 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
JM3D & JM3D-LLM: Elevating 3D Representation with Joint Multi-modal Cues
Oct 20, 2023
The rising importance of 3D representation learning, pivotal in computer vision, autonomous driving, and robotics, is evident. However, a prevailing trend, which straightforwardly resorted to transferring 2D alignment strategies to the 3D domain, encounters three distinct challenges: (1) Information Degradation: This arises from the alignment of 3D data with mere single-view 2D images and generic texts, neglecting the need for multi-view images and detailed subcategory texts. (2) Insufficient Synergy: These strategies align 3D representations to image and text features individually, hampering the overall optimization for 3D models. (3) Underutilization: The fine-grained information inherent in the learned representations is often not fully exploited, indicating a potential loss in detail. To address these issues, we introduce JM3D, a comprehensive approach integrating point cloud, text, and image. Key contributions include the Structured Multimodal Organizer (SMO), enriching vision-language representation with multiple views and hierarchical text, and the Joint Multi-modal Alignment (JMA), combining language understanding with visual representation. Our advanced model, JM3D-LLM, marries 3D representation with large language models via efficient fine-tuning. Evaluations on ModelNet40 and ScanObjectNN establish JM3D's superiority. The superior performance of JM3D-LLM further underscores the effectiveness of our representation transfer approach. Our code and models are available at https://github.com/Mr-Neko/JM3D.
R&B: Region and Boundary Aware Zero-shot Grounded Text-to-image Generation
Oct 26, 2023Recent text-to-image (T2I) diffusion models have achieved remarkable progress in generating high-quality images given text-prompts as input. However, these models fail to convey appropriate spatial composition specified by a layout instruction. In this work, we probe into zero-shot grounded T2I generation with diffusion models, that is, generating images corresponding to the input layout information without training auxiliary modules or finetuning diffusion models. We propose a Region and Boundary (R&B) aware cross-attention guidance approach that gradually modulates the attention maps of diffusion model during generative process, and assists the model to synthesize images (1) with high fidelity, (2) highly compatible with textual input, and (3) interpreting layout instructions accurately. Specifically, we leverage the discrete sampling to bridge the gap between consecutive attention maps and discrete layout constraints, and design a region-aware loss to refine the generative layout during diffusion process. We further propose a boundary-aware loss to strengthen object discriminability within the corresponding regions. Experimental results show that our method outperforms existing state-of-the-art zero-shot grounded T2I generation methods by a large margin both qualitatively and quantitatively on several benchmarks.
Virtual Accessory Try-On via Keypoint Hallucination
Oct 26, 2023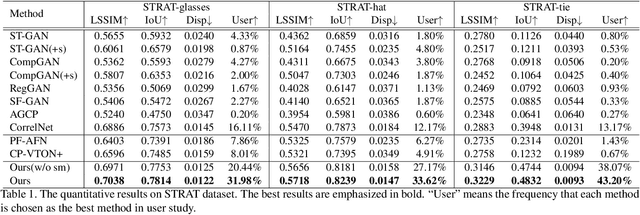
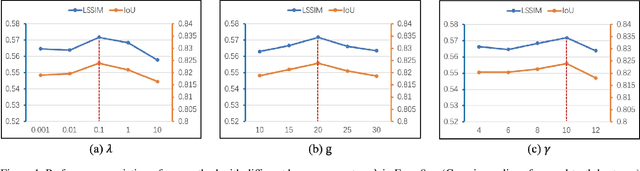
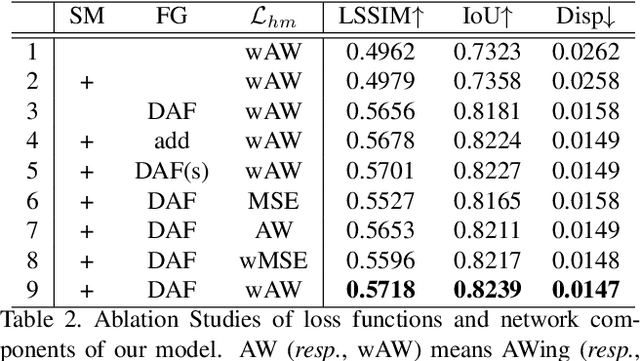
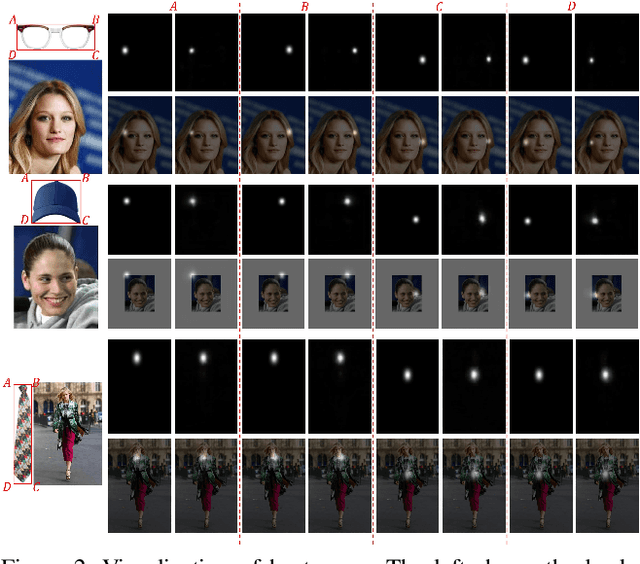
The virtual try-on task refers to fitting the clothes from one image onto another portrait image. In this paper, we focus on virtual accessory try-on, which fits accessory (e.g., glasses, ties) onto a face or portrait image. Unlike clothing try-on, which relies on human silhouette as guidance, accessory try-on warps the accessory into an appropriate location and shape to generate a plausible composite image. In contrast to previous try-on methods that treat foreground (i.e., accessories) and background (i.e., human faces or bodies) equally, we propose a background-oriented network to utilize the prior knowledge of human bodies and accessories. Specifically, our approach learns the human body priors and hallucinates the target locations of specified foreground keypoints in the background. Then our approach will inject foreground information with accessory priors into the background UNet. Based on the hallucinated target locations, the warping parameters are calculated to warp the foreground. Moreover, this background-oriented network can also easily incorporate auxiliary human face/body semantic segmentation supervision to further boost performance. Experiments conducted on STRAT dataset validate the effectiveness of our proposed method.
Joint Entity and Relation Extraction with Span Pruning and Hypergraph Neural Networks
Oct 26, 2023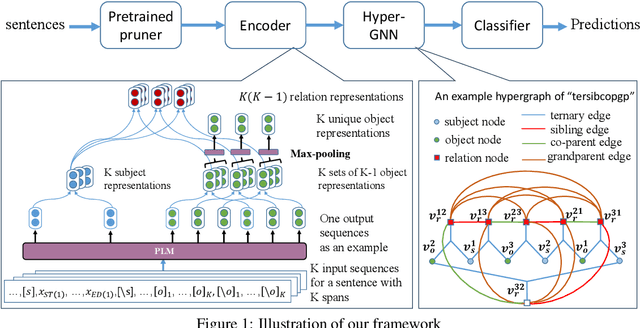
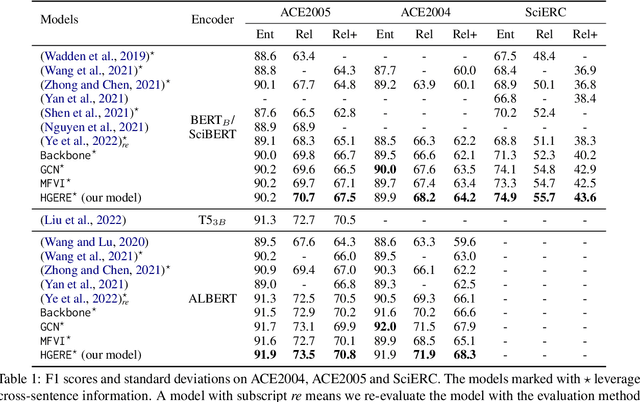
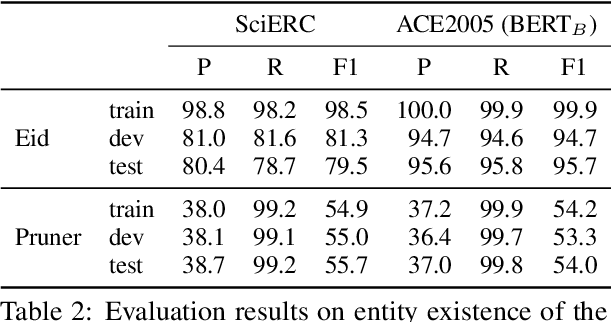
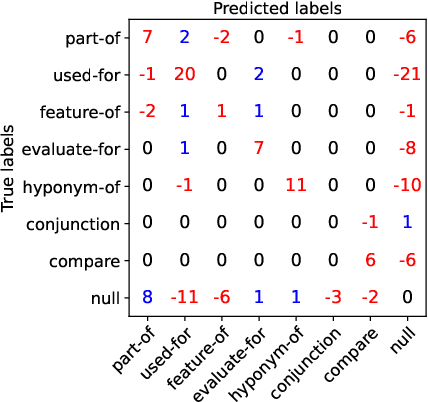
Entity and Relation Extraction (ERE) is an important task in information extraction. Recent marker-based pipeline models achieve state-of-the-art performance, but still suffer from the error propagation issue. Also, most of current ERE models do not take into account higher-order interactions between multiple entities and relations, while higher-order modeling could be beneficial.In this work, we propose HyperGraph neural network for ERE ($\hgnn{}$), which is built upon the PL-marker (a state-of-the-art marker-based pipleline model). To alleviate error propagation,we use a high-recall pruner mechanism to transfer the burden of entity identification and labeling from the NER module to the joint module of our model. For higher-order modeling, we build a hypergraph, where nodes are entities (provided by the span pruner) and relations thereof, and hyperedges encode interactions between two different relations or between a relation and its associated subject and object entities. We then run a hypergraph neural network for higher-order inference by applying message passing over the built hypergraph. Experiments on three widely used benchmarks (\acef{}, \ace{} and \scierc{}) for ERE task show significant improvements over the previous state-of-the-art PL-marker.
DiffS2UT: A Semantic Preserving Diffusion Model for Textless Direct Speech-to-Speech Translation
Oct 26, 2023While Diffusion Generative Models have achieved great success on image generation tasks, how to efficiently and effectively incorporate them into speech generation especially translation tasks remains a non-trivial problem. Specifically, due to the low information density of speech data, the transformed discrete speech unit sequence is much longer than the corresponding text transcription, posing significant challenges to existing auto-regressive models. Furthermore, it is not optimal to brutally apply discrete diffusion on the speech unit sequence while disregarding the continuous space structure, which will degrade the generation performance significantly. In this paper, we propose a novel diffusion model by applying the diffusion forward process in the \textit{continuous} speech representation space, while employing the diffusion backward process in the \textit{discrete} speech unit space. In this way, we preserve the semantic structure of the continuous speech representation space in the diffusion process and integrate the continuous and discrete diffusion models. We conduct extensive experiments on the textless direct speech-to-speech translation task, where the proposed method achieves comparable results to the computationally intensive auto-regressive baselines (500 steps on average) with significantly fewer decoding steps (50 steps).
A Wireless AI-Generated Content (AIGC) Provisioning Framework Empowered by Semantic Communication
Oct 26, 2023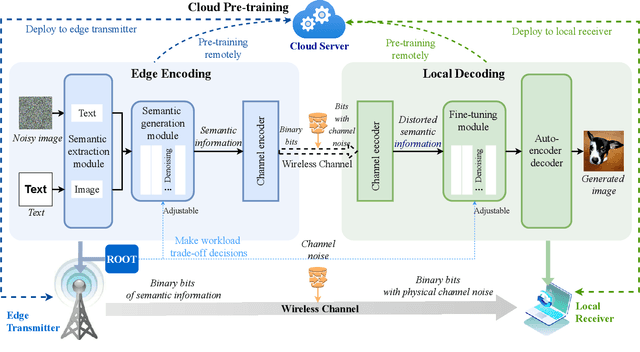
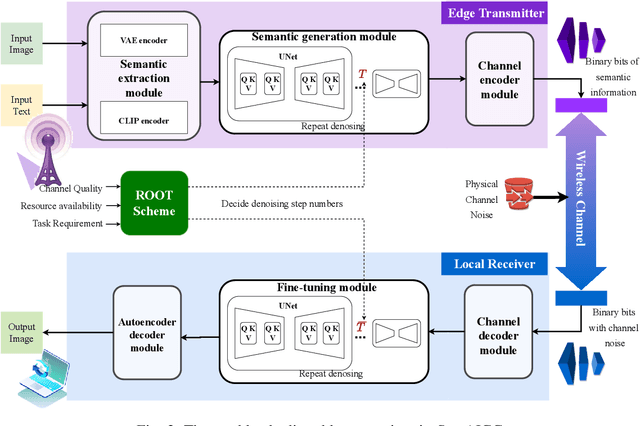
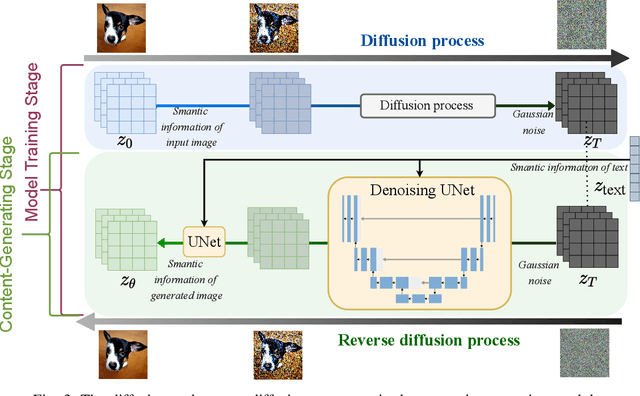
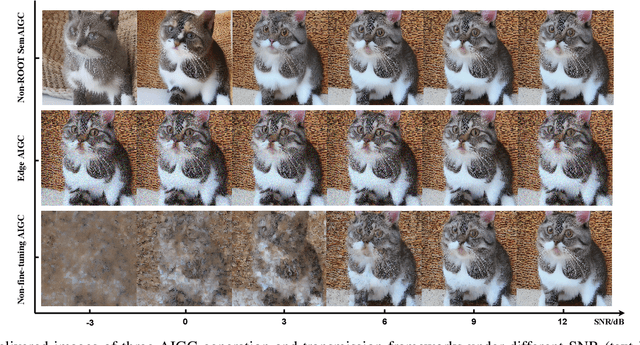
Generative AI applications are recently catering to a vast user base by creating diverse and high-quality AI-generated content (AIGC). With the proliferation of mobile devices and rapid growth of mobile traffic, providing ubiquitous access to high-quality AIGC services via wireless communication networks is becoming the future direction for AIGC products. However, it is challenging to provide optimal AIGC services in wireless networks with unstable channels, limited bandwidth resources, and unevenly distributed computational resources. To tackle these challenges, we propose a semantic communication (SemCom)-empowered AIGC (SemAIGC) generation and transmission framework, where only semantic information of the content rather than all the binary bits should be extracted and transmitted by using SemCom. Specifically, SemAIGC integrates diffusion-based models within the semantic encoder and decoder for efficient content generation and flexible adjustment of the computing workload of both transmitter and receiver. Meanwhile, we devise a resource-aware workload trade-off (ROOT) scheme into the SemAIGC framework to intelligently decide transmitter/receiver workload, thus adjusting the utilization of computational resource according to service requirements. Simulations verify the superiority of our proposed SemAIGC framework in terms of latency and content quality compared to conventional approaches.
Explicit Time Embedding Based Cascade Attention Network for Information Popularity Prediction
Aug 19, 2023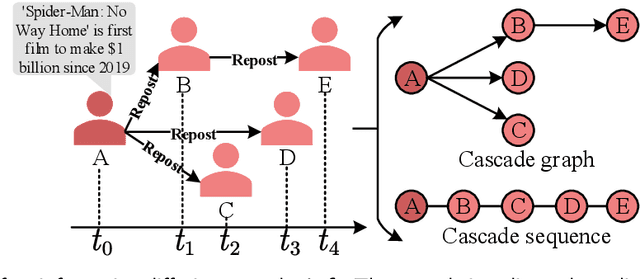
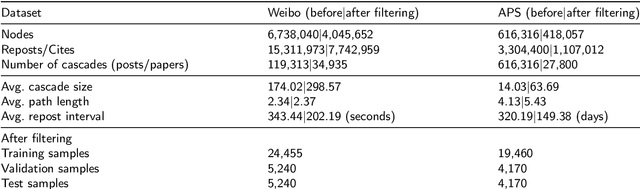
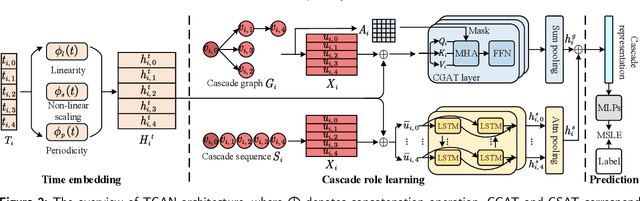
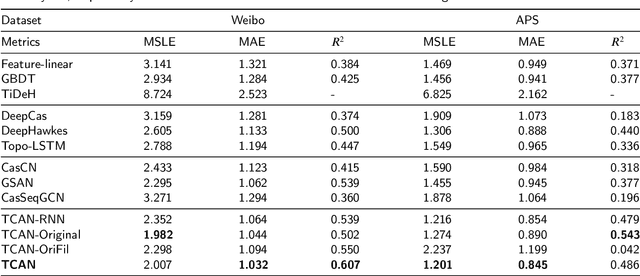
Predicting information cascade popularity is a fundamental problem in social networks. Capturing temporal attributes and cascade role information (e.g., cascade graphs and cascade sequences) is necessary for understanding the information cascade. Current methods rarely focus on unifying this information for popularity predictions, which prevents them from effectively modeling the full properties of cascades to achieve satisfactory prediction performances. In this paper, we propose an explicit Time embedding based Cascade Attention Network (TCAN) as a novel popularity prediction architecture for large-scale information networks. TCAN integrates temporal attributes (i.e., periodicity, linearity, and non-linear scaling) into node features via a general time embedding approach (TE), and then employs a cascade graph attention encoder (CGAT) and a cascade sequence attention encoder (CSAT) to fully learn the representation of cascade graphs and cascade sequences. We use two real-world datasets (i.e., Weibo and APS) with tens of thousands of cascade samples to validate our methods. Experimental results show that TCAN obtains mean logarithm squared errors of 2.007 and 1.201 and running times of 1.76 hours and 0.15 hours on both datasets, respectively. Furthermore, TCAN outperforms other representative baselines by 10.4%, 3.8%, and 10.4% in terms of MSLE, MAE, and R-squared on average while maintaining good interpretability.
Towards Safer Operations: An Expert-involved Dataset of High-Pressure Gas Incidents for Preventing Future Failures
Oct 23, 2023This paper introduces a new IncidentAI dataset for safety prevention. Different from prior corpora that usually contain a single task, our dataset comprises three tasks: named entity recognition, cause-effect extraction, and information retrieval. The dataset is annotated by domain experts who have at least six years of practical experience as high-pressure gas conservation managers. We validate the contribution of the dataset in the scenario of safety prevention. Preliminary results on the three tasks show that NLP techniques are beneficial for analyzing incident reports to prevent future failures. The dataset facilitates future research in NLP and incident management communities. The access to the dataset is also provided (the IncidentAI dataset is available at: https://github.com/Cinnamon/incident-ai-dataset).
Reasoning about Ambiguous Definite Descriptions
Oct 23, 2023Natural language reasoning plays an increasingly important role in improving language models' ability to solve complex language understanding tasks. An interesting use case for reasoning is the resolution of context-dependent ambiguity. But no resources exist to evaluate how well Large Language Models can use explicit reasoning to resolve ambiguity in language. We propose to use ambiguous definite descriptions for this purpose and create and publish the first benchmark dataset consisting of such phrases. Our method includes all information required to resolve the ambiguity in the prompt, which means a model does not require anything but reasoning to do well. We find this to be a challenging task for recent LLMs. Code and data available at: https://github.com/sfschouten/exploiting-ambiguity
DCQA: Document-Level Chart Question Answering towards Complex Reasoning and Common-Sense Understanding
Oct 29, 2023Visually-situated languages such as charts and plots are omnipresent in real-world documents. These graphical depictions are human-readable and are often analyzed in visually-rich documents to address a variety of questions that necessitate complex reasoning and common-sense responses. Despite the growing number of datasets that aim to answer questions over charts, most only address this task in isolation, without considering the broader context of document-level question answering. Moreover, such datasets lack adequate common-sense reasoning information in their questions. In this work, we introduce a novel task named document-level chart question answering (DCQA). The goal of this task is to conduct document-level question answering, extracting charts or plots in the document via document layout analysis (DLA) first and subsequently performing chart question answering (CQA). The newly developed benchmark dataset comprises 50,010 synthetic documents integrating charts in a wide range of styles (6 styles in contrast to 3 for PlotQA and ChartQA) and includes 699,051 questions that demand a high degree of reasoning ability and common-sense understanding. Besides, we present the development of a potent question-answer generation engine that employs table data, a rich color set, and basic question templates to produce a vast array of reasoning question-answer pairs automatically. Based on DCQA, we devise an OCR-free transformer for document-level chart-oriented understanding, capable of DLA and answering complex reasoning and common-sense questions over charts in an OCR-free manner. Our DCQA dataset is expected to foster research on understanding visualizations in documents, especially for scenarios that require complex reasoning for charts in the visually-rich document. We implement and evaluate a set of baselines, and our proposed method achieves comparable results.