 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Step-by-Step Remediation of Students' Mathematical Mistakes
Oct 16, 2023
Scaling high-quality tutoring is a major challenge in education. Because of the growing demand, many platforms employ novice tutors who, unlike professional educators, struggle to effectively address student mistakes and thus fail to seize prime learning opportunities for students. In this paper, we explore the potential for large language models (LLMs) to assist math tutors in remediating student mistakes. We present ReMath, a benchmark co-developed with experienced math teachers that deconstructs their thought process for remediation. The benchmark consists of three step-by-step tasks: (1) infer the type of student error, (2) determine the strategy to address the error, and (3) generate a response that incorporates that information. We evaluate the performance of state-of-the-art instruct-tuned and dialog models on ReMath. Our findings suggest that although models consistently improve upon original tutor responses, we cannot rely on models alone to remediate mistakes. Providing models with the error type (e.g., the student is guessing) and strategy (e.g., simplify the problem) leads to a 75% improvement in the response quality over models without that information. Nonetheless, despite the improvement, the quality of the best model's responses still falls short of experienced math teachers. Our work sheds light on the potential and limitations of using current LLMs to provide high-quality learning experiences for both tutors and students at scale. Our work is open-sourced at this link: \url{https://github.com/rosewang2008/remath}.
Contextualized Machine Learning
Oct 17, 2023We examine Contextualized Machine Learning (ML), a paradigm for learning heterogeneous and context-dependent effects. Contextualized ML estimates heterogeneous functions by applying deep learning to the meta-relationship between contextual information and context-specific parametric models. This is a form of varying-coefficient modeling that unifies existing frameworks including cluster analysis and cohort modeling by introducing two reusable concepts: a context encoder which translates sample context into model parameters, and sample-specific model which operates on sample predictors. We review the process of developing contextualized models, nonparametric inference from contextualized models, and identifiability conditions of contextualized models. Finally, we present the open-source PyTorch package ContextualizedML.
Memory efficient location recommendation through proximity-aware representation
Oct 10, 2023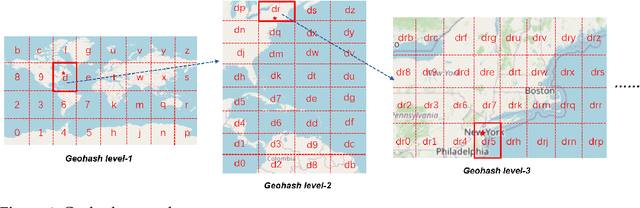
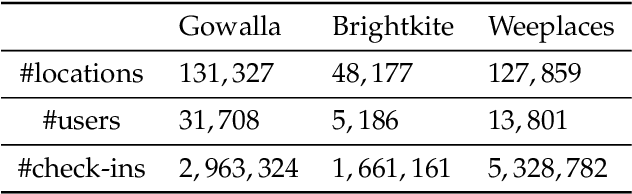
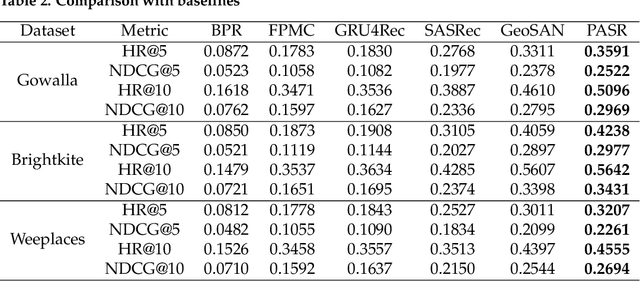
Sequential location recommendation plays a huge role in modern life, which can enhance user experience, bring more profit to businesses and assist in government administration. Although methods for location recommendation have evolved significantly thanks to the development of recommendation systems, there is still limited utilization of geographic information, along with the ongoing challenge of addressing data sparsity. In response, we introduce a Proximity-aware based region representation for Sequential Recommendation (PASR for short), built upon the Self-Attention Network architecture. We tackle the sparsity issue through a novel loss function employing importance sampling, which emphasizes informative negative samples during optimization. Moreover, PASR enhances the integration of geographic information by employing a self-attention-based geography encoder to the hierarchical grid and proximity grid at each GPS point. To further leverage geographic information, we utilize the proximity-aware negative samplers to enhance the quality of negative samples. We conducted evaluations using three real-world Location-Based Social Networking (LBSN) datasets, demonstrating that PASR surpasses state-of-the-art sequential location recommendation methods
Universal Multi-modal Entity Alignment via Iteratively Fusing Modality Similarity Paths
Oct 10, 2023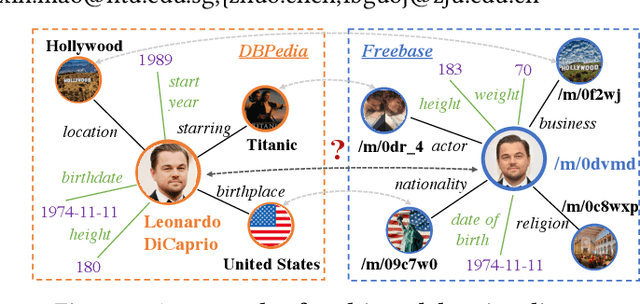
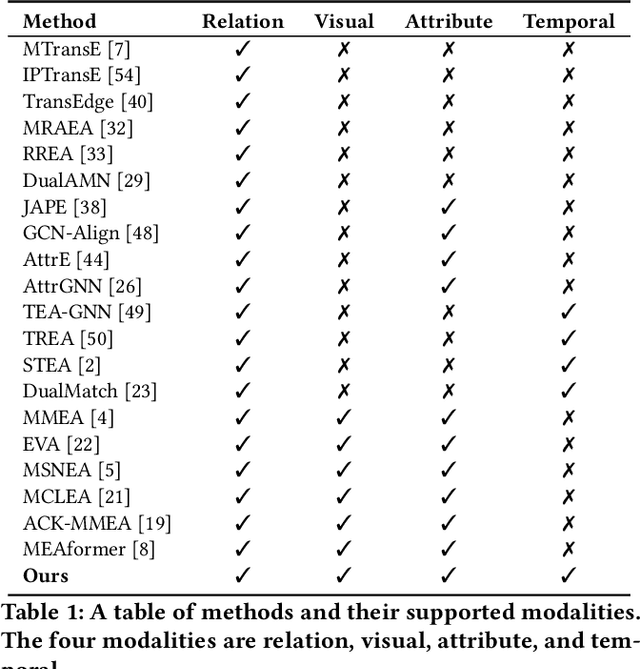

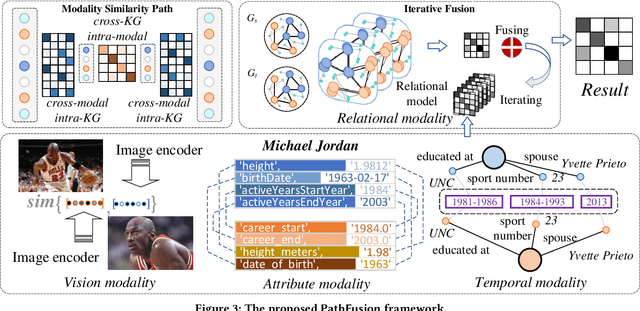
The objective of Entity Alignment (EA) is to identify equivalent entity pairs from multiple Knowledge Graphs (KGs) and create a more comprehensive and unified KG. The majority of EA methods have primarily focused on the structural modality of KGs, lacking exploration of multi-modal information. A few multi-modal EA methods have made good attempts in this field. Still, they have two shortcomings: (1) inconsistent and inefficient modality modeling that designs complex and distinct models for each modality; (2) ineffective modality fusion due to the heterogeneous nature of modalities in EA. To tackle these challenges, we propose PathFusion, consisting of two main components: (1) MSP, a unified modeling approach that simplifies the alignment process by constructing paths connecting entities and modality nodes to represent multiple modalities; (2) IRF, an iterative fusion method that effectively combines information from different modalities using the path as an information carrier. Experimental results on real-world datasets demonstrate the superiority of PathFusion over state-of-the-art methods, with 22.4%-28.9% absolute improvement on Hits@1, and 0.194-0.245 absolute improvement on MRR.
Cheap Talking Algorithms
Oct 11, 2023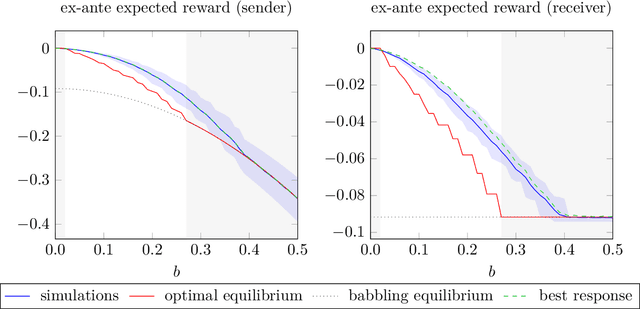
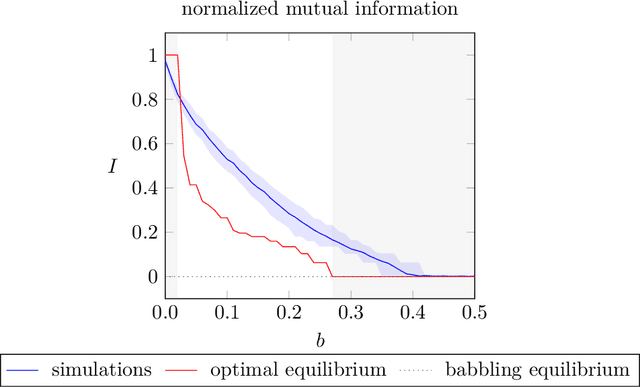
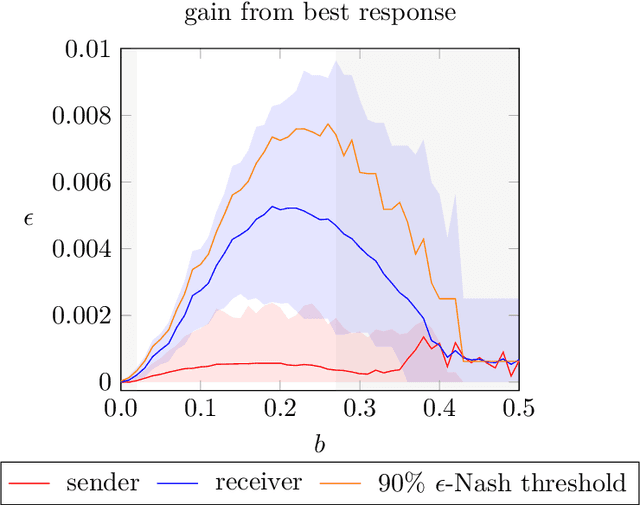
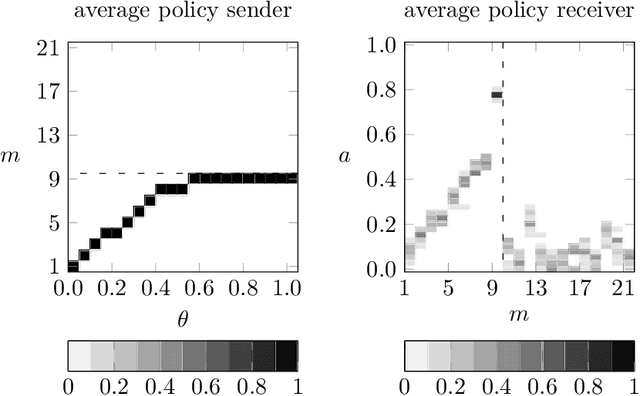
We simulate behaviour of independent reinforcement learning algorithms playing the Crawford and Sobel (1982) game of strategic information transmission. We show that a sender and a receiver training together converge to strategies close to the exante optimal equilibrium of the game. Hence, communication takes place to the largest extent predicted by Nash equilibrium given the degree of conflict of interest between agents. The conclusion is shown to be robust to alternative specifications of the hyperparameters and of the game. We discuss implications for theories of equilibrium selection in information transmission games, for work on emerging communication among algorithms in computer science and for the economics of collusions in markets populated by artificially intelligent agents.
Augmenting End-to-End Steering Angle Prediction with CAN Bus Data
Oct 22, 2023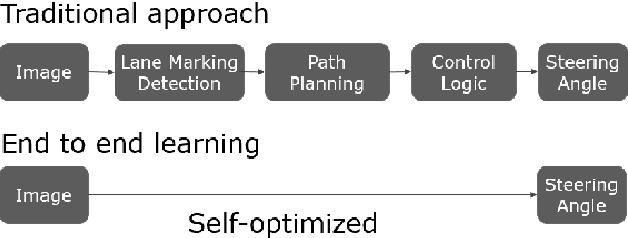
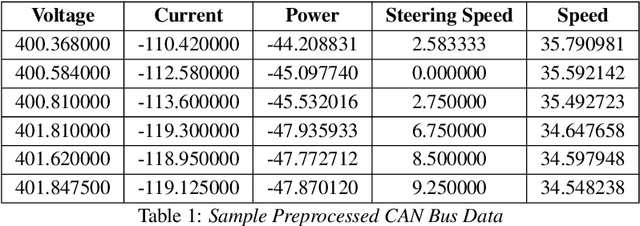
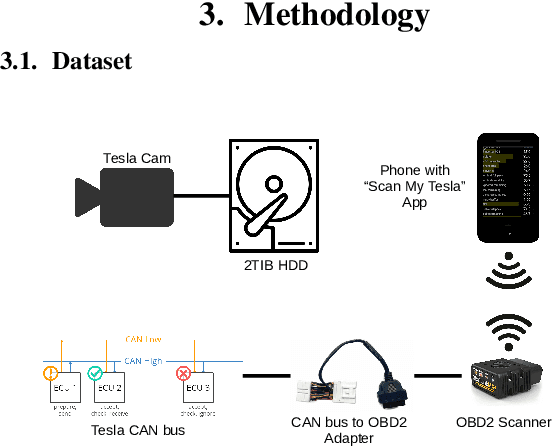
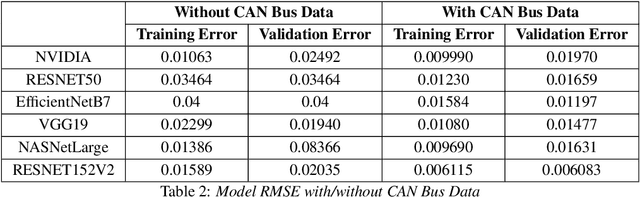
In recent years, end to end steering prediction for autonomous vehicles has become a major area of research. The primary method for achieving end to end steering was to use computer vision models on a live feed of video data. However, to further increase accuracy, many companies have added data from light detection and ranging (LiDAR) and or radar sensors through sensor fusion. However, the addition of lasers and sensors comes at a high financial cost. In this paper, I address both of these issues by increasing the accuracy of the computer vision models without the increased cost of using LiDAR and or sensors. I achieved this by improving the accuracy of computer vision models by sensor fusing CAN bus data, a vehicle protocol, with video data. CAN bus data is a rich source of information about the vehicle's state, including its speed, steering angle, and acceleration. By fusing this data with video data, the accuracy of the computer vision model's predictions can be improved. When I trained the model without CAN bus data, I obtained an RMSE of 0.02492, while the model trained with the CAN bus data achieved an RMSE of 0.01970. This finding indicates that fusing CAN Bus data with video data can reduce the computer vision model's prediction error by 20% with some models decreasing the error by 80%.
Visual-Attribute Prompt Learning for Progressive Mild Cognitive Impairment Prediction
Oct 22, 2023Deep learning (DL) has been used in the automatic diagnosis of Mild Cognitive Impairment (MCI) and Alzheimer's Disease (AD) with brain imaging data. However, previous methods have not fully exploited the relation between brain image and clinical information that is widely adopted by experts in practice. To exploit the heterogeneous features from imaging and tabular data simultaneously, we propose the Visual-Attribute Prompt Learning-based Transformer (VAP-Former), a transformer-based network that efficiently extracts and fuses the multi-modal features with prompt fine-tuning. Furthermore, we propose a Prompt fine-Tuning (PT) scheme to transfer the knowledge from AD prediction task for progressive MCI (pMCI) diagnosis. In details, we first pre-train the VAP-Former without prompts on the AD diagnosis task and then fine-tune the model on the pMCI detection task with PT, which only needs to optimize a small amount of parameters while keeping the backbone frozen. Next, we propose a novel global prompt token for the visual prompts to provide global guidance to the multi-modal representations. Extensive experiments not only show the superiority of our method compared with the state-of-the-art methods in pMCI prediction but also demonstrate that the global prompt can make the prompt learning process more effective and stable. Interestingly, the proposed prompt learning model even outperforms the fully fine-tuning baseline on transferring the knowledge from AD to pMCI.
$Λ$-Split: A Privacy-Preserving Split Computing Framework for Cloud-Powered Generative AI
Oct 23, 2023In the wake of the burgeoning expansion of generative artificial intelligence (AI) services, the computational demands inherent to these technologies frequently necessitate cloud-powered computational offloading, particularly for resource-constrained mobile devices. These services commonly employ prompts to steer the generative process, and both the prompts and the resultant content, such as text and images, may harbor privacy-sensitive or confidential information, thereby elevating security and privacy risks. To mitigate these concerns, we introduce $\Lambda$-Split, a split computing framework to facilitate computational offloading while simultaneously fortifying data privacy against risks such as eavesdropping and unauthorized access. In $\Lambda$-Split, a generative model, usually a deep neural network (DNN), is partitioned into three sub-models and distributed across the user's local device and a cloud server: the input-side and output-side sub-models are allocated to the local, while the intermediate, computationally-intensive sub-model resides on the cloud server. This architecture ensures that only the hidden layer outputs are transmitted, thereby preventing the external transmission of privacy-sensitive raw input and output data. Given the black-box nature of DNNs, estimating the original input or output from intercepted hidden layer outputs poses a significant challenge for malicious eavesdroppers. Moreover, $\Lambda$-Split is orthogonal to traditional encryption-based security mechanisms, offering enhanced security when deployed in conjunction. We empirically validate the efficacy of the $\Lambda$-Split framework using Llama 2 and Stable Diffusion XL, representative large language and diffusion models developed by Meta and Stability AI, respectively. Our $\Lambda$-Split implementation is publicly accessible at https://github.com/nishio-laboratory/lambda_split.
One-dimensional convolutional neural network model for breast cancer subtypes classification and biochemical content evaluation using micro-FTIR hyperspectral images
Oct 23, 2023Breast cancer treatment still remains a challenge, where molecular subtypes classification plays a crucial role in selecting appropriate and specific therapy. The four subtypes are Luminal A (LA), Luminal B (LB), HER2 subtype, and Triple-Negative Breast Cancer (TNBC). Immunohistochemistry is the gold-standard evaluation, although interobserver variations are reported and molecular signatures identification is time-consuming. Fourier transform infrared micro-spectroscopy with machine learning approaches have been used to evaluate cancer samples, presenting biochemical-related explainability. However, this explainability is harder when using deep learning. This study created a 1D deep learning tool for breast cancer subtype evaluation and biochemical contribution. Sixty hyperspectral images were acquired from a human breast cancer microarray. K-Means clustering was applied to select tissue and paraffin spectra. CaReNet-V1, a novel 1D convolutional neural network, was developed to classify breast cancer (CA) and adjacent tissue (AT), and molecular subtypes. A 1D adaptation of Grad-CAM was applied to assess the biochemical impact to the classifications. CaReNet-V1 effectively classified CA and AT (test accuracy of 0.89), as well as HER2 and TNBC subtypes (0.83 and 0.86), with greater difficulty for LA and LB (0.74 and 0.68). The model enabled the evaluation of the most contributing wavenumbers to the predictions, providing a direct relationship with the biochemical content. Therefore, CaReNet-V1 and hyperspectral images is a potential approach for breast cancer biopsies assessment, providing additional information to the pathology report. Biochemical content impact feature may be used for other studies, such as treatment efficacy evaluation and development new diagnostics and therapeutic methods.
Deep Autoencoder-based Z-Interference Channels with Perfect and Imperfect CSI
Oct 23, 2023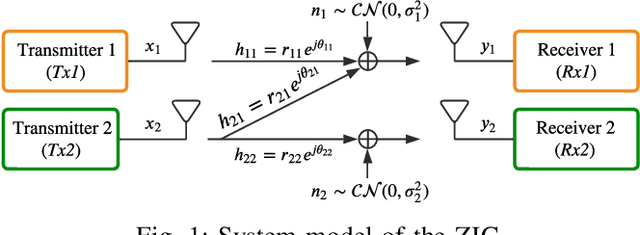
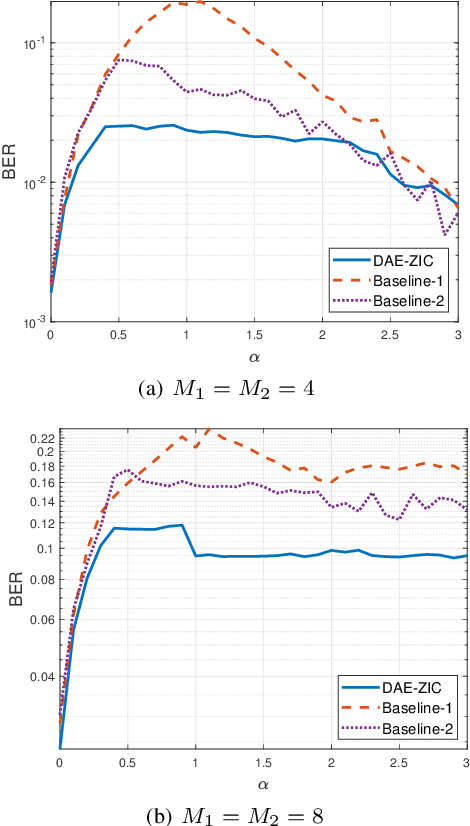
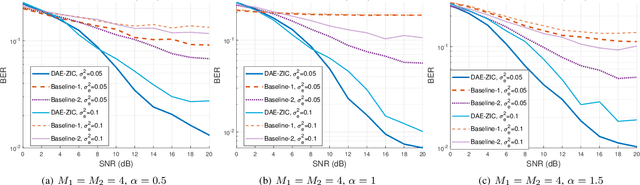
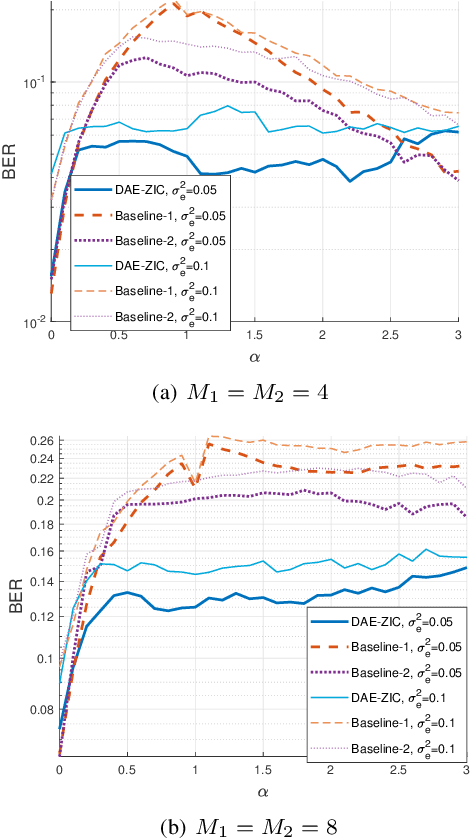
A deep autoencoder (DAE)-based structure for endto-end communication over the two-user Z-interference channel (ZIC) with finite-alphabet inputs is designed in this paper. The proposed structure jointly optimizes the two encoder/decoder pairs and generates interference-aware constellations that dynamically adapt their shape based on interference intensity to minimize the bit error rate (BER). An in-phase/quadrature-phase (I/Q) power allocation layer is introduced in the DAE to guarantee an average power constraint and enable the architecture to generate constellations with nonuniform shapes. This brings further gain compared to standard uniform constellations such as quadrature amplitude modulation. The proposed structure is then extended to work with imperfect channel state information (CSI). The CSI imperfection due to both the estimation and quantization errors are examined. The performance of the DAEZIC is compared with two baseline methods, i.e., standard and rotated constellations. The proposed structure significantly enhances the performance of the ZIC both for the perfect and imperfect CSI. Simulation results show that the improvement is achieved in all interference regimes (weak, moderate, and strong) and consistently increases with the signal-to-noise ratio (SNR). For example, more than an order of magnitude BER reduction is obtained with respect to the most competitive conventional method at weak interference when SNR>15dB and two bits per symbol are transmitted. The improvements reach about two orders of magnitude when quantization error exists, indicating that the DAE-ZIC is more robust to the interference compared to the conventional methods.