 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning with Noisy Labels Using Collaborative Sample Selection and Contrastive Semi-Supervised Learning
Oct 24, 2023
Learning with noisy labels (LNL) has been extensively studied, with existing approaches typically following a framework that alternates between clean sample selection and semi-supervised learning (SSL). However, this approach has a limitation: the clean set selected by the Deep Neural Network (DNN) classifier, trained through self-training, inevitably contains noisy samples. This mixture of clean and noisy samples leads to misguidance in DNN training during SSL, resulting in impaired generalization performance due to confirmation bias caused by error accumulation in sample selection. To address this issue, we propose a method called Collaborative Sample Selection (CSS), which leverages the large-scale pre-trained model CLIP. CSS aims to remove the mixed noisy samples from the identified clean set. We achieve this by training a 2-Dimensional Gaussian Mixture Model (2D-GMM) that combines the probabilities from CLIP with the predictions from the DNN classifier. To further enhance the adaptation of CLIP to LNL, we introduce a co-training mechanism with a contrastive loss in semi-supervised learning. This allows us to jointly train the prompt of CLIP and the DNN classifier, resulting in improved feature representation, boosted classification performance of DNNs, and reciprocal benefits to our Collaborative Sample Selection. By incorporating auxiliary information from CLIP and utilizing prompt fine-tuning, we effectively eliminate noisy samples from the clean set and mitigate confirmation bias during training. Experimental results on multiple benchmark datasets demonstrate the effectiveness of our proposed method in comparison with the state-of-the-art approaches.
Characterizing Mechanisms for Factual Recall in Language Models
Oct 24, 2023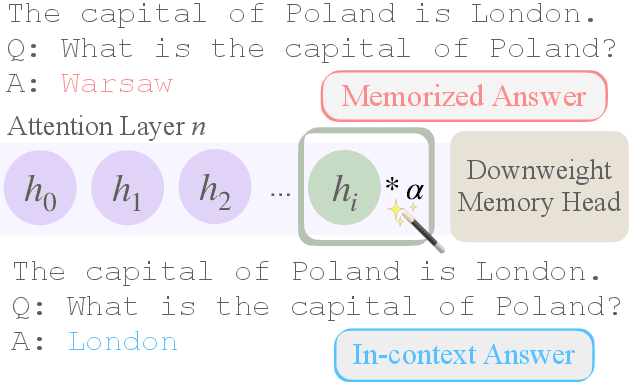

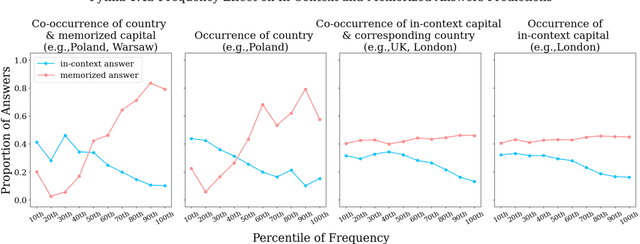
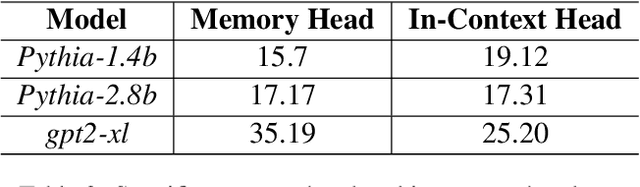
Language Models (LMs) often must integrate facts they memorized in pretraining with new information that appears in a given context. These two sources can disagree, causing competition within the model, and it is unclear how an LM will resolve the conflict. On a dataset that queries for knowledge of world capitals, we investigate both distributional and mechanistic determinants of LM behavior in such situations. Specifically, we measure the proportion of the time an LM will use a counterfactual prefix (e.g., "The capital of Poland is London") to overwrite what it learned in pretraining ("Warsaw"). On Pythia and GPT2, the training frequency of both the query country ("Poland") and the in-context city ("London") highly affect the models' likelihood of using the counterfactual. We then use head attribution to identify individual attention heads that either promote the memorized answer or the in-context answer in the logits. By scaling up or down the value vector of these heads, we can control the likelihood of using the in-context answer on new data. This method can increase the rate of generating the in-context answer to 88\% of the time simply by scaling a single head at runtime. Our work contributes to a body of evidence showing that we can often localize model behaviors to specific components and provides a proof of concept for how future methods might control model behavior dynamically at runtime.
Non-Stationary Contextual Bandit Learning via Neural Predictive Ensemble Sampling
Oct 14, 2023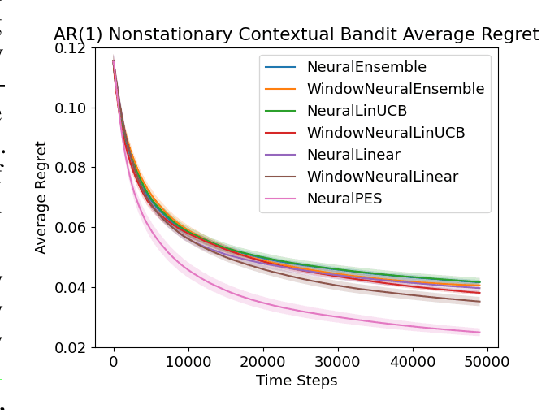
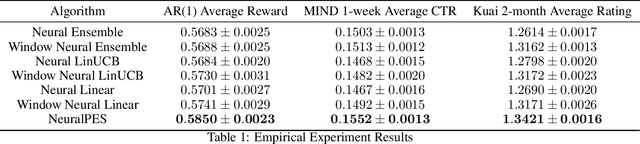
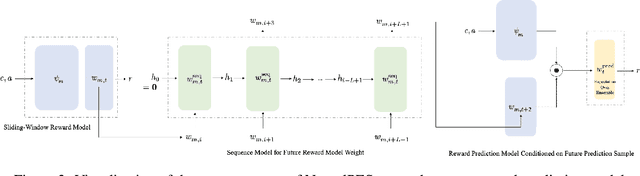

Real-world applications of contextual bandits often exhibit non-stationarity due to seasonality, serendipity, and evolving social trends. While a number of non-stationary contextual bandit learning algorithms have been proposed in the literature, they excessively explore due to a lack of prioritization for information of enduring value, or are designed in ways that do not scale in modern applications with high-dimensional user-specific features and large action set, or both. In this paper, we introduce a novel non-stationary contextual bandit algorithm that addresses these concerns. It combines a scalable, deep-neural-network-based architecture with a carefully designed exploration mechanism that strategically prioritizes collecting information with the most lasting value in a non-stationary environment. Through empirical evaluations on two real-world recommendation datasets, which exhibit pronounced non-stationarity, we demonstrate that our approach significantly outperforms the state-of-the-art baselines.
Randomized Benchmarking of Local Zeroth-Order Optimizers for Variational Quantum Systems
Oct 14, 2023In the field of quantum information, classical optimizers play an important role. From experimentalists optimizing their physical devices to theorists exploring variational quantum algorithms, many aspects of quantum information require the use of a classical optimizer. For this reason, there are many papers that benchmark the effectiveness of different optimizers for specific quantum optimization tasks and choices of parameterized algorithms. However, for researchers exploring new algorithms or physical devices, the insights from these studies don't necessarily translate. To address this concern, we compare the performance of classical optimizers across a series of partially-randomized tasks to more broadly sample the space of quantum optimization problems. We focus on local zeroth-order optimizers due to their generally favorable performance and query-efficiency on quantum systems. We discuss insights from these experiments that can help motivate future works to improve these optimizers for use on quantum systems.
SAIR: Learning Semantic-aware Implicit Representation
Oct 13, 2023Implicit representation of an image can map arbitrary coordinates in the continuous domain to their corresponding color values, presenting a powerful capability for image reconstruction. Nevertheless, existing implicit representation approaches only focus on building continuous appearance mapping, ignoring the continuities of the semantic information across pixels. As a result, they can hardly achieve desired reconstruction results when the semantic information within input images is corrupted, for example, a large region misses. To address the issue, we propose to learn semantic-aware implicit representation (SAIR), that is, we make the implicit representation of each pixel rely on both its appearance and semantic information (\eg, which object does the pixel belong to). To this end, we propose a framework with two modules: (1) building a semantic implicit representation (SIR) for a corrupted image whose large regions miss. Given an arbitrary coordinate in the continuous domain, we can obtain its respective text-aligned embedding indicating the object the pixel belongs. (2) building an appearance implicit representation (AIR) based on the SIR. Given an arbitrary coordinate in the continuous domain, we can reconstruct its color whether or not the pixel is missed in the input. We validate the novel semantic-aware implicit representation method on the image inpainting task, and the extensive experiments demonstrate that our method surpasses state-of-the-art approaches by a significant margin.
Learning Co-Speech Gesture for Multimodal Aphasia Type Detection
Oct 20, 2023Aphasia, a language disorder resulting from brain damage, requires accurate identification of specific aphasia types, such as Broca's and Wernicke's aphasia, for effective treatment. However, little attention has been paid to developing methods to detect different types of aphasia. Recognizing the importance of analyzing co-speech gestures for distinguish aphasia types, we propose a multimodal graph neural network for aphasia type detection using speech and corresponding gesture patterns. By learning the correlation between the speech and gesture modalities for each aphasia type, our model can generate textual representations sensitive to gesture information, leading to accurate aphasia type detection. Extensive experiments demonstrate the superiority of our approach over existing methods, achieving state-of-the-art results (F1 84.2\%). We also show that gesture features outperform acoustic features, highlighting the significance of gesture expression in detecting aphasia types. We provide the codes for reproducibility purposes.
Copyright Violations and Large Language Models
Oct 20, 2023Language models may memorize more than just facts, including entire chunks of texts seen during training. Fair use exemptions to copyright laws typically allow for limited use of copyrighted material without permission from the copyright holder, but typically for extraction of information from copyrighted materials, rather than {\em verbatim} reproduction. This work explores the issue of copyright violations and large language models through the lens of verbatim memorization, focusing on possible redistribution of copyrighted text. We present experiments with a range of language models over a collection of popular books and coding problems, providing a conservative characterization of the extent to which language models can redistribute these materials. Overall, this research highlights the need for further examination and the potential impact on future developments in natural language processing to ensure adherence to copyright regulations. Code is at \url{https://github.com/coastalcph/CopyrightLLMs}.
Multi-level Contrastive Learning for Script-based Character Understanding
Oct 20, 2023In this work, we tackle the scenario of understanding characters in scripts, which aims to learn the characters' personalities and identities from their utterances. We begin by analyzing several challenges in this scenario, and then propose a multi-level contrastive learning framework to capture characters' global information in a fine-grained manner. To validate the proposed framework, we conduct extensive experiments on three character understanding sub-tasks by comparing with strong pre-trained language models, including SpanBERT, Longformer, BigBird and ChatGPT-3.5. Experimental results demonstrate that our method improves the performances by a considerable margin. Through further in-depth analysis, we show the effectiveness of our method in addressing the challenges and provide more hints on the scenario of character understanding. We will open-source our work on github at https://github.com/David-Li0406/Script-based-Character-Understanding.
ReLM: Leveraging Language Models for Enhanced Chemical Reaction Prediction
Oct 20, 2023Predicting chemical reactions, a fundamental challenge in chemistry, involves forecasting the resulting products from a given reaction process. Conventional techniques, notably those employing Graph Neural Networks (GNNs), are often limited by insufficient training data and their inability to utilize textual information, undermining their applicability in real-world applications. In this work, we propose ReLM, a novel framework that leverages the chemical knowledge encoded in language models (LMs) to assist GNNs, thereby enhancing the accuracy of real-world chemical reaction predictions. To further enhance the model's robustness and interpretability, we incorporate the confidence score strategy, enabling the LMs to self-assess the reliability of their predictions. Our experimental results demonstrate that ReLM improves the performance of state-of-the-art GNN-based methods across various chemical reaction datasets, especially in out-of-distribution settings. Codes are available at https://github.com/syr-cn/ReLM.
Deep Learning for blind spectral unmixing of LULC classes with MODIS multispectral time series and ancillary data
Oct 11, 2023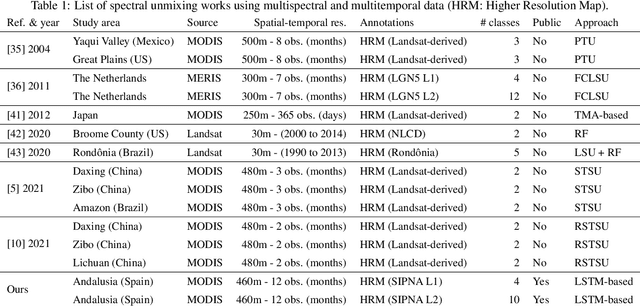
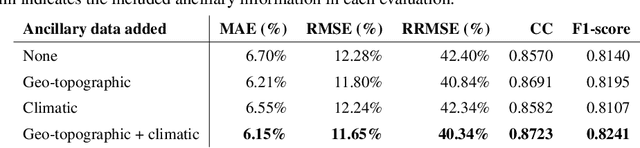
Remotely sensed data are dominated by mixed Land Use and Land Cover (LULC) types. Spectral unmixing is a technique to extract information from mixed pixels into their constituent LULC types and corresponding abundance fractions. Traditionally, solving this task has relied on either classical methods that require prior knowledge of endmembers or machine learning methods that avoid explicit endmembers calculation, also known as blind spectral unmixing (BSU). Most BSU studies based on Deep Learning (DL) focus on one time-step hyperspectral data, yet its acquisition remains quite costly compared with multispectral data. To our knowledge, here we provide the first study on BSU of LULC classes using multispectral time series data with DL models. We further boost the performance of a Long-Short Term Memory (LSTM)-based model by incorporating geographic plus topographic (geo-topographic) and climatic ancillary information. Our experiments show that combining spectral-temporal input data together with geo-topographic and climatic information substantially improves the abundance estimation of LULC classes in mixed pixels. To carry out this study, we built a new labeled dataset of the region of Andalusia (Spain) with monthly multispectral time series of pixels for the year 2013 from MODIS at 460m resolution, for two hierarchical levels of LULC classes, named Andalusia MultiSpectral MultiTemporal Unmixing (Andalusia-MSMTU). This dataset provides, at the pixel level, a multispectral time series plus ancillary information annotated with the abundance of each LULC class inside each pixel. The dataset and code are available to the public.