 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Evaluating ChatGPT's Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness
Apr 23, 2023
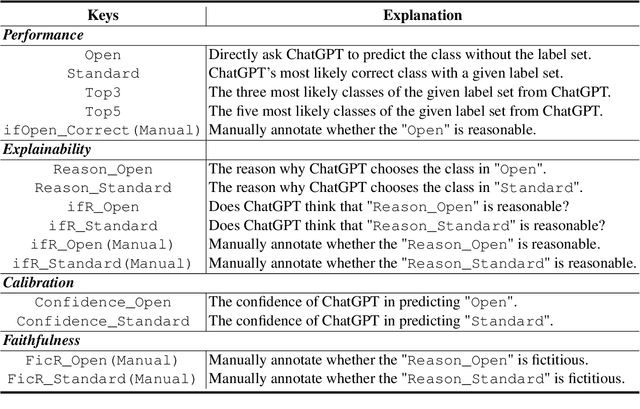
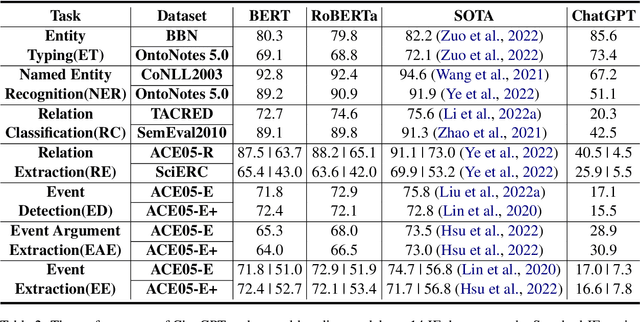
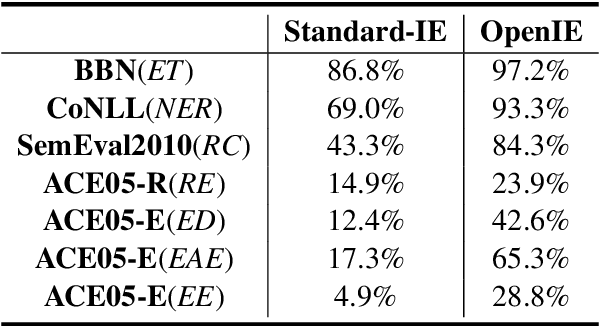
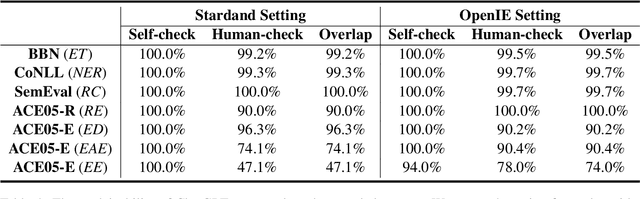
The capability of Large Language Models (LLMs) like ChatGPT to comprehend user intent and provide reasonable responses has made them extremely popular lately. In this paper, we focus on assessing the overall ability of ChatGPT using 7 fine-grained information extraction (IE) tasks. Specially, we present the systematically analysis by measuring ChatGPT's performance, explainability, calibration, and faithfulness, and resulting in 15 keys from either the ChatGPT or domain experts. Our findings reveal that ChatGPT's performance in Standard-IE setting is poor, but it surprisingly exhibits excellent performance in the OpenIE setting, as evidenced by human evaluation. In addition, our research indicates that ChatGPT provides high-quality and trustworthy explanations for its decisions. However, there is an issue of ChatGPT being overconfident in its predictions, which resulting in low calibration. Furthermore, ChatGPT demonstrates a high level of faithfulness to the original text in the majority of cases. We manually annotate and release the test sets of 7 fine-grained IE tasks contains 14 datasets to further promote the research. The datasets and code are available at https://github.com/pkuserc/ChatGPT_for_IE.
A Knowledge-enhanced Two-stage Generative Framework for Medical Dialogue Information Extraction
Jul 30, 2023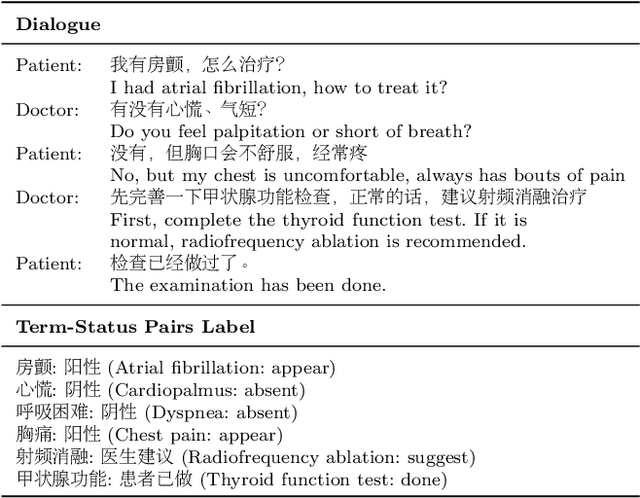
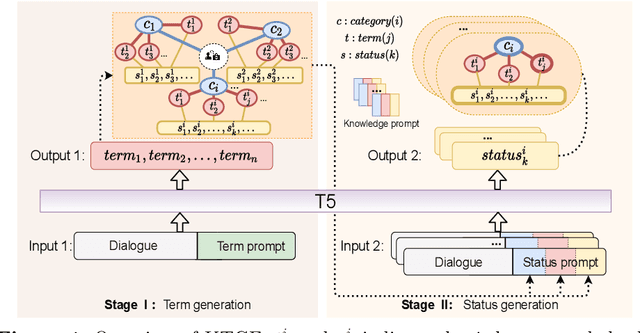
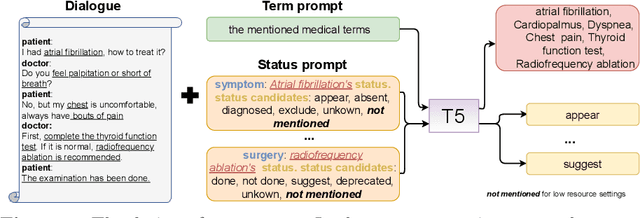
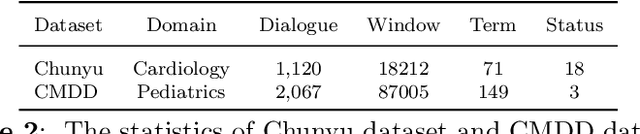
This paper focuses on term-status pair extraction from medical dialogues (MD-TSPE), which is essential in diagnosis dialogue systems and the automatic scribe of electronic medical records (EMRs). In the past few years, works on MD-TSPE have attracted increasing research attention, especially after the remarkable progress made by generative methods. However, these generative methods output a whole sequence consisting of term-status pairs in one stage and ignore integrating prior knowledge, which demands a deeper understanding to model the relationship between terms and infer the status of each term. This paper presents a knowledge-enhanced two-stage generative framework (KTGF) to address the above challenges. Using task-specific prompts, we employ a single model to complete the MD-TSPE through two phases in a unified generative form: we generate all terms the first and then generate the status of each generated term. In this way, the relationship between terms can be learned more effectively from the sequence containing only terms in the first phase, and our designed knowledge-enhanced prompt in the second phase can leverage the category and status candidates of the generated term for status generation. Furthermore, our proposed special status ``not mentioned" makes more terms available and enriches the training data in the second phase, which is critical in the low-resource setting. The experiments on the Chunyu and CMDD datasets show that the proposed method achieves superior results compared to the state-of-the-art models in the full training and low-resource settings.
Black-Box Analysis: GPTs Across Time in Legal Textual Entailment Task
Sep 11, 2023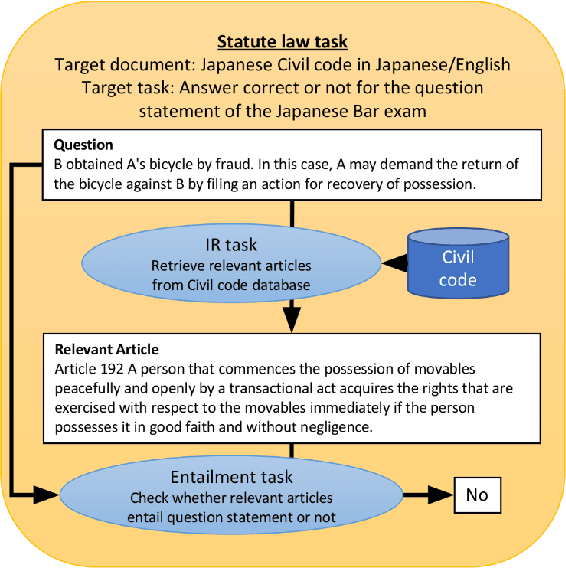
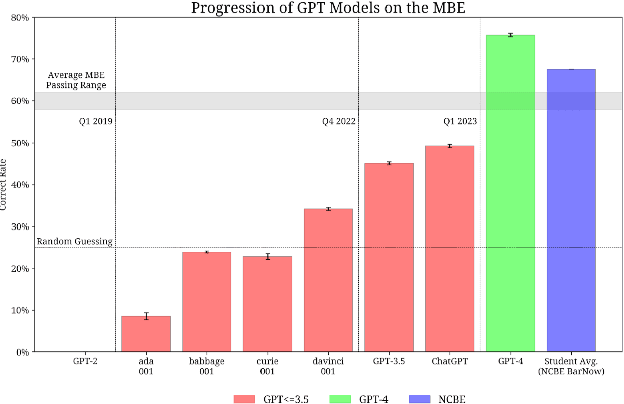
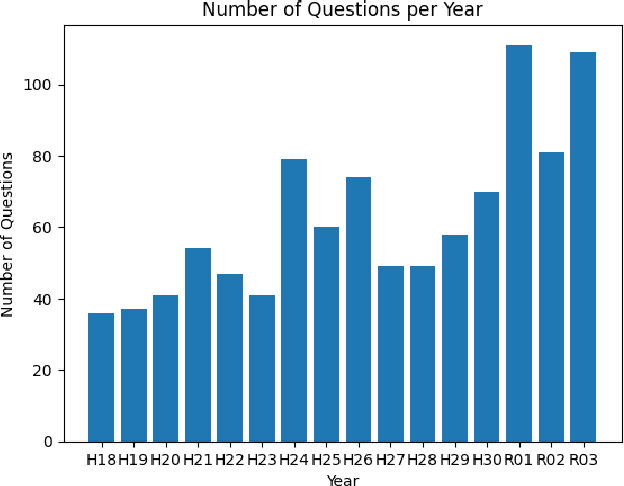
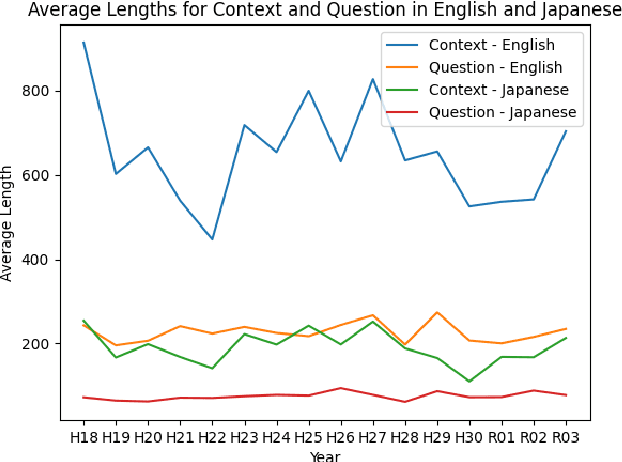
The evolution of Generative Pre-trained Transformer (GPT) models has led to significant advancements in various natural language processing applications, particularly in legal textual entailment. We present an analysis of GPT-3.5 (ChatGPT) and GPT-4 performances on COLIEE Task 4 dataset, a prominent benchmark in this domain. The study encompasses data from Heisei 18 (2006) to Reiwa 3 (2021), exploring the models' abilities to discern entailment relationships within Japanese statute law across different periods. Our preliminary experimental results unveil intriguing insights into the models' strengths and weaknesses in handling legal textual entailment tasks, as well as the patterns observed in model performance. In the context of proprietary models with undisclosed architectures and weights, black-box analysis becomes crucial for evaluating their capabilities. We discuss the influence of training data distribution and the implications on the models' generalizability. This analysis serves as a foundation for future research, aiming to optimize GPT-based models and enable their successful adoption in legal information extraction and entailment applications.
Localize, Retrieve and Fuse: A Generalized Framework for Free-Form Question Answering over Tables
Sep 21, 2023
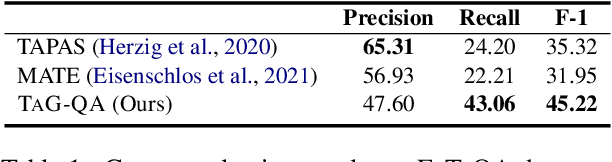
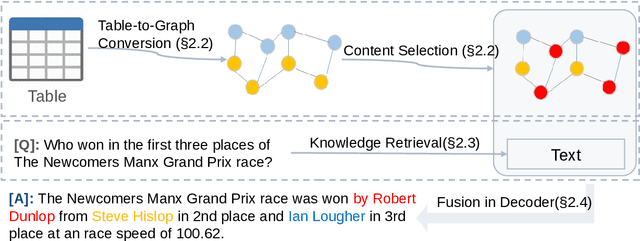
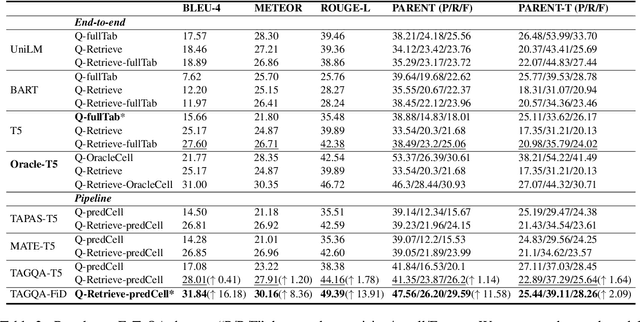
Question answering on tabular data (a.k.a TableQA), which aims at generating answers to questions grounded on a provided table, has gained significant attention recently. Prior work primarily produces concise factual responses through information extraction from individual or limited table cells, lacking the ability to reason across diverse table cells. Yet, the realm of free-form TableQA, which demands intricate strategies for selecting relevant table cells and the sophisticated integration and inference of discrete data fragments, remains mostly unexplored. To this end, this paper proposes a generalized three-stage approach: Table-to- Graph conversion and cell localizing, external knowledge retrieval, and the fusion of table and text (called TAG-QA), to address the challenge of inferring long free-form answers in generative TableQA. In particular, TAG-QA (1) locates relevant table cells using a graph neural network to gather intersecting cells between relevant rows and columns, (2) leverages external knowledge from Wikipedia, and (3) generates answers by integrating both tabular data and natural linguistic information. Experiments showcase the superior capabilities of TAG-QA in generating sentences that are both faithful and coherent, particularly when compared to several state-of-the-art baselines. Notably, TAG-QA surpasses the robust pipeline-based baseline TAPAS by 17% and 14% in terms of BLEU-4 and PARENT F-score, respectively. Furthermore, TAG-QA outperforms the end-to-end model T5 by 16% and 12% on BLEU-4 and PARENT F-score, respectively.
Graph Representation Learning for Infrared and Visible Image Fusion
Nov 01, 2023Infrared and visible image fusion aims to extract complementary features to synthesize a single fused image. Many methods employ convolutional neural networks (CNNs) to extract local features due to its translation invariance and locality. However, CNNs fail to consider the image's non-local self-similarity (NLss), though it can expand the receptive field by pooling operations, it still inevitably leads to information loss. In addition, the transformer structure extracts long-range dependence by considering the correlativity among all image patches, leading to information redundancy of such transformer-based methods. However, graph representation is more flexible than grid (CNN) or sequence (transformer structure) representation to address irregular objects, and graph can also construct the relationships among the spatially repeatable details or texture with far-space distance. Therefore, to address the above issues, it is significant to convert images into the graph space and thus adopt graph convolutional networks (GCNs) to extract NLss. This is because the graph can provide a fine structure to aggregate features and propagate information across the nearest vertices without introducing redundant information. Concretely, we implement a cascaded NLss extraction pattern to extract NLss of intra- and inter-modal by exploring interactions of different image pixels in intra- and inter-image positional distance. We commence by preforming GCNs on each intra-modal to aggregate features and propagate information to extract independent intra-modal NLss. Then, GCNs are performed on the concatenate intra-modal NLss features of infrared and visible images, which can explore the cross-domain NLss of inter-modal to reconstruct the fused image. Ablation studies and extensive experiments illustrates the effectiveness and superiority of the proposed method on three datasets.
Type-aware Decoding via Explicitly Aggregating Event Information for Document-level Event Extraction
Oct 16, 2023Document-level event extraction (DEE) faces two main challenges: arguments-scattering and multi-event. Although previous methods attempt to address these challenges, they overlook the interference of event-unrelated sentences during event detection and neglect the mutual interference of different event roles during argument extraction. Therefore, this paper proposes a novel Schema-based Explicitly Aggregating~(SEA) model to address these limitations. SEA aggregates event information into event type and role representations, enabling the decoding of event records based on specific type-aware representations. By detecting each event based on its event type representation, SEA mitigates the interference caused by event-unrelated information. Furthermore, SEA extracts arguments for each role based on its role-aware representations, reducing mutual interference between different roles. Experimental results on the ChFinAnn and DuEE-fin datasets show that SEA outperforms the SOTA methods.
Optimising Human-Machine Collaboration for Efficient High-Precision Information Extraction from Text Documents
Feb 18, 2023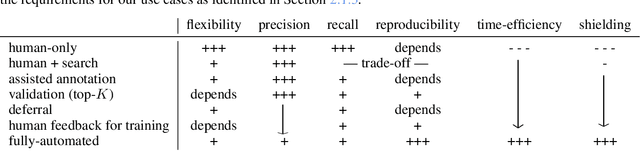
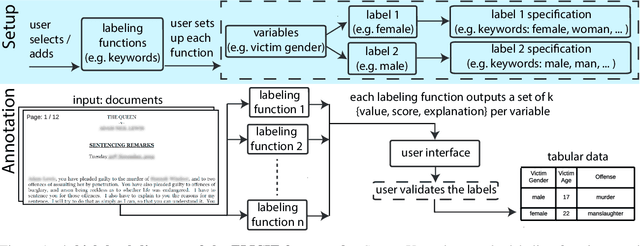
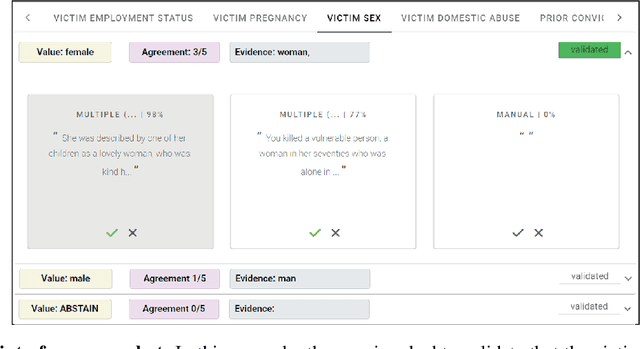
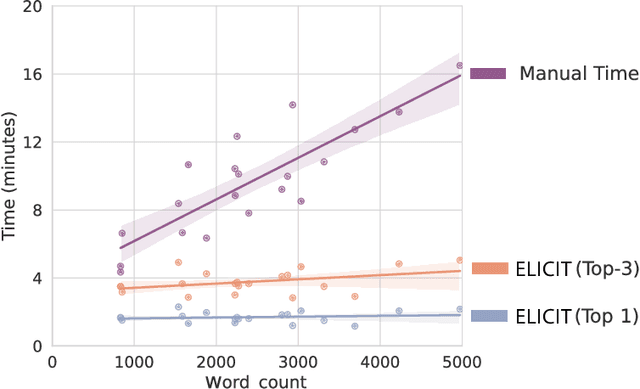
While humans can extract information from unstructured text with high precision and recall, this is often too time-consuming to be practical. Automated approaches, on the other hand, produce nearly-immediate results, but may not be reliable enough for high-stakes applications where precision is essential. In this work, we consider the benefits and drawbacks of various human-only, human-machine, and machine-only information extraction approaches. We argue for the utility of a human-in-the-loop approach in applications where high precision is required, but purely manual extraction is infeasible. We present a framework and an accompanying tool for information extraction using weak-supervision labelling with human validation. We demonstrate our approach on three criminal justice datasets. We find that the combination of computer speed and human understanding yields precision comparable to manual annotation while requiring only a fraction of time, and significantly outperforms fully automated baselines in terms of precision.
LasUIE: Unifying Information Extraction with Latent Adaptive Structure-aware Generative Language Model
Apr 13, 2023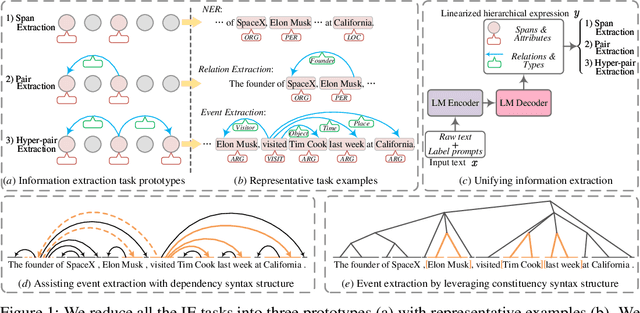
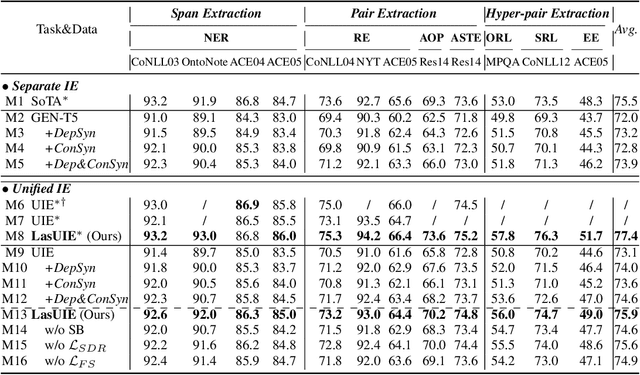
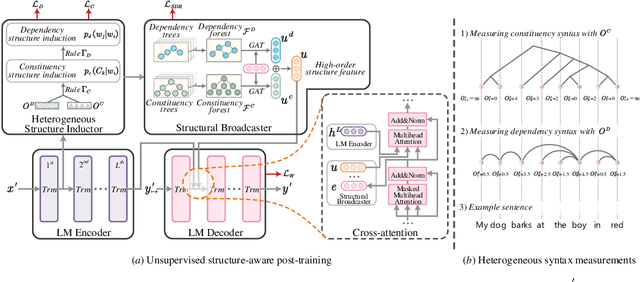
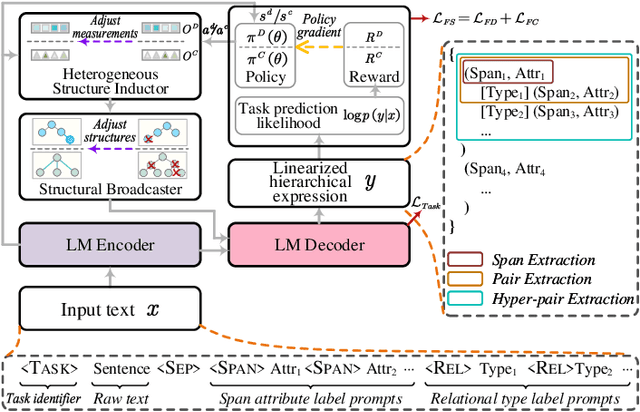
Universally modeling all typical information extraction tasks (UIE) with one generative language model (GLM) has revealed great potential by the latest study, where various IE predictions are unified into a linearized hierarchical expression under a GLM. Syntactic structure information, a type of effective feature which has been extensively utilized in IE community, should also be beneficial to UIE. In this work, we propose a novel structure-aware GLM, fully unleashing the power of syntactic knowledge for UIE. A heterogeneous structure inductor is explored to unsupervisedly induce rich heterogeneous structural representations by post-training an existing GLM. In particular, a structural broadcaster is devised to compact various latent trees into explicit high-order forests, helping to guide a better generation during decoding. We finally introduce a task-oriented structure fine-tuning mechanism, further adjusting the learned structures to most coincide with the end-task's need. Over 12 IE benchmarks across 7 tasks our system shows significant improvements over the baseline UIE system. Further in-depth analyses show that our GLM learns rich task-adaptive structural bias that greatly resolves the UIE crux, the long-range dependence issue and boundary identifying. Source codes are open at https://github.com/ChocoWu/LasUIE.
Zero-Shot Information Extraction via Chatting with ChatGPT
Feb 20, 2023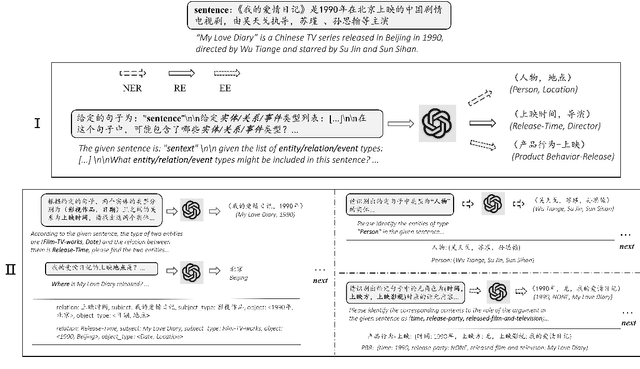
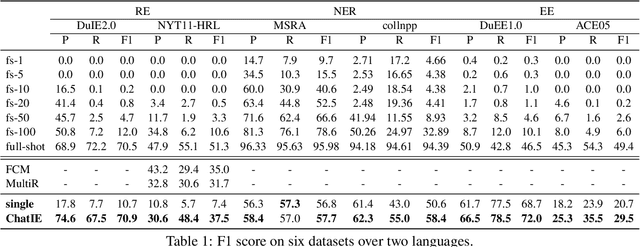


Zero-shot information extraction (IE) aims to build IE systems from the unannotated text. It is challenging due to involving little human intervention. Challenging but worthwhile, zero-shot IE reduces the time and effort that data labeling takes. Recent efforts on large language models (LLMs, e.g., GPT-3, ChatGPT) show promising performance on zero-shot settings, thus inspiring us to explore prompt-based methods. In this work, we ask whether strong IE models can be constructed by directly prompting LLMs. Specifically, we transform the zero-shot IE task into a multi-turn question-answering problem with a two-stage framework (ChatIE). With the power of ChatGPT, we extensively evaluate our framework on three IE tasks: entity-relation triple extract, named entity recognition, and event extraction. Empirical results on six datasets across two languages show that ChatIE achieves impressive performance and even surpasses some full-shot models on several datasets (e.g., NYT11-HRL). We believe that our work could shed light on building IE models with limited resources.
A Contextualized Real-Time Multimodal Emotion Recognition for Conversational Agents using Graph Convolutional Networks in Reinforcement Learning
Oct 24, 2023Owing to the recent developments in Generative Artificial Intelligence (GenAI) and Large Language Models (LLM), conversational agents are becoming increasingly popular and accepted. They provide a human touch by interacting in ways familiar to us and by providing support as virtual companions. Therefore, it is important to understand the user's emotions in order to respond considerately. Compared to the standard problem of emotion recognition, conversational agents face an additional constraint in that recognition must be real-time. Studies on model architectures using audio, visual, and textual modalities have mainly focused on emotion classification using full video sequences that do not provide online features. In this work, we present a novel paradigm for contextualized Emotion Recognition using Graph Convolutional Network with Reinforcement Learning (conER-GRL). Conversations are partitioned into smaller groups of utterances for effective extraction of contextual information. The system uses Gated Recurrent Units (GRU) to extract multimodal features from these groups of utterances. More importantly, Graph Convolutional Networks (GCN) and Reinforcement Learning (RL) agents are cascade trained to capture the complex dependencies of emotion features in interactive scenarios. Comparing the results of the conER-GRL model with other state-of-the-art models on the benchmark dataset IEMOCAP demonstrates the advantageous capabilities of the conER-GRL architecture in recognizing emotions in real-time from multimodal conversational signals.