 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Agri-GNN: A Novel Genotypic-Topological Graph Neural Network Framework Built on GraphSAGE for Optimized Yield Prediction
Oct 19, 2023
Agriculture, as the cornerstone of human civilization, constantly seeks to integrate technology for enhanced productivity and sustainability. This paper introduces $\textit{Agri-GNN}$, a novel Genotypic-Topological Graph Neural Network Framework tailored to capture the intricate spatial and genotypic interactions of crops, paving the way for optimized predictions of harvest yields. $\textit{Agri-GNN}$ constructs a Graph $\mathcal{G}$ that considers farming plots as nodes, and then methodically constructs edges between nodes based on spatial and genotypic similarity, allowing for the aggregation of node information through a genotypic-topological filter. Graph Neural Networks (GNN), by design, consider the relationships between data points, enabling them to efficiently model the interconnected agricultural ecosystem. By harnessing the power of GNNs, $\textit{Agri-GNN}$ encapsulates both local and global information from plants, considering their inherent connections based on spatial proximity and shared genotypes, allowing stronger predictions to be made than traditional Machine Learning architectures. $\textit{Agri-GNN}$ is built from the GraphSAGE architecture, because of its optimal calibration with large graphs, like those of farming plots and breeding experiments. $\textit{Agri-GNN}$ experiments, conducted on a comprehensive dataset of vegetation indices, time, genotype information, and location data, demonstrate that $\textit{Agri-GNN}$ achieves an $R^2 = .876$ in yield predictions for farming fields in Iowa. The results show significant improvement over the baselines and other work in the field. $\textit{Agri-GNN}$ represents a blueprint for using advanced graph-based neural architectures to predict crop yield, providing significant improvements over baselines in the field.
Semantic Information for Object Detection
Aug 17, 2023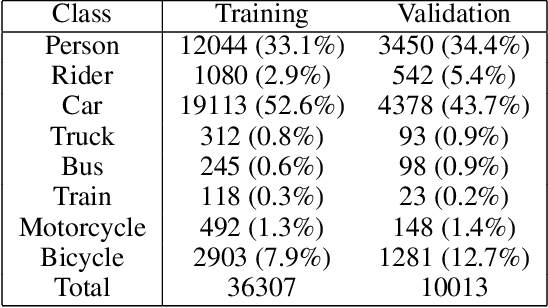
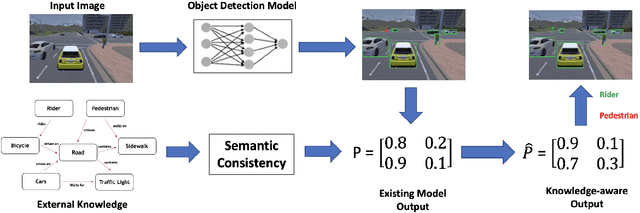

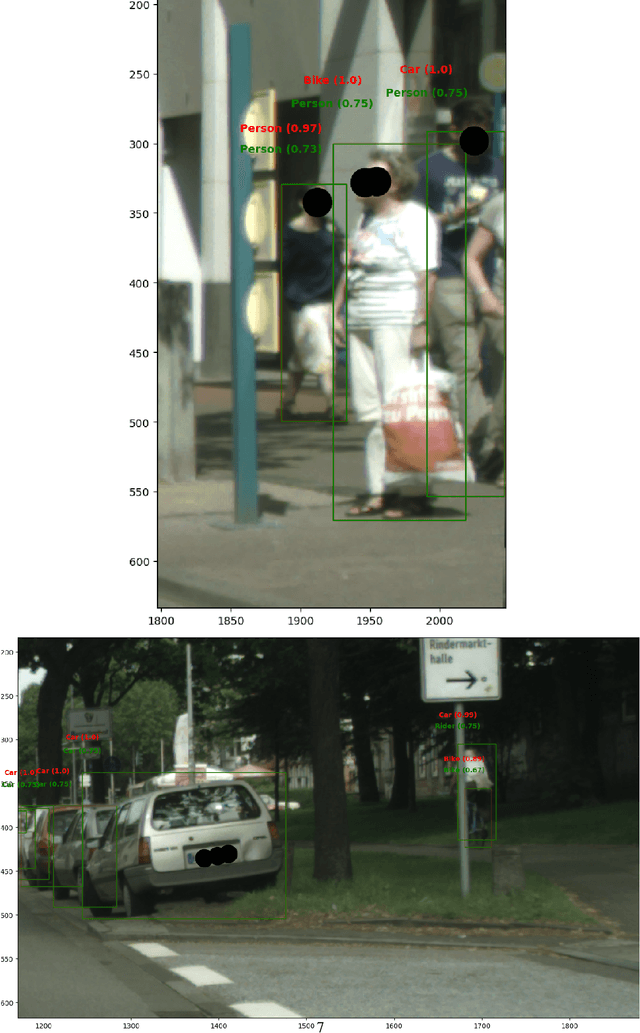
In this paper, we demonstrate that the concept of Semantic Consistency and the ensuing method of Knowledge-Aware Re-Optimization can be adapted for the problem of object detection in intricate traffic scenes. Furthermore, we introduce a novel method for extracting a knowledge graph from a dataset of images provided with instance-level annotations, and integrate this new knowledge graph with the existing semantic consistency model. Combining both this novel hybrid knowledge graph and the preexisting methods of frequency analysis and external knowledge graph as sources for semantic information, we investigate the effectiveness of knowledge-aware re-optimization on the Faster-RCNN and DETR object detection models. We find that limited but consistent improvements in precision and or recall can be achieved using this method for all combinations of model and method studied.
Exploring OCR Capabilities of GPT-4V(ision) : A Quantitative and In-depth Evaluation
Oct 25, 2023This paper presents a comprehensive evaluation of the Optical Character Recognition (OCR) capabilities of the recently released GPT-4V(ision), a Large Multimodal Model (LMM). We assess the model's performance across a range of OCR tasks, including scene text recognition, handwritten text recognition, handwritten mathematical expression recognition, table structure recognition, and information extraction from visually-rich document. The evaluation reveals that GPT-4V performs well in recognizing and understanding Latin contents, but struggles with multilingual scenarios and complex tasks. Based on these observations, we delve deeper into the necessity of specialized OCR models and deliberate on the strategies to fully harness the pretrained general LMMs like GPT-4V for OCR downstream tasks. The study offers a critical reference for future research in OCR with LMMs. Evaluation pipeline and results are available at https://github.com/SCUT-DLVCLab/GPT-4V_OCR.
Aplicacion de Robots Humanoides como Guias Interactivos en Museos: Una Simulacion con el Robot NAO
Oct 25, 2023This article presents an application that evaluates the feasibility of humanoid robots as interactive guides in art museums. The application entailes programming a NAO robot and a chatbot to provide information about art pieces in a simulated museum environment. In this controlled scenario, the learning employees interact with the robot and the chatbot. The result is a skilled participation in the interactions, along with the effectiveness of the robot and chatbot that communicates the basic details of the art objects. You see natural and fluid interactions between the students and the robot. This suggests that the addition of humanoid robots to museums may provide a better experience for visitors, but also the need to continue to do more to optimize the quality of interaction. This study contributes to understanding the possibilities and requirements of applying humanoid technologies in a cultural context.
Graph Neural Networks with a Distribution of Parametrized Graphs
Oct 25, 2023Traditionally, graph neural networks have been trained using a single observed graph. However, the observed graph represents only one possible realization. In many applications, the graph may encounter uncertainties, such as having erroneous or missing edges, as well as edge weights that provide little informative value. To address these challenges and capture additional information previously absent in the observed graph, we introduce latent variables to parameterize and generate multiple graphs. We obtain the maximum likelihood estimate of the network parameters in an Expectation-Maximization (EM) framework based on the multiple graphs. Specifically, we iteratively determine the distribution of the graphs using a Markov Chain Monte Carlo (MCMC) method, incorporating the principles of PAC-Bayesian theory. Numerical experiments demonstrate improvements in performance against baseline models on node classification for heterogeneous graphs and graph regression on chemistry datasets.
Unleashing the potential of prompt engineering in Large Language Models: a comprehensive review
Oct 27, 2023This paper delves into the pivotal role of prompt engineering in unleashing the capabilities of Large Language Models (LLMs). Prompt engineering is the process of structuring input text for LLMs and is a technique integral to optimizing the efficacy of LLMs. This survey elucidates foundational principles of prompt engineering, such as role-prompting, one-shot, and few-shot prompting, as well as more advanced methodologies such as the chain-of-thought and tree-of-thoughts prompting. The paper sheds light on how external assistance in the form of plugins can assist in this task, and reduce machine hallucination by retrieving external knowledge. We subsequently delineate prospective directions in prompt engineering research, emphasizing the need for a deeper understanding of structures and the role of agents in Artificial Intelligence-Generated Content (AIGC) tools. We discuss how to assess the efficacy of prompt methods from different perspectives and using different methods. Finally, we gather information about the application of prompt engineering in such fields as education and programming, showing its transformative potential. This comprehensive survey aims to serve as a friendly guide for anyone venturing through the big world of LLMs and prompt engineering.
Alignment and Outer Shell Isotropy for Hyperbolic Graph Contrastive Learning
Oct 27, 2023Learning good self-supervised graph representations that are beneficial to downstream tasks is challenging. Among a variety of methods, contrastive learning enjoys competitive performance. The embeddings of contrastive learning are arranged on a hypersphere that enables the Cosine distance measurement in the Euclidean space. However, the underlying structure of many domains such as graphs exhibits highly non-Euclidean latent geometry. To this end, we propose a novel contrastive learning framework to learn high-quality graph embedding. Specifically, we design the alignment metric that effectively captures the hierarchical data-invariant information, as well as we propose a substitute of uniformity metric to prevent the so-called dimensional collapse. We show that in the hyperbolic space one has to address the leaf- and height-level uniformity which are related to properties of trees, whereas in the ambient space of the hyperbolic manifold, these notions translate into imposing an isotropic ring density towards boundaries of Poincar\'e ball. This ring density can be easily imposed by promoting the isotropic feature distribution on the tangent space of manifold. In the experiments, we demonstrate the efficacy of our proposed method across different hyperbolic graph embedding techniques in both supervised and self-supervised learning settings.
Function Space Bayesian Pseudocoreset for Bayesian Neural Networks
Oct 27, 2023A Bayesian pseudocoreset is a compact synthetic dataset summarizing essential information of a large-scale dataset and thus can be used as a proxy dataset for scalable Bayesian inference. Typically, a Bayesian pseudocoreset is constructed by minimizing a divergence measure between the posterior conditioning on the pseudocoreset and the posterior conditioning on the full dataset. However, evaluating the divergence can be challenging, particularly for the models like deep neural networks having high-dimensional parameters. In this paper, we propose a novel Bayesian pseudocoreset construction method that operates on a function space. Unlike previous methods, which construct and match the coreset and full data posteriors in the space of model parameters (weights), our method constructs variational approximations to the coreset posterior on a function space and matches it to the full data posterior in the function space. By working directly on the function space, our method could bypass several challenges that may arise when working on a weight space, including limited scalability and multi-modality issue. Through various experiments, we demonstrate that the Bayesian pseudocoresets constructed from our method enjoys enhanced uncertainty quantification and better robustness across various model architectures.
SDOH-NLI: a Dataset for Inferring Social Determinants of Health from Clinical Notes
Oct 27, 2023Social and behavioral determinants of health (SDOH) play a significant role in shaping health outcomes, and extracting these determinants from clinical notes is a first step to help healthcare providers systematically identify opportunities to provide appropriate care and address disparities. Progress on using NLP methods for this task has been hindered by the lack of high-quality publicly available labeled data, largely due to the privacy and regulatory constraints on the use of real patients' information. This paper introduces a new dataset, SDOH-NLI, that is based on publicly available notes and which we release publicly. We formulate SDOH extraction as a natural language inference (NLI) task, and provide binary textual entailment labels obtained from human raters for a cross product of a set of social history snippets as premises and SDOH factors as hypotheses. Our dataset differs from standard NLI benchmarks in that our premises and hypotheses are obtained independently. We evaluate both "off-the-shelf" entailment models as well as models fine-tuned on our data, and highlight the ways in which our dataset appears more challenging than commonly used NLI datasets.
Feature Selection in the Contrastive Analysis Setting
Oct 27, 2023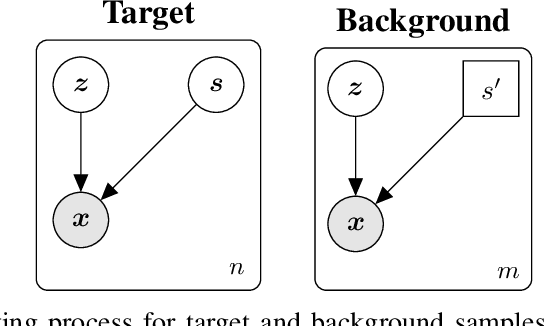
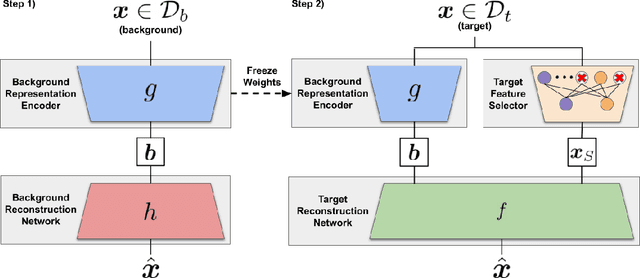
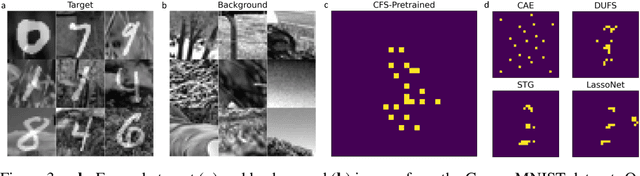

Contrastive analysis (CA) refers to the exploration of variations uniquely enriched in a target dataset as compared to a corresponding background dataset generated from sources of variation that are irrelevant to a given task. For example, a biomedical data analyst may wish to find a small set of genes to use as a proxy for variations in genomic data only present among patients with a given disease (target) as opposed to healthy control subjects (background). However, as of yet the problem of feature selection in the CA setting has received little attention from the machine learning community. In this work we present contrastive feature selection (CFS), a method for performing feature selection in the CA setting. We motivate our approach with a novel information-theoretic analysis of representation learning in the CA setting, and we empirically validate CFS on a semi-synthetic dataset and four real-world biomedical datasets. We find that our method consistently outperforms previously proposed state-of-the-art supervised and fully unsupervised feature selection methods not designed for the CA setting. An open-source implementation of our method is available at https://github.com/suinleelab/CFS.