robustness and practical applicability.
DeepFracture: A Generative Approach for Predicting Brittle Fractures
Oct 20, 2023
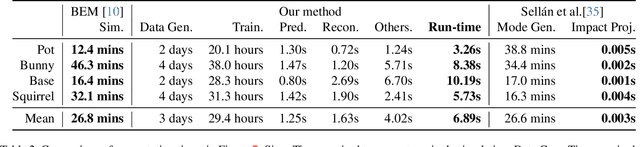
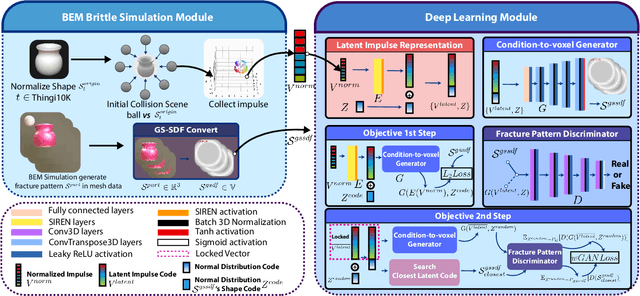
In the realm of brittle fracture animation, generating realistic destruction animations with physics simulation techniques can be computationally expensive. Although methods using Voronoi diagrams or pre-fractured patterns work for real-time applications, they often lack realism in portraying brittle fractures. This paper introduces a novel learning-based approach for seamlessly merging realistic brittle fracture animations with rigid-body simulations. Our method utilizes BEM brittle fracture simulations to create fractured patterns and collision conditions for a given shape, which serve as training data for the learning process. To effectively integrate collision conditions and fractured shapes into a deep learning framework, we introduce the concept of latent impulse representation and geometrically-segmented signed distance function (GS-SDF). The latent impulse representation serves as input, capturing information about impact forces on the shape's surface. Simultaneously, a GS-SDF is used as the output representation of the fractured shape. To address the challenge of optimizing multiple fractured pattern targets with a single latent code, we propose an eight-dimensional latent space based on a normal distribution code within our latent impulse representation design. This adaptation effectively transforms our neural network into a generative one. Our experimental results demonstrate that our approach can generate significantly more detailed brittle fractures compared to existing techniques, all while maintaining commendable computational efficiency during run-time.
POTLoc: Pseudo-Label Oriented Transformer for Point-Supervised Temporal Action Localization
Oct 20, 2023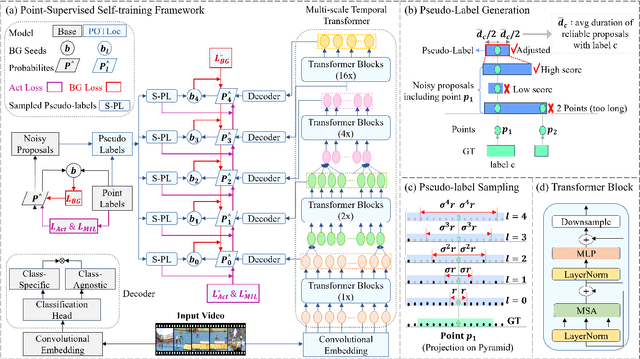
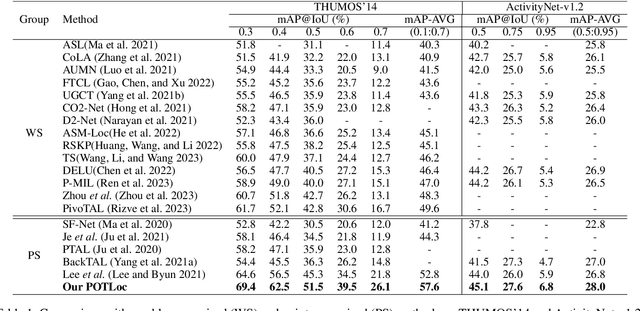
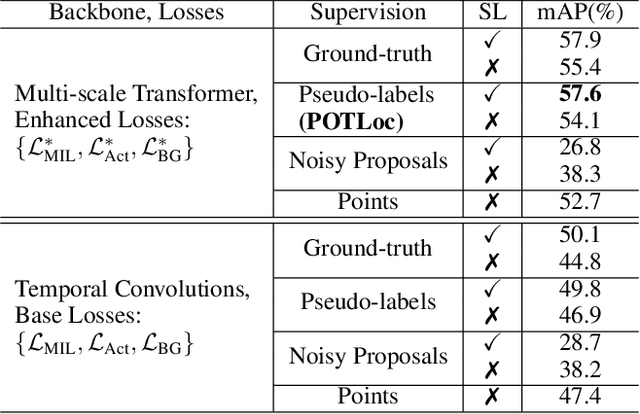
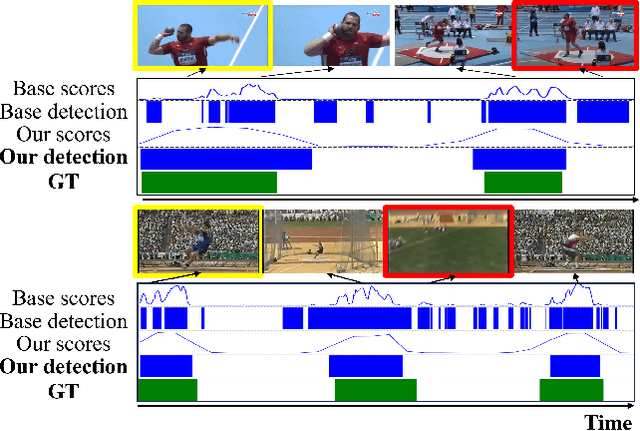
This paper tackles the challenge of point-supervised temporal action detection, wherein only a single frame is annotated for each action instance in the training set. Most of the current methods, hindered by the sparse nature of annotated points, struggle to effectively represent the continuous structure of actions or the inherent temporal and semantic dependencies within action instances. Consequently, these methods frequently learn merely the most distinctive segments of actions, leading to the creation of incomplete action proposals. This paper proposes POTLoc, a Pseudo-label Oriented Transformer for weakly-supervised Action Localization utilizing only point-level annotation. POTLoc is designed to identify and track continuous action structures via a self-training strategy. The base model begins by generating action proposals solely with point-level supervision. These proposals undergo refinement and regression to enhance the precision of the estimated action boundaries, which subsequently results in the production of `pseudo-labels' to serve as supplementary supervisory signals. The architecture of the model integrates a transformer with a temporal feature pyramid to capture video snippet dependencies and model actions of varying duration. The pseudo-labels, providing information about the coarse locations and boundaries of actions, assist in guiding the transformer for enhanced learning of action dynamics. POTLoc outperforms the state-of-the-art point-supervised methods on THUMOS'14 and ActivityNet-v1.2 datasets, showing a significant improvement of 5% average mAP on the former.
Three-Dimensional Medical Image Fusion with Deformable Cross-Attention
Oct 10, 2023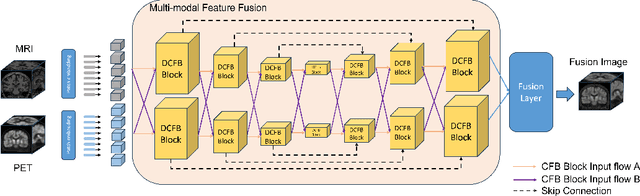
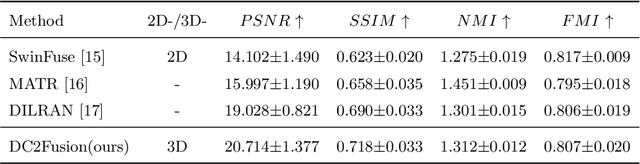
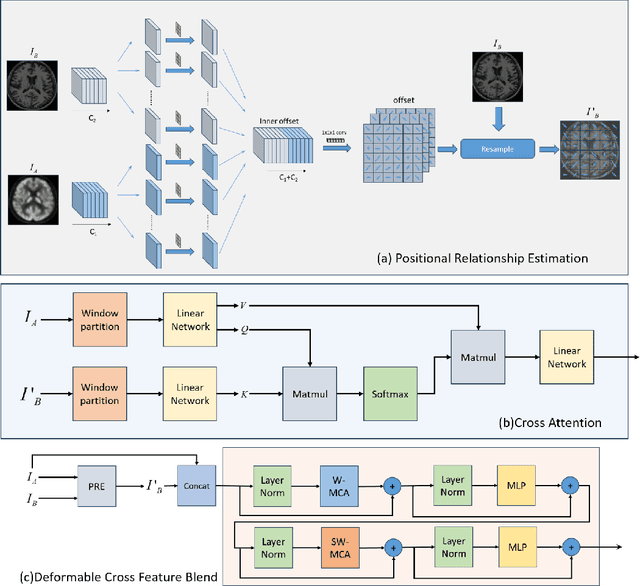
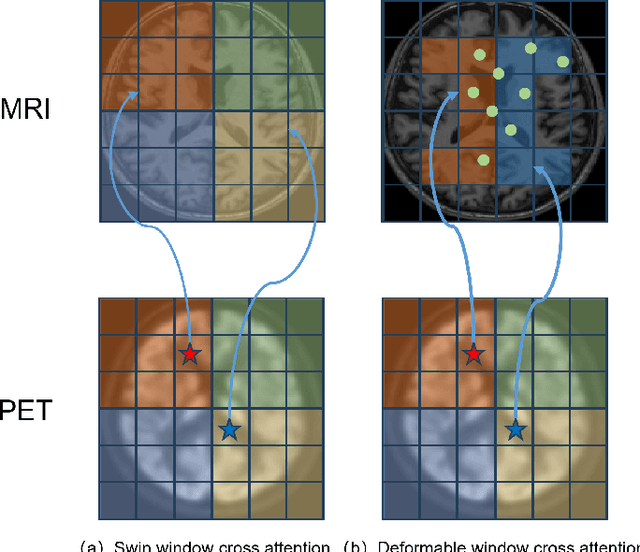
Multimodal medical image fusion plays an instrumental role in several areas of medical image processing, particularly in disease recognition and tumor detection. Traditional fusion methods tend to process each modality independently before combining the features and reconstructing the fusion image. However, this approach often neglects the fundamental commonalities and disparities between multimodal information. Furthermore, the prevailing methodologies are largely confined to fusing two-dimensional (2D) medical image slices, leading to a lack of contextual supervision in the fusion images and subsequently, a decreased information yield for physicians relative to three-dimensional (3D) images. In this study, we introduce an innovative unsupervised feature mutual learning fusion network designed to rectify these limitations. Our approach incorporates a Deformable Cross Feature Blend (DCFB) module that facilitates the dual modalities in discerning their respective similarities and differences. We have applied our model to the fusion of 3D MRI and PET images obtained from 660 patients in the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset. Through the application of the DCFB module, our network generates high-quality MRI-PET fusion images. Experimental results demonstrate that our method surpasses traditional 2D image fusion methods in performance metrics such as Peak Signal to Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM). Importantly, the capacity of our method to fuse 3D images enhances the information available to physicians and researchers, thus marking a significant step forward in the field. The code will soon be available online.