 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
SwG-former: Sliding-window Graph Convolutional Network Integrated with Conformer for Sound Event Localization and Detection
Oct 21, 2023
Sound event localization and detection (SELD) is a joint task of sound event detection (SED) and direction of arrival (DoA) estimation. SED mainly relies on temporal dependencies to distinguish different sound classes, while DoA estimation depends on spatial correlations to estimate source directions. To jointly optimize two subtasks, the SELD system should extract spatial correlations and model temporal dependencies simultaneously. However, numerous models mainly extract spatial correlations and model temporal dependencies separately. In this paper, the interdependence of spatial-temporal information in audio signals is exploited for simultaneous extraction to enhance the model performance. In response, a novel graph representation leveraging graph convolutional network (GCN) in non-Euclidean space is developed to extract spatial-temporal information concurrently. A sliding-window graph (SwG) module is designed based on the graph representation. It exploits sliding-windows with different sizes to learn temporal context information and dynamically constructs graph vertices in the frequency-channel (F-C) domain to capture spatial correlations. Furthermore, as the cornerstone of message passing, a robust Conv2dAgg function is proposed and embedded into the SwG module to aggregate the features of neighbor vertices. To improve the performance of SELD in a natural spatial acoustic environment, a general and efficient SwG-former model is proposed by integrating the SwG module with the Conformer. It exhibits superior performance in comparison to recent advanced SELD models. To further validate the generality and efficiency of the SwG-former, it is seamlessly integrated into the event-independent network version 2 (EINV2) called SwG-EINV2. The SwG-EINV2 surpasses the state-of-the-art (SOTA) methods under the same acoustic environment.
Enhancing Argument Structure Extraction with Efficient Leverage of Contextual Information
Oct 08, 2023
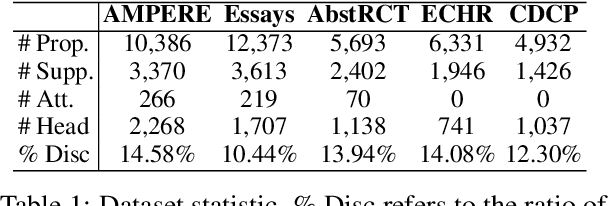
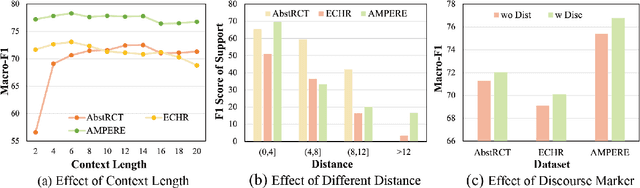
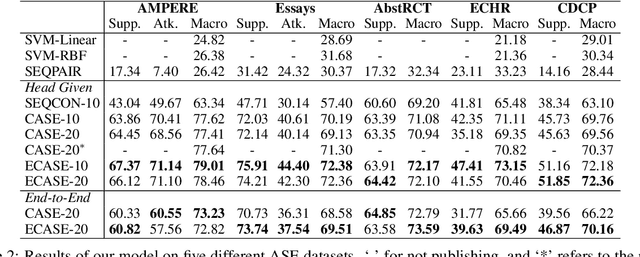
Argument structure extraction (ASE) aims to identify the discourse structure of arguments within documents. Previous research has demonstrated that contextual information is crucial for developing an effective ASE model. However, we observe that merely concatenating sentences in a contextual window does not fully utilize contextual information and can sometimes lead to excessive attention on less informative sentences. To tackle this challenge, we propose an Efficient Context-aware ASE model (ECASE) that fully exploits contextual information by enhancing modeling capacity and augmenting training data. Specifically, we introduce a sequence-attention module and distance-weighted similarity loss to aggregate contextual information and argumentative information. Additionally, we augment the training data by randomly masking discourse markers and sentences, which reduces the model's reliance on specific words or less informative sentences. Our experiments on five datasets from various domains demonstrate that our model achieves state-of-the-art performance. Furthermore, ablation studies confirm the effectiveness of each module in our model.
NESTLE: a No-Code Tool for Statistical Analysis of Legal Corpus
Sep 08, 2023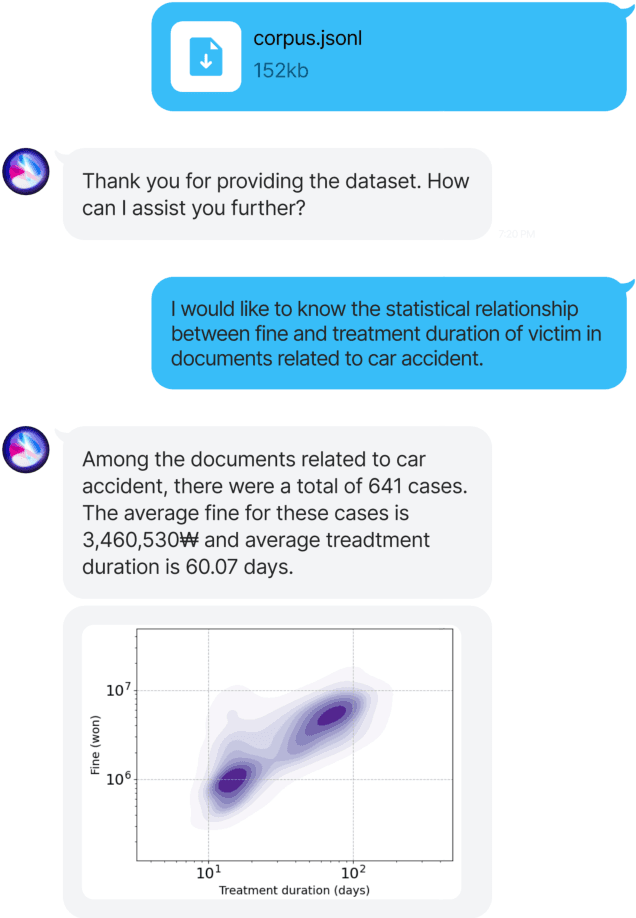
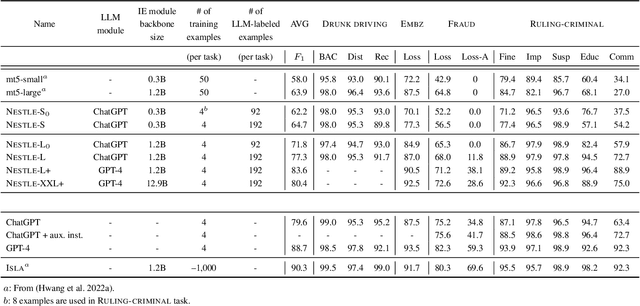
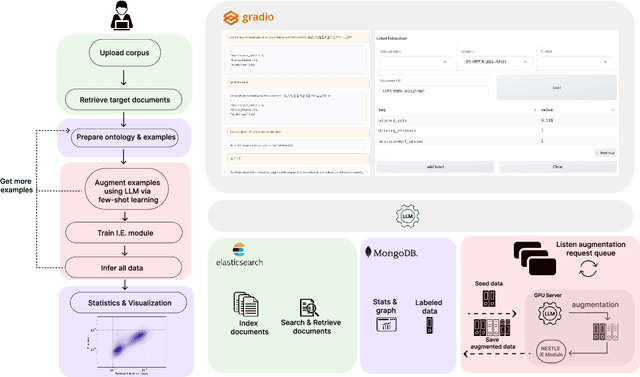

The statistical analysis of large scale legal corpus can provide valuable legal insights. For such analysis one needs to (1) select a subset of the corpus using document retrieval tools, (2) structuralize text using information extraction (IE) systems, and (3) visualize the data for the statistical analysis. Each process demands either specialized tools or programming skills whereas no comprehensive unified "no-code" tools have been available. Especially for IE, if the target information is not predefined in the ontology of the IE system, one needs to build their own system. Here we provide NESTLE, a no code tool for large-scale statistical analysis of legal corpus. With NESTLE, users can search target documents, extract information, and visualize the structured data all via the chat interface with accompanying auxiliary GUI for the fine-level control. NESTLE consists of three main components: a search engine, an end-to-end IE system, and a Large Language Model (LLM) that glues the whole components together and provides the chat interface. Powered by LLM and the end-to-end IE system, NESTLE can extract any type of information that has not been predefined in the IE system opening up the possibility of unlimited customizable statistical analysis of the corpus without writing a single line of code. The use of the custom end-to-end IE system also enables faster and low-cost IE on large scale corpus. We validate our system on 15 Korean precedent IE tasks and 3 legal text classification tasks from LEXGLUE. The comprehensive experiments reveal NESTLE can achieve GPT-4 comparable performance by training the internal IE module with 4 human-labeled, and 192 LLM-labeled examples. The detailed analysis provides the insight on the trade-off between accuracy, time, and cost in building such system.
Product Attribute Value Extraction using Large Language Models
Oct 19, 2023E-commerce applications such as faceted product search or product comparison are based on structured product descriptions like attribute/value pairs. The vendors on e-commerce platforms do not provide structured product descriptions but describe offers using titles or descriptions. To process such offers, it is necessary to extract attribute/value pairs from textual product attributes. State-of-the-art attribute/value extraction techniques rely on pre-trained language models (PLMs), such as BERT. Two major drawbacks of these models for attribute/value extraction are that (i) the models require significant amounts of task-specific training data and (ii) the fine-tuned models face challenges in generalizing to attribute values not included in the training data. This paper explores the potential of large language models (LLMs) as a training data-efficient and robust alternative to PLM-based attribute/value extraction methods. We consider hosted LLMs, such as GPT-3.5 and GPT-4, as well as open-source LLMs based on Llama2. We evaluate the models in a zero-shot scenario and in a scenario where task-specific training data is available. In the zero-shot scenario, we compare various prompt designs for representing information about the target attributes of the extraction. In the scenario with training data, we investigate (i) the provision of example attribute values, (ii) the selection of in-context demonstrations, and (iii) the fine-tuning of GPT-3.5. Our experiments show that GPT-4 achieves an average F1-score of 85% on the two evaluation datasets while the best PLM-based techniques perform on average 5% worse using the same amount of training data. GPT-4 achieves a 10% higher F1-score than the best open-source LLM. The fine-tuned GPT-3.5 model reaches a similar performance as GPT-4 while being significantly more cost-efficient.
Be Careful What You Smooth For: Label Smoothing Can Be a Privacy Shield but Also a Catalyst for Model Inversion Attacks
Oct 10, 2023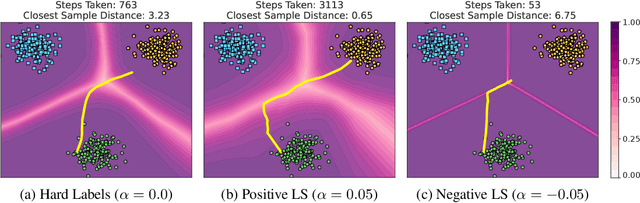

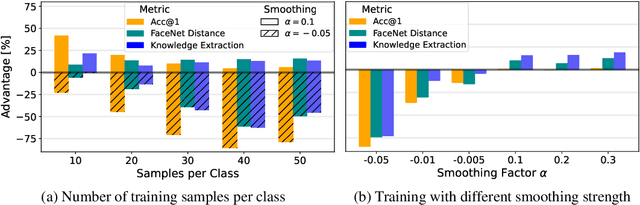
Label smoothing -- using softened labels instead of hard ones -- is a widely adopted regularization method for deep learning, showing diverse benefits such as enhanced generalization and calibration. Its implications for preserving model privacy, however, have remained unexplored. To fill this gap, we investigate the impact of label smoothing on model inversion attacks (MIAs), which aim to generate class-representative samples by exploiting the knowledge encoded in a classifier, thereby inferring sensitive information about its training data. Through extensive analyses, we uncover that traditional label smoothing fosters MIAs, thereby increasing a model's privacy leakage. Even more, we reveal that smoothing with negative factors counters this trend, impeding the extraction of class-related information and leading to privacy preservation, beating state-of-the-art defenses. This establishes a practical and powerful novel way for enhancing model resilience against MIAs.
Syntactic Multi-view Learning for Open Information Extraction
Dec 05, 2022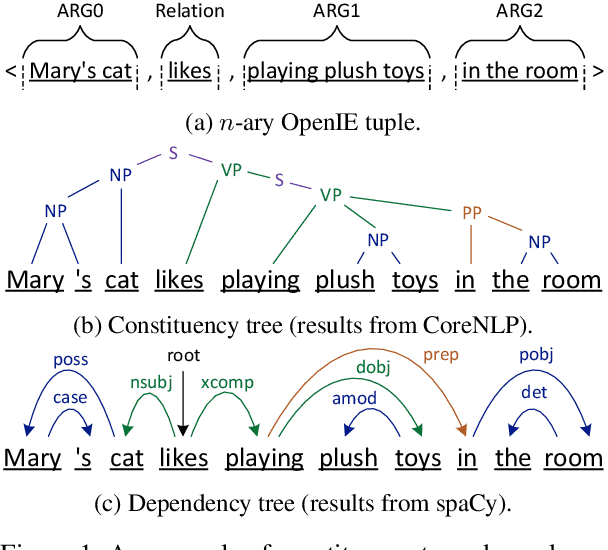
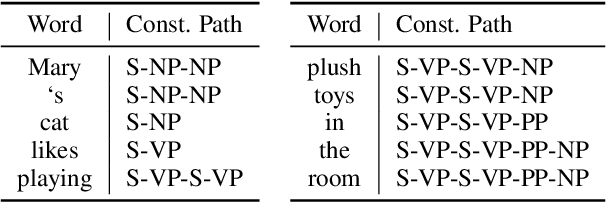
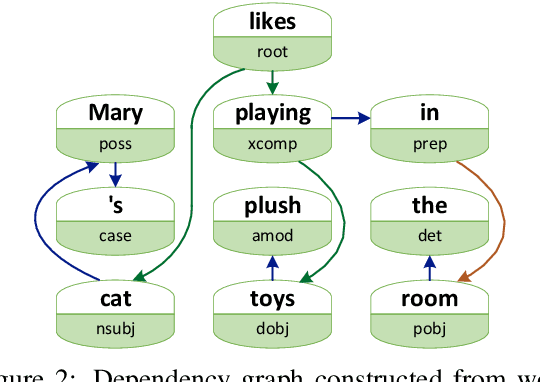
Open Information Extraction (OpenIE) aims to extract relational tuples from open-domain sentences. Traditional rule-based or statistical models have been developed based on syntactic structures of sentences, identified by syntactic parsers. However, previous neural OpenIE models under-explore the useful syntactic information. In this paper, we model both constituency and dependency trees into word-level graphs, and enable neural OpenIE to learn from the syntactic structures. To better fuse heterogeneous information from both graphs, we adopt multi-view learning to capture multiple relationships from them. Finally, the finetuned constituency and dependency representations are aggregated with sentential semantic representations for tuple generation. Experiments show that both constituency and dependency information, and the multi-view learning are effective.
* To appear in EMNLP 2022
Accelerated materials language processing enabled by GPT
Aug 18, 2023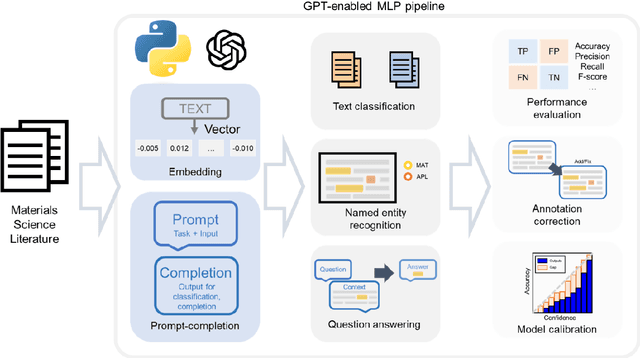
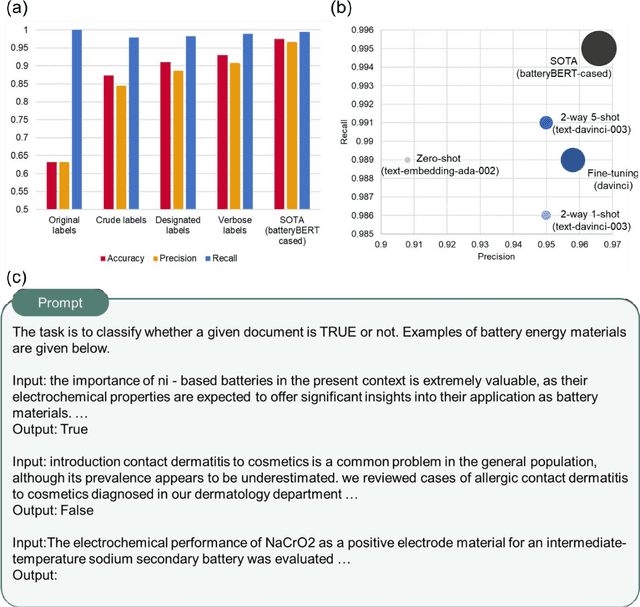
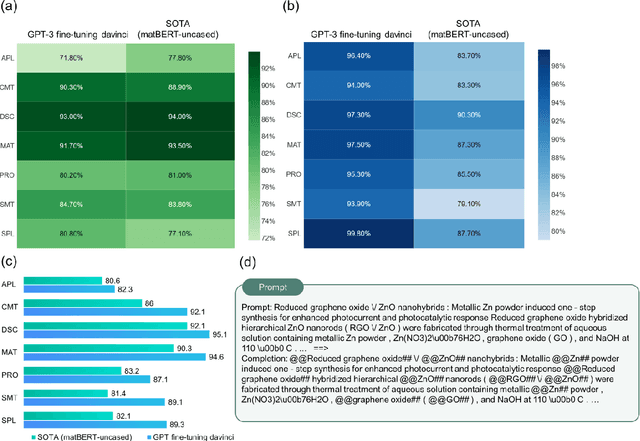
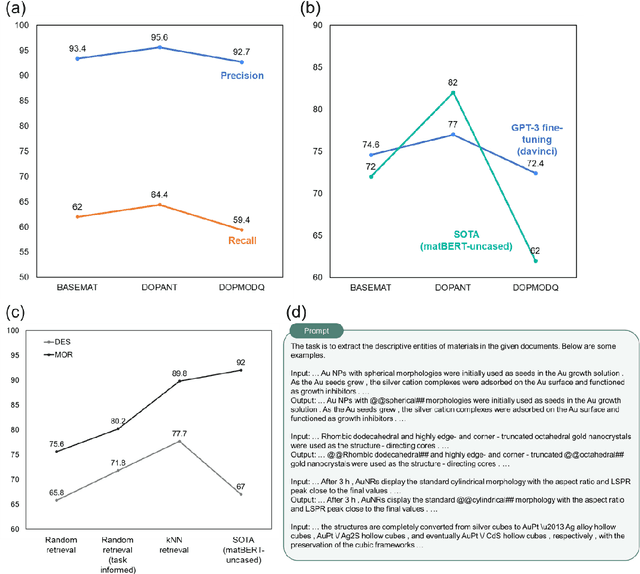
Materials language processing (MLP) is one of the key facilitators of materials science research, as it enables the extraction of structured information from massive materials science literature. Prior works suggested high-performance MLP models for text classification, named entity recognition (NER), and extractive question answering (QA), which require complex model architecture, exhaustive fine-tuning and a large number of human-labelled datasets. In this study, we develop generative pretrained transformer (GPT)-enabled pipelines where the complex architectures of prior MLP models are replaced with strategic designs of prompt engineering. First, we develop a GPT-enabled document classification method for screening relevant documents, achieving comparable accuracy and reliability compared to prior models, with only small dataset. Secondly, for NER task, we design an entity-centric prompts, and learning few-shot of them improved the performance on most of entities in three open datasets. Finally, we develop an GPT-enabled extractive QA model, which provides improved performance and shows the possibility of automatically correcting annotations. While our findings confirm the potential of GPT-enabled MLP models as well as their value in terms of reliability and practicability, our scientific methods and systematic approach are applicable to any materials science domain to accelerate the information extraction of scientific literature.
Towards reducing hallucination in extracting information from financial reports using Large Language Models
Oct 16, 2023For a financial analyst, the question and answer (Q\&A) segment of the company financial report is a crucial piece of information for various analysis and investment decisions. However, extracting valuable insights from the Q\&A section has posed considerable challenges as the conventional methods such as detailed reading and note-taking lack scalability and are susceptible to human errors, and Optical Character Recognition (OCR) and similar techniques encounter difficulties in accurately processing unstructured transcript text, often missing subtle linguistic nuances that drive investor decisions. Here, we demonstrate the utilization of Large Language Models (LLMs) to efficiently and rapidly extract information from earnings report transcripts while ensuring high accuracy transforming the extraction process as well as reducing hallucination by combining retrieval-augmented generation technique as well as metadata. We evaluate the outcomes of various LLMs with and without using our proposed approach based on various objective metrics for evaluating Q\&A systems, and empirically demonstrate superiority of our method.
Knowledge-Enhanced Multi-Label Few-Shot Product Attribute-Value Extraction
Aug 16, 2023
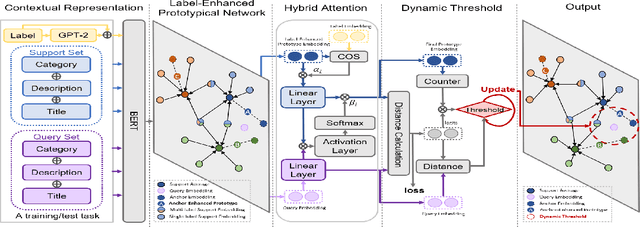
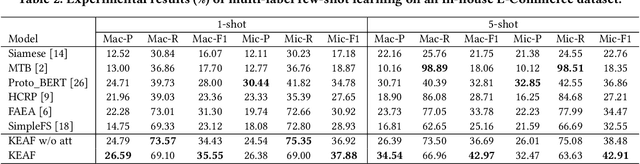
Existing attribute-value extraction (AVE) models require large quantities of labeled data for training. However, new products with new attribute-value pairs enter the market every day in real-world e-Commerce. Thus, we formulate AVE in multi-label few-shot learning (FSL), aiming to extract unseen attribute value pairs based on a small number of training examples. We propose a Knowledge-Enhanced Attentive Framework (KEAF) based on prototypical networks, leveraging the generated label description and category information to learn more discriminative prototypes. Besides, KEAF integrates with hybrid attention to reduce noise and capture more informative semantics for each class by calculating the label-relevant and query-related weights. To achieve multi-label inference, KEAF further learns a dynamic threshold by integrating the semantic information from both the support set and the query set. Extensive experiments with ablation studies conducted on two datasets demonstrate that KEAF outperforms other SOTA models for information extraction in FSL. The code can be found at: https://github.com/gjiaying/KEAF
BELB: a Biomedical Entity Linking Benchmark
Aug 22, 2023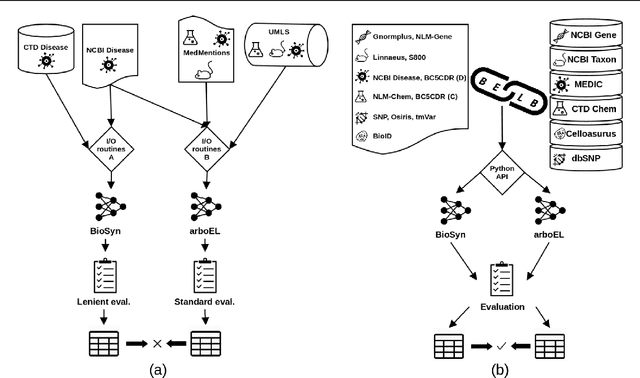
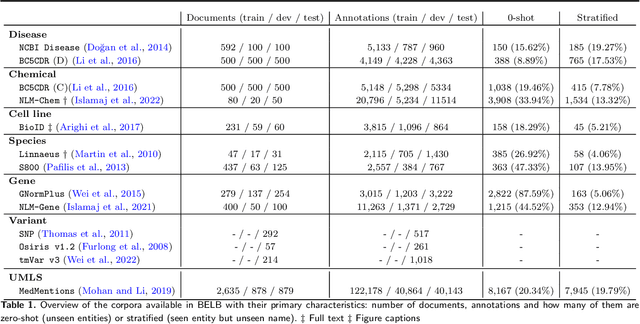
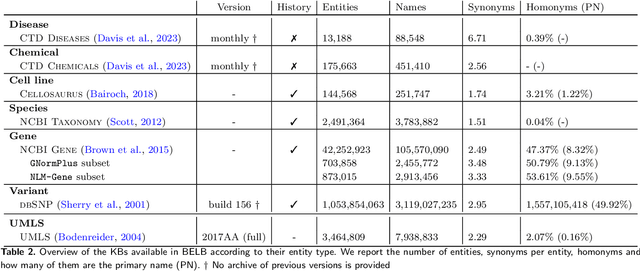

Biomedical entity linking (BEL) is the task of grounding entity mentions to a knowledge base. It plays a vital role in information extraction pipelines for the life sciences literature. We review recent work in the field and find that, as the task is absent from existing benchmarks for biomedical text mining, different studies adopt different experimental setups making comparisons based on published numbers problematic. Furthermore, neural systems are tested primarily on instances linked to the broad coverage knowledge base UMLS, leaving their performance to more specialized ones, e.g. genes or variants, understudied. We therefore developed BELB, a Biomedical Entity Linking Benchmark, providing access in a unified format to 11 corpora linked to 7 knowledge bases and spanning six entity types: gene, disease, chemical, species, cell line and variant. BELB greatly reduces preprocessing overhead in testing BEL systems on multiple corpora offering a standardized testbed for reproducible experiments. Using BELB we perform an extensive evaluation of six rule-based entity-specific systems and three recent neural approaches leveraging pre-trained language models. Our results reveal a mixed picture showing that neural approaches fail to perform consistently across entity types, highlighting the need of further studies towards entity-agnostic models.