 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AdaFuse: Adaptive Medical Image Fusion Based on Spatial-Frequential Cross Attention
Oct 09, 2023
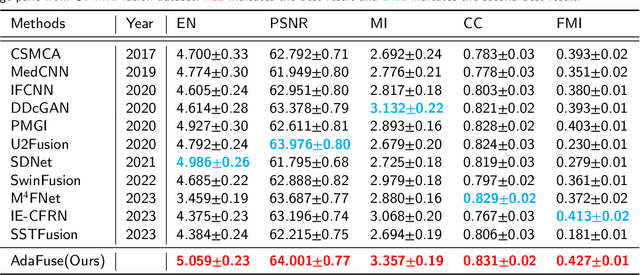
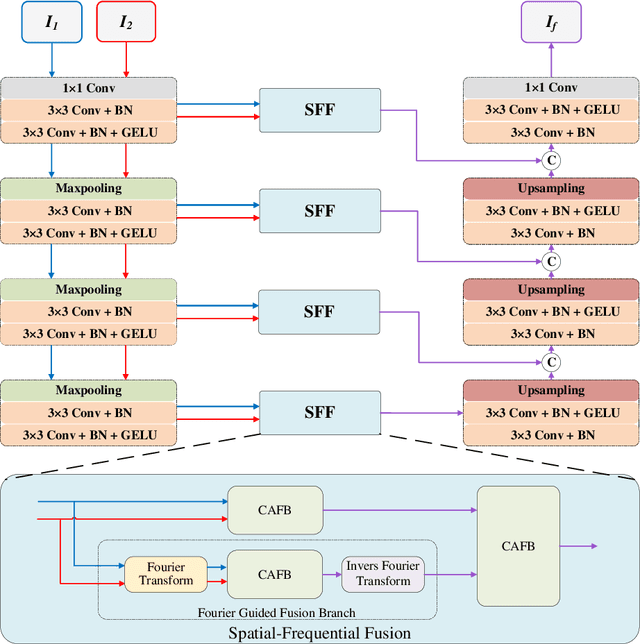
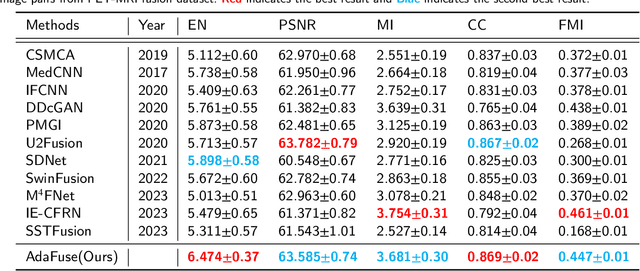
Multi-modal medical image fusion is essential for the precise clinical diagnosis and surgical navigation since it can merge the complementary information in multi-modalities into a single image. The quality of the fused image depends on the extracted single modality features as well as the fusion rules for multi-modal information. Existing deep learning-based fusion methods can fully exploit the semantic features of each modality, they cannot distinguish the effective low and high frequency information of each modality and fuse them adaptively. To address this issue, we propose AdaFuse, in which multimodal image information is fused adaptively through frequency-guided attention mechanism based on Fourier transform. Specifically, we propose the cross-attention fusion (CAF) block, which adaptively fuses features of two modalities in the spatial and frequency domains by exchanging key and query values, and then calculates the cross-attention scores between the spatial and frequency features to further guide the spatial-frequential information fusion. The CAF block enhances the high-frequency features of the different modalities so that the details in the fused images can be retained. Moreover, we design a novel loss function composed of structure loss and content loss to preserve both low and high frequency information. Extensive comparison experiments on several datasets demonstrate that the proposed method outperforms state-of-the-art methods in terms of both visual quality and quantitative metrics. The ablation experiments also validate the effectiveness of the proposed loss and fusion strategy. Our code is publicly available at https://github.com/xianming-gu/AdaFuse.
DREAM+: Efficient Dataset Distillation by Bidirectional Representative Matching
Oct 23, 2023Dataset distillation plays a crucial role in creating compact datasets with similar training performance compared with original large-scale ones. This is essential for addressing the challenges of data storage and training costs. Prevalent methods facilitate knowledge transfer by matching the gradients, embedding distributions, or training trajectories of synthetic images with those of the sampled original images. Although there are various matching objectives, currently the strategy for selecting original images is limited to naive random sampling. We argue that random sampling overlooks the evenness of the selected sample distribution, which may result in noisy or biased matching targets. Besides, the sample diversity is also not constrained by random sampling. Additionally, current methods predominantly focus on single-dimensional matching, where information is not fully utilized. To address these challenges, we propose a novel matching strategy called Dataset Distillation by Bidirectional REpresentAtive Matching (DREAM+), which selects representative original images for bidirectional matching. DREAM+ is applicable to a variety of mainstream dataset distillation frameworks and significantly reduces the number of distillation iterations by more than 15 times without affecting performance. Given sufficient training time, DREAM+ can further improve the performance and achieve state-of-the-art results. We have released the code at github.com/NUS-HPC-AI-Lab/DREAM+.
Leveraging Deep Learning for Abstractive Code Summarization of Unofficial Documentation
Oct 23, 2023Usually, programming languages have official documentation to guide developers with APIs, methods, and classes. However, researchers identified insufficient or inadequate documentation examples and flaws with the API's complex structure as barriers to learning an API. As a result, developers may consult other sources (StackOverflow, GitHub, etc.) to learn more about an API. Recent research studies have shown that unofficial documentation is a valuable source of information for generating code summaries. We, therefore, have been motivated to leverage such a type of documentation along with deep learning techniques towards generating high-quality summaries for APIs discussed in informal documentation. This paper proposes an automatic approach using the BART algorithm, a state-of-the-art transformer model, to generate summaries for APIs discussed in StackOverflow. We built an oracle of human-generated summaries to evaluate our approach against it using ROUGE and BLEU metrics which are the most widely used evaluation metrics in text summarization. Furthermore, we evaluated our summaries empirically against a previous work in terms of quality. Our findings demonstrate that using deep learning algorithms can improve summaries' quality and outperform the previous work by an average of %57 for Precision, %66 for Recall, and %61 for F-measure, and it runs 4.4 times faster.
When Language Models Fall in Love: Animacy Processing in Transformer Language Models
Oct 23, 2023
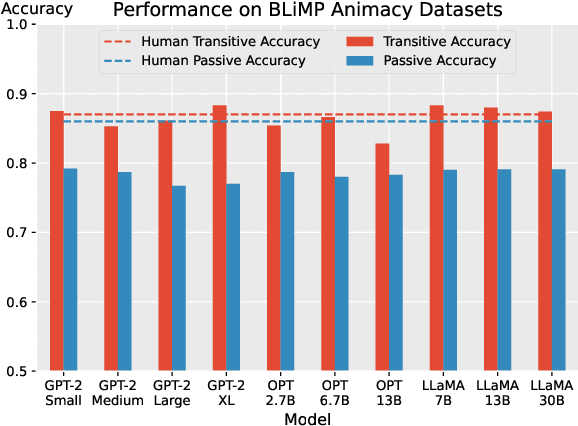

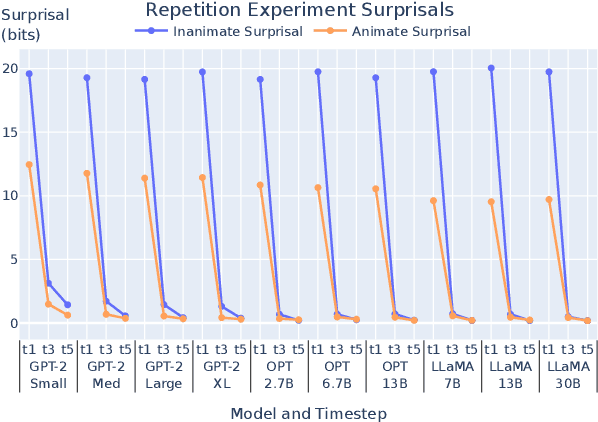
Animacy - whether an entity is alive and sentient - is fundamental to cognitive processing, impacting areas such as memory, vision, and language. However, animacy is not always expressed directly in language: in English it often manifests indirectly, in the form of selectional constraints on verbs and adjectives. This poses a potential issue for transformer language models (LMs): they often train only on text, and thus lack access to extralinguistic information from which humans learn about animacy. We ask: how does this impact LMs' animacy processing - do they still behave as humans do? We answer this question using open-source LMs. Like previous studies, we find that LMs behave much like humans when presented with entities whose animacy is typical. However, we also show that even when presented with stories about atypically animate entities, such as a peanut in love, LMs adapt: they treat these entities as animate, though they do not adapt as well as humans. Even when the context indicating atypical animacy is very short, LMs pick up on subtle clues and change their behavior. We conclude that despite the limited signal through which LMs can learn about animacy, they are indeed sensitive to the relevant lexical semantic nuances available in English.
Rethinking SIGN Training: Provable Nonconvex Acceleration without First- and Second-Order Gradient Lipschitz
Oct 23, 2023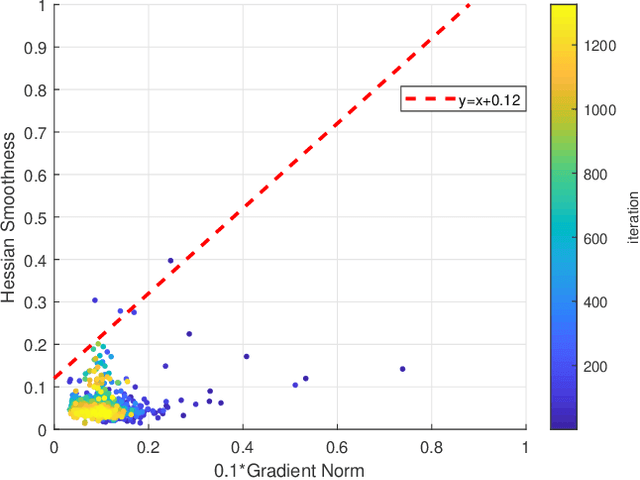
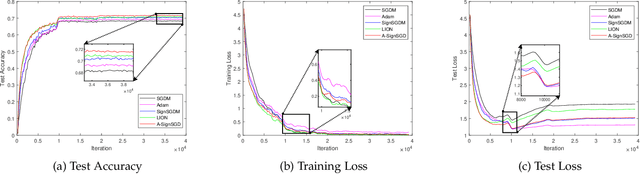
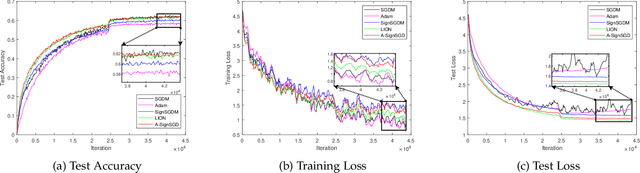
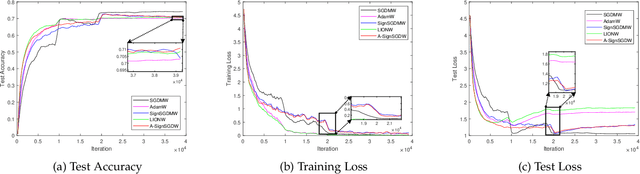
Sign-based stochastic methods have gained attention due to their ability to achieve robust performance despite using only the sign information for parameter updates. However, the current convergence analysis of sign-based methods relies on the strong assumptions of first-order gradient Lipschitz and second-order gradient Lipschitz, which may not hold in practical tasks like deep neural network training that involve high non-smoothness. In this paper, we revisit sign-based methods and analyze their convergence under more realistic assumptions of first- and second-order smoothness. We first establish the convergence of the sign-based method under weak first-order Lipschitz. Motivated by the weak first-order Lipschitz, we propose a relaxed second-order condition that still allows for nonconvex acceleration in sign-based methods. Based on our theoretical results, we gain insights into the computational advantages of the recently developed LION algorithm. In distributed settings, we prove that this nonconvex acceleration persists with linear speedup in the number of nodes, when utilizing fast communication compression gossip protocols. The novelty of our theoretical results lies in that they are derived under much weaker assumptions, thereby expanding the provable applicability of sign-based algorithms to a wider range of problems.
An Efficient Imbalance-Aware Federated Learning Approach for Wearable Healthcare with Autoregressive Ratio Observation
Oct 23, 2023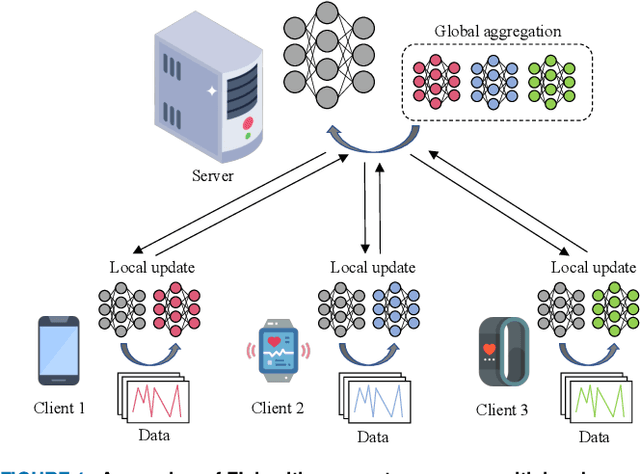
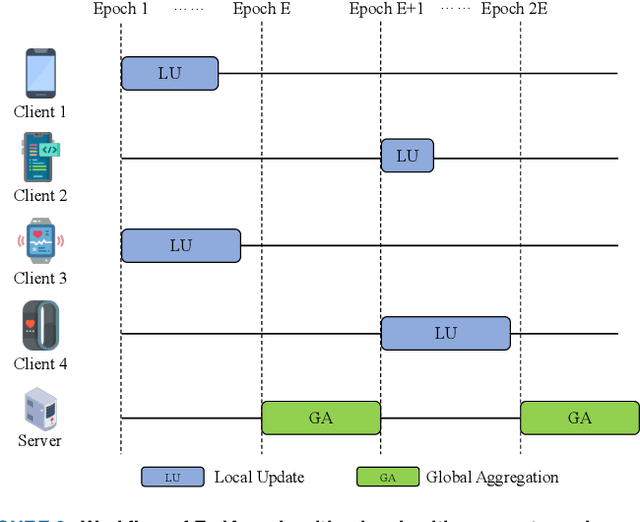
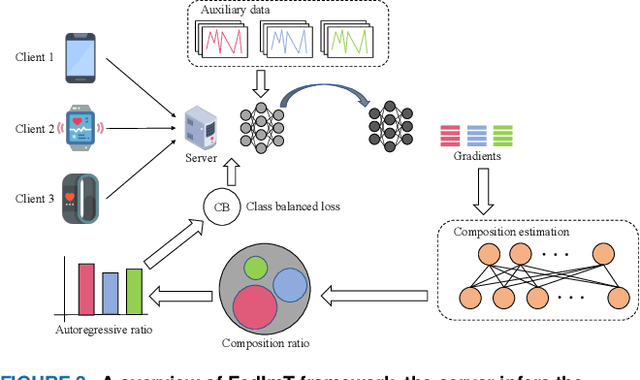
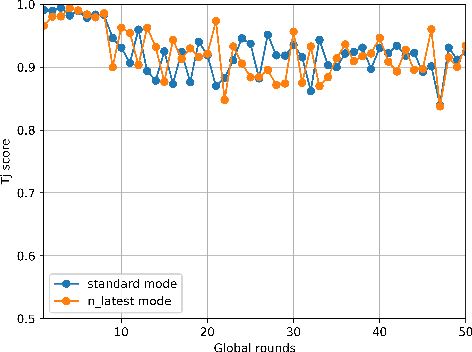
Widely available healthcare services are now getting popular because of advancements in wearable sensing techniques and mobile edge computing. People's health information is collected by edge devices such as smartphones and wearable bands for further analysis on servers, then send back suggestions and alerts for abnormal conditions. The recent emergence of federated learning allows users to train private data on local devices while updating models collaboratively. However, the heterogeneous distribution of the health condition data may lead to significant risks to model performance due to class imbalance. Meanwhile, as FL training is powered by sharing gradients only with the server, training data is almost inaccessible. The conventional solutions to class imbalance do not work for federated learning. In this work, we propose a new federated learning framework FedImT, dedicated to addressing the challenges of class imbalance in federated learning scenarios. FedImT contains an online scheme that can estimate the data composition during each round of aggregation, then introduces a self-attenuating iterative equivalent to track variations of multiple estimations and promptly tweak the balance of the loss computing for minority classes. Experiments demonstrate the effectiveness of FedImT in solving the imbalance problem without extra energy consumption and avoiding privacy risks.
Causal Inference Using LLM-Guided Discovery
Oct 23, 2023At the core of causal inference lies the challenge of determining reliable causal graphs solely based on observational data. Since the well-known backdoor criterion depends on the graph, any errors in the graph can propagate downstream to effect inference. In this work, we initially show that complete graph information is not necessary for causal effect inference; the topological order over graph variables (causal order) alone suffices. Further, given a node pair, causal order is easier to elicit from domain experts compared to graph edges since determining the existence of an edge can depend extensively on other variables. Interestingly, we find that the same principle holds for Large Language Models (LLMs) such as GPT-3.5-turbo and GPT-4, motivating an automated method to obtain causal order (and hence causal effect) with LLMs acting as virtual domain experts. To this end, we employ different prompting strategies and contextual cues to propose a robust technique of obtaining causal order from LLMs. Acknowledging LLMs' limitations, we also study possible techniques to integrate LLMs with established causal discovery algorithms, including constraint-based and score-based methods, to enhance their performance. Extensive experiments demonstrate that our approach significantly improves causal ordering accuracy as compared to discovery algorithms, highlighting the potential of LLMs to enhance causal inference across diverse fields.
Understanding and Modeling the Effects of Task and Context on Drivers' Gaze Allocation
Oct 23, 2023
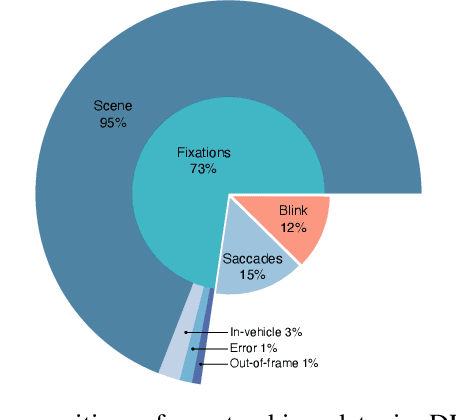

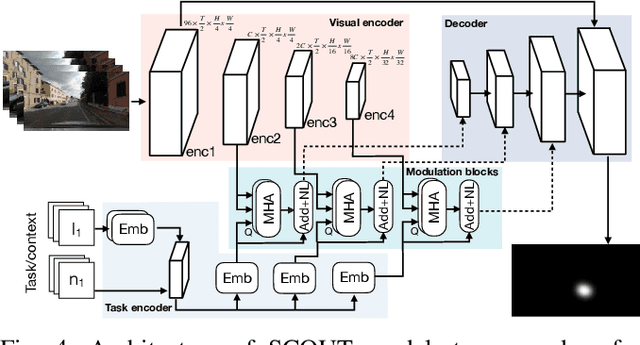
Understanding what drivers look at is important for many applications, including driver training, monitoring, and assistance, as well as self-driving. Traditionally, factors affecting human visual attention have been divided into bottom-up (involuntary attraction to salient regions) and top-down (task- and context-driven). Although both play a role in drivers' gaze allocation, most of the existing modeling approaches apply techniques developed for bottom-up saliency and do not consider task and context influences explicitly. Likewise, common driving attention benchmarks lack relevant task and context annotations. Therefore, to enable analysis and modeling of these factors for drivers' gaze prediction, we propose the following: 1) address some shortcomings of the popular DR(eye)VE dataset and extend it with per-frame annotations for driving task and context; 2) benchmark a number of baseline and SOTA models for saliency and driver gaze prediction and analyze them w.r.t. the new annotations; and finally, 3) a novel model that modulates drivers' gaze prediction with explicit action and context information, and as a result significantly improves SOTA performance on DR(eye)VE overall (by 24\% KLD and 89\% NSS) and on a subset of action and safety-critical intersection scenarios (by 10--30\% KLD). Extended annotations, code for model and evaluation will be made publicly available.
Spiking mode-based neural networks
Oct 23, 2023Spiking neural networks play an important role in brain-like neuromorphic computations and in studying working mechanisms of neural circuits. One drawback of training a large scale spiking neural network is that an expensive cost of updating all weights is required. Furthermore, after training, all information related to the computational task is hidden into the weight matrix, prohibiting us from a transparent understanding of circuit mechanisms. Therefore, in this work, we address these challenges by proposing a spiking mode-based training protocol. The first advantage is that the weight is interpreted by input and output modes and their associated scores characterizing importance of each decomposition term. The number of modes is thus adjustable, allowing more degrees of freedom for modeling the experimental data. This reduces a sizable training cost because of significantly reduced space complexity for learning. The second advantage is that one can project the high dimensional neural activity in the ambient space onto the mode space which is typically of a low dimension, e.g., a few modes are sufficient to capture the shape of the underlying neural manifolds. We analyze our framework in two computational tasks -- digit classification and selective sensory integration tasks. Our work thus derives a mode-based learning rule for spiking neural networks.
"Why Should I Review This Paper?" Unifying Semantic, Topic, and Citation Factors for Paper-Reviewer Matching
Oct 23, 2023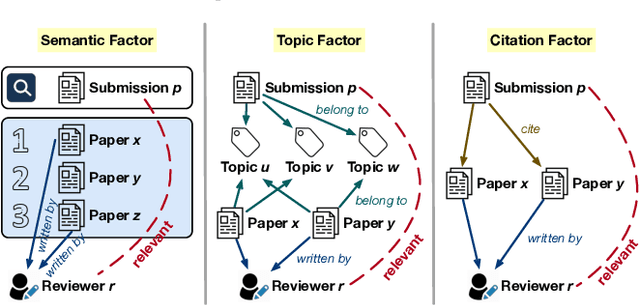
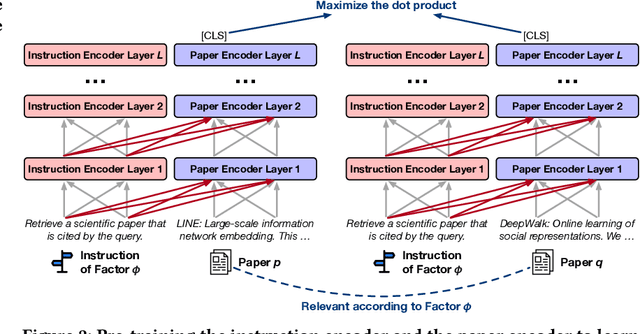
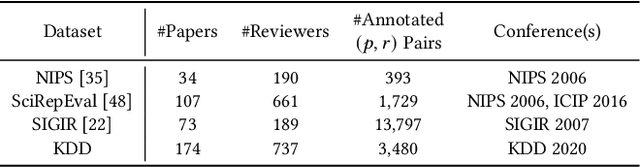
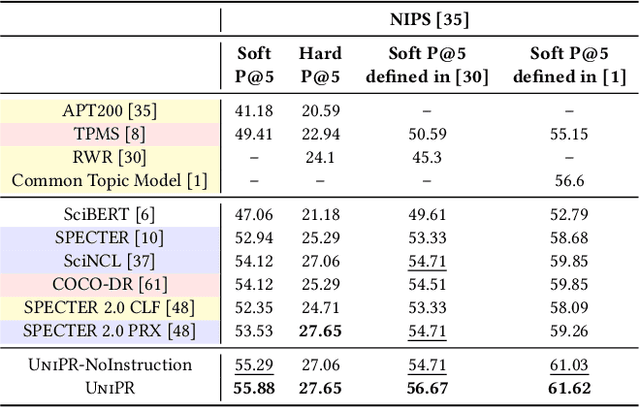
As many academic conferences are overwhelmed by a rapidly increasing number of paper submissions, automatically finding appropriate reviewers for each submission becomes a more urgent need than ever. Various factors have been considered by previous attempts on this task to measure the expertise relevance between a paper and a reviewer, including whether the paper is semantically close to, shares topics with, and cites previous papers of the reviewer. However, the majority of previous studies take only one of these factors into account, leading to an incomprehensive evaluation of paper-reviewer relevance. To bridge this gap, in this paper, we propose a unified model for paper-reviewer matching that jointly captures semantic, topic, and citation factors. In the unified model, a contextualized language model backbone is shared by all factors to learn common knowledge, while instruction tuning is introduced to characterize the uniqueness of each factor by producing factor-aware paper embeddings. Experiments on four datasets (one of which is newly contributed by us) across different fields, including machine learning, computer vision, information retrieval, and data mining, consistently validate the effectiveness of our proposed UniPR model in comparison with state-of-the-art paper-reviewer matching methods and scientific pre-trained language models.