 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Localize, Retrieve and Fuse: A Generalized Framework for Free-Form Question Answering over Tables
Sep 21, 2023

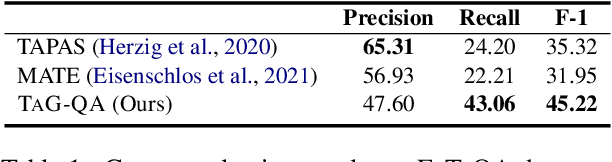
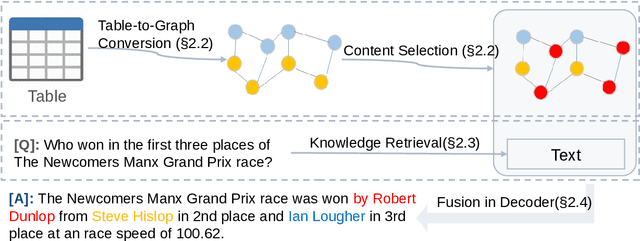
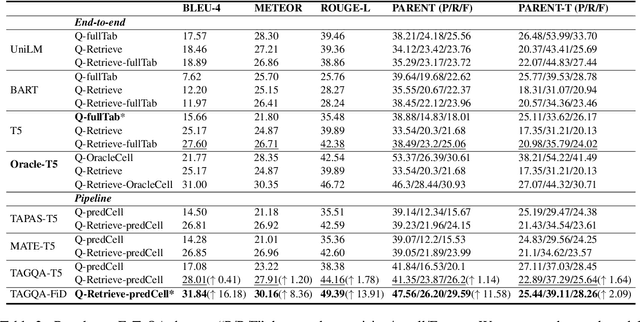
Question answering on tabular data (a.k.a TableQA), which aims at generating answers to questions grounded on a provided table, has gained significant attention recently. Prior work primarily produces concise factual responses through information extraction from individual or limited table cells, lacking the ability to reason across diverse table cells. Yet, the realm of free-form TableQA, which demands intricate strategies for selecting relevant table cells and the sophisticated integration and inference of discrete data fragments, remains mostly unexplored. To this end, this paper proposes a generalized three-stage approach: Table-to- Graph conversion and cell localizing, external knowledge retrieval, and the fusion of table and text (called TAG-QA), to address the challenge of inferring long free-form answers in generative TableQA. In particular, TAG-QA (1) locates relevant table cells using a graph neural network to gather intersecting cells between relevant rows and columns, (2) leverages external knowledge from Wikipedia, and (3) generates answers by integrating both tabular data and natural linguistic information. Experiments showcase the superior capabilities of TAG-QA in generating sentences that are both faithful and coherent, particularly when compared to several state-of-the-art baselines. Notably, TAG-QA surpasses the robust pipeline-based baseline TAPAS by 17% and 14% in terms of BLEU-4 and PARENT F-score, respectively. Furthermore, TAG-QA outperforms the end-to-end model T5 by 16% and 12% on BLEU-4 and PARENT F-score, respectively.
Type-aware Decoding via Explicitly Aggregating Event Information for Document-level Event Extraction
Oct 16, 2023Document-level event extraction (DEE) faces two main challenges: arguments-scattering and multi-event. Although previous methods attempt to address these challenges, they overlook the interference of event-unrelated sentences during event detection and neglect the mutual interference of different event roles during argument extraction. Therefore, this paper proposes a novel Schema-based Explicitly Aggregating~(SEA) model to address these limitations. SEA aggregates event information into event type and role representations, enabling the decoding of event records based on specific type-aware representations. By detecting each event based on its event type representation, SEA mitigates the interference caused by event-unrelated information. Furthermore, SEA extracts arguments for each role based on its role-aware representations, reducing mutual interference between different roles. Experimental results on the ChFinAnn and DuEE-fin datasets show that SEA outperforms the SOTA methods.
Graph Representation Learning for Infrared and Visible Image Fusion
Nov 01, 2023Infrared and visible image fusion aims to extract complementary features to synthesize a single fused image. Many methods employ convolutional neural networks (CNNs) to extract local features due to its translation invariance and locality. However, CNNs fail to consider the image's non-local self-similarity (NLss), though it can expand the receptive field by pooling operations, it still inevitably leads to information loss. In addition, the transformer structure extracts long-range dependence by considering the correlativity among all image patches, leading to information redundancy of such transformer-based methods. However, graph representation is more flexible than grid (CNN) or sequence (transformer structure) representation to address irregular objects, and graph can also construct the relationships among the spatially repeatable details or texture with far-space distance. Therefore, to address the above issues, it is significant to convert images into the graph space and thus adopt graph convolutional networks (GCNs) to extract NLss. This is because the graph can provide a fine structure to aggregate features and propagate information across the nearest vertices without introducing redundant information. Concretely, we implement a cascaded NLss extraction pattern to extract NLss of intra- and inter-modal by exploring interactions of different image pixels in intra- and inter-image positional distance. We commence by preforming GCNs on each intra-modal to aggregate features and propagate information to extract independent intra-modal NLss. Then, GCNs are performed on the concatenate intra-modal NLss features of infrared and visible images, which can explore the cross-domain NLss of inter-modal to reconstruct the fused image. Ablation studies and extensive experiments illustrates the effectiveness and superiority of the proposed method on three datasets.
MaScQA: A Question Answering Dataset for Investigating Materials Science Knowledge of Large Language Models
Aug 17, 2023
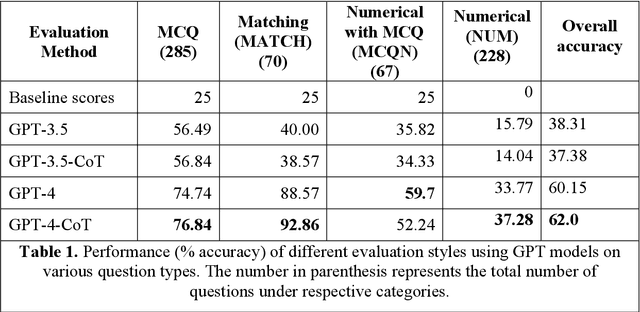
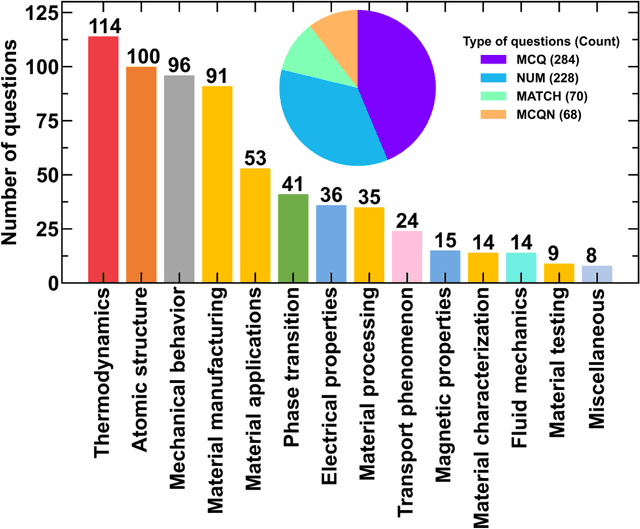
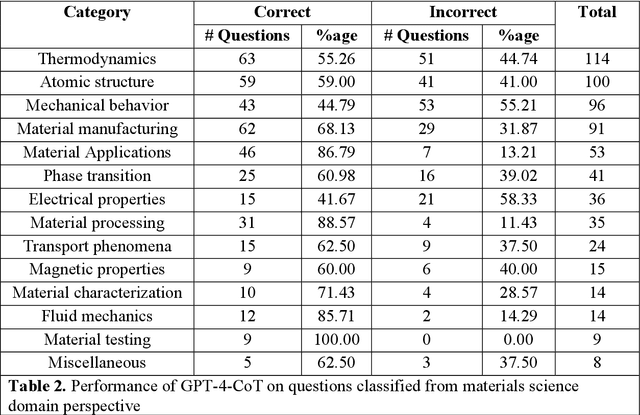
Information extraction and textual comprehension from materials literature are vital for developing an exhaustive knowledge base that enables accelerated materials discovery. Language models have demonstrated their capability to answer domain-specific questions and retrieve information from knowledge bases. However, there are no benchmark datasets in the materials domain that can evaluate the understanding of the key concepts by these language models. In this work, we curate a dataset of 650 challenging questions from the materials domain that require the knowledge and skills of a materials student who has cleared their undergraduate degree. We classify these questions based on their structure and the materials science domain-based subcategories. Further, we evaluate the performance of GPT-3.5 and GPT-4 models on solving these questions via zero-shot and chain of thought prompting. It is observed that GPT-4 gives the best performance (~62% accuracy) as compared to GPT-3.5. Interestingly, in contrast to the general observation, no significant improvement in accuracy is observed with the chain of thought prompting. To evaluate the limitations, we performed an error analysis, which revealed conceptual errors (~64%) as the major contributor compared to computational errors (~36%) towards the reduced performance of LLMs. We hope that the dataset and analysis performed in this work will promote further research in developing better materials science domain-specific LLMs and strategies for information extraction.
Contextualized Medication Information Extraction Using Transformer-based Deep Learning Architectures
Mar 14, 2023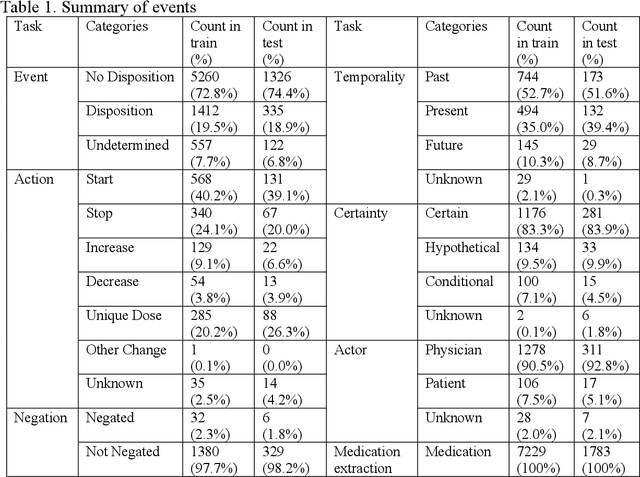
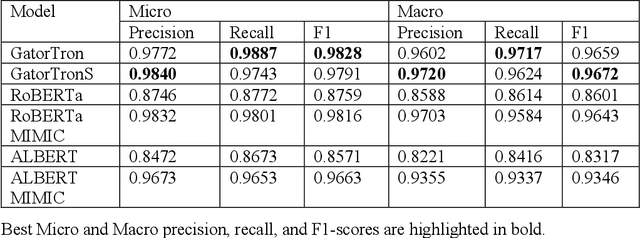
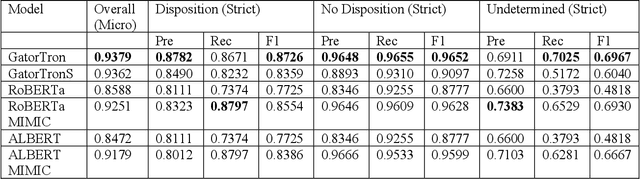
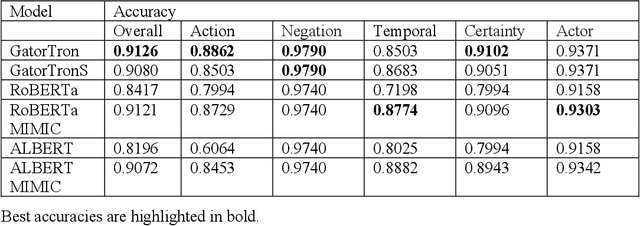
Objective: To develop a natural language processing (NLP) system to extract medications and contextual information that help understand drug changes. This project is part of the 2022 n2c2 challenge. Materials and methods: We developed NLP systems for medication mention extraction, event classification (indicating medication changes discussed or not), and context classification to classify medication changes context into 5 orthogonal dimensions related to drug changes. We explored 6 state-of-the-art pretrained transformer models for the three subtasks, including GatorTron, a large language model pretrained using >90 billion words of text (including >80 billion words from >290 million clinical notes identified at the University of Florida Health). We evaluated our NLP systems using annotated data and evaluation scripts provided by the 2022 n2c2 organizers. Results:Our GatorTron models achieved the best F1-scores of 0.9828 for medication extraction (ranked 3rd), 0.9379 for event classification (ranked 2nd), and the best micro-average accuracy of 0.9126 for context classification. GatorTron outperformed existing transformer models pretrained using smaller general English text and clinical text corpora, indicating the advantage of large language models. Conclusion: This study demonstrated the advantage of using large transformer models for contextual medication information extraction from clinical narratives.
A Contextualized Real-Time Multimodal Emotion Recognition for Conversational Agents using Graph Convolutional Networks in Reinforcement Learning
Oct 24, 2023Owing to the recent developments in Generative Artificial Intelligence (GenAI) and Large Language Models (LLM), conversational agents are becoming increasingly popular and accepted. They provide a human touch by interacting in ways familiar to us and by providing support as virtual companions. Therefore, it is important to understand the user's emotions in order to respond considerately. Compared to the standard problem of emotion recognition, conversational agents face an additional constraint in that recognition must be real-time. Studies on model architectures using audio, visual, and textual modalities have mainly focused on emotion classification using full video sequences that do not provide online features. In this work, we present a novel paradigm for contextualized Emotion Recognition using Graph Convolutional Network with Reinforcement Learning (conER-GRL). Conversations are partitioned into smaller groups of utterances for effective extraction of contextual information. The system uses Gated Recurrent Units (GRU) to extract multimodal features from these groups of utterances. More importantly, Graph Convolutional Networks (GCN) and Reinforcement Learning (RL) agents are cascade trained to capture the complex dependencies of emotion features in interactive scenarios. Comparing the results of the conER-GRL model with other state-of-the-art models on the benchmark dataset IEMOCAP demonstrates the advantageous capabilities of the conER-GRL architecture in recognizing emotions in real-time from multimodal conversational signals.
Leave no Place Behind: Improved Geolocation in Humanitarian Documents
Sep 06, 2023
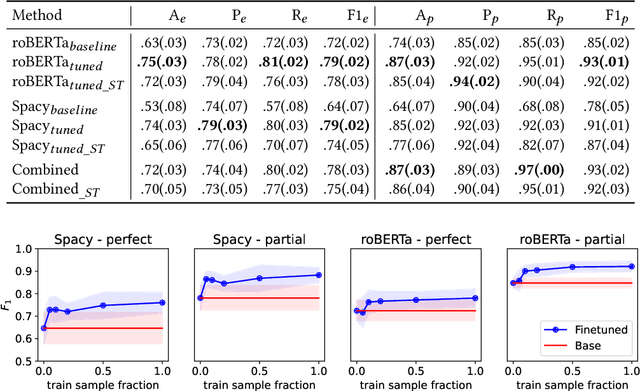
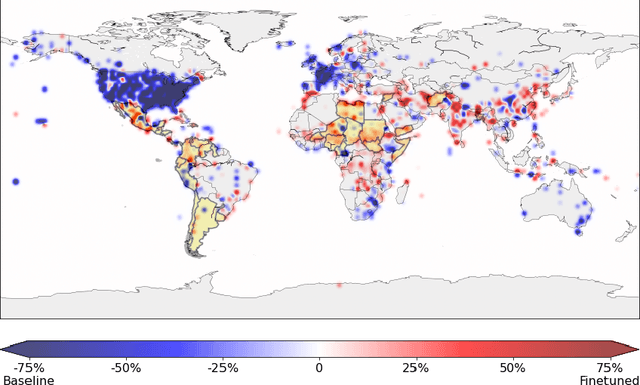
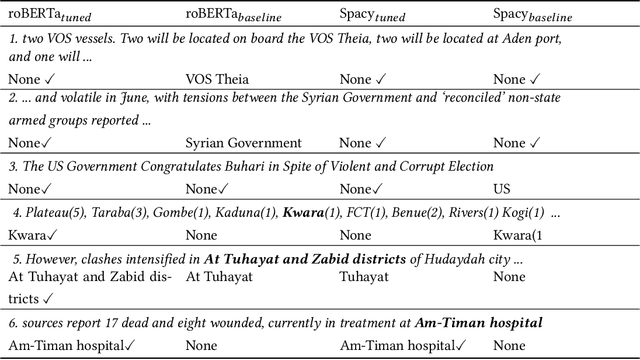
Geographical location is a crucial element of humanitarian response, outlining vulnerable populations, ongoing events, and available resources. Latest developments in Natural Language Processing may help in extracting vital information from the deluge of reports and documents produced by the humanitarian sector. However, the performance and biases of existing state-of-the-art information extraction tools are unknown. In this work, we develop annotated resources to fine-tune the popular Named Entity Recognition (NER) tools Spacy and roBERTa to perform geotagging of humanitarian texts. We then propose a geocoding method FeatureRank which links the candidate locations to the GeoNames database. We find that not only does the humanitarian-domain data improves the performance of the classifiers (up to F1 = 0.92), but it also alleviates some of the bias of the existing tools, which erroneously favor locations in the Western countries. Thus, we conclude that more resources from non-Western documents are necessary to ensure that off-the-shelf NER systems are suitable for the deployment in the humanitarian sector.
CARE: Co-Attention Network for Joint Entity and Relation Extraction
Aug 24, 2023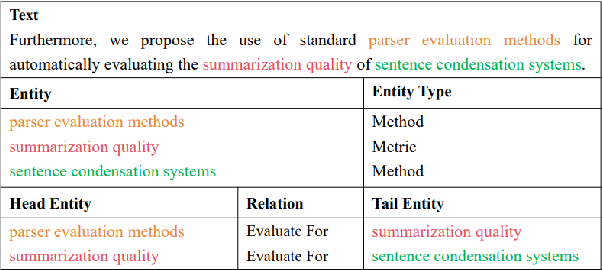
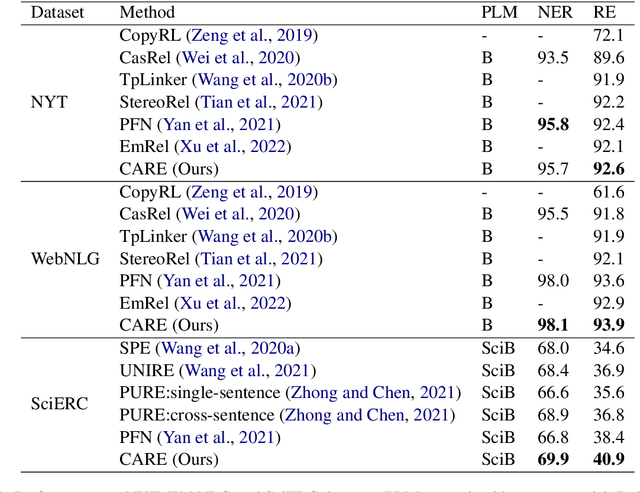
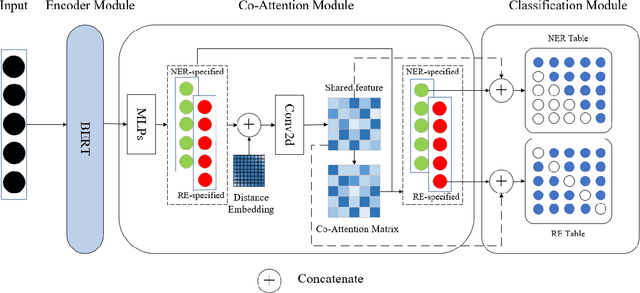
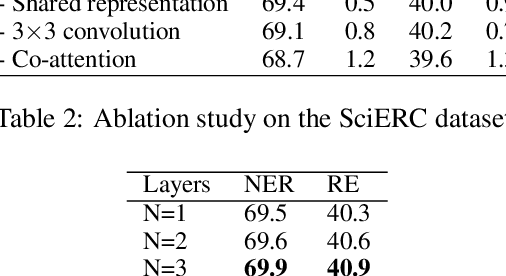
Joint entity and relation extraction is the fundamental task of information extraction, consisting of two subtasks: named entity recognition and relation extraction. Most existing joint extraction methods suffer from issues of feature confusion or inadequate interaction between two subtasks. In this work, we propose a Co-Attention network for joint entity and Relation Extraction (CARE). Our approach involves learning separate representations for each subtask, aiming to avoid feature overlap. At the core of our approach is the co-attention module that captures two-way interaction between two subtasks, allowing the model to leverage entity information for relation prediction and vice versa, thus promoting mutual enhancement. Extensive experiments on three joint entity-relation extraction benchmark datasets (NYT, WebNLG and SciERC) show that our proposed model achieves superior performance, surpassing existing baseline models.
MIST: Medical Image Segmentation Transformer with Convolutional Attention Mixing (CAM) Decoder
Oct 30, 2023One of the common and promising deep learning approaches used for medical image segmentation is transformers, as they can capture long-range dependencies among the pixels by utilizing self-attention. Despite being successful in medical image segmentation, transformers face limitations in capturing local contexts of pixels in multimodal dimensions. We propose a Medical Image Segmentation Transformer (MIST) incorporating a novel Convolutional Attention Mixing (CAM) decoder to address this issue. MIST has two parts: a pre-trained multi-axis vision transformer (MaxViT) is used as an encoder, and the encoded feature representation is passed through the CAM decoder for segmenting the images. In the CAM decoder, an attention-mixer combining multi-head self-attention, spatial attention, and squeeze and excitation attention modules is introduced to capture long-range dependencies in all spatial dimensions. Moreover, to enhance spatial information gain, deep and shallow convolutions are used for feature extraction and receptive field expansion, respectively. The integration of low-level and high-level features from different network stages is enabled by skip connections, allowing MIST to suppress unnecessary information. The experiments show that our MIST transformer with CAM decoder outperforms the state-of-the-art models specifically designed for medical image segmentation on the ACDC and Synapse datasets. Our results also demonstrate that adding the CAM decoder with a hierarchical transformer improves segmentation performance significantly. Our model with data and code is publicly available on GitHub.
Exploring the law of text geographic information
Sep 01, 2023
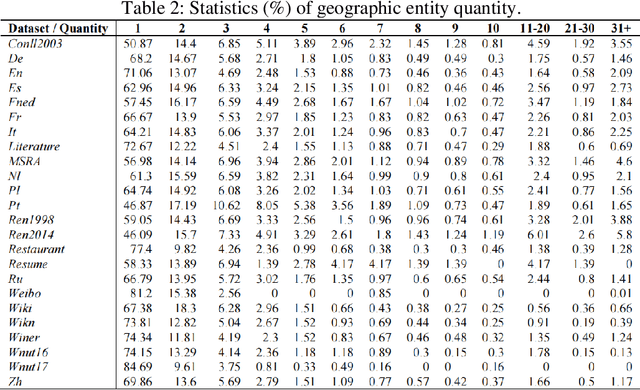
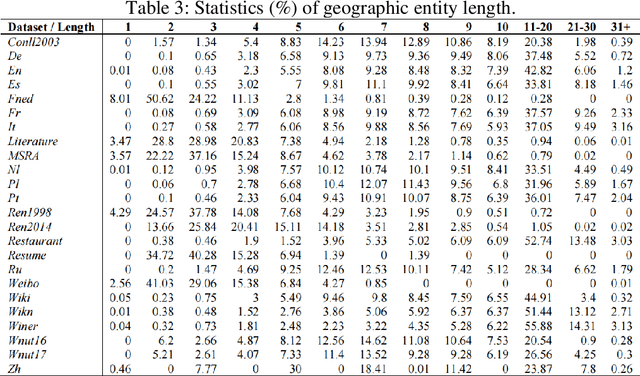
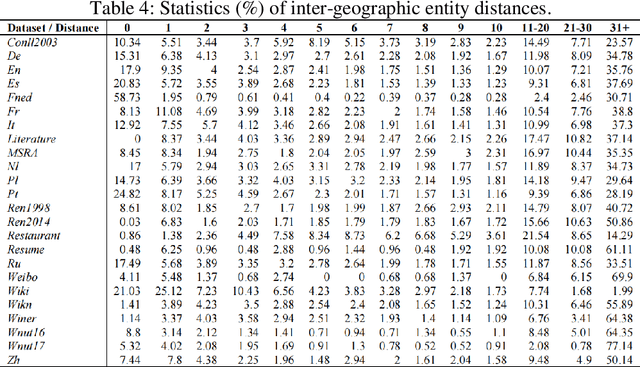
Textual geographic information is indispensable and heavily relied upon in practical applications. The absence of clear distribution poses challenges in effectively harnessing geographic information, thereby driving our quest for exploration. We contend that geographic information is influenced by human behavior, cognition, expression, and thought processes, and given our intuitive understanding of natural systems, we hypothesize its conformity to the Gamma distribution. Through rigorous experiments on a diverse range of 24 datasets encompassing different languages and types, we have substantiated this hypothesis, unearthing the underlying regularities governing the dimensions of quantity, length, and distance in geographic information. Furthermore, theoretical analyses and comparisons with Gaussian distributions and Zipf's law have refuted the contingency of these laws. Significantly, we have estimated the upper bounds of human utilization of geographic information, pointing towards the existence of uncharted territories. Also, we provide guidance in geographic information extraction. Hope we peer its true countenance uncovering the veil of geographic information.