 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Language Model Unalignment: Parametric Red-Teaming to Expose Hidden Harms and Biases
Oct 22, 2023
Red-teaming has been a widely adopted way to evaluate the harmfulness of Large Language Models (LLMs). It aims to jailbreak a model's safety behavior to make it act as a helpful agent disregarding the harmfulness of the query. Existing methods are primarily based on input text-based red-teaming such as adversarial prompts, low-resource prompts, or contextualized prompts to condition the model in a way to bypass its safe behavior. Bypassing the guardrails uncovers hidden harmful information and biases in the model that are left untreated or newly introduced by its safety training. However, prompt-based attacks fail to provide such a diagnosis owing to their low attack success rate, and applicability to specific models. In this paper, we present a new perspective on LLM safety research i.e., parametric red-teaming through Unalignment. It simply (instruction) tunes the model parameters to break model guardrails that are not deeply rooted in the model's behavior. Unalignment using as few as 100 examples can significantly bypass commonly referred to as CHATGPT, to the point where it responds with an 88% success rate to harmful queries on two safety benchmark datasets. On open-source models such as VICUNA-7B and LLAMA-2-CHAT 7B AND 13B, it shows an attack success rate of more than 91%. On bias evaluations, Unalignment exposes inherent biases in safety-aligned models such as CHATGPT and LLAMA- 2-CHAT where the model's responses are strongly biased and opinionated 64% of the time.
Manifold-Preserving Transformers are Effective for Short-Long Range Encoding
Oct 22, 2023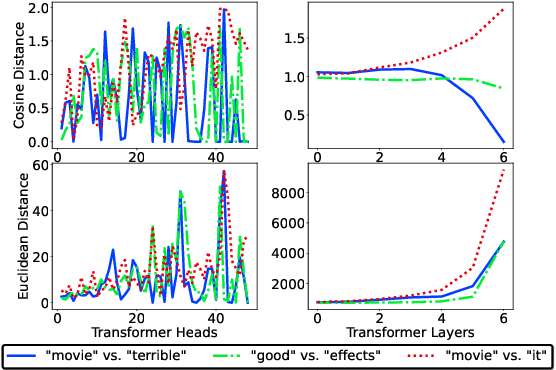
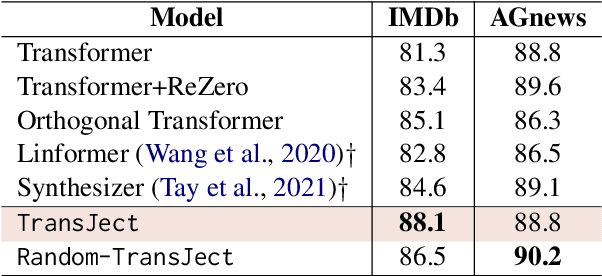
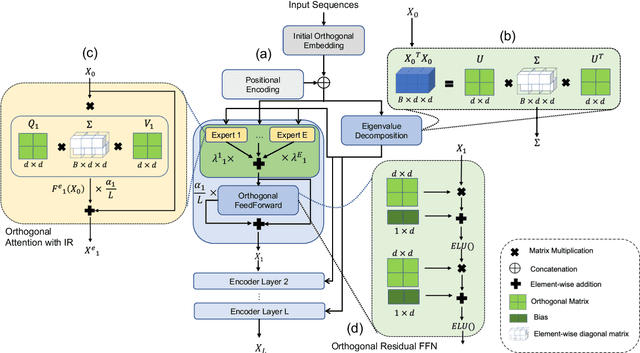
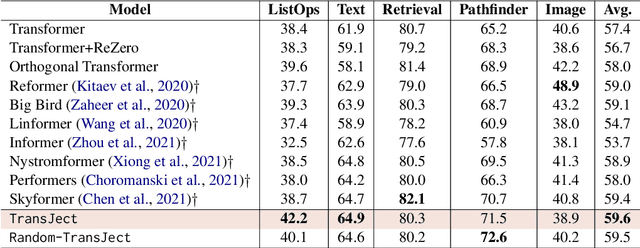
Multi-head self-attention-based Transformers have shown promise in different learning tasks. Albeit these models exhibit significant improvement in understanding short-term and long-term contexts from sequences, encoders of Transformers and their variants fail to preserve layer-wise contextual information. Transformers usually project tokens onto sparse manifolds and fail to preserve mathematical equivalence among the token representations. In this work, we propose TransJect, an encoder model that guarantees a theoretical bound for layer-wise distance preservation between a pair of tokens. We propose a simple alternative to dot-product attention to ensure Lipschitz continuity. This allows TransJect to learn injective mappings to transform token representations to different manifolds with similar topology and preserve Euclidean distance between every pair of tokens in subsequent layers. Evaluations across multiple benchmark short- and long-sequence classification tasks show maximum improvements of 6.8% and 5.9%, respectively, over the variants of Transformers. Additionally, TransJect displays 79% better performance than Transformer on the language modeling task. We further highlight the shortcomings of multi-head self-attention from the statistical physics viewpoint. Although multi-head self-attention was incepted to learn different abstraction levels within the networks, our empirical analyses suggest that different attention heads learn randomly and unorderly. In contrast, TransJect adapts a mixture of experts for regularization; these experts are more orderly and balanced and learn different sparse representations from the input sequences. TransJect exhibits very low entropy and can be efficiently scaled to larger depths.
SeUNet-Trans: A Simple yet Effective UNet-Transformer Model for Medical Image Segmentation
Oct 22, 2023Automated medical image segmentation is becoming increasingly crucial in modern clinical practice, driven by the growing demand for precise diagnoses, the push towards personalized treatment plans, and advancements in machine learning algorithms, especially the incorporation of deep learning methods. While convolutional neural networks (CNNs) have been prevalent among these methods, the remarkable potential of Transformer-based models for computer vision tasks is gaining more acknowledgment. To harness the advantages of both CNN-based and Transformer-based models, we propose a simple yet effective UNet-Transformer (seUNet-Trans) model for medical image segmentation. In our approach, the UNet model is designed as a feature extractor to generate multiple feature maps from the input images, and these maps are propagated into a bridge layer, which sequentially connects the UNet and the Transformer. In this stage, we employ the pixel-level embedding technique without position embedding vectors to make the model more efficient. Moreover, we applied spatial-reduction attention in the Transformer to reduce the computational/memory overhead. By leveraging the UNet architecture and the self-attention mechanism, our model not only preserves both local and global context information but also captures long-range dependencies between input elements. The proposed model is extensively experimented on five medical image segmentation datasets, including polyp segmentation, to demonstrate its efficacy. A comparison with several state-of-the-art segmentation models on these datasets shows the superior performance of seUNet-Trans.
When Urban Region Profiling Meets Large Language Models
Oct 22, 2023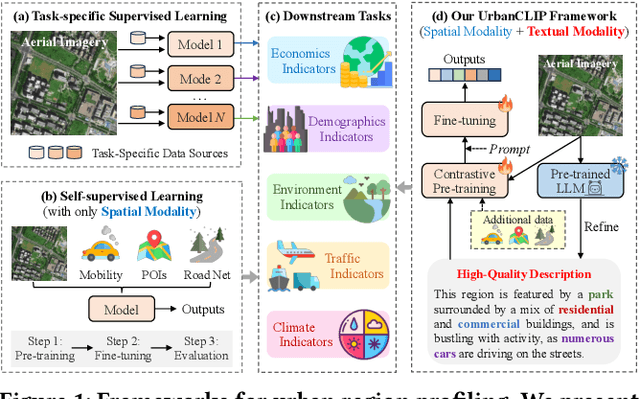
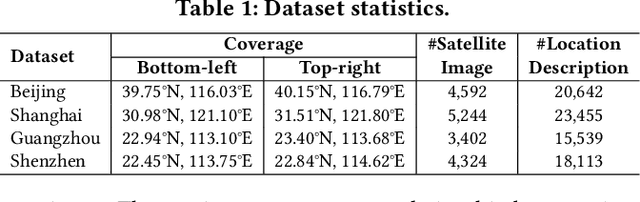
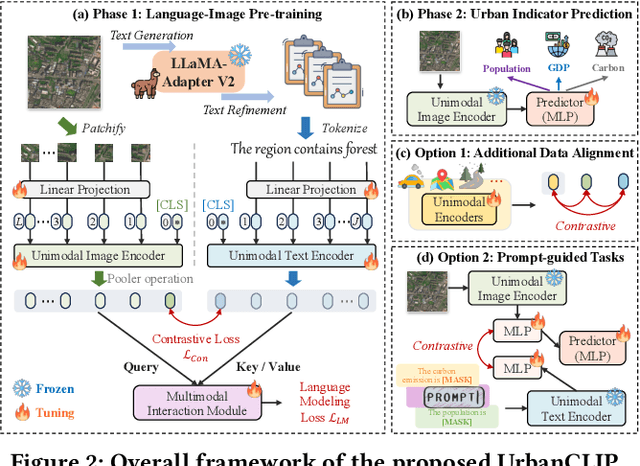
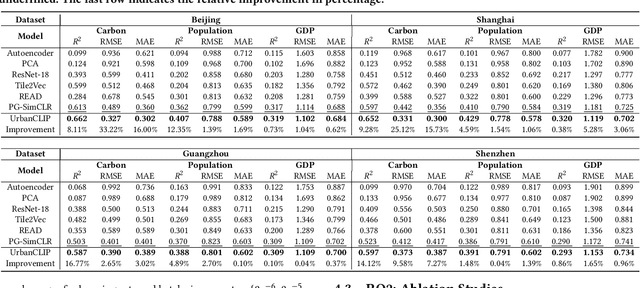
Urban region profiling from web-sourced data is of utmost importance for urban planning and sustainable development. We are witnessing a rising trend of LLMs for various fields, especially dealing with multi-modal data research such as vision-language learning, where the text modality serves as a supplement information for the image. Since textual modality has never been introduced into modality combinations in urban region profiling, we aim to answer two fundamental questions in this paper: i) Can textual modality enhance urban region profiling? ii) and if so, in what ways and with regard to which aspects? To answer the questions, we leverage the power of Large Language Models (LLMs) and introduce the first-ever LLM-enhanced framework that integrates the knowledge of textual modality into urban imagery profiling, named LLM-enhanced Urban Region Profiling with Contrastive Language-Image Pretraining (UrbanCLIP). Specifically, it first generates a detailed textual description for each satellite image by an open-source Image-to-Text LLM. Then, the model is trained on the image-text pairs, seamlessly unifying natural language supervision for urban visual representation learning, jointly with contrastive loss and language modeling loss. Results on predicting three urban indicators in four major Chinese metropolises demonstrate its superior performance, with an average improvement of 6.1% on R^2 compared to the state-of-the-art methods. Our code and the image-language dataset will be released upon paper notification.
Cross-Domain HAR: Few Shot Transfer Learning for Human Activity Recognition
Oct 22, 2023The ubiquitous availability of smartphones and smartwatches with integrated inertial measurement units (IMUs) enables straightforward capturing of human activities. For specific applications of sensor based human activity recognition (HAR), however, logistical challenges and burgeoning costs render especially the ground truth annotation of such data a difficult endeavor, resulting in limited scale and diversity of datasets. Transfer learning, i.e., leveraging publicly available labeled datasets to first learn useful representations that can then be fine-tuned using limited amounts of labeled data from a target domain, can alleviate some of the performance issues of contemporary HAR systems. Yet they can fail when the differences between source and target conditions are too large and/ or only few samples from a target application domain are available, each of which are typical challenges in real-world human activity recognition scenarios. In this paper, we present an approach for economic use of publicly available labeled HAR datasets for effective transfer learning. We introduce a novel transfer learning framework, Cross-Domain HAR, which follows the teacher-student self-training paradigm to more effectively recognize activities with very limited label information. It bridges conceptual gaps between source and target domains, including sensor locations and type of activities. Through our extensive experimental evaluation on a range of benchmark datasets, we demonstrate the effectiveness of our approach for practically relevant few shot activity recognition scenarios. We also present a detailed analysis into how the individual components of our framework affect downstream performance.
Bi-Encoders based Species Normalization -- Pairwise Sentence Learning to Rank
Oct 22, 2023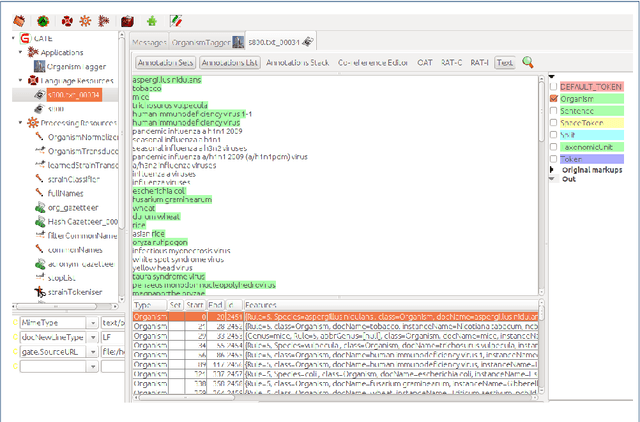
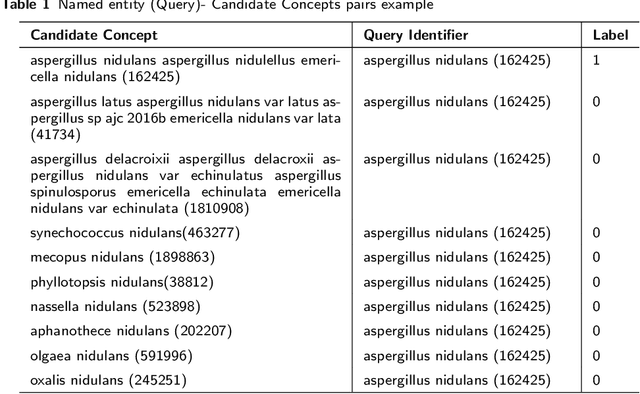
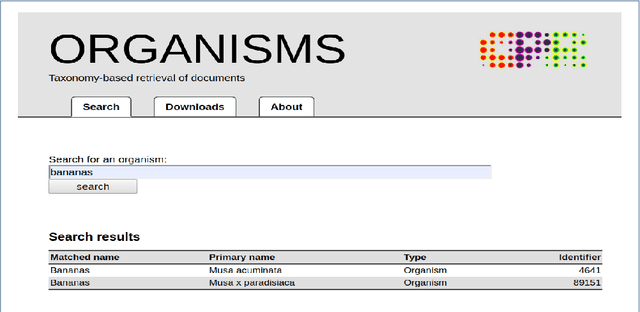

Motivation: Biomedical named-entity normalization involves connecting biomedical entities with distinct database identifiers in order to facilitate data integration across various fields of biology. Existing systems for biomedical named entity normalization heavily rely on dictionaries, manually created rules, and high-quality representative features such as lexical or morphological characteristics. However, recent research has investigated the use of neural network-based models to reduce dependence on dictionaries, manually crafted rules, and features. Despite these advancements, the performance of these models is still limited due to the lack of sufficiently large training datasets. These models have a tendency to overfit small training corpora and exhibit poor generalization when faced with previously unseen entities, necessitating the redesign of rules and features. Contribution: We present a novel deep learning approach for named entity normalization, treating it as a pair-wise learning to rank problem. Our method utilizes the widely-used information retrieval algorithm Best Matching 25 to generate candidate concepts, followed by the application of bi-directional encoder representation from the encoder (BERT) to re-rank the candidate list. Notably, our approach eliminates the need for feature-engineering or rule creation. We conduct experiments on species entity types and evaluate our method against state-of-the-art techniques using LINNAEUS and S800 biomedical corpora. Our proposed approach surpasses existing methods in linking entities to the NCBI taxonomy. To the best of our knowledge, there is no existing neural network-based approach for species normalization in the literature.
Exploring Large Language Models for Multi-Modal Out-of-Distribution Detection
Oct 12, 2023Out-of-distribution (OOD) detection is essential for reliable and trustworthy machine learning. Recent multi-modal OOD detection leverages textual information from in-distribution (ID) class names for visual OOD detection, yet it currently neglects the rich contextual information of ID classes. Large language models (LLMs) encode a wealth of world knowledge and can be prompted to generate descriptive features for each class. Indiscriminately using such knowledge causes catastrophic damage to OOD detection due to LLMs' hallucinations, as is observed by our analysis. In this paper, we propose to apply world knowledge to enhance OOD detection performance through selective generation from LLMs. Specifically, we introduce a consistency-based uncertainty calibration method to estimate the confidence score of each generation. We further extract visual objects from each image to fully capitalize on the aforementioned world knowledge. Extensive experiments demonstrate that our method consistently outperforms the state-of-the-art.
Sensing-assisted Accurate and Fast Beam Management for Cellular-connected mmWave UAV Network
Oct 12, 2023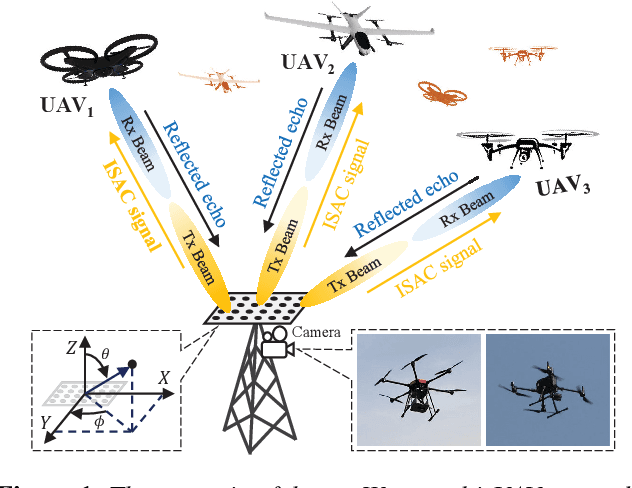
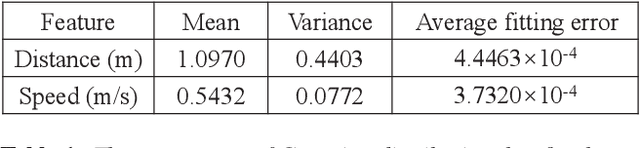
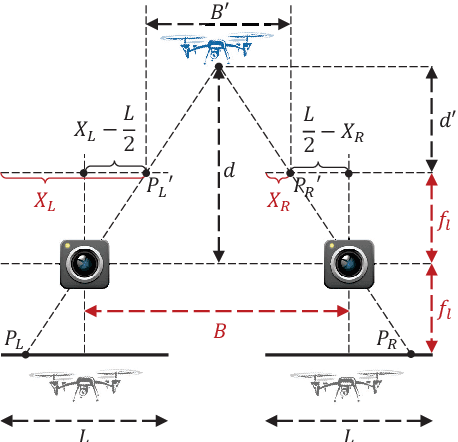
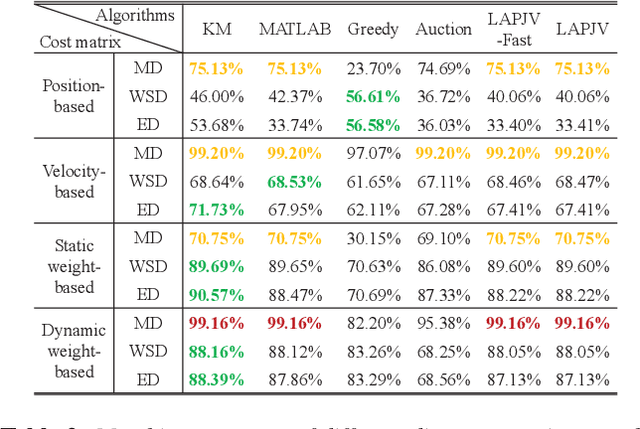
Beam management, including initial access (IA) and beam tracking, is essential to the millimeter-wave Unmanned Aerial Vehicle (UAV) network. However, conventional communication-only and feedback-based schemes suffer a high delay and low accuracy of beam alignment since they only enable the receiver to passively hear the information of the transmitter from the radio domain. This paper presents a novel sensing-assisted beam management approach, the first solution that fully utilizes the information from the visual domain to improve communication performance. We employ both integrated sensing and communication and computer vision techniques and design an extended Kalman filtering method for beam tracking and prediction. Besides, we also propose a novel dual identity association solution to distinguish multiple UAVs in dynamic environments. Real-world experiments and numerical results show that the proposed solution outperforms the conventional methods in IA delay, association accuracy, tracking error, and communication performance.
UniParser: Multi-Human Parsing with Unified Correlation Representation Learning
Oct 13, 2023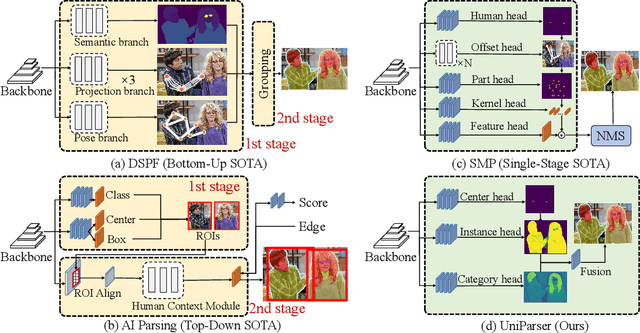
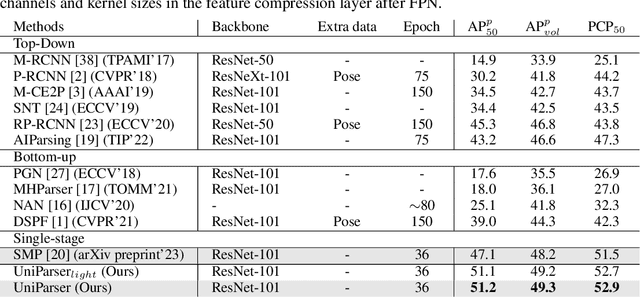
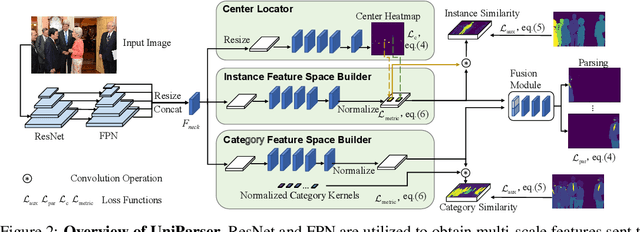
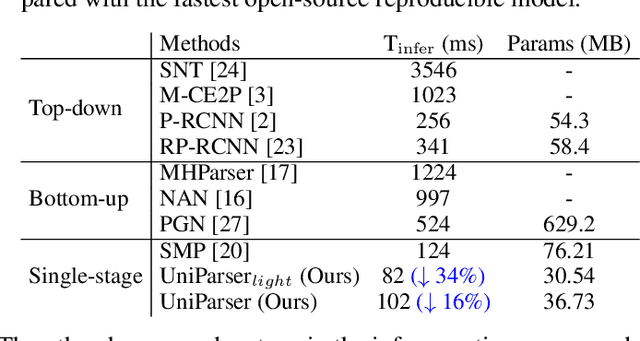
Multi-human parsing is an image segmentation task necessitating both instance-level and fine-grained category-level information. However, prior research has typically processed these two types of information through separate branches and distinct output formats, leading to inefficient and redundant frameworks. This paper introduces UniParser, which integrates instance-level and category-level representations in three key aspects: 1) we propose a unified correlation representation learning approach, allowing our network to learn instance and category features within the cosine space; 2) we unify the form of outputs of each modules as pixel-level segmentation results while supervising instance and category features using a homogeneous label accompanied by an auxiliary loss; and 3) we design a joint optimization procedure to fuse instance and category representations. By virtual of unifying instance-level and category-level output, UniParser circumvents manually designed post-processing techniques and surpasses state-of-the-art methods, achieving 49.3% AP on MHPv2.0 and 60.4% AP on CIHP. We will release our source code, pretrained models, and online demos to facilitate future studies.
Geom-Erasing: Geometry-Driven Removal of Implicit Concept in Diffusion Models
Oct 13, 2023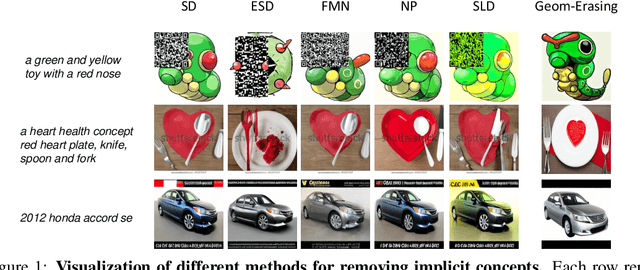

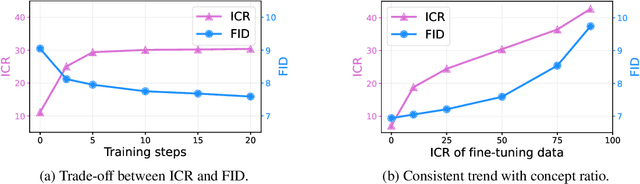
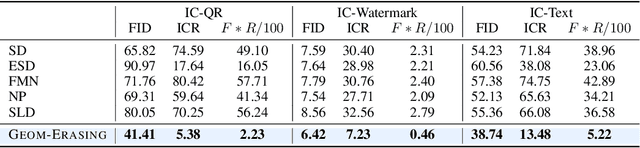
Fine-tuning diffusion models through personalized datasets is an acknowledged method for improving generation quality across downstream tasks, which, however, often inadvertently generates unintended concepts such as watermarks and QR codes, attributed to the limitations in image sources and collecting methods within specific downstream tasks. Existing solutions suffer from eliminating these unintentionally learned implicit concepts, primarily due to the dependency on the model's ability to recognize concepts that it actually cannot discern. In this work, we introduce Geom-Erasing, a novel approach that successfully removes the implicit concepts with either an additional accessible classifier or detector model to encode geometric information of these concepts into text domain. Moreover, we propose Implicit Concept, a novel image-text dataset imbued with three implicit concepts (i.e., watermarks, QR codes, and text) for training and evaluation. Experimental results demonstrate that Geom-Erasing not only identifies but also proficiently eradicates implicit concepts, revealing a significant improvement over the existing methods. The integration of geometric information marks a substantial progression in the precise removal of implicit concepts in diffusion models.