 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Byzantine-Resilient Decentralized Multi-Armed Bandits
Oct 11, 2023
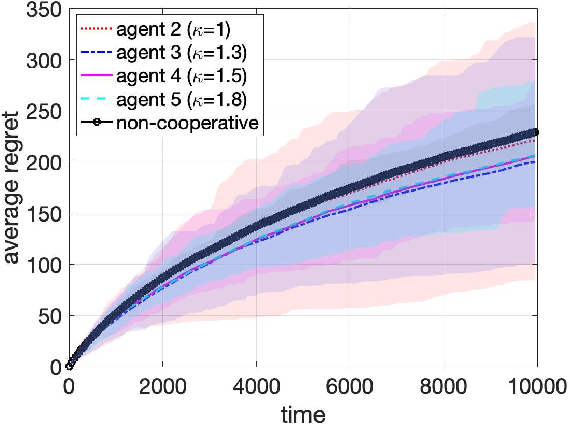
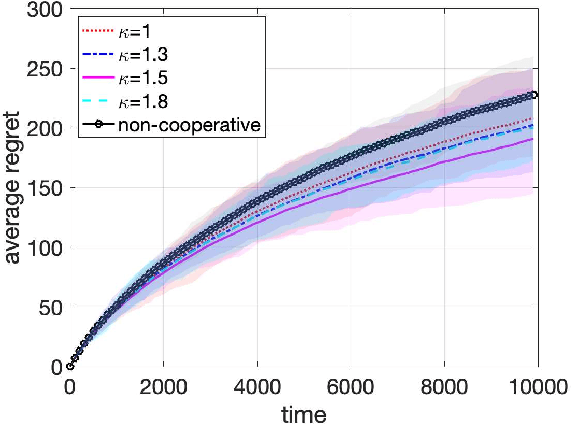
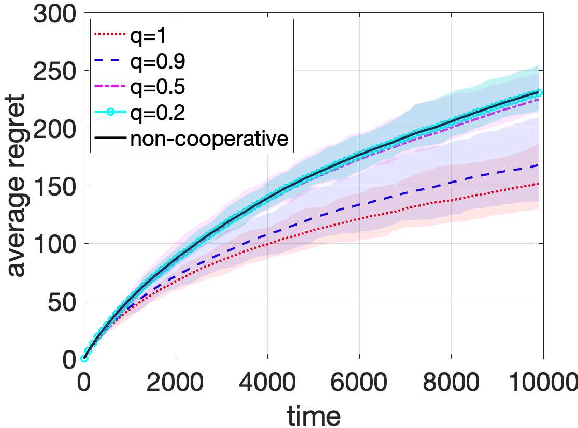
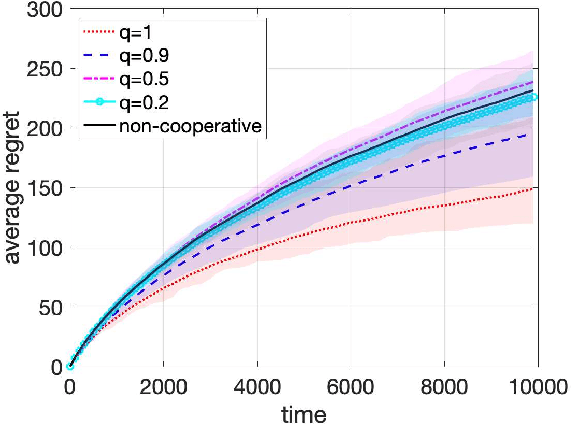
In decentralized cooperative multi-armed bandits (MAB), each agent observes a distinct stream of rewards, and seeks to exchange information with others to select a sequence of arms so as to minimize its regret. Agents in the cooperative setting can outperform a single agent running a MAB method such as Upper-Confidence Bound (UCB) independently. In this work, we study how to recover such salient behavior when an unknown fraction of the agents can be Byzantine, that is, communicate arbitrarily wrong information in the form of reward mean-estimates or confidence sets. This framework can be used to model attackers in computer networks, instigators of offensive content into recommender systems, or manipulators of financial markets. Our key contribution is the development of a fully decentralized resilient upper confidence bound (UCB) algorithm that fuses an information mixing step among agents with a truncation of inconsistent and extreme values. This truncation step enables us to establish that the performance of each normal agent is no worse than the classic single-agent UCB1 algorithm in terms of regret, and more importantly, the cumulative regret of all normal agents is strictly better than the non-cooperative case, provided that each agent has at least 3f+1 neighbors where f is the maximum possible Byzantine agents in each agent's neighborhood. Extensions to time-varying neighbor graphs, and minimax lower bounds are further established on the achievable regret. Experiments corroborate the merits of this framework in practice.
Model-based Clustering of Individuals' Ecological Momentary Assessment Time-series Data for Improving Forecasting Performance
Oct 11, 2023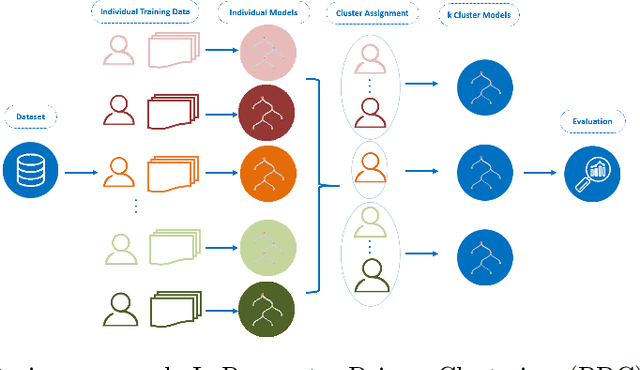
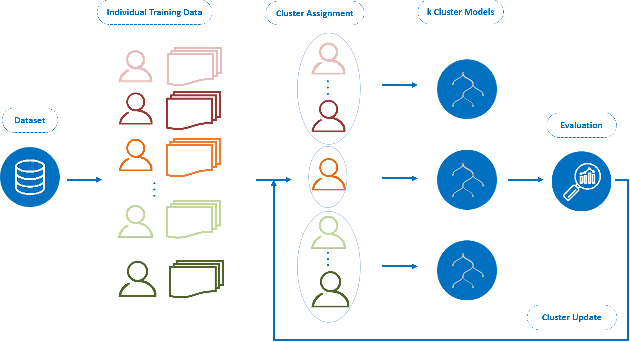
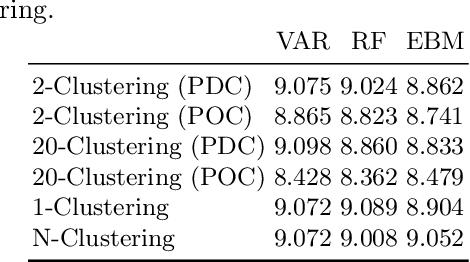
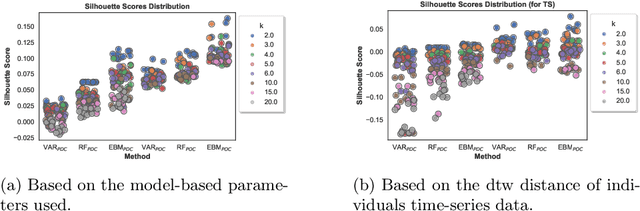
Through Ecological Momentary Assessment (EMA) studies, a number of time-series data is collected across multiple individuals, continuously monitoring various items of emotional behavior. Such complex data is commonly analyzed in an individual level, using personalized models. However, it is believed that additional information of similar individuals is likely to enhance these models leading to better individuals' description. Thus, clustering is investigated with an aim to group together the most similar individuals, and subsequently use this information in group-based models in order to improve individuals' predictive performance. More specifically, two model-based clustering approaches are examined, where the first is using model-extracted parameters of personalized models, whereas the second is optimized on the model-based forecasting performance. Both methods are then analyzed using intrinsic clustering evaluation measures (e.g. Silhouette coefficients) as well as the performance of a downstream forecasting scheme, where each forecasting group-model is devoted to describe all individuals belonging to one cluster. Among these, clustering based on performance shows the best results, in terms of all examined evaluation measures. As another level of evaluation, those group-models' performance is compared to three baseline scenarios, the personalized, the all-in-one group and the random group-based concept. According to this comparison, the superiority of clustering-based methods is again confirmed, indicating that the utilization of group-based information could be effectively enhance the overall performance of all individuals' data.
Multimodal Graph Learning for Generative Tasks
Oct 11, 2023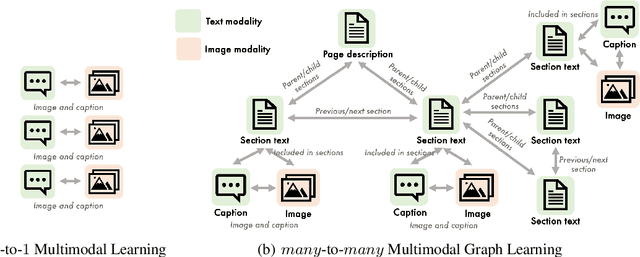
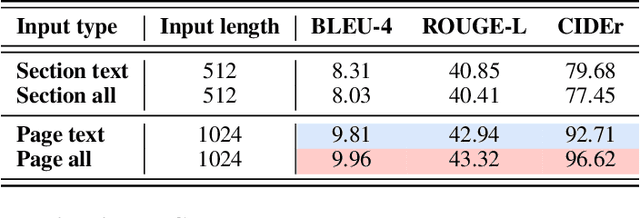
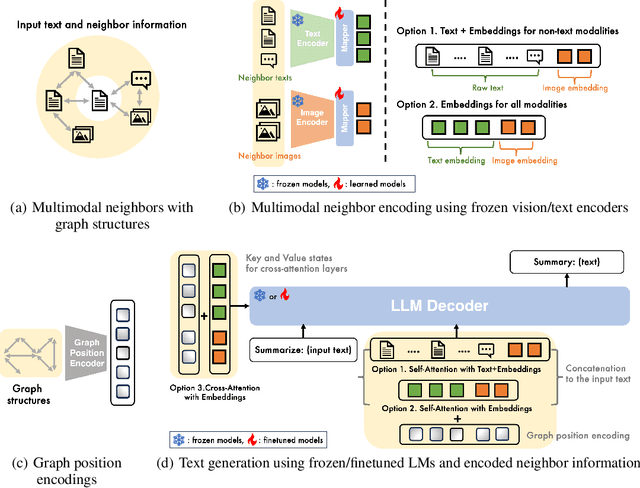
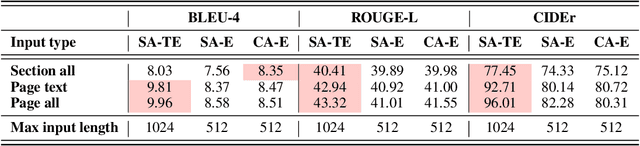
Multimodal learning combines multiple data modalities, broadening the types and complexity of data our models can utilize: for example, from plain text to image-caption pairs. Most multimodal learning algorithms focus on modeling simple one-to-one pairs of data from two modalities, such as image-caption pairs, or audio-text pairs. However, in most real-world settings, entities of different modalities interact with each other in more complex and multifaceted ways, going beyond one-to-one mappings. We propose to represent these complex relationships as graphs, allowing us to capture data with any number of modalities, and with complex relationships between modalities that can flexibly vary from one sample to another. Toward this goal, we propose Multimodal Graph Learning (MMGL), a general and systematic framework for capturing information from multiple multimodal neighbors with relational structures among them. In particular, we focus on MMGL for generative tasks, building upon pretrained Language Models (LMs), aiming to augment their text generation with multimodal neighbor contexts. We study three research questions raised by MMGL: (1) how can we infuse multiple neighbor information into the pretrained LMs, while avoiding scalability issues? (2) how can we infuse the graph structure information among multimodal neighbors into the LMs? and (3) how can we finetune the pretrained LMs to learn from the neighbor context in a parameter-efficient manner? We conduct extensive experiments to answer these three questions on MMGL and analyze the empirical results to pave the way for future MMGL research.
DepWiGNN: A Depth-wise Graph Neural Network for Multi-hop Spatial Reasoning in Text
Oct 19, 2023Spatial reasoning in text plays a crucial role in various real-world applications. Existing approaches for spatial reasoning typically infer spatial relations from pure text, which overlook the gap between natural language and symbolic structures. Graph neural networks (GNNs) have showcased exceptional proficiency in inducing and aggregating symbolic structures. However, classical GNNs face challenges in handling multi-hop spatial reasoning due to the over-smoothing issue, \textit{i.e.}, the performance decreases substantially as the number of graph layers increases. To cope with these challenges, we propose a novel \textbf{Dep}th-\textbf{Wi}se \textbf{G}raph \textbf{N}eural \textbf{N}etwork (\textbf{DepWiGNN}). Specifically, we design a novel node memory scheme and aggregate the information over the depth dimension instead of the breadth dimension of the graph, which empowers the ability to collect long dependencies without stacking multiple layers. Experimental results on two challenging multi-hop spatial reasoning datasets show that DepWiGNN outperforms existing spatial reasoning methods. The comparisons with the other three GNNs further demonstrate its superiority in capturing long dependency in the graph.
RTNH+: Enhanced 4D Radar Object Detection Network using Combined CFAR-based Two-level Preprocessing and Vertical Encoding
Oct 19, 2023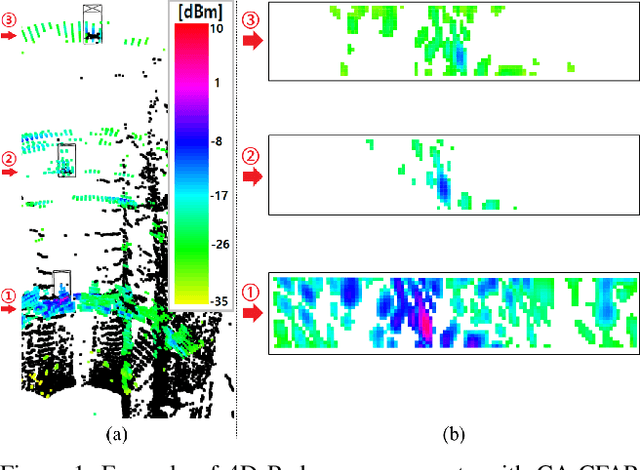
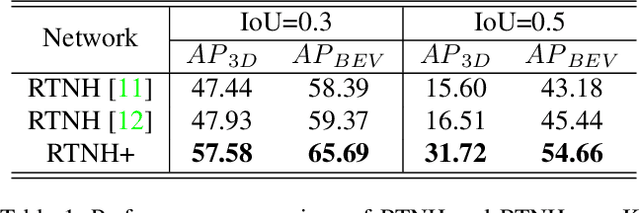
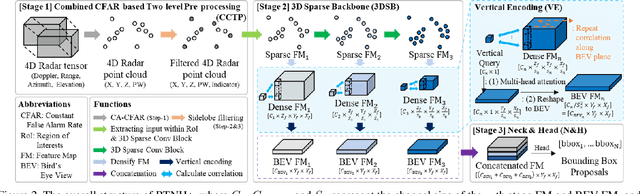
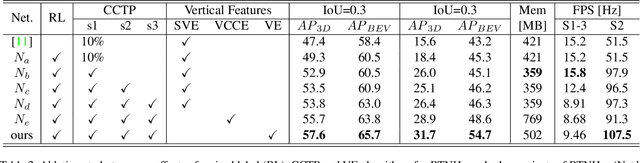
Four-dimensional (4D) Radar is a useful sensor for 3D object detection and the relative radial speed estimation of surrounding objects under various weather conditions. However, since Radar measurements are corrupted with invalid components such as noise, interference, and clutter, it is necessary to employ a preprocessing algorithm before the 3D object detection with neural networks. In this paper, we propose RTNH+ that is an enhanced version of RTNH, a 4D Radar object detection network, by two novel algorithms. The first algorithm is the combined constant false alarm rate (CFAR)-based two-level preprocessing (CCTP) algorithm that generates two filtered measurements of different characteristics using the same 4D Radar measurements, which can enrich the information of the input to the 4D Radar object detection network. The second is the vertical encoding (VE) algorithm that effectively encodes vertical features of the road objects from the CCTP outputs. We provide details of the RTNH+, and demonstrate that RTNH+ achieves significant performance improvement of 10.14\% in ${{AP}_{3D}^{IoU=0.3}}$ and 16.12\% in ${{AP}_{3D}^{IoU=0.5}}$ over RTNH.
Deep Learning Techniques for Video Instance Segmentation: A Survey
Oct 19, 2023Video instance segmentation, also known as multi-object tracking and segmentation, is an emerging computer vision research area introduced in 2019, aiming at detecting, segmenting, and tracking instances in videos simultaneously. By tackling the video instance segmentation tasks through effective analysis and utilization of visual information in videos, a range of computer vision-enabled applications (e.g., human action recognition, medical image processing, autonomous vehicle navigation, surveillance, etc) can be implemented. As deep-learning techniques take a dominant role in various computer vision areas, a plethora of deep-learning-based video instance segmentation schemes have been proposed. This survey offers a multifaceted view of deep-learning schemes for video instance segmentation, covering various architectural paradigms, along with comparisons of functional performance, model complexity, and computational overheads. In addition to the common architectural designs, auxiliary techniques for improving the performance of deep-learning models for video instance segmentation are compiled and discussed. Finally, we discuss a range of major challenges and directions for further investigations to help advance this promising research field.
Blending gradient boosted trees and neural networks for point and probabilistic forecasting of hierarchical time series
Oct 19, 2023In this paper we tackle the problem of point and probabilistic forecasting by describing a blending methodology of machine learning models that belong to gradient boosted trees and neural networks families. These principles were successfully applied in the recent M5 Competition on both Accuracy and Uncertainty tracks. The keypoints of our methodology are: a) transform the task to regression on sales for a single day b) information rich feature engineering c) create a diverse set of state-of-the-art machine learning models and d) carefully construct validation sets for model tuning. We argue that the diversity of the machine learning models along with the careful selection of validation examples, where the most important ingredients for the effectiveness of our approach. Although forecasting data had an inherent hierarchy structure (12 levels), none of our proposed solutions exploited that hierarchical scheme. Using the proposed methodology, our team was ranked within the gold medal range in both Accuracy and the Uncertainty track. Inference code along with already trained models are available at https://github.com/IoannisNasios/M5_Uncertainty_3rd_place
HuBERTopic: Enhancing Semantic Representation of HuBERT through Self-supervision Utilizing Topic Model
Oct 06, 2023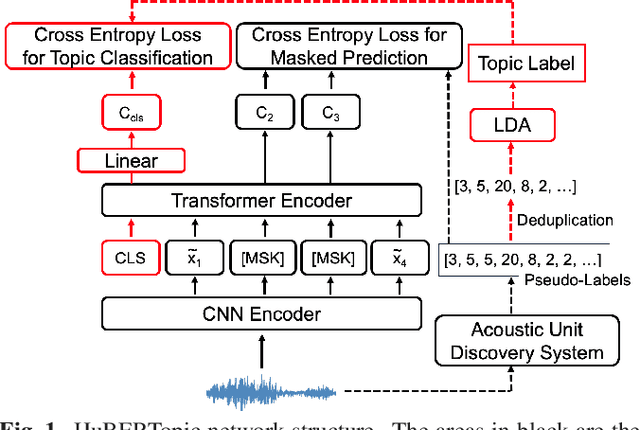
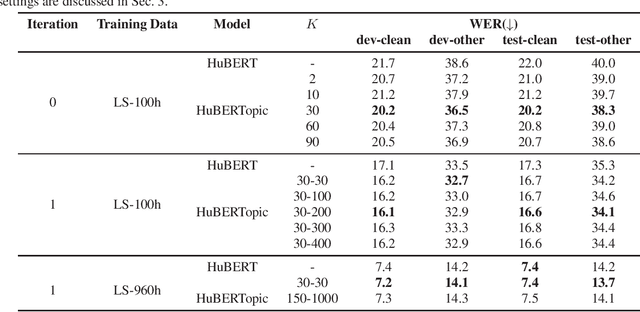

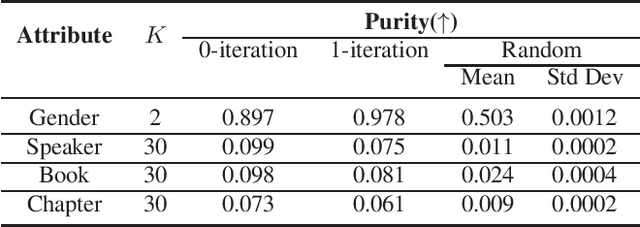
Recently, the usefulness of self-supervised representation learning (SSRL) methods has been confirmed in various downstream tasks. Many of these models, as exemplified by HuBERT and WavLM, use pseudo-labels generated from spectral features or the model's own representation features. From previous studies, it is known that the pseudo-labels contain semantic information. However, the masked prediction task, the learning criterion of HuBERT, focuses on local contextual information and may not make effective use of global semantic information such as speaker, theme of speech, and so on. In this paper, we propose a new approach to enrich the semantic representation of HuBERT. We apply topic model to pseudo-labels to generate a topic label for each utterance. An auxiliary topic classification task is added to HuBERT by using topic labels as teachers. This allows additional global semantic information to be incorporated in an unsupervised manner. Experimental results demonstrate that our method achieves comparable or better performance than the baseline in most tasks, including automatic speech recognition and five out of the eight SUPERB tasks. Moreover, we find that topic labels include various information about utterance, such as gender, speaker, and its theme. This highlights the effectiveness of our approach in capturing multifaceted semantic nuances.
Inferring Power Grid Information with Power Line Communications: Review and Insights
Aug 21, 2023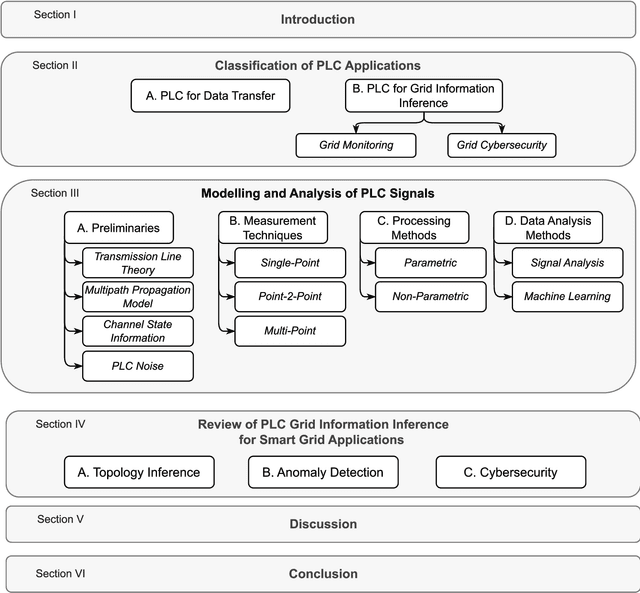
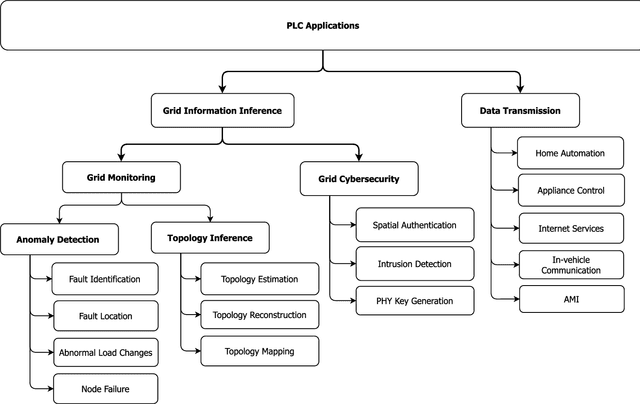
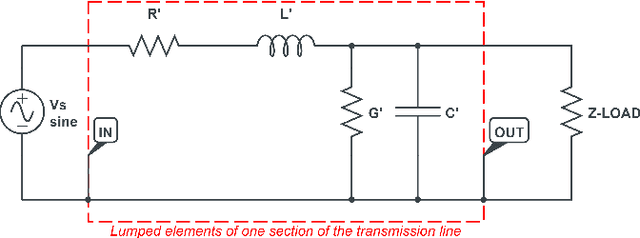
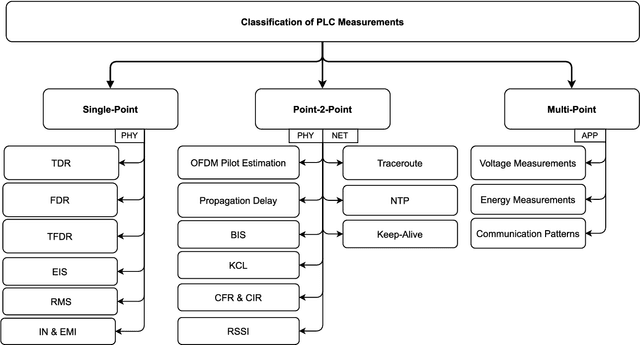
High-frequency signals were widely studied in the last decade to identify grid and channel conditions in PLNs. PLMs operating on the grid's physical layer are capable of transmitting such signals to infer information about the grid. Hence, PLC is a suitable communication technology for SG applications, especially suited for grid monitoring and surveillance. In this paper, we provide several contributions: 1) a classification of PLC-based applications; 2) a taxonomy of the related methodologies; 3) a review of the literature in the area of PLC Grid Information Inference (GII); and, insights that can be leveraged to further advance the field. We found research contributions addressing PLMs for three main PLC-GII applications: topology inference, anomaly detection, and physical layer key generation. In addition, various PLC-GII measurement, processing, and analysis approaches were found to provide distinctive features in measurement resolution, computation complexity, and analysis accuracy. We utilize the outcome of our review to shed light on the current limitations of the research contributions and suggest future research directions in this field.
Analysis of Weather and Time Features in Machine Learning-aided ERCOT Load Forecasting
Oct 13, 2023Accurate load forecasting is critical for efficient and reliable operations of the electric power system. A large part of electricity consumption is affected by weather conditions, making weather information an important determinant of electricity usage. Personal appliances and industry equipment also contribute significantly to electricity demand with temporal patterns, making time a useful factor to consider in load forecasting. This work develops several machine learning (ML) models that take various time and weather information as part of the input features to predict the short-term system-wide total load. Ablation studies were also performed to investigate and compare the impacts of different weather factors on the prediction accuracy. Actual load and historical weather data for the same region were processed and then used to train the ML models. It is interesting to observe that using all available features, each of which may be correlated to the load, is unlikely to achieve the best forecasting performance; features with redundancy may even decrease the inference capabilities of ML models. This indicates the importance of feature selection for ML models. Overall, case studies demonstrated the effectiveness of ML models trained with different weather and time input features for ERCOT load forecasting.