 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Instability of computer vision models is a necessary result of the task itself
Oct 26, 2023
Adversarial examples resulting from instability of current computer vision models are an extremely important topic due to their potential to compromise any application. In this paper we demonstrate that instability is inevitable due to a) symmetries (translational invariance) of the data, b) the categorical nature of the classification task, and c) the fundamental discrepancy of classifying images as objects themselves. The issue is further exacerbated by non-exhaustive labelling of the training data. Therefore we conclude that instability is a necessary result of how the problem of computer vision is currently formulated. While the problem cannot be eliminated, through the analysis of the causes, we have arrived at ways how it can be partially alleviated. These include i) increasing the resolution of images, ii) providing contextual information for the image, iii) exhaustive labelling of training data, and iv) preventing attackers from frequent access to the computer vision system.
Driving through the Concept Gridlock: Unraveling Explainability Bottlenecks in Automated Driving
Oct 26, 2023Concept bottleneck models have been successfully used for explainable machine learning by encoding information within the model with a set of human-defined concepts. In the context of human-assisted or autonomous driving, explainability models can help user acceptance and understanding of decisions made by the autonomous vehicle, which can be used to rationalize and explain driver or vehicle behavior. We propose a new approach using concept bottlenecks as visual features for control command predictions and explanations of user and vehicle behavior. We learn a human-understandable concept layer that we use to explain sequential driving scenes while learning vehicle control commands. This approach can then be used to determine whether a change in a preferred gap or steering commands from a human (or autonomous vehicle) is led by an external stimulus or change in preferences. We achieve competitive performance to latent visual features while gaining interpretability within our model setup.
GraphGPT: Graph Instruction Tuning for Large Language Models
Oct 19, 2023Graph Neural Networks (GNNs) have advanced graph structure understanding via recursive information exchange and aggregation among graph nodes. To improve model robustness, self-supervised learning (SSL) has emerged as a promising approach for data augmentation. However, existing methods for generating pre-trained graph embeddings often rely on fine-tuning with specific downstream task labels, which limits their usability in scenarios where labeled data is scarce or unavailable. To address this, our research focuses on advancing the generalization capabilities of graph models in challenging zero-shot learning scenarios. Inspired by the success of large language models (LLMs), we aim to develop a graph-oriented LLM that can achieve high generalization across diverse downstream datasets and tasks, even without any information available from the downstream graph data. In this work, we present the GraphGPT framework that aligns LLMs with graph structural knowledge with a graph instruction tuning paradigm. Our framework incorporates a text-graph grounding component to establish a connection between textual information and graph structures. Additionally, we propose a dual-stage instruction tuning paradigm, accompanied by a lightweight graph-text alignment projector. This paradigm explores self-supervised graph structural signals and task-specific graph instructions, to guide LLMs in understanding complex graph structures and improving their adaptability across different downstream tasks. Our framework is evaluated on supervised and zero-shot graph learning tasks, demonstrating superior generalization and outperforming state-of-the-art baselines.
Parallel Bayesian Optimization Using Satisficing Thompson Sampling for Time-Sensitive Black-Box Optimization
Oct 19, 2023Bayesian optimization (BO) is widely used for black-box optimization problems, and have been shown to perform well in various real-world tasks. However, most of the existing BO methods aim to learn the optimal solution, which may become infeasible when the parameter space is extremely large or the problem is time-sensitive. In these contexts, switching to a satisficing solution that requires less information can result in better performance. In this work, we focus on time-sensitive black-box optimization problems and propose satisficing Thompson sampling-based parallel Bayesian optimization (STS-PBO) approaches, including synchronous and asynchronous versions. We shift the target from an optimal solution to a satisficing solution that is easier to learn. The rate-distortion theory is introduced to construct a loss function that balances the amount of information that needs to be learned with sub-optimality, and the Blahut-Arimoto algorithm is adopted to compute the target solution that reaches the minimum information rate under the distortion limit at each step. Both discounted and undiscounted Bayesian cumulative regret bounds are theoretically derived for the proposed STS-PBO approaches. The effectiveness of the proposed methods is demonstrated on a fast-charging design problem of Lithium-ion batteries. The results are accordant with theoretical analyses, and show that our STS-PBO methods outperform both sequential counterparts and parallel BO with traditional Thompson sampling in both synchronous and asynchronous settings.
Cross-attention Spatio-temporal Context Transformer for Semantic Segmentation of Historical Maps
Oct 19, 2023Historical maps provide useful spatio-temporal information on the Earth's surface before modern earth observation techniques came into being. To extract information from maps, neural networks, which gain wide popularity in recent years, have replaced hand-crafted map processing methods and tedious manual labor. However, aleatoric uncertainty, known as data-dependent uncertainty, inherent in the drawing/scanning/fading defects of the original map sheets and inadequate contexts when cropping maps into small tiles considering the memory limits of the training process, challenges the model to make correct predictions. As aleatoric uncertainty cannot be reduced even with more training data collected, we argue that complementary spatio-temporal contexts can be helpful. To achieve this, we propose a U-Net-based network that fuses spatio-temporal features with cross-attention transformers (U-SpaTem), aggregating information at a larger spatial range as well as through a temporal sequence of images. Our model achieves a better performance than other state-or-art models that use either temporal or spatial contexts. Compared with pure vision transformers, our model is more lightweight and effective. To the best of our knowledge, leveraging both spatial and temporal contexts have been rarely explored before in the segmentation task. Even though our application is on segmenting historical maps, we believe that the method can be transferred into other fields with similar problems like temporal sequences of satellite images. Our code is freely accessible at https://github.com/chenyizi086/wu.2023.sigspatial.git.
EntropyRank: Unsupervised Keyphrase Extraction via Side-Information Optimization for Language Model-based Text Compression
Aug 29, 2023We propose an unsupervised method to extract keywords and keyphrases from texts based on a pre-trained language model (LM) and Shannon's information maximization. Specifically, our method extracts phrases having the highest conditional entropy under the LM. The resulting set of keyphrases turns out to solve a relevant information-theoretic problem: if provided as side information, it leads to the expected minimal binary code length in compressing the text using the LM and an entropy encoder. Alternately, the resulting set is an approximation via a causal LM to the set of phrases that minimize the entropy of the text when conditioned upon it. Empirically, the method provides results comparable to the most commonly used methods in various keyphrase extraction benchmark challenges.
DPSS-based Codebook Design for Near-Field XL-MIMO Channel Estimation
Oct 27, 2023Future sixth-generation (6G) systems are expected to leverage extremely large-scale multiple-input multiple-output (XL-MIMO) technology, which significantly expands the range of the near-field region. While accurate channel estimation is essential for beamforming and data detection, the unique characteristics of near-field channels pose additional challenges to the effective acquisition of channel state information. In this paper, we propose a novel codebook design, which allows efficient near-field channel estimation with significantly reduced codebook size. Specifically, we consider the eigen-problem based on the near-field electromagnetic wave transmission model. Moreover, we derive the general form of the eigenvectors associated with the near-field channel matrix, revealing their noteworthy connection to the discrete prolate spheroidal sequence (DPSS). Based on the proposed near-field codebook design, we further introduce a two-step channel estimation scheme. Simulation results demonstrate that the proposed codebook design not only achieves superior sparsification performance of near-field channels with a lower leakage effect, but also significantly improves the accuracy in compressive sensing channel estimation.
"Honey, Tell Me What's Wrong", Global Explanation of Textual Discriminative Models through Cooperative Generation
Oct 27, 2023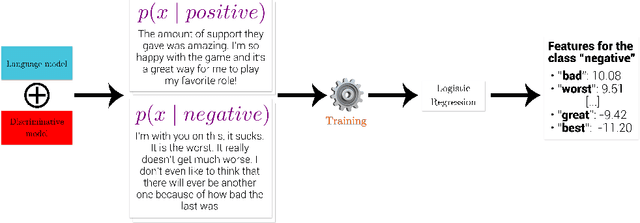

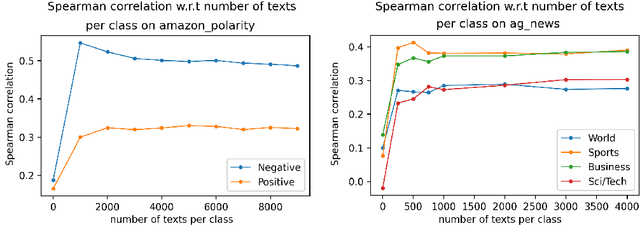
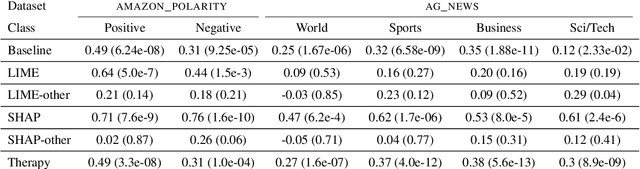
The ubiquity of complex machine learning has raised the importance of model-agnostic explanation algorithms. These methods create artificial instances by slightly perturbing real instances, capturing shifts in model decisions. However, such methods rely on initial data and only provide explanations of the decision for these. To tackle these problems, we propose Therapy, the first global and model-agnostic explanation method adapted to text which requires no input dataset. Therapy generates texts following the distribution learned by a classifier through cooperative generation. Because it does not rely on initial samples, it allows to generate explanations even when data is absent (e.g., for confidentiality reasons). Moreover, conversely to existing methods that combine multiple local explanations into a global one, Therapy offers a global overview of the model behavior on the input space. Our experiments show that although using no input data to generate samples, Therapy provides insightful information about features used by the classifier that is competitive with the ones from methods relying on input samples and outperforms them when input samples are not specific to the studied model.
Preventing Language Models From Hiding Their Reasoning
Oct 27, 2023Large language models (LLMs) often benefit from intermediate steps of reasoning to generate answers to complex problems. When these intermediate steps of reasoning are used to monitor the activity of the model, it is essential that this explicit reasoning is faithful, i.e. that it reflects what the model is actually reasoning about. In this work, we focus on one potential way intermediate steps of reasoning could be unfaithful: encoded reasoning, where an LLM could encode intermediate steps of reasoning in the generated text in a way that is not understandable to human readers. We show that language models can be trained to make use of encoded reasoning to get higher performance without the user understanding the intermediate steps of reasoning. We argue that, as language models get stronger, this behavior becomes more likely to appear naturally. Finally, we describe a methodology that enables the evaluation of defenses against encoded reasoning, and show that, under the right conditions, paraphrasing successfully prevents even the best encoding schemes we built from encoding more than 3 bits of information per KB of text.
Image super-resolution via dynamic network
Oct 16, 2023Convolutional neural networks (CNNs) depend on deep network architectures to extract accurate information for image super-resolution. However, obtained information of these CNNs cannot completely express predicted high-quality images for complex scenes. In this paper, we present a dynamic network for image super-resolution (DSRNet), which contains a residual enhancement block, wide enhancement block, feature refinement block and construction block. The residual enhancement block is composed of a residual enhanced architecture to facilitate hierarchical features for image super-resolution. To enhance robustness of obtained super-resolution model for complex scenes, a wide enhancement block achieves a dynamic architecture to learn more robust information to enhance applicability of an obtained super-resolution model for varying scenes. To prevent interference of components in a wide enhancement block, a refinement block utilizes a stacked architecture to accurately learn obtained features. Also, a residual learning operation is embedded in the refinement block to prevent long-term dependency problem. Finally, a construction block is responsible for reconstructing high-quality images. Designed heterogeneous architecture can not only facilitate richer structural information, but also be lightweight, which is suitable for mobile digital devices. Experimental results shows that our method is more competitive in terms of performance and recovering time of image super-resolution and complexity. The code of DSRNet can be obtained at https://github.com/hellloxiaotian/DSRNet.