 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Aggregating Local and Global Features via Selective State Spaces Model for Efficient Image Deblurring
Mar 29, 2024
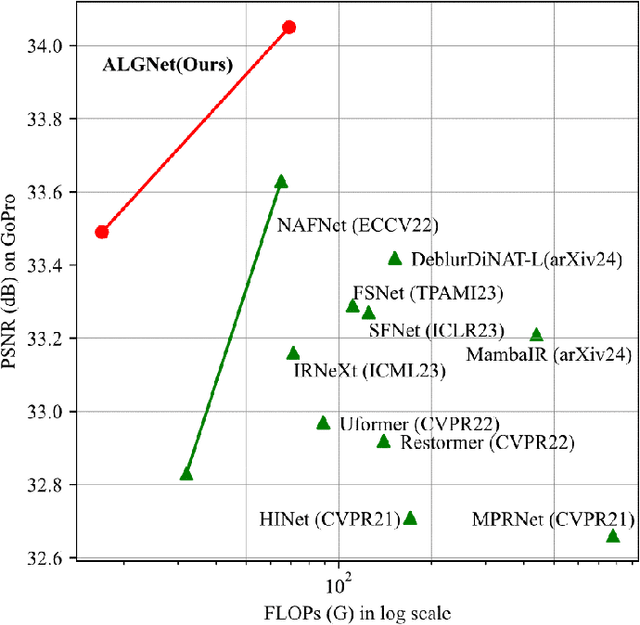
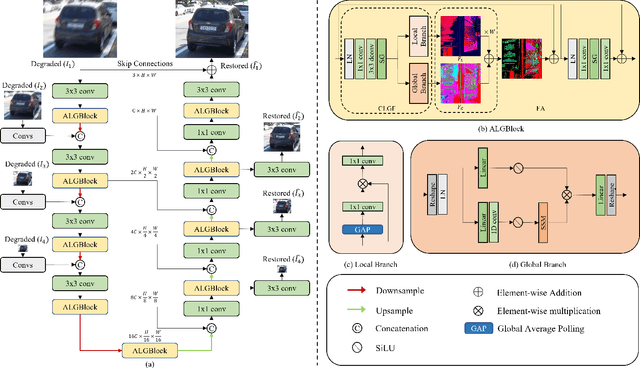

Image deblurring is a process of restoring a high quality image from the corresponding blurred image. Significant progress in this field has been made possible by the emergence of various effective deep learning models, including CNNs and Transformers. However, these methods often face the dilemma between eliminating long-range blur degradation perturbations and maintaining computational efficiency, which hinders their practical application. To address this issue, we propose an efficient image deblurring network that leverages selective structured state spaces model to aggregate enriched and accurate features. Specifically, we design an aggregate local and global block (ALGBlock) to capture and fuse both local invariant properties and non-local information. The ALGBlock consists of two blocks: (1) The local block models local connectivity using simplified channel attention. (2) The global block captures long-range dependency features with linear complexity through selective structured state spaces. Nevertheless, we note that the image details are local features of images, we accentuate the local part for restoration by recalibrating the weight when aggregating the two branches for recovery. Experimental results demonstrate that the proposed method outperforms state-of-the-art approaches on widely used benchmarks, highlighting its superior performance.
Binarized Low-light Raw Video Enhancement
Mar 29, 2024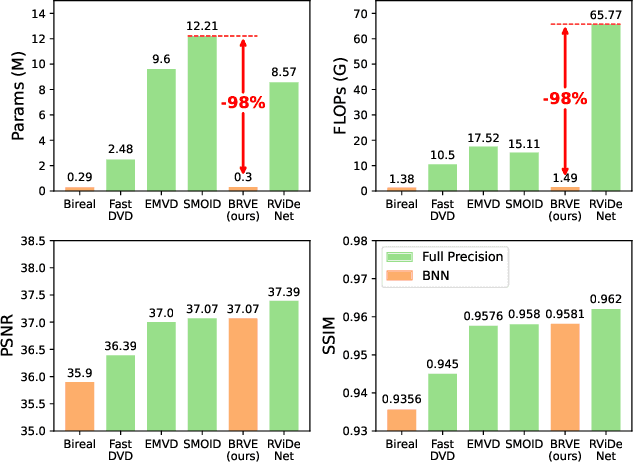
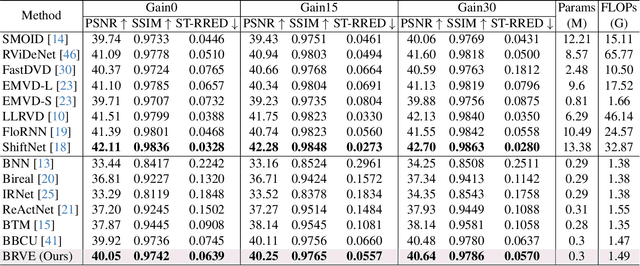
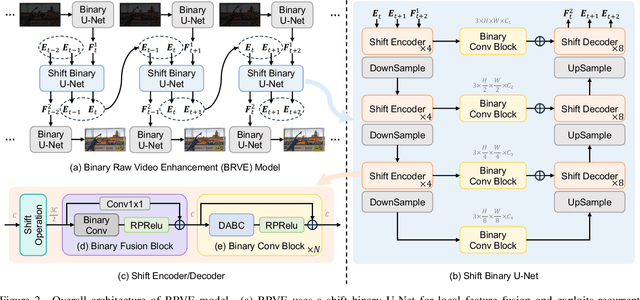
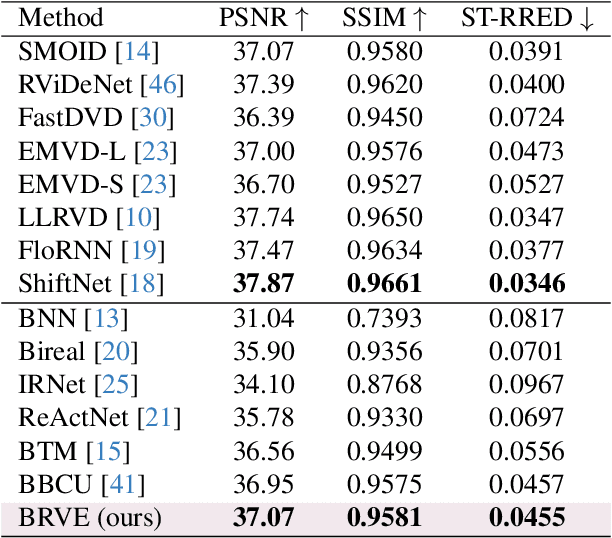
Recently, deep neural networks have achieved excellent performance on low-light raw video enhancement. However, they often come with high computational complexity and large memory costs, which hinder their applications on resource-limited devices. In this paper, we explore the feasibility of applying the extremely compact binary neural network (BNN) to low-light raw video enhancement. Nevertheless, there are two main issues with binarizing video enhancement models. One is how to fuse the temporal information to improve low-light denoising without complex modules. The other is how to narrow the performance gap between binary convolutions with the full precision ones. To address the first issue, we introduce a spatial-temporal shift operation, which is easy-to-binarize and effective. The temporal shift efficiently aggregates the features of neighbor frames and the spatial shift handles the misalignment caused by the large motion in videos. For the second issue, we present a distribution-aware binary convolution, which captures the distribution characteristics of real-valued input and incorporates them into plain binary convolutions to alleviate the degradation in performance. Extensive quantitative and qualitative experiments have shown our high-efficiency binarized low-light raw video enhancement method can attain a promising performance.
Context-Aware Integration of Language and Visual References for Natural Language Tracking
Mar 29, 2024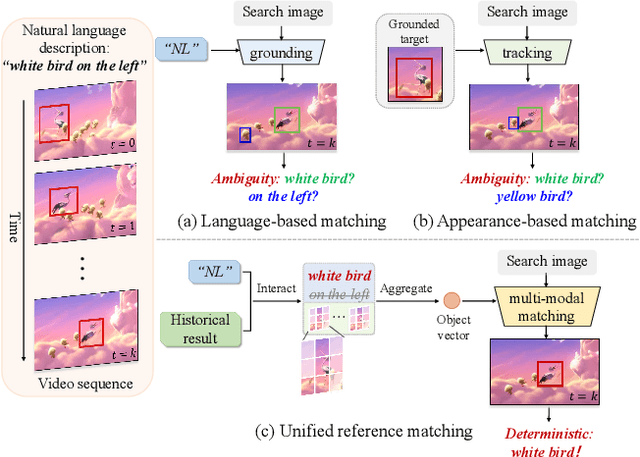

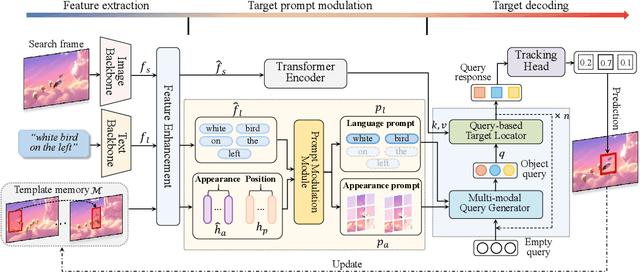
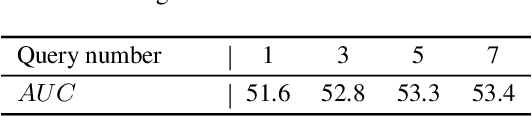
Tracking by natural language specification (TNL) aims to consistently localize a target in a video sequence given a linguistic description in the initial frame. Existing methodologies perform language-based and template-based matching for target reasoning separately and merge the matching results from two sources, which suffer from tracking drift when language and visual templates miss-align with the dynamic target state and ambiguity in the later merging stage. To tackle the issues, we propose a joint multi-modal tracking framework with 1) a prompt modulation module to leverage the complementarity between temporal visual templates and language expressions, enabling precise and context-aware appearance and linguistic cues, and 2) a unified target decoding module to integrate the multi-modal reference cues and executes the integrated queries on the search image to predict the target location in an end-to-end manner directly. This design ensures spatio-temporal consistency by leveraging historical visual information and introduces an integrated solution, generating predictions in a single step. Extensive experiments conducted on TNL2K, OTB-Lang, LaSOT, and RefCOCOg validate the efficacy of our proposed approach. The results demonstrate competitive performance against state-of-the-art methods for both tracking and grounding.
On Large Language Models' Hallucination with Regard to Known Facts
Mar 29, 2024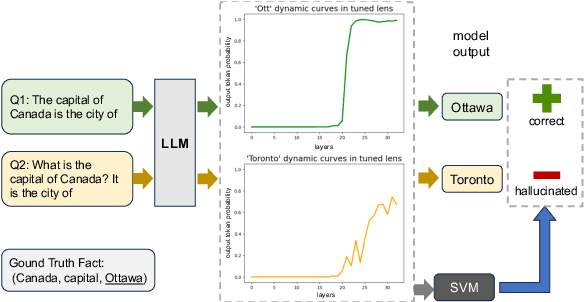
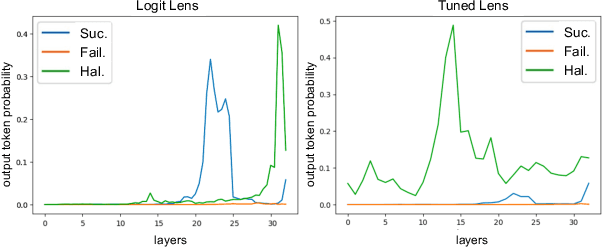
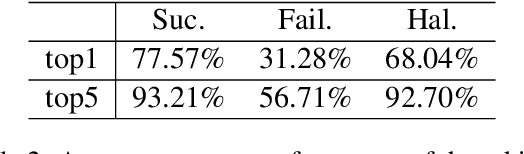
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88\% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
Vision-Based Force Estimation for Minimally Invasive Telesurgery Through Contact Detection and Local Stiffness Models
Mar 27, 2024In minimally invasive telesurgery, obtaining accurate force information is difficult due to the complexities of in-vivo end effector force sensing. This constrains development and implementation of haptic feedback and force-based automated performance metrics, respectively. Vision-based force sensing approaches using deep learning are a promising alternative to intrinsic end effector force sensing. However, they have limited ability to generalize to novel scenarios, and require learning on high-quality force sensor training data that can be difficult to obtain. To address these challenges, this paper presents a novel vision-based contact-conditional approach for force estimation in telesurgical environments. Our method leverages supervised learning with human labels and end effector position data to train deep neural networks. Predictions from these trained models are optionally combined with robot joint torque information to estimate forces indirectly from visual data. We benchmark our method against ground truth force sensor data and demonstrate generality by fine-tuning to novel surgical scenarios in a data-efficient manner. Our methods demonstrated greater than 90% accuracy on contact detection and less than 10% force prediction error. These results suggest potential usefulness of contact-conditional force estimation for sensory substitution haptic feedback and tissue handling skill evaluation in clinical settings.
LocalStyleFool: Regional Video Style Transfer Attack Using Segment Anything Model
Mar 27, 2024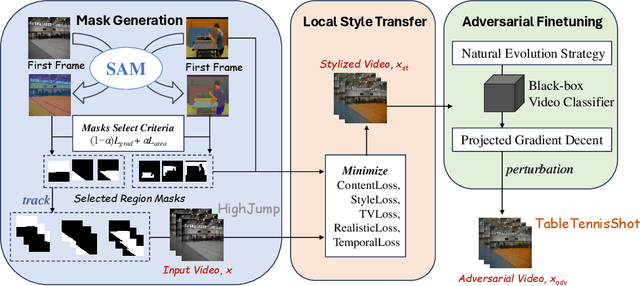
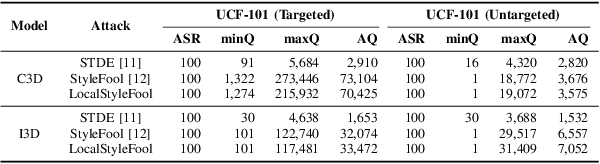
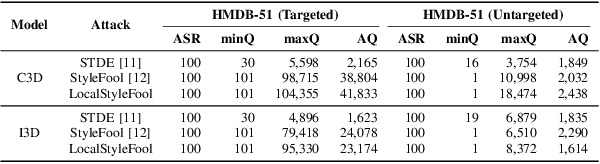

Previous work has shown that well-crafted adversarial perturbations can threaten the security of video recognition systems. Attackers can invade such models with a low query budget when the perturbations are semantic-invariant, such as StyleFool. Despite the query efficiency, the naturalness of the minutia areas still requires amelioration, since StyleFool leverages style transfer to all pixels in each frame. To close the gap, we propose LocalStyleFool, an improved black-box video adversarial attack that superimposes regional style-transfer-based perturbations on videos. Benefiting from the popularity and scalably usability of Segment Anything Model (SAM), we first extract different regions according to semantic information and then track them through the video stream to maintain the temporal consistency. Then, we add style-transfer-based perturbations to several regions selected based on the associative criterion of transfer-based gradient information and regional area. Perturbation fine adjustment is followed to make stylized videos adversarial. We demonstrate that LocalStyleFool can improve both intra-frame and inter-frame naturalness through a human-assessed survey, while maintaining competitive fooling rate and query efficiency. Successful experiments on the high-resolution dataset also showcase that scrupulous segmentation of SAM helps to improve the scalability of adversarial attacks under high-resolution data.
Efficient Heatmap-Guided 6-Dof Grasp Detection in Cluttered Scenes
Mar 27, 2024Fast and robust object grasping in clutter is a crucial component of robotics. Most current works resort to the whole observed point cloud for 6-Dof grasp generation, ignoring the guidance information excavated from global semantics, thus limiting high-quality grasp generation and real-time performance. In this work, we show that the widely used heatmaps are underestimated in the efficiency of 6-Dof grasp generation. Therefore, we propose an effective local grasp generator combined with grasp heatmaps as guidance, which infers in a global-to-local semantic-to-point way. Specifically, Gaussian encoding and the grid-based strategy are applied to predict grasp heatmaps as guidance to aggregate local points into graspable regions and provide global semantic information. Further, a novel non-uniform anchor sampling mechanism is designed to improve grasp accuracy and diversity. Benefiting from the high-efficiency encoding in the image space and focusing on points in local graspable regions, our framework can perform high-quality grasp detection in real-time and achieve state-of-the-art results. In addition, real robot experiments demonstrate the effectiveness of our method with a success rate of 94% and a clutter completion rate of 100%. Our code is available at https://github.com/THU-VCLab/HGGD.
Chain-of-Action: Faithful and Multimodal Question Answering through Large Language Models
Mar 26, 2024We present a Chain-of-Action (CoA) framework for multimodal and retrieval-augmented Question-Answering (QA). Compared to the literature, CoA overcomes two major challenges of current QA applications: (i) unfaithful hallucination that is inconsistent with real-time or domain facts and (ii) weak reasoning performance over compositional information. Our key contribution is a novel reasoning-retrieval mechanism that decomposes a complex question into a reasoning chain via systematic prompting and pre-designed actions. Methodologically, we propose three types of domain-adaptable `Plug-and-Play' actions for retrieving real-time information from heterogeneous sources. We also propose a multi-reference faith score (MRFS) to verify and resolve conflicts in the answers. Empirically, we exploit both public benchmarks and a Web3 case study to demonstrate the capability of CoA over other methods.
Understanding Long Videos in One Multimodal Language Model Pass
Mar 25, 2024Large Language Models (LLMs), known to contain a strong awareness of world knowledge, have allowed recent approaches to achieve excellent performance on Long-Video Understanding benchmarks, but at high inference costs. In this work, we first propose Likelihood Selection, a simple technique that unlocks faster inference in autoregressive LLMs for multiple-choice tasks common in long-video benchmarks. In addition to faster inference, we discover the resulting models to yield surprisingly good accuracy on long-video tasks, even with no video specific information. Building on this, we inject video-specific object-centric information extracted from off-the-shelf pre-trained models and utilize natural language as a medium for information fusion. Our resulting Multimodal Video Understanding (MVU) framework demonstrates state-of-the-art performance across long-video and fine-grained action recognition benchmarks. Code available at: https://github.com/kahnchana/mvu
MineLand: Simulating Large-Scale Multi-Agent Interactions with Limited Multimodal Senses and Physical Needs
Mar 28, 2024Conventional multi-agent simulators often assume perfect information and limitless capabilities, hindering the ecological validity of social interactions. We propose a multi-agent Minecraft simulator, MineLand, that bridges this gap by introducing limited multimodal senses and physical needs. Our simulator supports up to 48 agents with limited visual, auditory, and environmental awareness, forcing them to actively communicate and collaborate to fulfill physical needs like food and resources. This fosters dynamic and valid multi-agent interactions. We further introduce an AI agent framework, Alex, inspired by multitasking theory, enabling agents to handle intricate coordination and scheduling. Our experiments demonstrate that the simulator, the corresponding benchmark, and the AI agent framework contribute to more ecological and nuanced collective behavior. The source code of MineLand and Alex is openly available at https://github.com/cocacola-lab/MineLand.