 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Visual-Attribute Prompt Learning for Progressive Mild Cognitive Impairment Prediction
Oct 22, 2023
Deep learning (DL) has been used in the automatic diagnosis of Mild Cognitive Impairment (MCI) and Alzheimer's Disease (AD) with brain imaging data. However, previous methods have not fully exploited the relation between brain image and clinical information that is widely adopted by experts in practice. To exploit the heterogeneous features from imaging and tabular data simultaneously, we propose the Visual-Attribute Prompt Learning-based Transformer (VAP-Former), a transformer-based network that efficiently extracts and fuses the multi-modal features with prompt fine-tuning. Furthermore, we propose a Prompt fine-Tuning (PT) scheme to transfer the knowledge from AD prediction task for progressive MCI (pMCI) diagnosis. In details, we first pre-train the VAP-Former without prompts on the AD diagnosis task and then fine-tune the model on the pMCI detection task with PT, which only needs to optimize a small amount of parameters while keeping the backbone frozen. Next, we propose a novel global prompt token for the visual prompts to provide global guidance to the multi-modal representations. Extensive experiments not only show the superiority of our method compared with the state-of-the-art methods in pMCI prediction but also demonstrate that the global prompt can make the prompt learning process more effective and stable. Interestingly, the proposed prompt learning model even outperforms the fully fine-tuning baseline on transferring the knowledge from AD to pMCI.
Contextualized Machine Learning
Oct 17, 2023We examine Contextualized Machine Learning (ML), a paradigm for learning heterogeneous and context-dependent effects. Contextualized ML estimates heterogeneous functions by applying deep learning to the meta-relationship between contextual information and context-specific parametric models. This is a form of varying-coefficient modeling that unifies existing frameworks including cluster analysis and cohort modeling by introducing two reusable concepts: a context encoder which translates sample context into model parameters, and sample-specific model which operates on sample predictors. We review the process of developing contextualized models, nonparametric inference from contextualized models, and identifiability conditions of contextualized models. Finally, we present the open-source PyTorch package ContextualizedML.
Universal Multi-modal Entity Alignment via Iteratively Fusing Modality Similarity Paths
Oct 10, 2023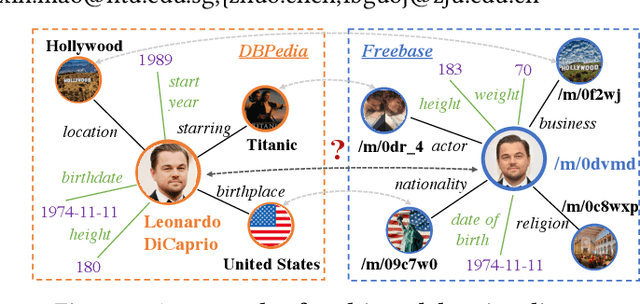
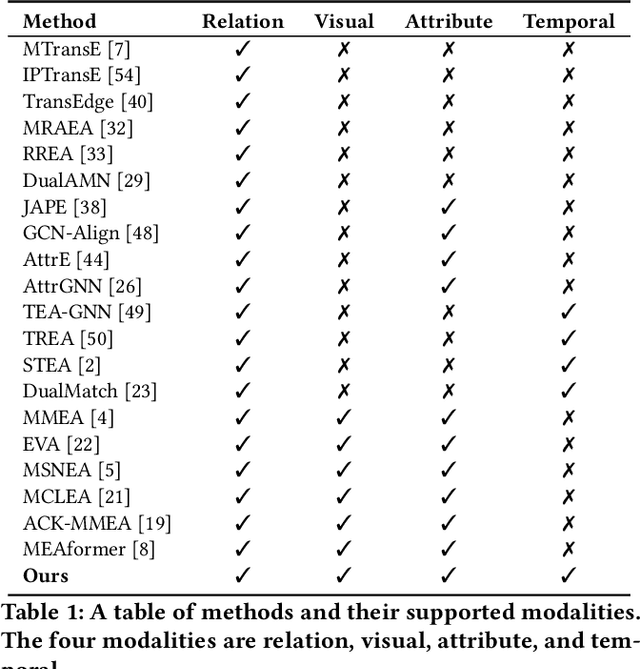

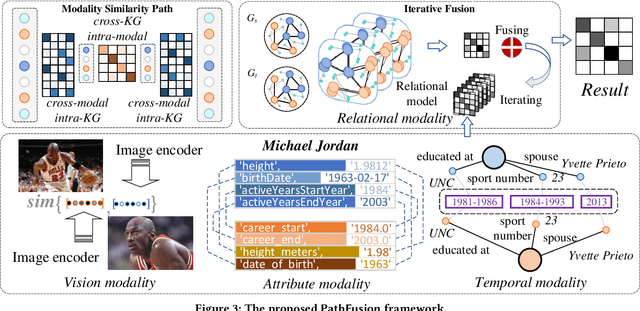
The objective of Entity Alignment (EA) is to identify equivalent entity pairs from multiple Knowledge Graphs (KGs) and create a more comprehensive and unified KG. The majority of EA methods have primarily focused on the structural modality of KGs, lacking exploration of multi-modal information. A few multi-modal EA methods have made good attempts in this field. Still, they have two shortcomings: (1) inconsistent and inefficient modality modeling that designs complex and distinct models for each modality; (2) ineffective modality fusion due to the heterogeneous nature of modalities in EA. To tackle these challenges, we propose PathFusion, consisting of two main components: (1) MSP, a unified modeling approach that simplifies the alignment process by constructing paths connecting entities and modality nodes to represent multiple modalities; (2) IRF, an iterative fusion method that effectively combines information from different modalities using the path as an information carrier. Experimental results on real-world datasets demonstrate the superiority of PathFusion over state-of-the-art methods, with 22.4%-28.9% absolute improvement on Hits@1, and 0.194-0.245 absolute improvement on MRR.
Memory efficient location recommendation through proximity-aware representation
Oct 10, 2023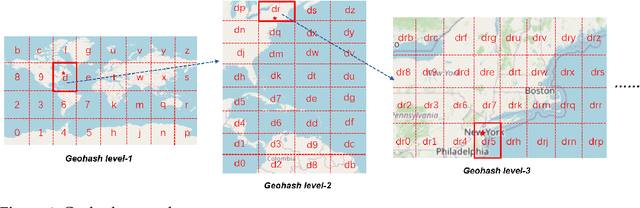
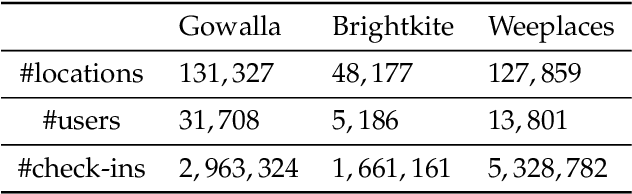
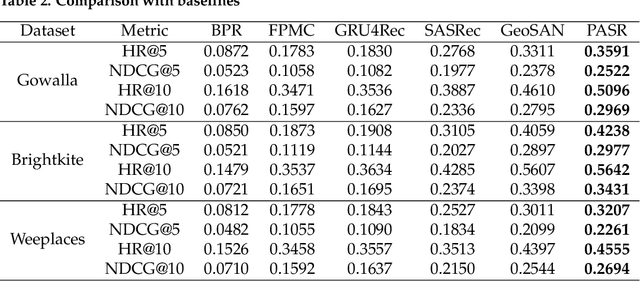
Sequential location recommendation plays a huge role in modern life, which can enhance user experience, bring more profit to businesses and assist in government administration. Although methods for location recommendation have evolved significantly thanks to the development of recommendation systems, there is still limited utilization of geographic information, along with the ongoing challenge of addressing data sparsity. In response, we introduce a Proximity-aware based region representation for Sequential Recommendation (PASR for short), built upon the Self-Attention Network architecture. We tackle the sparsity issue through a novel loss function employing importance sampling, which emphasizes informative negative samples during optimization. Moreover, PASR enhances the integration of geographic information by employing a self-attention-based geography encoder to the hierarchical grid and proximity grid at each GPS point. To further leverage geographic information, we utilize the proximity-aware negative samplers to enhance the quality of negative samples. We conducted evaluations using three real-world Location-Based Social Networking (LBSN) datasets, demonstrating that PASR surpasses state-of-the-art sequential location recommendation methods
Cheap Talking Algorithms
Oct 11, 2023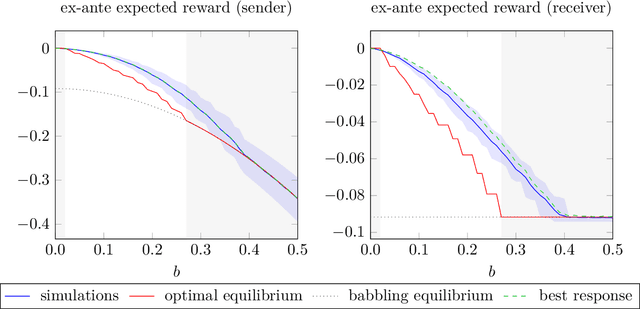
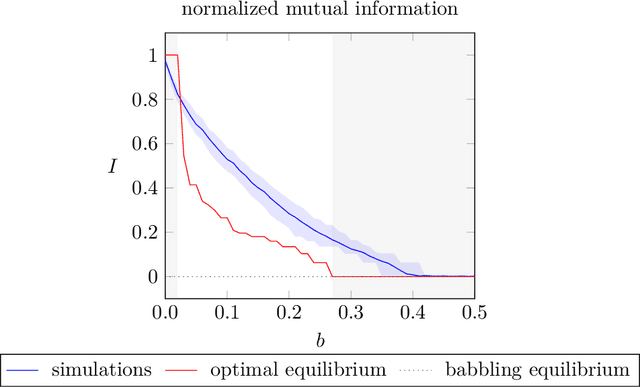
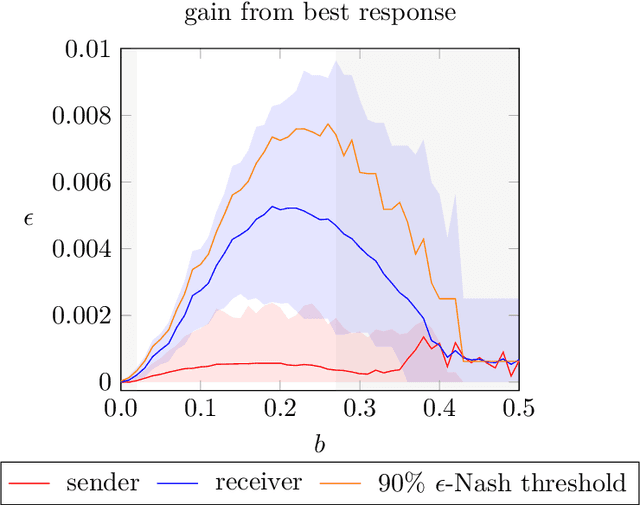
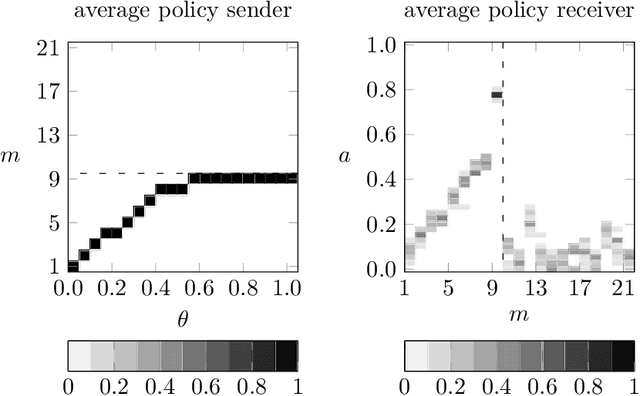
We simulate behaviour of independent reinforcement learning algorithms playing the Crawford and Sobel (1982) game of strategic information transmission. We show that a sender and a receiver training together converge to strategies close to the exante optimal equilibrium of the game. Hence, communication takes place to the largest extent predicted by Nash equilibrium given the degree of conflict of interest between agents. The conclusion is shown to be robust to alternative specifications of the hyperparameters and of the game. We discuss implications for theories of equilibrium selection in information transmission games, for work on emerging communication among algorithms in computer science and for the economics of collusions in markets populated by artificially intelligent agents.
Democratizing LLMs: An Exploration of Cost-Performance Trade-offs in Self-Refined Open-Source Models
Oct 11, 2023The dominance of proprietary LLMs has led to restricted access and raised information privacy concerns. High-performing open-source alternatives are crucial for information-sensitive and high-volume applications but often lag behind in performance. To address this gap, we propose (1) A untargeted variant of iterative self-critique and self-refinement devoid of external influence. (2) A novel ranking metric - Performance, Refinement, and Inference Cost Score (PeRFICS) - to find the optimal model for a given task considering refined performance and cost. Our experiments show that SoTA open source models of varying sizes from 7B - 65B, on average, improve 8.2% from their baseline performance. Strikingly, even models with extremely small memory footprints, such as Vicuna-7B, show a 11.74% improvement overall and up to a 25.39% improvement in high-creativity, open ended tasks on the Vicuna benchmark. Vicuna-13B takes it a step further and outperforms ChatGPT post-refinement. This work has profound implications for resource-constrained and information-sensitive environments seeking to leverage LLMs without incurring prohibitive costs, compromising on performance and privacy. The domain-agnostic self-refinement process coupled with our novel ranking metric facilitates informed decision-making in model selection, thereby reducing costs and democratizing access to high-performing language models, as evidenced by case studies.
Multimodal Graph Learning for Generative Tasks
Oct 12, 2023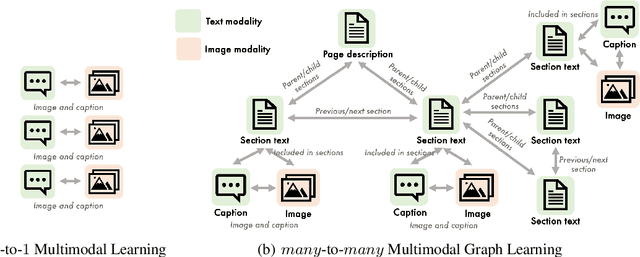
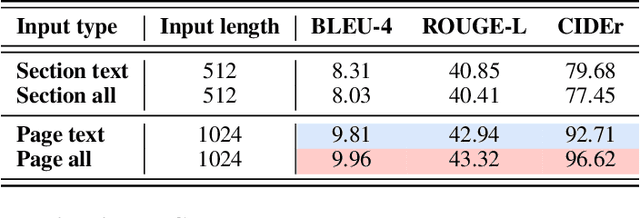
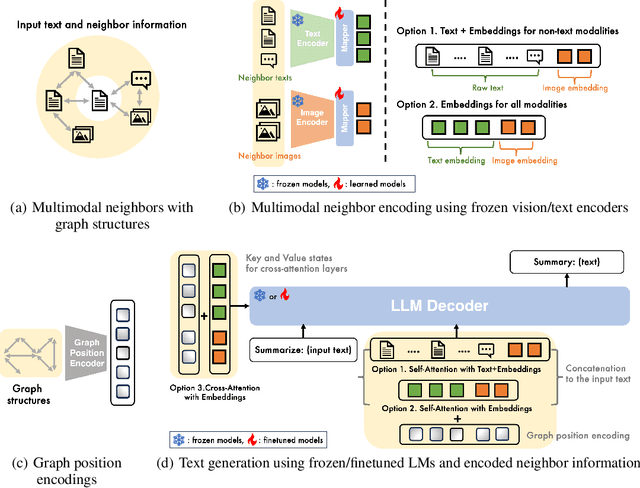
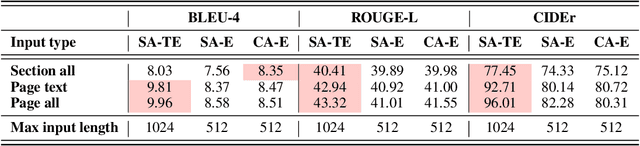
Multimodal learning combines multiple data modalities, broadening the types and complexity of data our models can utilize: for example, from plain text to image-caption pairs. Most multimodal learning algorithms focus on modeling simple one-to-one pairs of data from two modalities, such as image-caption pairs, or audio-text pairs. However, in most real-world settings, entities of different modalities interact with each other in more complex and multifaceted ways, going beyond one-to-one mappings. We propose to represent these complex relationships as graphs, allowing us to capture data with any number of modalities, and with complex relationships between modalities that can flexibly vary from one sample to another. Toward this goal, we propose Multimodal Graph Learning (MMGL), a general and systematic framework for capturing information from multiple multimodal neighbors with relational structures among them. In particular, we focus on MMGL for generative tasks, building upon pretrained Language Models (LMs), aiming to augment their text generation with multimodal neighbor contexts. We study three research questions raised by MMGL: (1) how can we infuse multiple neighbor information into the pretrained LMs, while avoiding scalability issues? (2) how can we infuse the graph structure information among multimodal neighbors into the LMs? and (3) how can we finetune the pretrained LMs to learn from the neighbor context in a parameter-efficient manner? We conduct extensive experiments to answer these three questions on MMGL and analyze the empirical results to pave the way for future MMGL research.
ALPHA: Attention-based Long-horizon Pathfinding in Highly-structured Areas
Oct 12, 2023The multi-agent pathfinding (MAPF) problem seeks collision-free paths for a team of agents from their current positions to their pre-set goals in a known environment, and is an essential problem found at the core of many logistics, transportation, and general robotics applications. Existing learning-based MAPF approaches typically only let each agent make decisions based on a limited field-of-view (FOV) around its position, as a natural means to fix the input dimensions of its policy network. However, this often makes policies short-sighted, since agents lack the ability to perceive and plan for obstacles/agents beyond their FOV. To address this challenge, we propose ALPHA, a new framework combining the use of ground truth proximal (local) information and fuzzy distal (global) information to let agents sequence local decisions based on the full current state of the system, and avoid such myopicity. We further allow agents to make short-term predictions about each others' paths, as a means to reason about each others' path intentions, thereby enhancing the level of cooperation among agents at the whole system level. Our neural structure relies on a Graph Transformer architecture to allow agents to selectively combine these different sources of information and reason about their inter-dependencies at different spatial scales. Our simulation experiments demonstrate that ALPHA outperforms both globally-guided MAPF solvers and communication-learning based ones, showcasing its potential towards scalability in realistic deployments.
Training A Semantic Communication System with Federated Learning
Oct 20, 2023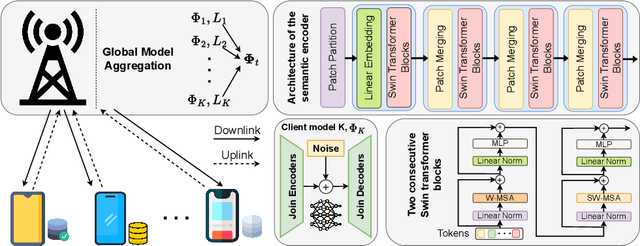
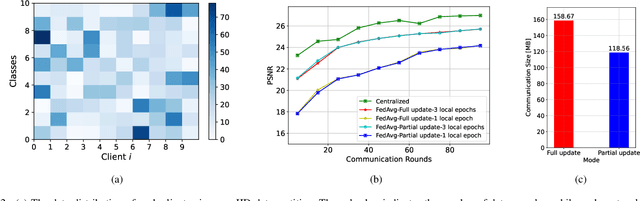
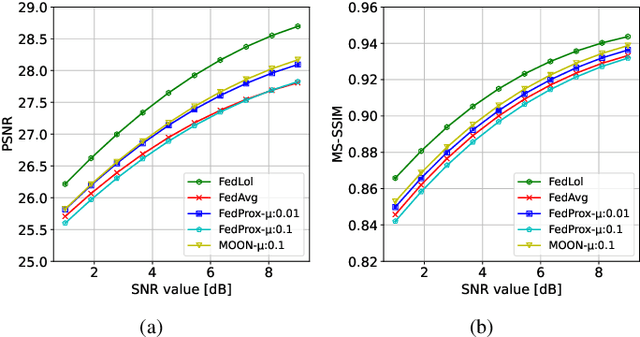

Semantic communication has emerged as a pillar for the next generation of communication systems due to its capabilities in alleviating data redundancy. Most semantic communication systems are built using advanced deep learning models whose performance heavily depends on data availability. These studies assume that an abundance of training data is available, which is unrealistic. In practice, data is mainly created on the user side. Due to privacy and security concerns, the transmission of data is restricted, which is necessary for conventional centralized training schemes. To address this challenge, we explore semantic communication in federated learning (FL) setting that utilizes user data without leaking privacy. Additionally, we design our system to tackle the communication overhead by reducing the quantity of information delivered in each global round. In this way, we can save significant bandwidth for resource-limited devices and reduce overall network traffic. Finally, we propose a mechanism to aggregate the global model from the clients, called FedLol. Extensive simulation results demonstrate the efficacy of our proposed technique compared to baseline methods.
Simultaneous Machine Translation with Tailored Reference
Oct 20, 2023
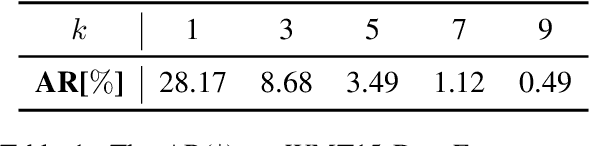
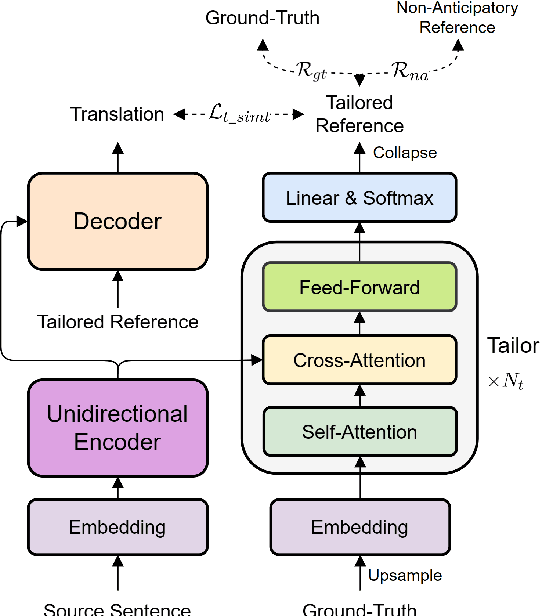

Simultaneous machine translation (SiMT) generates translation while reading the whole source sentence. However, existing SiMT models are typically trained using the same reference disregarding the varying amounts of available source information at different latency. Training the model with ground-truth at low latency may introduce forced anticipations, whereas utilizing reference consistent with the source word order at high latency results in performance degradation. Consequently, it is crucial to train the SiMT model with appropriate reference that avoids forced anticipations during training while maintaining high quality. In this paper, we propose a novel method that provides tailored reference for the SiMT models trained at different latency by rephrasing the ground-truth. Specifically, we introduce the tailor, induced by reinforcement learning, to modify ground-truth to the tailored reference. The SiMT model is trained with the tailored reference and jointly optimized with the tailor to enhance performance. Importantly, our method is applicable to a wide range of current SiMT approaches. Experiments on three translation tasks demonstrate that our method achieves state-of-the-art performance in both fixed and adaptive policies.