 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leveraging Hierarchical Feature Sharing for Efficient Dataset Condensation
Oct 11, 2023
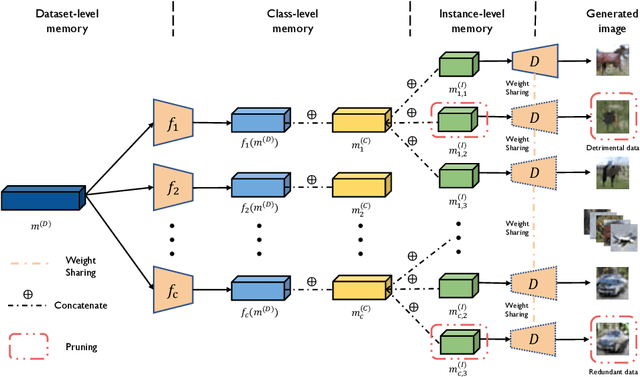
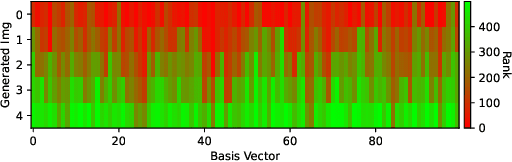
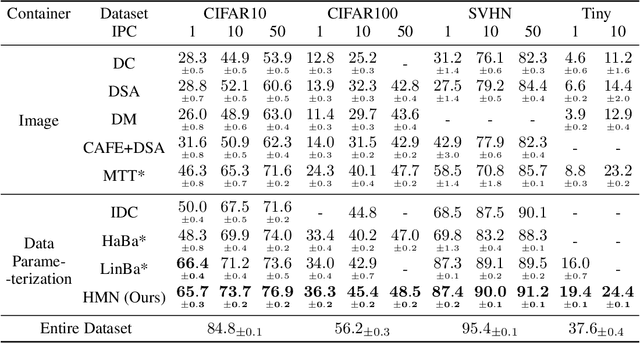
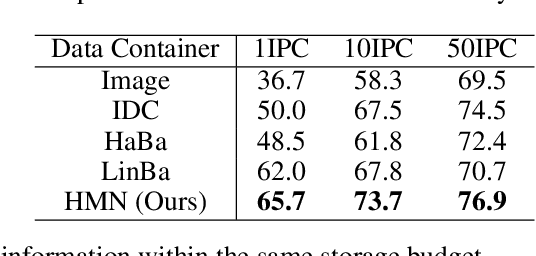
Given a real-world dataset, data condensation (DC) aims to synthesize a significantly smaller dataset that captures the knowledge of this dataset for model training with high performance. Recent works propose to enhance DC with data parameterization, which condenses data into parameterized data containers rather than pixel space. The intuition behind data parameterization is to encode shared features of images to avoid additional storage costs. In this paper, we recognize that images share common features in a hierarchical way due to the inherent hierarchical structure of the classification system, which is overlooked by current data parameterization methods. To better align DC with this hierarchical nature and encourage more efficient information sharing inside data containers, we propose a novel data parameterization architecture, Hierarchical Memory Network (HMN). HMN stores condensed data in a three-tier structure, representing the dataset-level, class-level, and instance-level features. Another helpful property of the hierarchical architecture is that HMN naturally ensures good independence among images despite achieving information sharing. This enables instance-level pruning for HMN to reduce redundant information, thereby further minimizing redundancy and enhancing performance. We evaluate HMN on four public datasets (SVHN, CIFAR10, CIFAR100, and Tiny-ImageNet) and compare HMN with eight DC baselines. The evaluation results show that our proposed method outperforms all baselines, even when trained with a batch-based loss consuming less GPU memory.
Leveraging Contextual Information for Effective Entity Salience Detection
Sep 14, 2023In text documents such as news articles, the content and key events usually revolve around a subset of all the entities mentioned in a document. These entities, often deemed as salient entities, provide useful cues of the aboutness of a document to a reader. Identifying the salience of entities was found helpful in several downstream applications such as search, ranking, and entity-centric summarization, among others. Prior work on salient entity detection mainly focused on machine learning models that require heavy feature engineering. We show that fine-tuning medium-sized language models with a cross-encoder style architecture yields substantial performance gains over feature engineering approaches. To this end, we conduct a comprehensive benchmarking of four publicly available datasets using models representative of the medium-sized pre-trained language model family. Additionally, we show that zero-shot prompting of instruction-tuned language models yields inferior results, indicating the task's uniqueness and complexity.
Classifying Whole Slide Images: What Matters?
Oct 05, 2023Recently there have been many algorithms proposed for the classification of very high resolution whole slide images (WSIs). These new algorithms are mostly focused on finding novel ways to combine the information from small local patches extracted from the slide, with an emphasis on effectively aggregating more global information for the final predictor. In this paper we thoroughly explore different key design choices for WSI classification algorithms to investigate what matters most for achieving high accuracy. Surprisingly, we found that capturing global context information does not necessarily mean better performance. A model that captures the most global information consistently performs worse than a model that captures less global information. In addition, a very simple multi-instance learning method that captures no global information performs almost as well as models that capture a lot of global information. These results suggest that the most important features for effective WSI classification are captured at the local small patch level, where cell and tissue micro-environment detail is most pronounced. Another surprising finding was that unsupervised pre-training on a larger set of 33 cancers gives significantly worse performance compared to pre-training on a smaller dataset of 7 cancers (including the target cancer). We posit that pre-training on a smaller, more focused dataset allows the feature extractor to make better use of the limited feature space to better discriminate between subtle differences in the input patch.
CARLG: Leveraging Contextual Clues and Role Correlations for Improving Document-level Event Argument Extraction
Oct 08, 2023
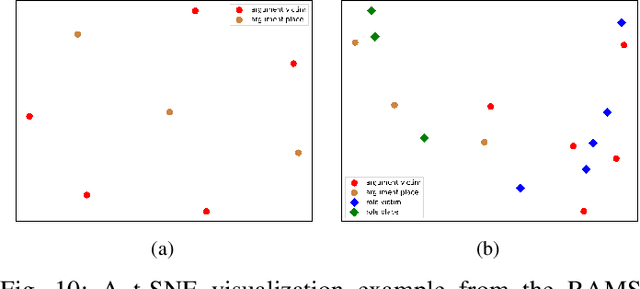
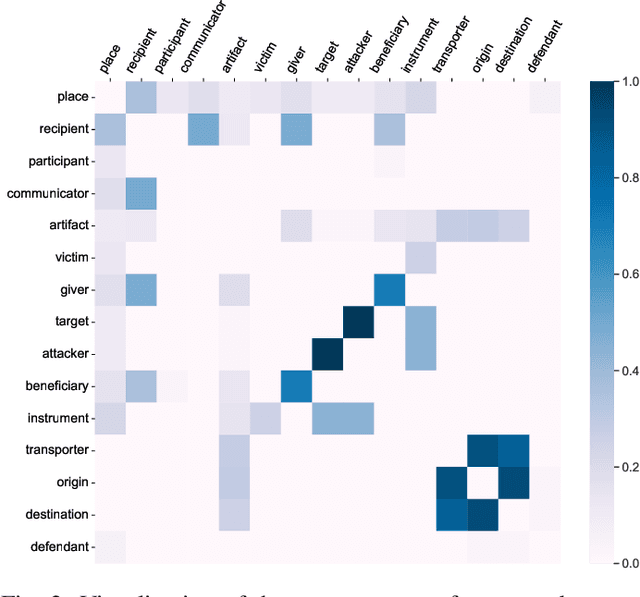
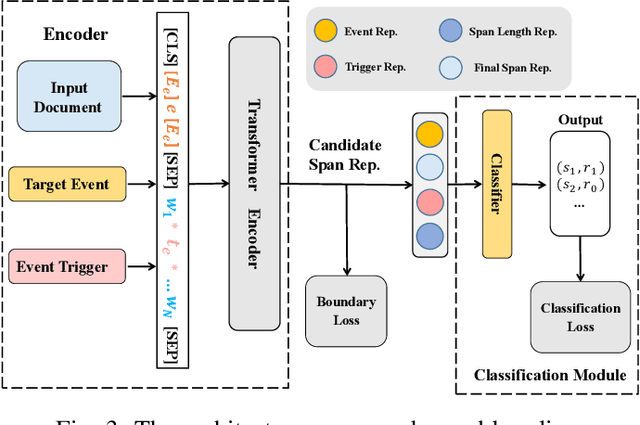
Document-level event argument extraction (EAE) is a crucial but challenging subtask in information extraction. Most existing approaches focus on the interaction between arguments and event triggers, ignoring two critical points: the information of contextual clues and the semantic correlations among argument roles. In this paper, we propose the CARLG model, which consists of two modules: Contextual Clues Aggregation (CCA) and Role-based Latent Information Guidance (RLIG), effectively leveraging contextual clues and role correlations for improving document-level EAE. The CCA module adaptively captures and integrates contextual clues by utilizing context attention weights from a pre-trained encoder. The RLIG module captures semantic correlations through role-interactive encoding and provides valuable information guidance with latent role representation. Notably, our CCA and RLIG modules are compact, transplantable and efficient, which introduce no more than 1% new parameters and can be easily equipped on other span-base methods with significant performance boost. Extensive experiments on the RAMS, WikiEvents, and MLEE datasets demonstrate the superiority of the proposed CARLG model. It outperforms previous state-of-the-art approaches by 1.26 F1, 1.22 F1, and 1.98 F1, respectively, while reducing the inference time by 31%. Furthermore, we provide detailed experimental analyses based on the performance gains and illustrate the interpretability of our model.
Investigating semantic subspaces of Transformer sentence embeddings through linear structural probing
Oct 18, 2023The question of what kinds of linguistic information are encoded in different layers of Transformer-based language models is of considerable interest for the NLP community. Existing work, however, has overwhelmingly focused on word-level representations and encoder-only language models with the masked-token training objective. In this paper, we present experiments with semantic structural probing, a method for studying sentence-level representations via finding a subspace of the embedding space that provides suitable task-specific pairwise distances between data-points. We apply our method to language models from different families (encoder-only, decoder-only, encoder-decoder) and of different sizes in the context of two tasks, semantic textual similarity and natural-language inference. We find that model families differ substantially in their performance and layer dynamics, but that the results are largely model-size invariant.
Semantic Association Rule Learning from Time Series Data and Knowledge Graphs
Oct 11, 2023Digital Twins (DT) are a promising concept in cyber-physical systems research due to their advanced features including monitoring and automated reasoning. Semantic technologies such as Knowledge Graphs (KG) are recently being utilized in DTs especially for information modelling. Building on this move, this paper proposes a pipeline for semantic association rule learning in DTs using KGs and time series data. In addition to this initial pipeline, we also propose new semantic association rule criterion. The approach is evaluated on an industrial water network scenario. Initial evaluation shows that the proposed approach is able to learn a high number of association rules with semantic information which are more generalizable. The paper aims to set a foundation for further work on using semantic association rule learning especially in the context of industrial applications.
JM3D & JM3D-LLM: Elevating 3D Representation with Joint Multi-modal Cues
Oct 14, 2023The rising importance of 3D representation learning, pivotal in computer vision, autonomous driving, and robotics, is evident. However, a prevailing trend, which straightforwardly resorted to transferring 2D alignment strategies to the 3D domain, encounters three distinct challenges: (1) Information Degradation: This arises from the alignment of 3D data with mere single-view 2D images and generic texts, neglecting the need for multi-view images and detailed subcategory texts. (2) Insufficient Synergy: These strategies align 3D representations to image and text features individually, hampering the overall optimization for 3D models. (3) Underutilization: The fine-grained information inherent in the learned representations is often not fully exploited, indicating a potential loss in detail. To address these issues, we introduce JM3D, a comprehensive approach integrating point cloud, text, and image. Key contributions include the Structured Multimodal Organizer (SMO), enriching vision-language representation with multiple views and hierarchical text, and the Joint Multi-modal Alignment (JMA), combining language understanding with visual representation. Our advanced model, JM3D-LLM, marries 3D representation with large language models via efficient fine-tuning. Evaluations on ModelNet40 and ScanObjectNN establish JM3D's superiority. The superior performance of JM3D-LLM further underscores the effectiveness of our representation transfer approach. Our code and models are available at https://github.com/Mr-Neko/JM3D.
Towards End-to-End Unsupervised Saliency Detection with Self-Supervised Top-Down Context
Oct 14, 2023
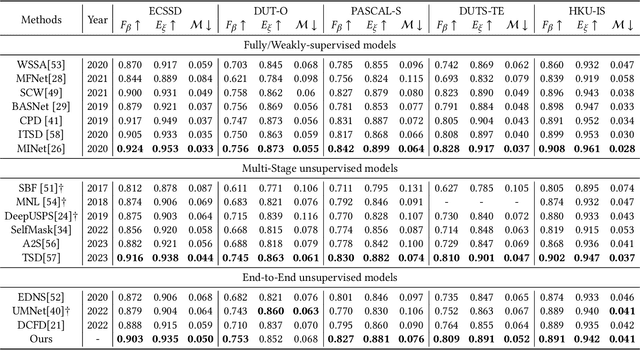
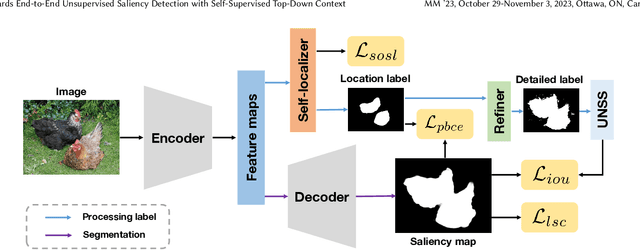
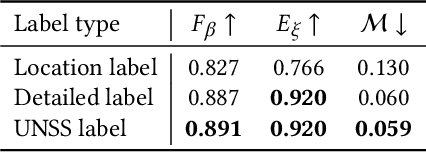
Unsupervised salient object detection aims to detect salient objects without using supervision signals eliminating the tedious task of manually labeling salient objects. To improve training efficiency, end-to-end methods for USOD have been proposed as a promising alternative. However, current solutions rely heavily on noisy handcraft labels and fail to mine rich semantic information from deep features. In this paper, we propose a self-supervised end-to-end salient object detection framework via top-down context. Specifically, motivated by contrastive learning, we exploit the self-localization from the deepest feature to construct the location maps which are then leveraged to learn the most instructive segmentation guidance. Further considering the lack of detailed information in deepest features, we exploit the detail-boosting refiner module to enrich the location labels with details. Moreover, we observe that due to lack of supervision, current unsupervised saliency models tend to detect non-salient objects that are salient in some other samples of corresponding scenarios. To address this widespread issue, we design a novel Unsupervised Non-Salient Suppression (UNSS) method developing the ability to ignore non-salient objects. Extensive experiments on benchmark datasets demonstrate that our method achieves leading performance among the recent end-to-end methods and most of the multi-stage solutions. The code is available.
AutoConv: Automatically Generating Information-seeking Conversations with Large Language Models
Aug 12, 2023

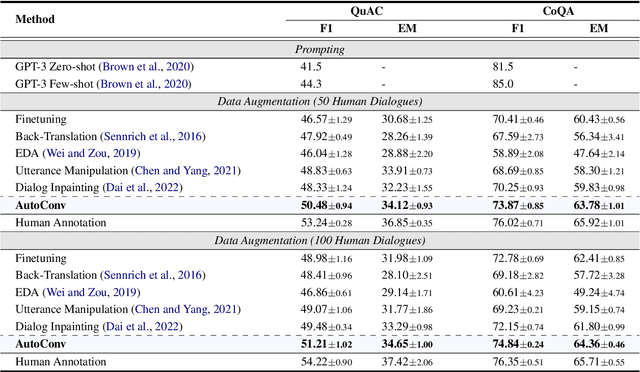
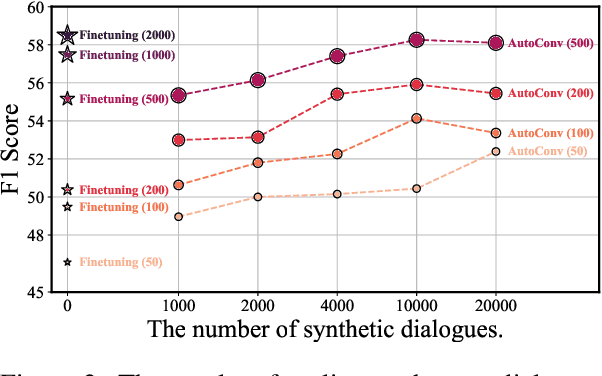
Information-seeking conversation, which aims to help users gather information through conversation, has achieved great progress in recent years. However, the research is still stymied by the scarcity of training data. To alleviate this problem, we propose AutoConv for synthetic conversation generation, which takes advantage of the few-shot learning ability and generation capacity of large language models (LLM). Specifically, we formulate the conversation generation problem as a language modeling task, then finetune an LLM with a few human conversations to capture the characteristics of the information-seeking process and use it for generating synthetic conversations with high quality. Experimental results on two frequently-used datasets verify that AutoConv has substantial improvements over strong baselines and alleviates the dependence on human annotation. In addition, we also provide several analysis studies to promote future research.
Image Super-resolution Via Latent Diffusion: A Sampling-space Mixture Of Experts And Frequency-augmented Decoder Approach
Oct 20, 2023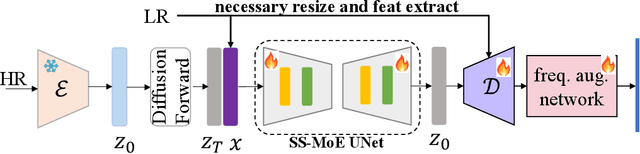

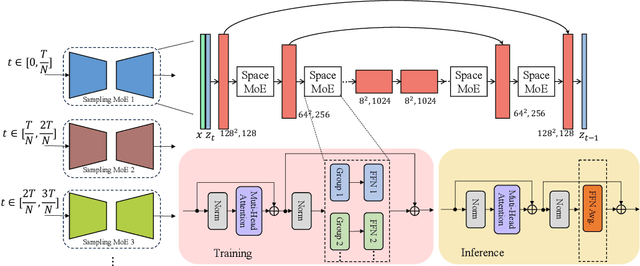
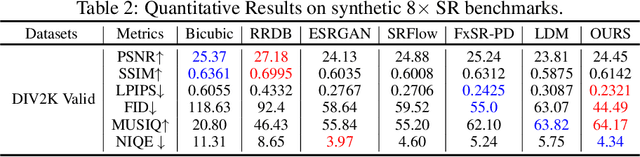
The recent use of diffusion prior, enhanced by pre-trained text-image models, has markedly elevated the performance of image super-resolution (SR). To alleviate the huge computational cost required by pixel-based diffusion SR, latent-based methods utilize a feature encoder to transform the image and then implement the SR image generation in a compact latent space. Nevertheless, there are two major issues that limit the performance of latent-based diffusion. First, the compression of latent space usually causes reconstruction distortion. Second, huge computational cost constrains the parameter scale of the diffusion model. To counteract these issues, we first propose a frequency compensation module that enhances the frequency components from latent space to pixel space. The reconstruction distortion (especially for high-frequency information) can be significantly decreased. Then, we propose to use Sample-Space Mixture of Experts (SS-MoE) to achieve more powerful latent-based SR, which steadily improves the capacity of the model without a significant increase in inference costs. These carefully crafted designs contribute to performance improvements in largely explored 4x blind super-resolution benchmarks and extend to large magnification factors, i.e., 8x image SR benchmarks. The code is available at https://github.com/amandaluof/moe_sr.