 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Leveraging Neural Radiance Fields for Uncertainty-Aware Visual Localization
Oct 10, 2023
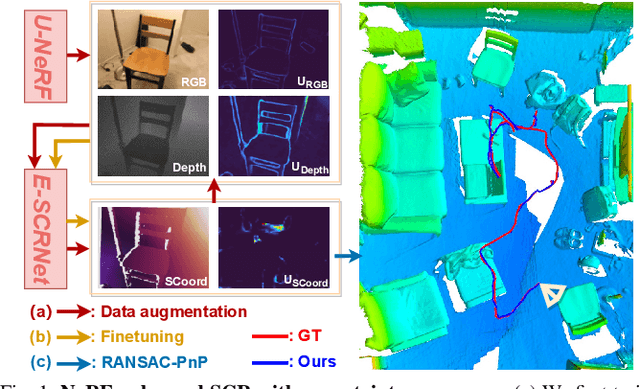
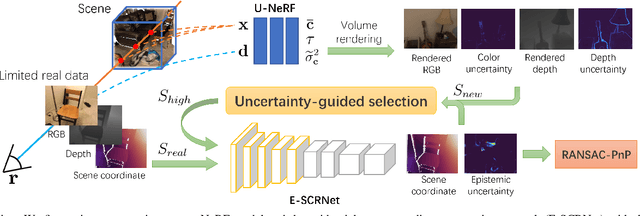
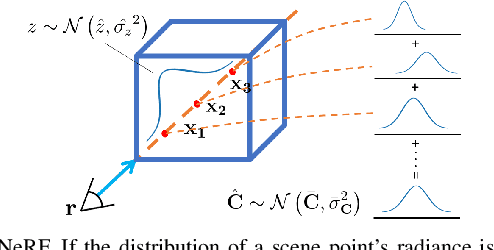

As a promising fashion for visual localization, scene coordinate regression (SCR) has seen tremendous progress in the past decade. Most recent methods usually adopt neural networks to learn the mapping from image pixels to 3D scene coordinates, which requires a vast amount of annotated training data. We propose to leverage Neural Radiance Fields (NeRF) to generate training samples for SCR. Despite NeRF's efficiency in rendering, many of the rendered data are polluted by artifacts or only contain minimal information gain, which can hinder the regression accuracy or bring unnecessary computational costs with redundant data. These challenges are addressed in three folds in this paper: (1) A NeRF is designed to separately predict uncertainties for the rendered color and depth images, which reveal data reliability at the pixel level. (2) SCR is formulated as deep evidential learning with epistemic uncertainty, which is used to evaluate information gain and scene coordinate quality. (3) Based on the three arts of uncertainties, a novel view selection policy is formed that significantly improves data efficiency. Experiments on public datasets demonstrate that our method could select the samples that bring the most information gain and promote the performance with the highest efficiency.
MedSyn: Text-guided Anatomy-aware Synthesis of High-Fidelity 3D CT Images
Oct 16, 2023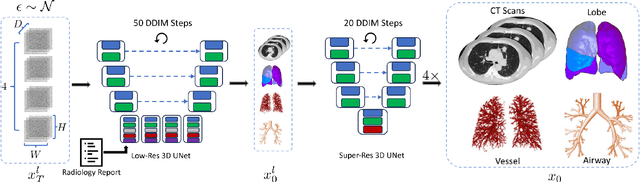
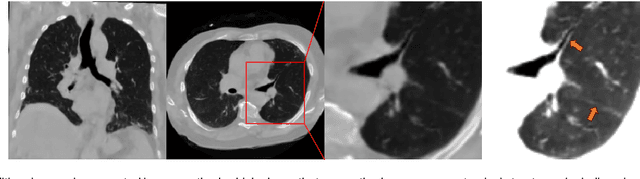
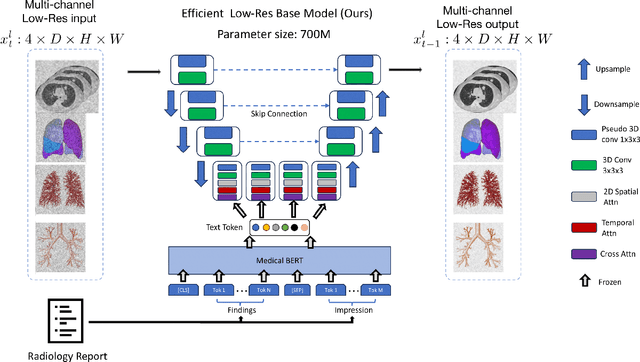
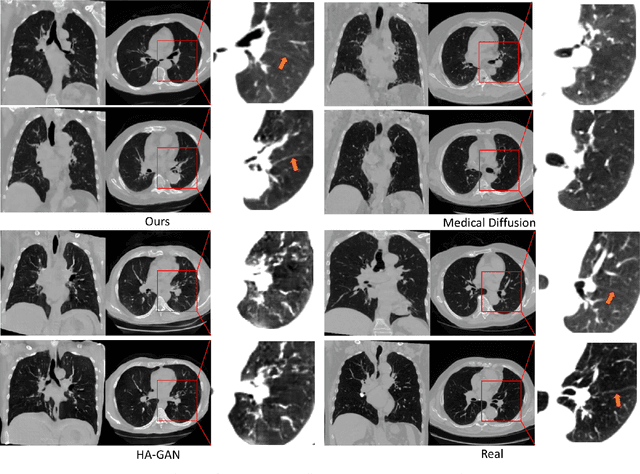
This paper introduces an innovative methodology for producing high-quality 3D lung CT images guided by textual information. While diffusion-based generative models are increasingly used in medical imaging, current state-of-the-art approaches are limited to low-resolution outputs and underutilize radiology reports' abundant information. The radiology reports can enhance the generation process by providing additional guidance and offering fine-grained control over the synthesis of images. Nevertheless, expanding text-guided generation to high-resolution 3D images poses significant memory and anatomical detail-preserving challenges. Addressing the memory issue, we introduce a hierarchical scheme that uses a modified UNet architecture. We start by synthesizing low-resolution images conditioned on the text, serving as a foundation for subsequent generators for complete volumetric data. To ensure the anatomical plausibility of the generated samples, we provide further guidance by generating vascular, airway, and lobular segmentation masks in conjunction with the CT images. The model demonstrates the capability to use textual input and segmentation tasks to generate synthesized images. The results of comparative assessments indicate that our approach exhibits superior performance compared to the most advanced models based on GAN and diffusion techniques, especially in accurately retaining crucial anatomical features such as fissure lines, airways, and vascular structures. This innovation introduces novel possibilities. This study focuses on two main objectives: (1) the development of a method for creating images based on textual prompts and anatomical components, and (2) the capability to generate new images conditioning on anatomical elements. The advancements in image generation can be applied to enhance numerous downstream tasks.
Key-phrase boosted unsupervised summary generation for FinTech organization
Oct 16, 2023With the recent advances in social media, the use of NLP techniques in social media data analysis has become an emerging research direction. Business organizations can particularly benefit from such an analysis of social media discourse, providing an external perspective on consumer behavior. Some of the NLP applications such as intent detection, sentiment classification, text summarization can help FinTech organizations to utilize the social media language data to find useful external insights and can be further utilized for downstream NLP tasks. Particularly, a summary which highlights the intents and sentiments of the users can be very useful for these organizations to get an external perspective. This external perspective can help organizations to better manage their products, offers, promotional campaigns, etc. However, certain challenges, such as a lack of labeled domain-specific datasets impede further exploration of these tasks in the FinTech domain. To overcome these challenges, we design an unsupervised phrase-based summary generation from social media data, using 'Action-Object' pairs (intent phrases). We evaluated the proposed method with other key-phrase based summary generation methods in the direction of contextual information of various Reddit discussion threads, available in the different summaries. We introduce certain "Context Metrics" such as the number of Unique words, Action-Object pairs, and Noun chunks to evaluate the contextual information retrieved from the source text in these phrase-based summaries. We demonstrate that our methods significantly outperform the baseline on these metrics, thus providing a qualitative and quantitative measure of their efficacy. Proposed framework has been leveraged as a web utility portal hosted within Amex.
Looping LOCI: Developing Object Permanence from Videos
Oct 16, 2023Recent compositional scene representation learning models have become remarkably good in segmenting and tracking distinct objects within visual scenes. Yet, many of these models require that objects are continuously, at least partially, visible. Moreover, they tend to fail on intuitive physics tests, which infants learn to solve over the first months of their life. Our goal is to advance compositional scene representation algorithms with an embedded algorithm that fosters the progressive learning of intuitive physics, akin to infant development. As a fundamental component for such an algorithm, we introduce Loci-Looped, which advances a recently published unsupervised object location, identification, and tracking neural network architecture (Loci, Traub et al., ICLR 2023) with an internal processing loop. The loop is designed to adaptively blend pixel-space information with anticipations yielding information-fused activities as percepts. Moreover, it is designed to learn compositional representations of both individual object dynamics and between-objects interaction dynamics. We show that Loci-Looped learns to track objects through extended periods of object occlusions, indeed simulating their hidden trajectories and anticipating their reappearance, without the need for an explicit history buffer. We even find that Loci-Looped surpasses state-of-the-art models on the ADEPT and the CLEVRER dataset, when confronted with object occlusions or temporary sensory data interruptions. This indicates that Loci-Looped is able to learn the physical concepts of object permanence and inertia in a fully unsupervised emergent manner. We believe that even further architectural advancements of the internal loop - also in other compositional scene representation learning models - can be developed in the near future.
Sensing-assisted Accurate and Fast Beam Management for Cellular-connected mmWave UAV Network
Oct 12, 2023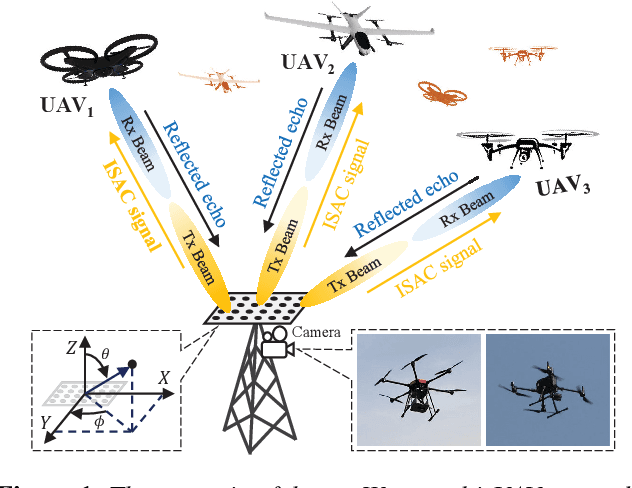
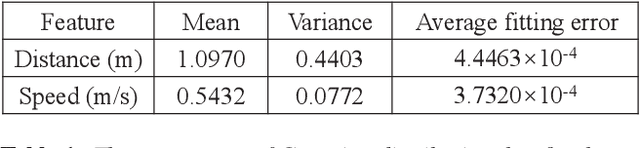
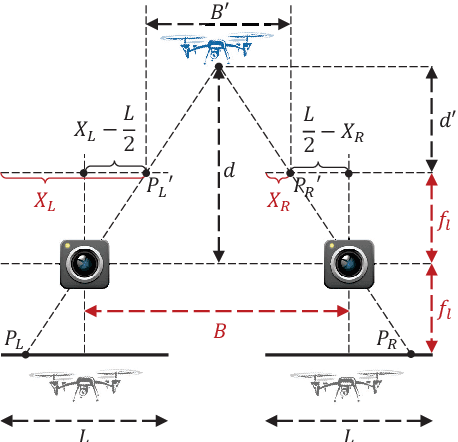
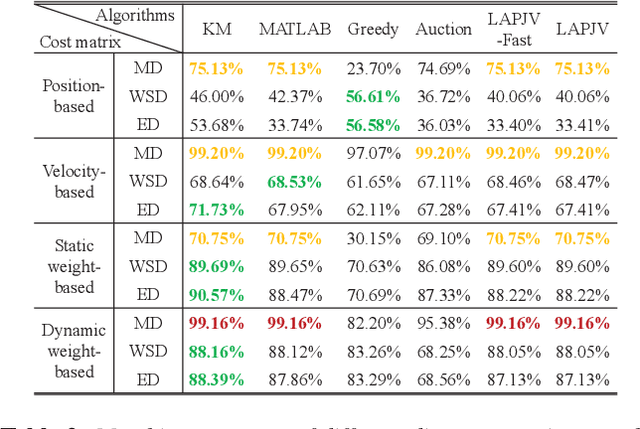
Beam management, including initial access (IA) and beam tracking, is essential to the millimeter-wave Unmanned Aerial Vehicle (UAV) network. However, conventional communication-only and feedback-based schemes suffer a high delay and low accuracy of beam alignment since they only enable the receiver to passively hear the information of the transmitter from the radio domain. This paper presents a novel sensing-assisted beam management approach, the first solution that fully utilizes the information from the visual domain to improve communication performance. We employ both integrated sensing and communication and computer vision techniques and design an extended Kalman filtering method for beam tracking and prediction. Besides, we also propose a novel dual identity association solution to distinguish multiple UAVs in dynamic environments. Real-world experiments and numerical results show that the proposed solution outperforms the conventional methods in IA delay, association accuracy, tracking error, and communication performance.
Exploring Large Language Models for Multi-Modal Out-of-Distribution Detection
Oct 12, 2023Out-of-distribution (OOD) detection is essential for reliable and trustworthy machine learning. Recent multi-modal OOD detection leverages textual information from in-distribution (ID) class names for visual OOD detection, yet it currently neglects the rich contextual information of ID classes. Large language models (LLMs) encode a wealth of world knowledge and can be prompted to generate descriptive features for each class. Indiscriminately using such knowledge causes catastrophic damage to OOD detection due to LLMs' hallucinations, as is observed by our analysis. In this paper, we propose to apply world knowledge to enhance OOD detection performance through selective generation from LLMs. Specifically, we introduce a consistency-based uncertainty calibration method to estimate the confidence score of each generation. We further extract visual objects from each image to fully capitalize on the aforementioned world knowledge. Extensive experiments demonstrate that our method consistently outperforms the state-of-the-art.
Image Compression using only Attention based Neural Networks
Oct 17, 2023In recent research, Learned Image Compression has gained prominence for its capacity to outperform traditional handcrafted pipelines, especially at low bit-rates. While existing methods incorporate convolutional priors with occasional attention blocks to address long-range dependencies, recent advances in computer vision advocate for a transformative shift towards fully transformer-based architectures grounded in the attention mechanism. This paper investigates the feasibility of image compression exclusively using attention layers within our novel model, QPressFormer. We introduce the concept of learned image queries to aggregate patch information via cross-attention, followed by quantization and coding techniques. Through extensive evaluations, our work demonstrates competitive performance achieved by convolution-free architectures across the popular Kodak, DIV2K, and CLIC datasets.
Classifying Whole Slide Images: What Matters?
Oct 05, 2023Recently there have been many algorithms proposed for the classification of very high resolution whole slide images (WSIs). These new algorithms are mostly focused on finding novel ways to combine the information from small local patches extracted from the slide, with an emphasis on effectively aggregating more global information for the final predictor. In this paper we thoroughly explore different key design choices for WSI classification algorithms to investigate what matters most for achieving high accuracy. Surprisingly, we found that capturing global context information does not necessarily mean better performance. A model that captures the most global information consistently performs worse than a model that captures less global information. In addition, a very simple multi-instance learning method that captures no global information performs almost as well as models that capture a lot of global information. These results suggest that the most important features for effective WSI classification are captured at the local small patch level, where cell and tissue micro-environment detail is most pronounced. Another surprising finding was that unsupervised pre-training on a larger set of 33 cancers gives significantly worse performance compared to pre-training on a smaller dataset of 7 cancers (including the target cancer). We posit that pre-training on a smaller, more focused dataset allows the feature extractor to make better use of the limited feature space to better discriminate between subtle differences in the input patch.
Geom-Erasing: Geometry-Driven Removal of Implicit Concept in Diffusion Models
Oct 13, 2023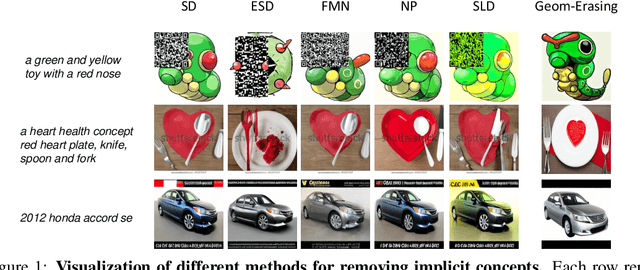

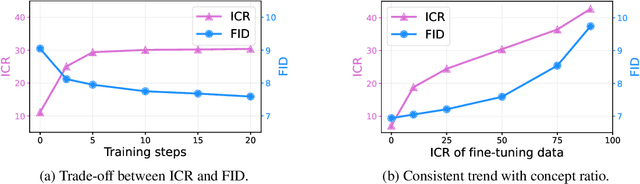
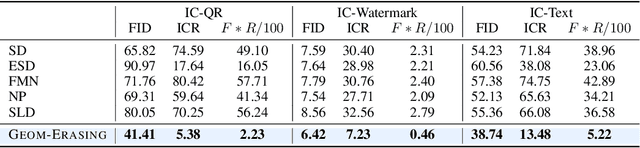
Fine-tuning diffusion models through personalized datasets is an acknowledged method for improving generation quality across downstream tasks, which, however, often inadvertently generates unintended concepts such as watermarks and QR codes, attributed to the limitations in image sources and collecting methods within specific downstream tasks. Existing solutions suffer from eliminating these unintentionally learned implicit concepts, primarily due to the dependency on the model's ability to recognize concepts that it actually cannot discern. In this work, we introduce Geom-Erasing, a novel approach that successfully removes the implicit concepts with either an additional accessible classifier or detector model to encode geometric information of these concepts into text domain. Moreover, we propose Implicit Concept, a novel image-text dataset imbued with three implicit concepts (i.e., watermarks, QR codes, and text) for training and evaluation. Experimental results demonstrate that Geom-Erasing not only identifies but also proficiently eradicates implicit concepts, revealing a significant improvement over the existing methods. The integration of geometric information marks a substantial progression in the precise removal of implicit concepts in diffusion models.
UniParser: Multi-Human Parsing with Unified Correlation Representation Learning
Oct 13, 2023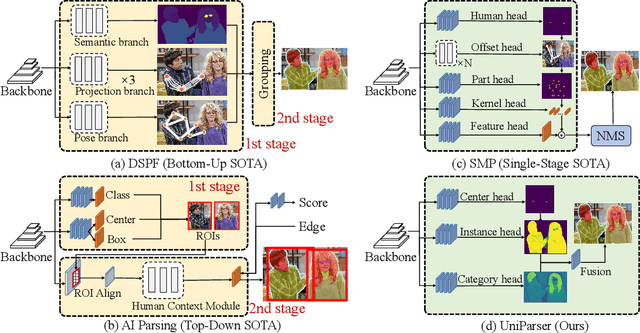
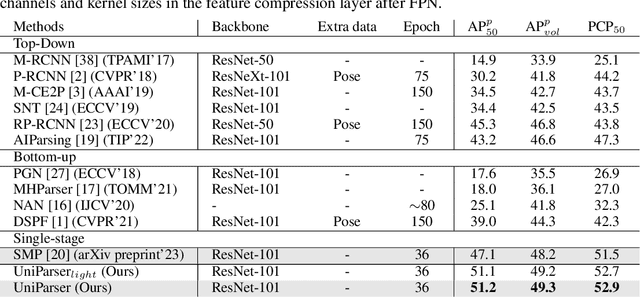
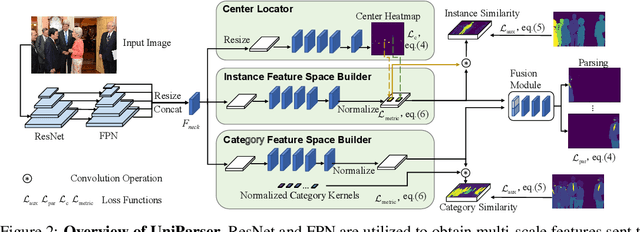
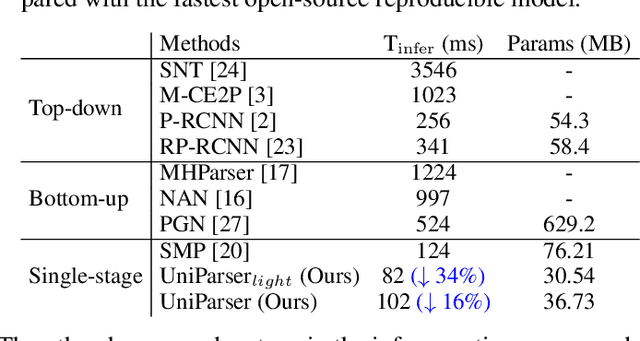
Multi-human parsing is an image segmentation task necessitating both instance-level and fine-grained category-level information. However, prior research has typically processed these two types of information through separate branches and distinct output formats, leading to inefficient and redundant frameworks. This paper introduces UniParser, which integrates instance-level and category-level representations in three key aspects: 1) we propose a unified correlation representation learning approach, allowing our network to learn instance and category features within the cosine space; 2) we unify the form of outputs of each modules as pixel-level segmentation results while supervising instance and category features using a homogeneous label accompanied by an auxiliary loss; and 3) we design a joint optimization procedure to fuse instance and category representations. By virtual of unifying instance-level and category-level output, UniParser circumvents manually designed post-processing techniques and surpasses state-of-the-art methods, achieving 49.3% AP on MHPv2.0 and 60.4% AP on CIHP. We will release our source code, pretrained models, and online demos to facilitate future studies.