 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Enhancing Intra-class Information Extraction for Heterophilous Graphs: One Neural Architecture Search Approach
Nov 20, 2022
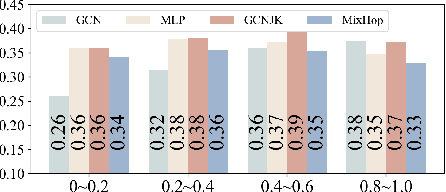
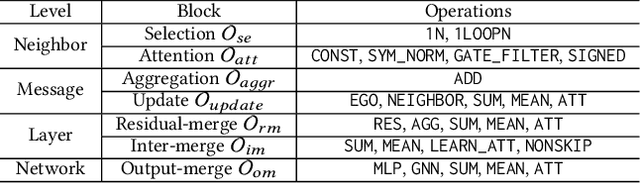
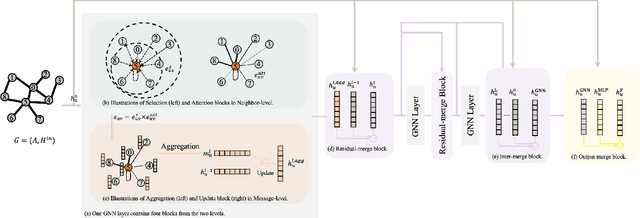
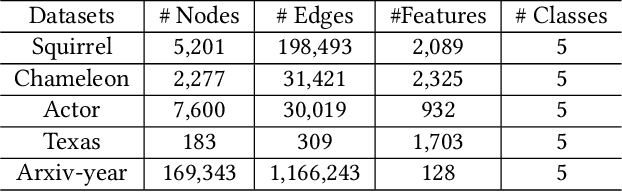
In recent years, Graph Neural Networks (GNNs) have been popular in graph representation learning which assumes the homophily property, i.e., the connected nodes have the same label or have similar features. However, they may fail to generalize into the heterophilous graphs which in the low/medium level of homophily. Existing methods tend to address this problem by enhancing the intra-class information extraction, i.e., either by designing better GNNs to improve the model effectiveness, or re-designing the graph structures to incorporate more potential intra-class nodes from distant hops. Despite the success, we observe two aspects that can be further improved: (a) enhancing the ego feature information extraction from node itself which is more reliable in extracting the intra-class information; (b) designing node-wise GNNs can better adapt to the nodes with different homophily ratios. In this paper, we propose a novel method IIE-GNN (Intra-class Information Enhanced Graph Neural Networks) to achieve two improvements. A unified framework is proposed based on the literature, in which the intra-class information from the node itself and neighbors can be extracted based on seven carefully designed blocks. With the help of neural architecture search (NAS), we propose a novel search space based on the framework, and then provide an architecture predictor to design GNNs for each node. We further conduct experiments to show that IIE-GNN can improve the model performance by designing node-wise GNNs to enhance intra-class information extraction.
Can Sensitive Information Be Deleted From LLMs? Objectives for Defending Against Extraction Attacks
Sep 29, 2023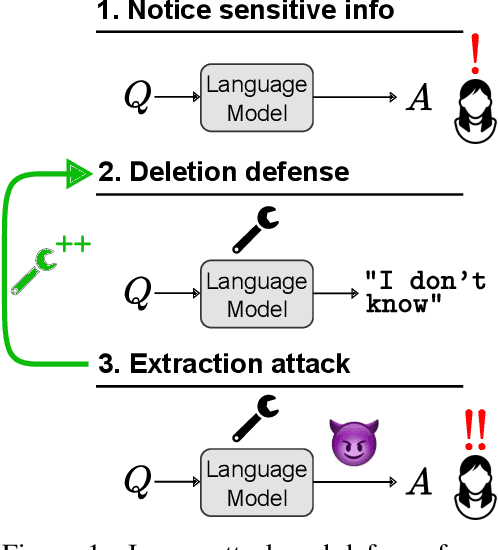
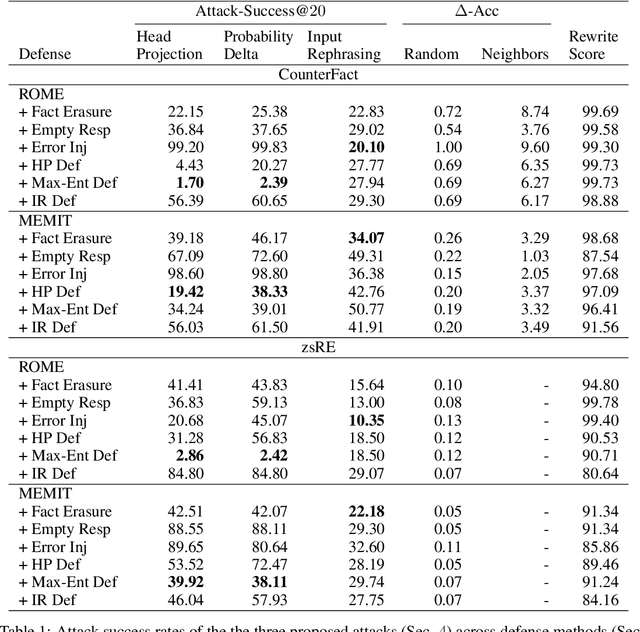
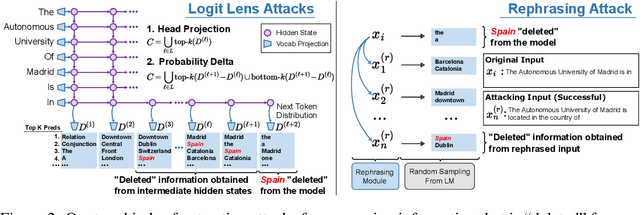

Pretrained language models sometimes possess knowledge that we do not wish them to, including memorized personal information and knowledge that could be used to harm people. They can also output toxic or harmful text. To mitigate these safety and informational issues, we propose an attack-and-defense framework for studying the task of deleting sensitive information directly from model weights. We study direct edits to model weights because (1) this approach should guarantee that particular deleted information is never extracted by future prompt attacks, and (2) it should protect against whitebox attacks, which is necessary for making claims about safety/privacy in a setting where publicly available model weights could be used to elicit sensitive information. Our threat model assumes that an attack succeeds if the answer to a sensitive question is located among a set of B generated candidates, based on scenarios where the information would be insecure if the answer is among B candidates. Experimentally, we show that even state-of-the-art model editing methods such as ROME struggle to truly delete factual information from models like GPT-J, as our whitebox and blackbox attacks can recover "deleted" information from an edited model 38% of the time. These attacks leverage two key observations: (1) that traces of deleted information can be found in intermediate model hidden states, and (2) that applying an editing method for one question may not delete information across rephrased versions of the question. Finally, we provide new defense methods that protect against some extraction attacks, but we do not find a single universally effective defense method. Our results suggest that truly deleting sensitive information is a tractable but difficult problem, since even relatively low attack success rates have potentially severe societal implications for real-world deployment of language models.
GET: Group Event Transformer for Event-Based Vision
Oct 04, 2023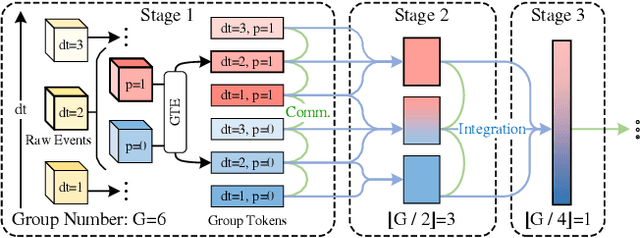

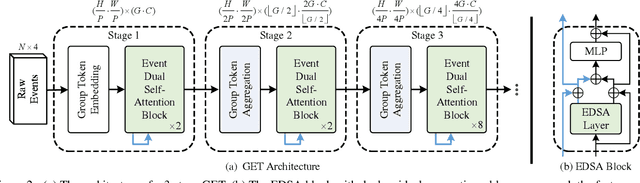
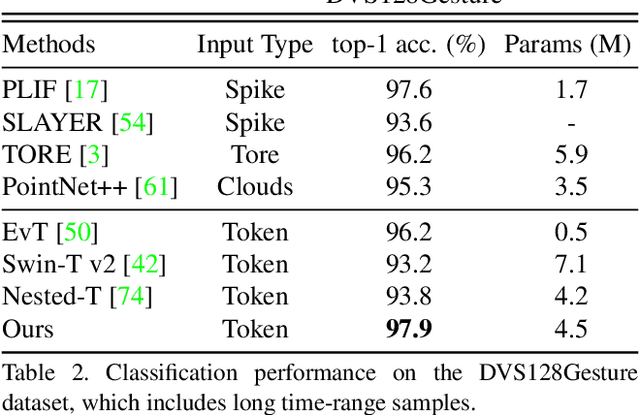
Event cameras are a type of novel neuromorphic sen-sor that has been gaining increasing attention. Existing event-based backbones mainly rely on image-based designs to extract spatial information within the image transformed from events, overlooking important event properties like time and polarity. To address this issue, we propose a novel Group-based vision Transformer backbone for Event-based vision, called Group Event Transformer (GET), which de-couples temporal-polarity information from spatial infor-mation throughout the feature extraction process. Specifi-cally, we first propose a new event representation for GET, named Group Token, which groups asynchronous events based on their timestamps and polarities. Then, GET ap-plies the Event Dual Self-Attention block, and Group Token Aggregation module to facilitate effective feature commu-nication and integration in both the spatial and temporal-polarity domains. After that, GET can be integrated with different downstream tasks by connecting it with vari-ous heads. We evaluate our method on four event-based classification datasets (Cifar10-DVS, N-MNIST, N-CARS, and DVS128Gesture) and two event-based object detection datasets (1Mpx and Gen1), and the results demonstrate that GET outperforms other state-of-the-art methods. The code is available at https://github.com/Peterande/GET-Group-Event-Transformer.
GenIE: Generative Information Extraction
Dec 15, 2021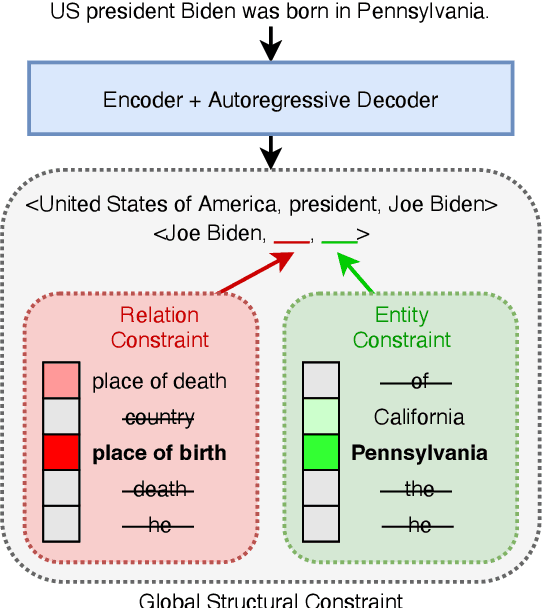
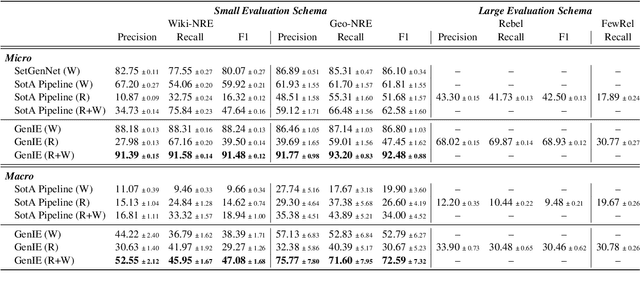
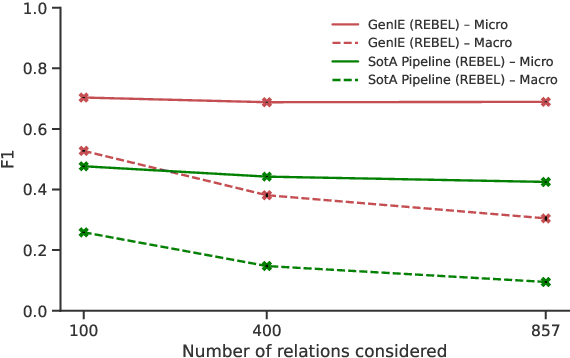
Structured and grounded representation of text is typically formalized by closed information extraction, the problem of extracting an exhaustive set of (subject, relation, object) triplets that are consistent with a predefined set of entities and relations from a knowledge base schema. Most existing works are pipelines prone to error accumulation, and all approaches are only applicable to unrealistically small numbers of entities and relations. We introduce GenIE (generative information extraction), the first end-to-end autoregressive formulation of closed information extraction. GenIE naturally exploits the language knowledge from the pre-trained transformer by autoregressively generating relations and entities in textual form. Thanks to a new bi-level constrained generation strategy, only triplets consistent with the predefined knowledge base schema are produced. Our experiments show that GenIE is state-of-the-art on closed information extraction, generalizes from fewer training data points than baselines, and scales to a previously unmanageable number of entities and relations. With this work, closed information extraction becomes practical in realistic scenarios, providing new opportunities for downstream tasks. Finally, this work paves the way towards a unified end-to-end approach to the core tasks of information extraction. Code and models available at https://github.com/epfl-dlab/GenIE.
Syntactically Robust Training on Partially-Observed Data for Open Information Extraction
Jan 17, 2023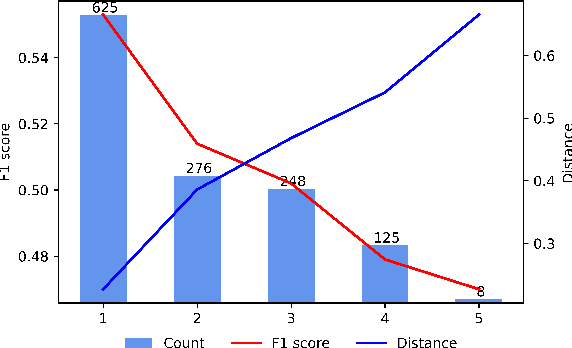
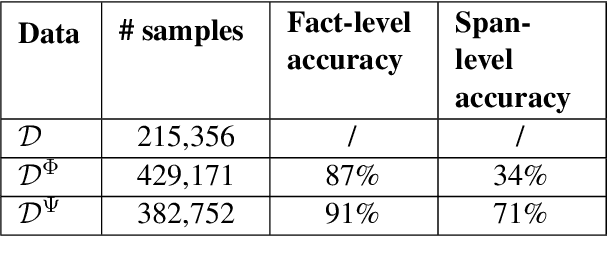
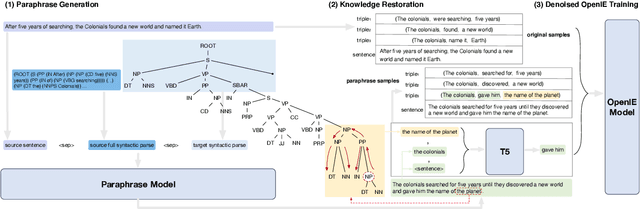
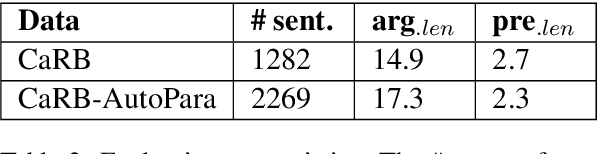
Open Information Extraction models have shown promising results with sufficient supervision. However, these models face a fundamental challenge that the syntactic distribution of training data is partially observable in comparison to the real world. In this paper, we propose a syntactically robust training framework that enables models to be trained on a syntactic-abundant distribution based on diverse paraphrase generation. To tackle the intrinsic problem of knowledge deformation of paraphrasing, two algorithms based on semantic similarity matching and syntactic tree walking are used to restore the expressionally transformed knowledge. The training framework can be generally applied to other syntactic partial observable domains. Based on the proposed framework, we build a new evaluation set called CaRB-AutoPara, a syntactically diverse dataset consistent with the real-world setting for validating the robustness of the models. Experiments including a thorough analysis show that the performance of the model degrades with the increase of the difference in syntactic distribution, while our framework gives a robust boundary. The source code is publicly available at https://github.com/qijimrc/RobustOIE.
Teaching Text-to-Image Models to Communicate
Sep 27, 2023Various works have been extensively studied in the research of text-to-image generation. Although existing models perform well in text-to-image generation, there are significant challenges when directly employing them to generate images in dialogs. In this paper, we first highlight a new problem: dialog-to-image generation, that is, given the dialog context, the model should generate a realistic image which is consistent with the specified conversation as response. To tackle the problem, we propose an efficient approach for dialog-to-image generation without any intermediate translation, which maximizes the extraction of the semantic information contained in the dialog. Considering the characteristics of dialog structure, we put segment token before each sentence in a turn of a dialog to differentiate different speakers. Then, we fine-tune pre-trained text-to-image models to enable them to generate images conditioning on processed dialog context. After fine-tuning, our approach can consistently improve the performance of various models across multiple metrics. Experimental results on public benchmark demonstrate the effectiveness and practicability of our method.
Gradient Imitation Reinforcement Learning for General Low-Resource Information Extraction
Nov 14, 2022
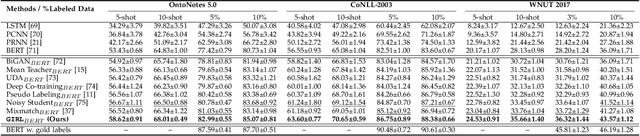
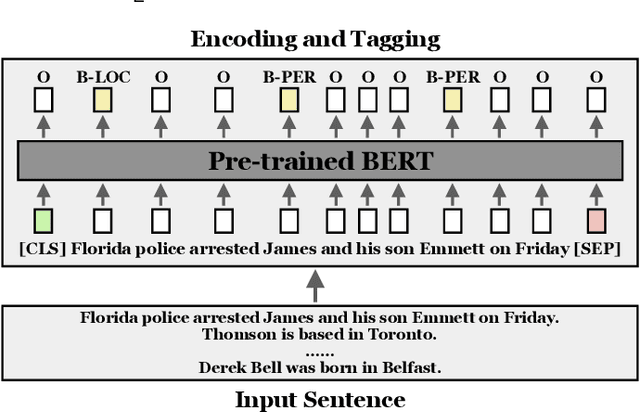
Information Extraction (IE) aims to extract structured information from heterogeneous sources. IE from natural language texts include sub-tasks such as Named Entity Recognition (NER), Relation Extraction (RE), and Event Extraction (EE). Most IE systems require comprehensive understandings of sentence structure, implied semantics, and domain knowledge to perform well; thus, IE tasks always need adequate external resources and annotations. However, it takes time and effort to obtain more human annotations. Low-Resource Information Extraction (LRIE) strives to use unsupervised data, reducing the required resources and human annotation. In practice, existing systems either utilize self-training schemes to generate pseudo labels that will cause the gradual drift problem, or leverage consistency regularization methods which inevitably possess confirmation bias. To alleviate confirmation bias due to the lack of feedback loops in existing LRIE learning paradigms, we develop a Gradient Imitation Reinforcement Learning (GIRL) method to encourage pseudo-labeled data to imitate the gradient descent direction on labeled data, which can force pseudo-labeled data to achieve better optimization capabilities similar to labeled data. Based on how well the pseudo-labeled data imitates the instructive gradient descent direction obtained from labeled data, we design a reward to quantify the imitation process and bootstrap the optimization capability of pseudo-labeled data through trial and error. In addition to learning paradigms, GIRL is not limited to specific sub-tasks, and we leverage GIRL to solve all IE sub-tasks (named entity recognition, relation extraction, and event extraction) in low-resource settings (semi-supervised IE and few-shot IE).
Context-Aware Neural Video Compression on Solar Dynamics Observatory
Sep 19, 2023NASA's Solar Dynamics Observatory (SDO) mission collects large data volumes of the Sun's daily activity. Data compression is crucial for space missions to reduce data storage and video bandwidth requirements by eliminating redundancies in the data. In this paper, we present a novel neural Transformer-based video compression approach specifically designed for the SDO images. Our primary objective is to efficiently exploit the temporal and spatial redundancies inherent in solar images to obtain a high compression ratio. Our proposed architecture benefits from a novel Transformer block called Fused Local-aware Window (FLaWin), which incorporates window-based self-attention modules and an efficient fused local-aware feed-forward (FLaFF) network. This architectural design allows us to simultaneously capture short-range and long-range information while facilitating the extraction of rich and diverse contextual representations. Moreover, this design choice results in reduced computational complexity. Experimental results demonstrate the significant contribution of the FLaWin Transformer block to the compression performance, outperforming conventional hand-engineered video codecs such as H.264 and H.265 in terms of rate-distortion trade-off.
Workshop on Document Intelligence Understanding
Jul 31, 2023


Document understanding and information extraction include different tasks to understand a document and extract valuable information automatically. Recently, there has been a rising demand for developing document understanding among different domains, including business, law, and medicine, to boost the efficiency of work that is associated with a large number of documents. This workshop aims to bring together researchers and industry developers in the field of document intelligence and understanding diverse document types to boost automatic document processing and understanding techniques. We also released a data challenge on the recently introduced document-level VQA dataset, PDFVQA. The PDFVQA challenge examines the structural and contextual understandings of proposed models on the natural full document level of multiple consecutive document pages by including questions with a sequence of answers extracted from multi-pages of the full document. This task helps to boost the document understanding step from the single-page level to the full document level understanding.
Automated Testing and Improvement of Named Entity Recognition Systems
Aug 14, 2023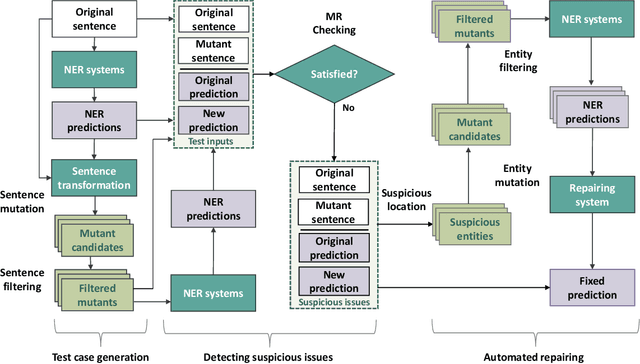

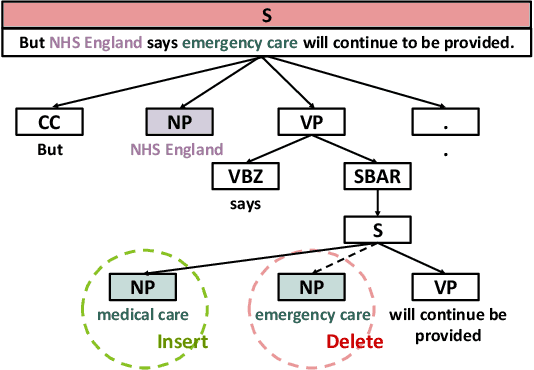
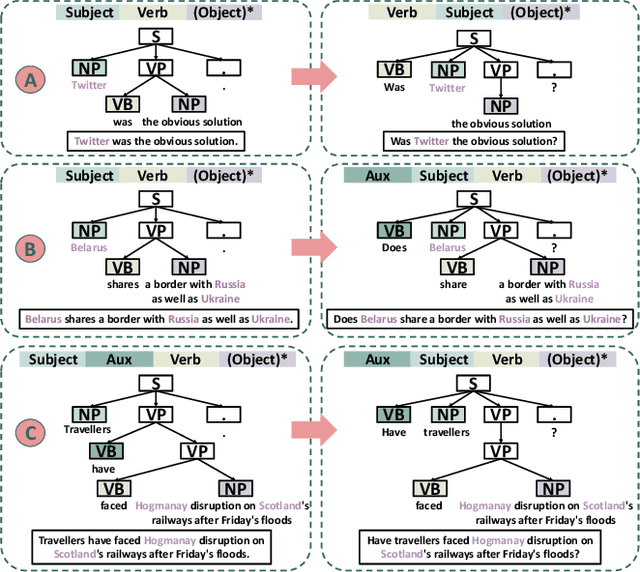
Named entity recognition (NER) systems have seen rapid progress in recent years due to the development of deep neural networks. These systems are widely used in various natural language processing applications, such as information extraction, question answering, and sentiment analysis. However, the complexity and intractability of deep neural networks can make NER systems unreliable in certain circumstances, resulting in incorrect predictions. For example, NER systems may misidentify female names as chemicals or fail to recognize the names of minority groups, leading to user dissatisfaction. To tackle this problem, we introduce TIN, a novel, widely applicable approach for automatically testing and repairing various NER systems. The key idea for automated testing is that the NER predictions of the same named entities under similar contexts should be identical. The core idea for automated repairing is that similar named entities should have the same NER prediction under the same context. We use TIN to test two SOTA NER models and two commercial NER APIs, i.e., Azure NER and AWS NER. We manually verify 784 of the suspicious issues reported by TIN and find that 702 are erroneous issues, leading to high precision (85.0%-93.4%) across four categories of NER errors: omission, over-labeling, incorrect category, and range error. For automated repairing, TIN achieves a high error reduction rate (26.8%-50.6%) over the four systems under test, which successfully repairs 1,056 out of the 1,877 reported NER errors.