 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
A Unified Generative Framework based on Prompt Learning for Various Information Extraction Tasks
Sep 23, 2022
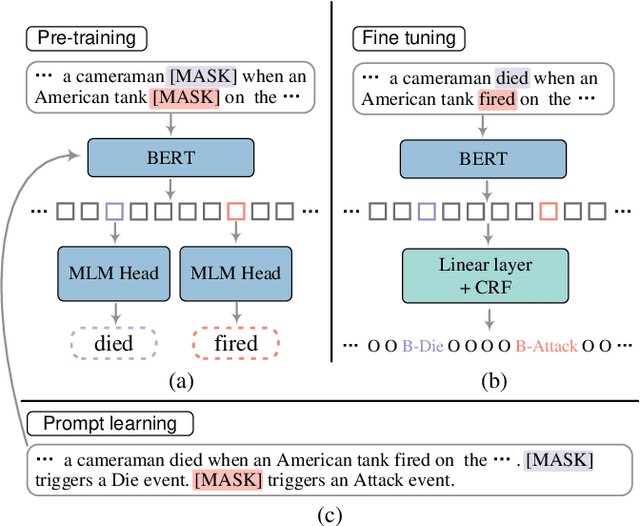
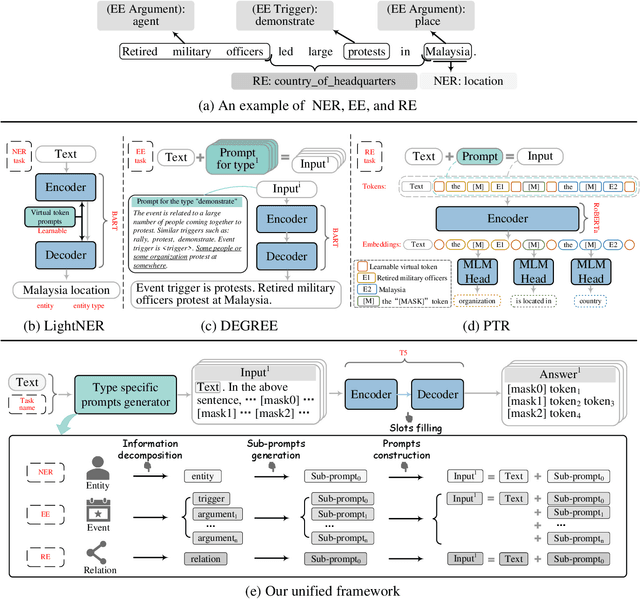
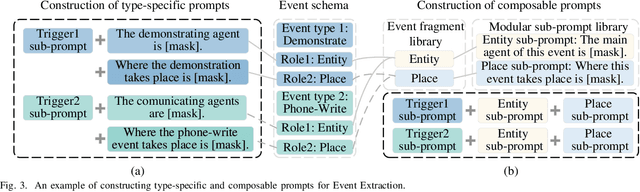
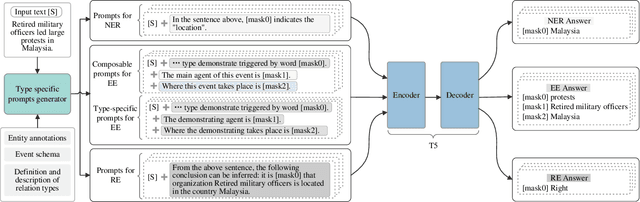
Prompt learning is an effective paradigm that bridges gaps between the pre-training tasks and the corresponding downstream applications. Approaches based on this paradigm have achieved great transcendent results in various applications. However, it still needs to be answered how to design a unified framework based on the prompt learning paradigm for various information extraction tasks. In this paper, we propose a novel composable prompt-based generative framework, which could be applied to a wide range of tasks in the field of Information Extraction. Specifically, we reformulate information extraction tasks into the form of filling slots in pre-designed type-specific prompts, which consist of one or multiple sub-prompts. A strategy of constructing composable prompts is proposed to enhance the generalization ability to extract events in data-scarce scenarios. Furthermore, to fit this framework, we transform Relation Extraction into the task of determining semantic consistency in prompts. The experimental results demonstrate that our approach surpasses compared baselines on real-world datasets in data-abundant and data-scarce scenarios. Further analysis of the proposed framework is presented, as well as numerical experiments conducted to investigate impact factors of performance on various tasks.
Similarity-based Memory Enhanced Joint Entity and Relation Extraction
Jul 14, 2023Document-level joint entity and relation extraction is a challenging information extraction problem that requires a unified approach where a single neural network performs four sub-tasks: mention detection, coreference resolution, entity classification, and relation extraction. Existing methods often utilize a sequential multi-task learning approach, in which the arbitral decomposition causes the current task to depend only on the previous one, missing the possible existence of the more complex relationships between them. In this paper, we present a multi-task learning framework with bidirectional memory-like dependency between tasks to address those drawbacks and perform the joint problem more accurately. Our empirical studies show that the proposed approach outperforms the existing methods and achieves state-of-the-art results on the BioCreative V CDR corpus.
UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition
Aug 07, 2023


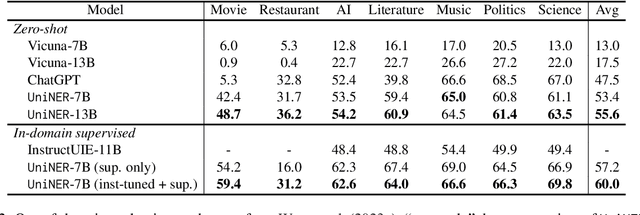
Large language models (LLMs) have demonstrated remarkable generalizability, such as understanding arbitrary entities and relations. Instruction tuning has proven effective for distilling LLMs into more cost-efficient models such as Alpaca and Vicuna. Yet such student models still trail the original LLMs by large margins in downstream applications. In this paper, we explore targeted distillation with mission-focused instruction tuning to train student models that can excel in a broad application class such as open information extraction. Using named entity recognition (NER) for case study, we show how ChatGPT can be distilled into much smaller UniversalNER models for open NER. For evaluation, we assemble the largest NER benchmark to date, comprising 43 datasets across 9 diverse domains such as biomedicine, programming, social media, law, finance. Without using any direct supervision, UniversalNER attains remarkable NER accuracy across tens of thousands of entity types, outperforming general instruction-tuned models such as Alpaca and Vicuna by over 30 absolute F1 points in average. With a tiny fraction of parameters, UniversalNER not only acquires ChatGPT's capability in recognizing arbitrary entity types, but also outperforms its NER accuracy by 7-9 absolute F1 points in average. Remarkably, UniversalNER even outperforms by a large margin state-of-the-art multi-task instruction-tuned systems such as InstructUIE, which uses supervised NER examples. We also conduct thorough ablation studies to assess the impact of various components in our distillation approach. We will release the distillation recipe, data, and UniversalNER models to facilitate future research on targeted distillation.
Social Media Fashion Knowledge Extraction as Captioning
Sep 28, 2023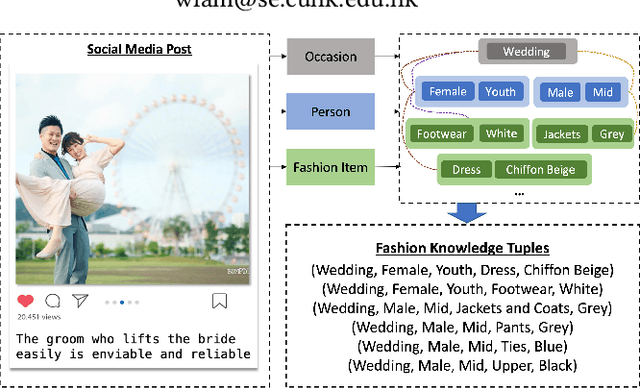
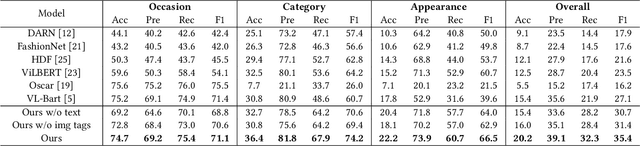

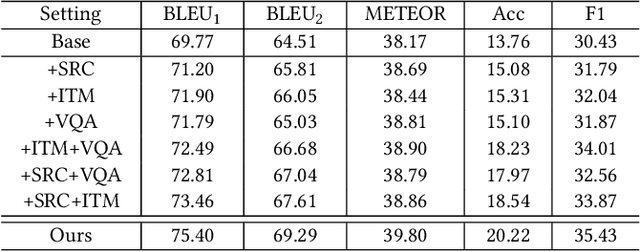
Social media plays a significant role in boosting the fashion industry, where a massive amount of fashion-related posts are generated every day. In order to obtain the rich fashion information from the posts, we study the task of social media fashion knowledge extraction. Fashion knowledge, which typically consists of the occasion, person attributes, and fashion item information, can be effectively represented as a set of tuples. Most previous studies on fashion knowledge extraction are based on the fashion product images without considering the rich text information in social media posts. Existing work on fashion knowledge extraction in social media is classification-based and requires to manually determine a set of fashion knowledge categories in advance. In our work, we propose to cast the task as a captioning problem to capture the interplay of the multimodal post information. Specifically, we transform the fashion knowledge tuples into a natural language caption with a sentence transformation method. Our framework then aims to generate the sentence-based fashion knowledge directly from the social media post. Inspired by the big success of pre-trained models, we build our model based on a multimodal pre-trained generative model and design several auxiliary tasks for enhancing the knowledge extraction. Since there is no existing dataset which can be directly borrowed to our task, we introduce a dataset consisting of social media posts with manual fashion knowledge annotation. Extensive experiments are conducted to demonstrate the effectiveness of our model.
Cross-domain Variational Capsules for Information Extraction
Oct 13, 2022In this paper, we present a characteristic extraction algorithm and the Multi-domain Image Characteristics Dataset of characteristic-tagged images to simulate the way a human brain classifies cross-domain information and generates insight. The intent was to identify prominent characteristics in data and use this identification mechanism to auto-generate insight from data in other unseen domains. An information extraction algorithm is proposed which is a combination of Variational Autoencoders (VAEs) and Capsule Networks. Capsule Networks are used to decompose images into their individual features and VAEs are used to explore variations on these decomposed features. Thus, making the model robust in recognizing characteristics from variations of the data. A noteworthy point is that the algorithm uses efficient hierarchical decoding of data which helps in richer output interpretation. Noticing a dearth in the number of datasets that contain visible characteristics in images belonging to various domains, the Multi-domain Image Characteristics Dataset was created and made publicly available. It consists of thousands of images across three domains. This dataset was created with the intent of introducing a new benchmark for fine-grained characteristic recognition tasks in the future.
* This paper was originally written in 2020
Lung Diseases Image Segmentation using Faster R-CNNs
Sep 10, 2023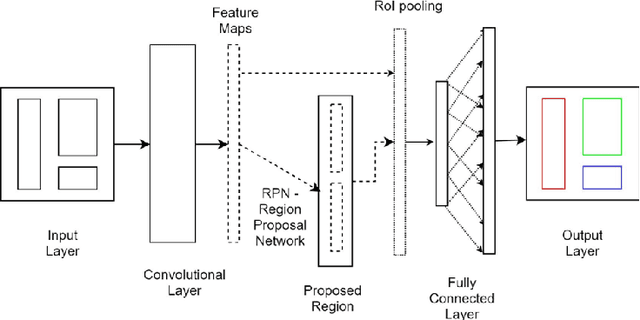
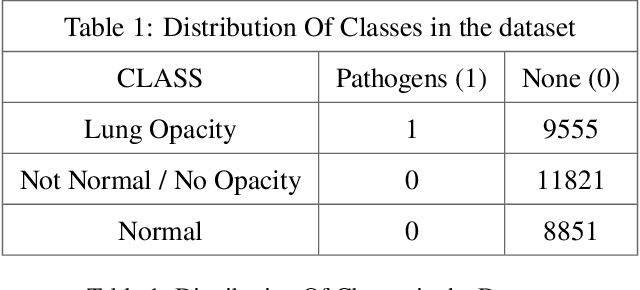
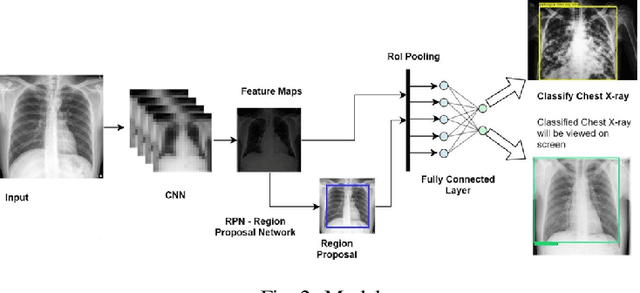
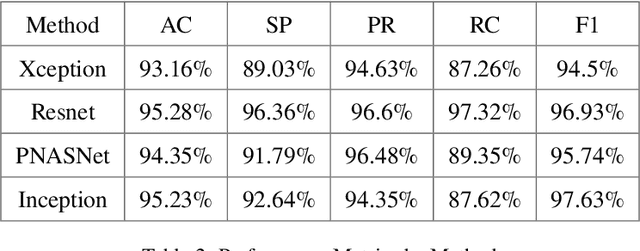
Lung diseases are a leading cause of child mortality in the developing world, with India accounting for approximately half of global pneumonia deaths (370,000) in 2016. Timely diagnosis is crucial for reducing mortality rates. This paper introduces a low-density neural network structure to mitigate topological challenges in deep networks. The network incorporates parameters into a feature pyramid, enhancing data extraction and minimizing information loss. Soft Non-Maximal Suppression optimizes regional proposals generated by the Region Proposal Network. The study evaluates the model on chest X-ray images, computing a confusion matrix to determine accuracy, precision, sensitivity, and specificity. We analyze loss functions, highlighting their trends during training. The regional proposal loss and classification loss assess model performance during training and classification phases. This paper analysis lung disease detection and neural network structures.
FormNetV2: Multimodal Graph Contrastive Learning for Form Document Information Extraction
May 04, 2023
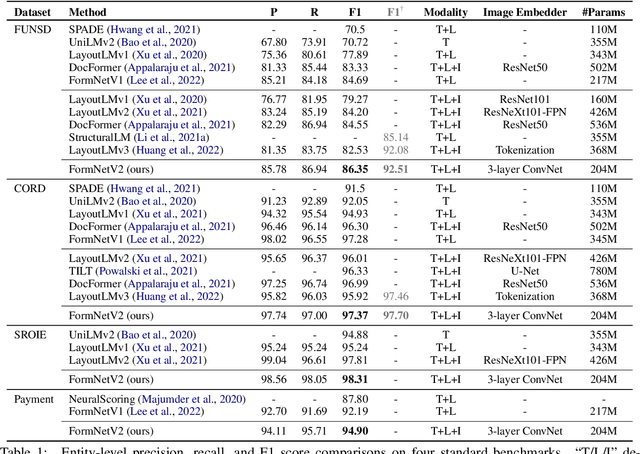
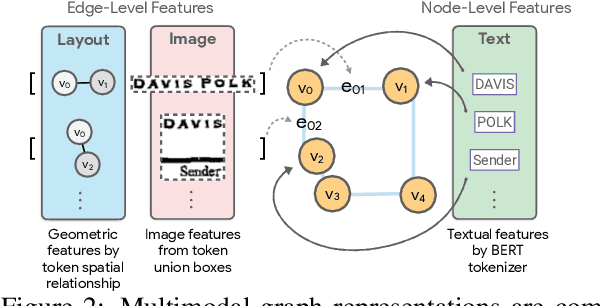
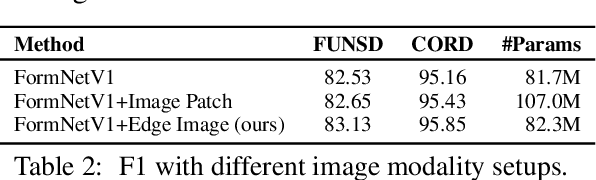
The recent advent of self-supervised pre-training techniques has led to a surge in the use of multimodal learning in form document understanding. However, existing approaches that extend the mask language modeling to other modalities require careful multi-task tuning, complex reconstruction target designs, or additional pre-training data. In FormNetV2, we introduce a centralized multimodal graph contrastive learning strategy to unify self-supervised pre-training for all modalities in one loss. The graph contrastive objective maximizes the agreement of multimodal representations, providing a natural interplay for all modalities without special customization. In addition, we extract image features within the bounding box that joins a pair of tokens connected by a graph edge, capturing more targeted visual cues without loading a sophisticated and separately pre-trained image embedder. FormNetV2 establishes new state-of-the-art performance on FUNSD, CORD, SROIE and Payment benchmarks with a more compact model size.
MATrIX -- Modality-Aware Transformer for Information eXtraction
May 17, 2022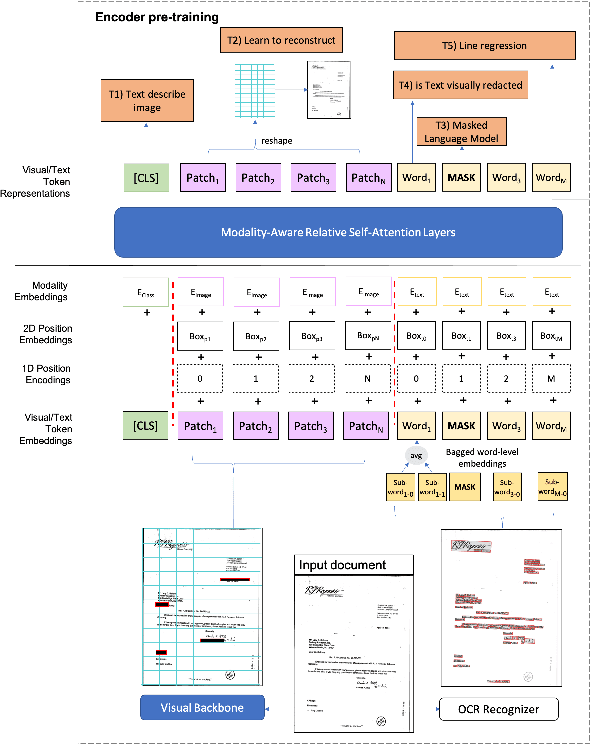
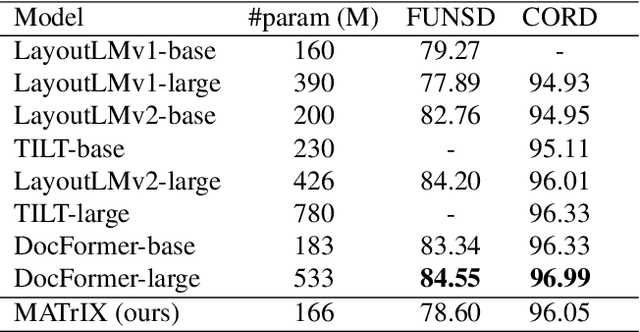

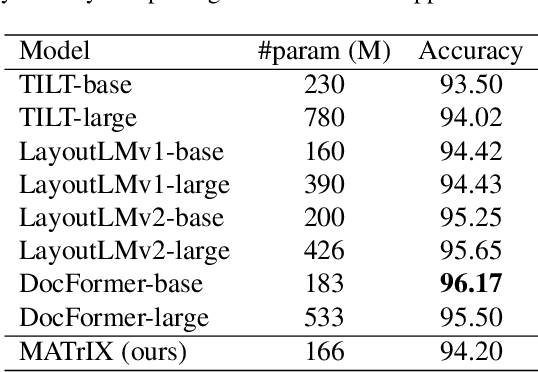
We present MATrIX - a Modality-Aware Transformer for Information eXtraction in the Visual Document Understanding (VDU) domain. VDU covers information extraction from visually rich documents such as forms, invoices, receipts, tables, graphs, presentations, or advertisements. In these, text semantics and visual information supplement each other to provide a global understanding of the document. MATrIX is pre-trained in an unsupervised way with specifically designed tasks that require the use of multi-modal information (spatial, visual, or textual). We consider the spatial and text modalities all at once in a single token set. To make the attention more flexible, we use a learned modality-aware relative bias in the attention mechanism to modulate the attention between the tokens of different modalities. We evaluate MATrIX on 3 different datasets each with strong baselines.
A Few-shot Approach to Resume Information Extraction via Prompts
Sep 20, 2022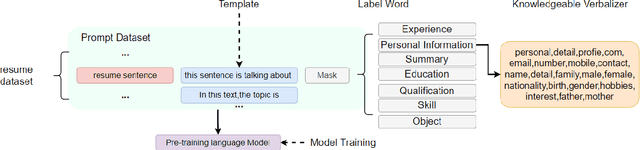

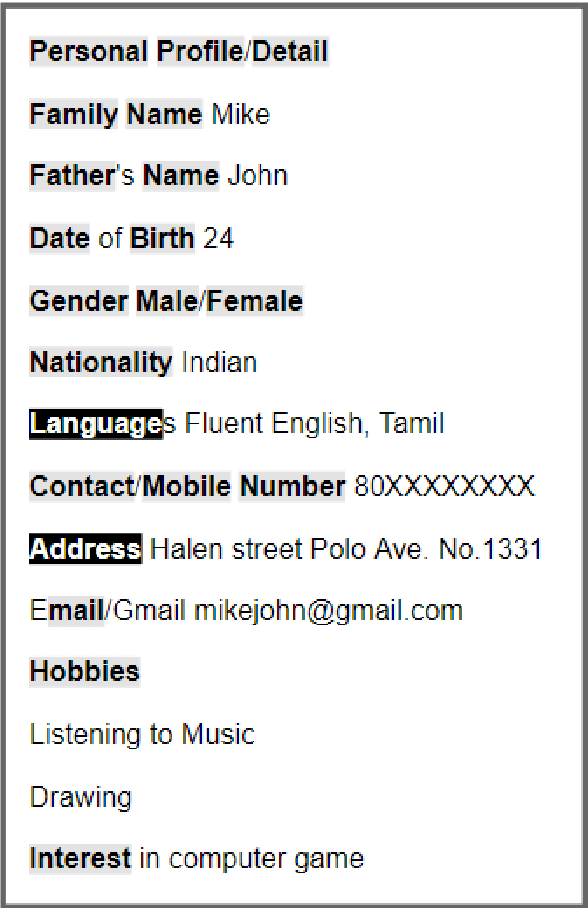

Prompt learning has been shown to achieve near-Fine-tune performance in most text classification tasks with very few training examples. It is advantageous for NLP tasks where samples are scarce. In this paper, we attempt to apply it to a practical scenario, i.e resume information extraction, and to enhance the existing method to make it more applicable to the resume information extraction task. In particular, we created multiple sets of manual templates and verbalizers based on the textual characteristics of resumes. In addition, we compared the performance of Masked Language Model (MLM) pre-training language models (PLMs) and Seq2Seq PLMs on this task. Furthermore, we improve the design method of verbalizer for Knowledgeable Prompt-tuning in order to provide a example for the design of Prompt templates and verbalizer for other application-based NLP tasks. In this case, we propose the concept of Manual Knowledgeable Verbalizer(MKV). A rule for constructing the Knowledgeable Verbalizer corresponding to the application scenario. Experiments demonstrate that templates and verbalizers designed based on our rules are more effective and robust than existing manual templates and automatically generated prompt methods. It is established that the currently available automatic prompt methods cannot compete with manually designed prompt templates for some realistic task scenarios. The results of the final confusion matrix indicate that our proposed MKV significantly resolved the sample imbalance issue.
Convolution and Attention Mixer for Synthetic Aperture Radar Image Change Detection
Sep 21, 2023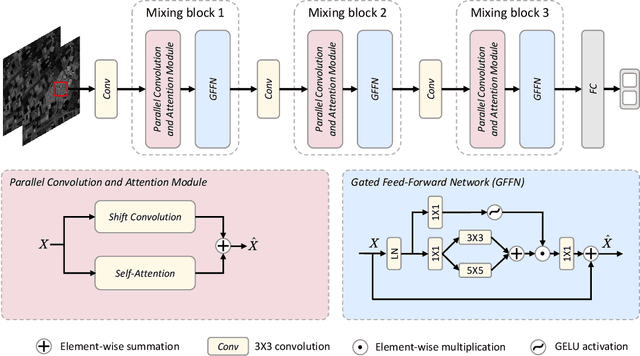
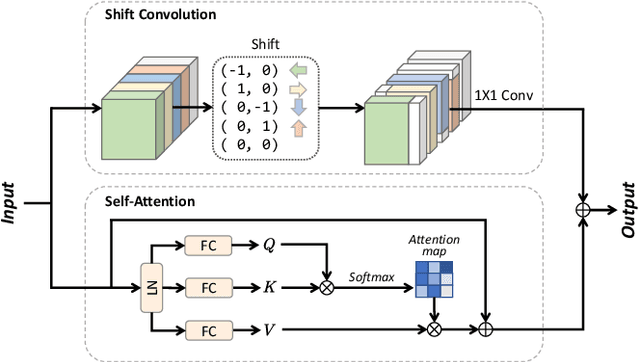
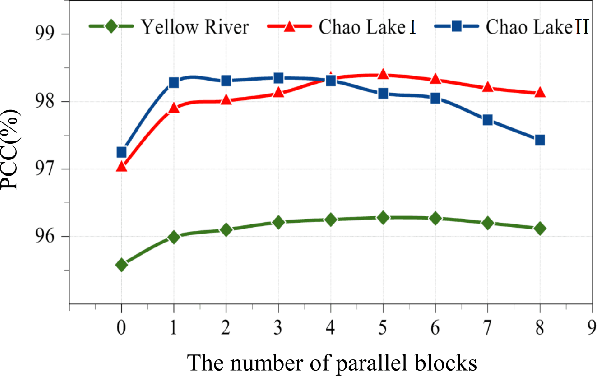
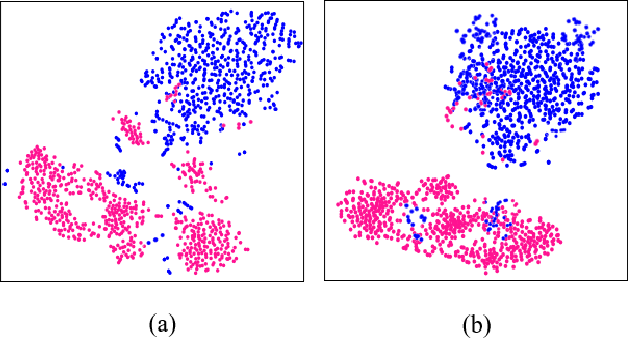
Synthetic aperture radar (SAR) image change detection is a critical task and has received increasing attentions in the remote sensing community. However, existing SAR change detection methods are mainly based on convolutional neural networks (CNNs), with limited consideration of global attention mechanism. In this letter, we explore Transformer-like architecture for SAR change detection to incorporate global attention. To this end, we propose a convolution and attention mixer (CAMixer). First, to compensate the inductive bias for Transformer, we combine self-attention with shift convolution in a parallel way. The parallel design effectively captures the global semantic information via the self-attention and performs local feature extraction through shift convolution simultaneously. Second, we adopt a gating mechanism in the feed-forward network to enhance the non-linear feature transformation. The gating mechanism is formulated as the element-wise multiplication of two parallel linear layers. Important features can be highlighted, leading to high-quality representations against speckle noise. Extensive experiments conducted on three SAR datasets verify the superior performance of the proposed CAMixer. The source codes will be publicly available at https://github.com/summitgao/CAMixer .