 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
A Unique Training Strategy to Enhance Language Models Capabilities for Health Mention Detection from Social Media Content
Oct 29, 2023
An ever-increasing amount of social media content requires advanced AI-based computer programs capable of extracting useful information. Specifically, the extraction of health-related content from social media is useful for the development of diverse types of applications including disease spread, mortality rate prediction, and finding the impact of diverse types of drugs on diverse types of diseases. Language models are competent in extracting the syntactic and semantics of text. However, they face a hard time extracting similar patterns from social media texts. The primary reason for this shortfall lies in the non-standardized writing style commonly employed by social media users. Following the need for an optimal language model competent in extracting useful patterns from social media text, the key goal of this paper is to train language models in such a way that they learn to derive generalized patterns. The key goal is achieved through the incorporation of random weighted perturbation and contrastive learning strategies. On top of a unique training strategy, a meta predictor is proposed that reaps the benefits of 5 different language models for discriminating posts of social media text into non-health and health-related classes. Comprehensive experimentation across 3 public benchmark datasets reveals that the proposed training strategy improves the performance of the language models up to 3.87%, in terms of F1-score, as compared to their performance with traditional training. Furthermore, the proposed meta predictor outperforms existing health mention classification predictors across all 3 benchmark datasets.
DOMINO: A Dual-System for Multi-step Visual Language Reasoning
Oct 04, 2023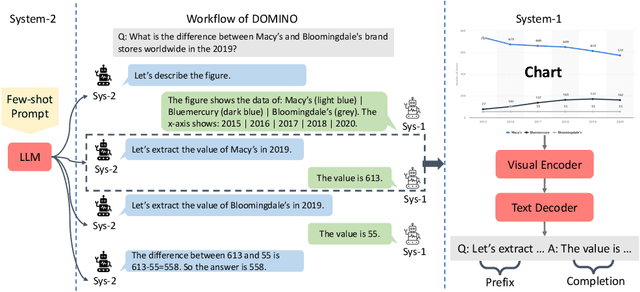
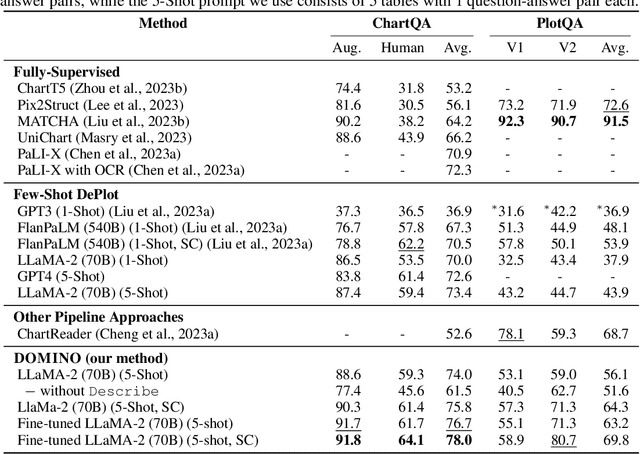
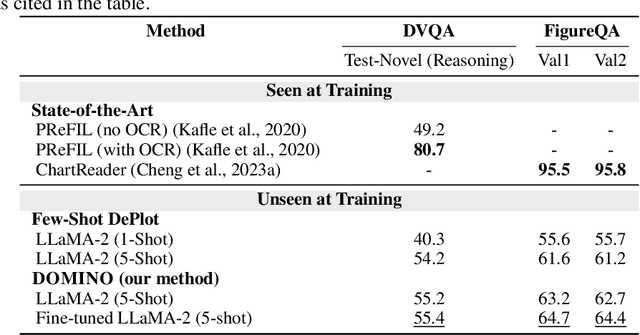
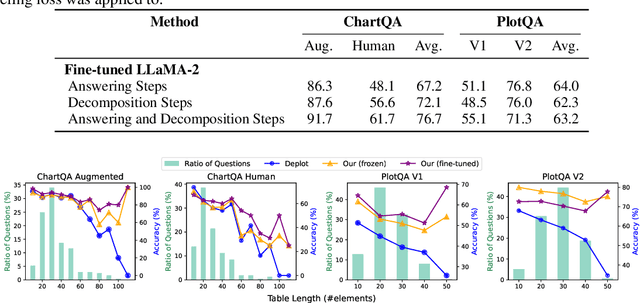
Visual language reasoning requires a system to extract text or numbers from information-dense images like charts or plots and perform logical or arithmetic reasoning to arrive at an answer. To tackle this task, existing work relies on either (1) an end-to-end vision-language model trained on a large amount of data, or (2) a two-stage pipeline where a captioning model converts the image into text that is further read by another large language model to deduce the answer. However, the former approach forces the model to answer a complex question with one single step, and the latter approach is prone to inaccurate or distracting information in the converted text that can confuse the language model. In this work, we propose a dual-system for multi-step multimodal reasoning, which consists of a "System-1" step for visual information extraction and a "System-2" step for deliberate reasoning. Given an input, System-2 breaks down the question into atomic sub-steps, each guiding System-1 to extract the information required for reasoning from the image. Experiments on chart and plot datasets show that our method with a pre-trained System-2 module performs competitively compared to prior work on in- and out-of-distribution data. By fine-tuning the System-2 module (LLaMA-2 70B) on only a small amount of data on multi-step reasoning, the accuracy of our method is further improved and surpasses the best fully-supervised end-to-end approach by 5.7% and a pipeline approach with FlanPaLM (540B) by 7.5% on a challenging dataset with human-authored questions.
SS-MAE: Spatial-Spectral Masked Auto-Encoder for Multi-Source Remote Sensing Image Classification
Nov 08, 2023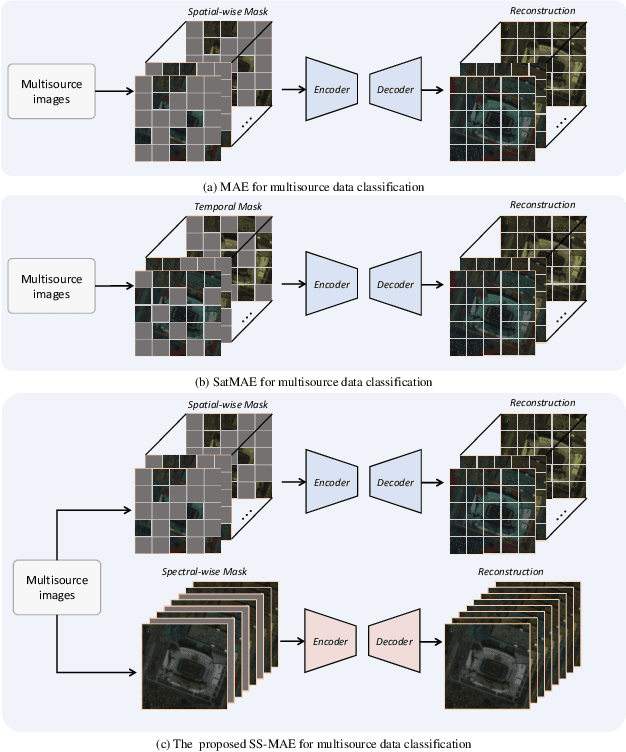

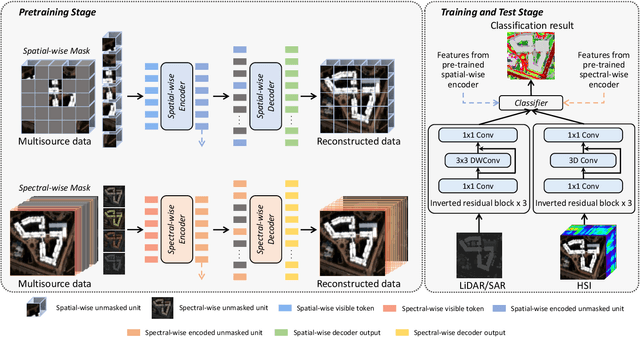
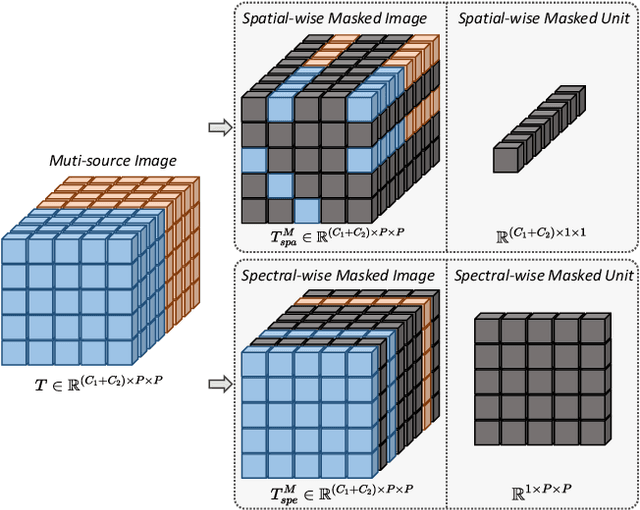
Masked image modeling (MIM) is a highly popular and effective self-supervised learning method for image understanding. Existing MIM-based methods mostly focus on spatial feature modeling, neglecting spectral feature modeling. Meanwhile, existing MIM-based methods use Transformer for feature extraction, some local or high-frequency information may get lost. To this end, we propose a spatial-spectral masked auto-encoder (SS-MAE) for HSI and LiDAR/SAR data joint classification. Specifically, SS-MAE consists of a spatial-wise branch and a spectral-wise branch. The spatial-wise branch masks random patches and reconstructs missing pixels, while the spectral-wise branch masks random spectral channels and reconstructs missing channels. Our SS-MAE fully exploits the spatial and spectral representations of the input data. Furthermore, to complement local features in the training stage, we add two lightweight CNNs for feature extraction. Both global and local features are taken into account for feature modeling. To demonstrate the effectiveness of the proposed SS-MAE, we conduct extensive experiments on three publicly available datasets. Extensive experiments on three multi-source datasets verify the superiority of our SS-MAE compared with several state-of-the-art baselines. The source codes are available at \url{https://github.com/summitgao/SS-MAE}.
StructChart: Perception, Structuring, Reasoning for Visual Chart Understanding
Sep 25, 2023
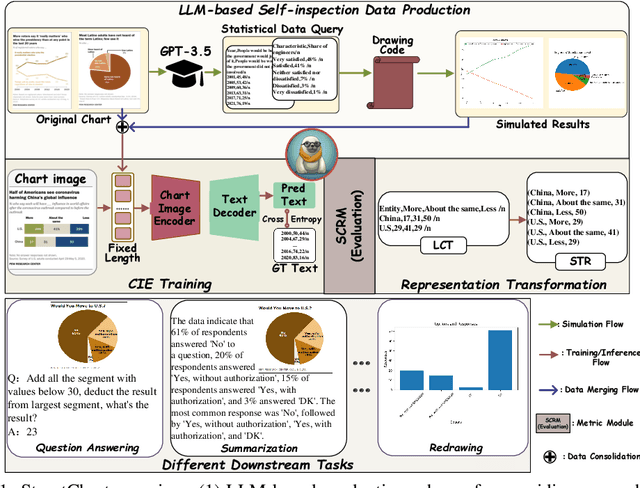
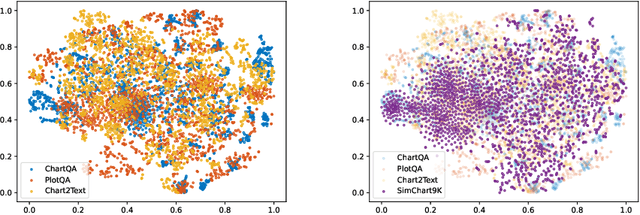
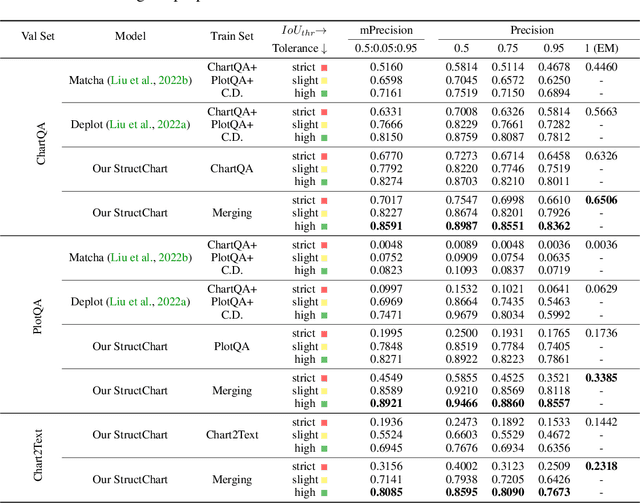
Charts are common in literature across different scientific fields, conveying rich information easily accessible to readers. Current chart-related tasks focus on either chart perception which refers to extracting information from the visual charts, or performing reasoning given the extracted data, e.g. in a tabular form. In this paper, we aim to establish a unified and label-efficient learning paradigm for joint perception and reasoning tasks, which can be generally applicable to different downstream tasks, beyond the question-answering task as specifically studied in peer works. Specifically, StructChart first reformulates the chart information from the popular tubular form (specifically linearized CSV) to the proposed Structured Triplet Representations (STR), which is more friendly for reducing the task gap between chart perception and reasoning due to the employed structured information extraction for charts. We then propose a Structuring Chart-oriented Representation Metric (SCRM) to quantitatively evaluate the performance for the chart perception task. To enrich the dataset for training, we further explore the possibility of leveraging the Large Language Model (LLM), enhancing the chart diversity in terms of both chart visual style and its statistical information. Extensive experiments are conducted on various chart-related tasks, demonstrating the effectiveness and promising potential for a unified chart perception-reasoning paradigm to push the frontier of chart understanding.
Towards Safer Operations: An Expert-involved Dataset of High-Pressure Gas Incidents for Preventing Future Failures
Oct 23, 2023This paper introduces a new IncidentAI dataset for safety prevention. Different from prior corpora that usually contain a single task, our dataset comprises three tasks: named entity recognition, cause-effect extraction, and information retrieval. The dataset is annotated by domain experts who have at least six years of practical experience as high-pressure gas conservation managers. We validate the contribution of the dataset in the scenario of safety prevention. Preliminary results on the three tasks show that NLP techniques are beneficial for analyzing incident reports to prevent future failures. The dataset facilitates future research in NLP and incident management communities. The access to the dataset is also provided (the IncidentAI dataset is available at: https://github.com/Cinnamon/incident-ai-dataset).
MORTY: Structured Summarization for Targeted Information Extraction from Scholarly Articles
Dec 11, 2022Information extraction from scholarly articles is a challenging task due to the sizable document length and implicit information hidden in text, figures, and citations. Scholarly information extraction has various applications in exploration, archival, and curation services for digital libraries and knowledge management systems. We present MORTY, an information extraction technique that creates structured summaries of text from scholarly articles. Our approach condenses the article's full-text to property-value pairs as a segmented text snippet called structured summary. We also present a sizable scholarly dataset combining structured summaries retrieved from a scholarly knowledge graph and corresponding publicly available scientific articles, which we openly publish as a resource for the research community. Our results show that structured summarization is a suitable approach for targeted information extraction that complements other commonly used methods such as question answering and named entity recognition.
Sequential Action-Induced Invariant Representation for Reinforcement Learning
Sep 22, 2023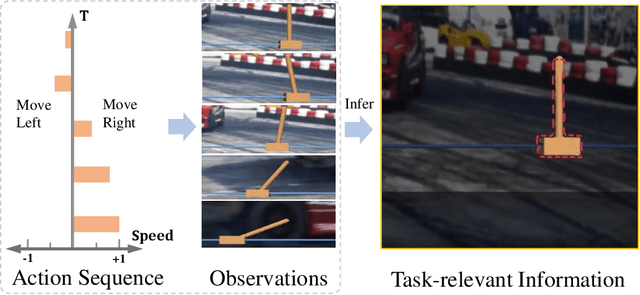

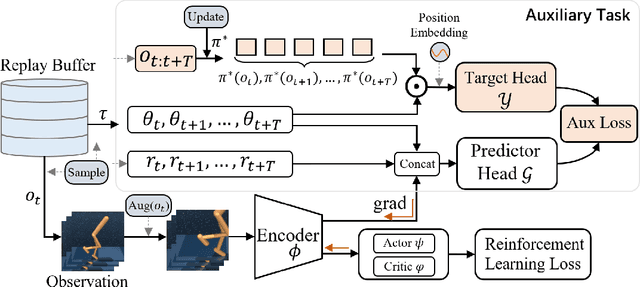

How to accurately learn task-relevant state representations from high-dimensional observations with visual distractions is a realistic and challenging problem in visual reinforcement learning. Recently, unsupervised representation learning methods based on bisimulation metrics, contrast, prediction, and reconstruction have shown the ability for task-relevant information extraction. However, due to the lack of appropriate mechanisms for the extraction of task information in the prediction, contrast, and reconstruction-related approaches and the limitations of bisimulation-related methods in domains with sparse rewards, it is still difficult for these methods to be effectively extended to environments with distractions. To alleviate these problems, in the paper, the action sequences, which contain task-intensive signals, are incorporated into representation learning. Specifically, we propose a Sequential Action--induced invariant Representation (SAR) method, in which the encoder is optimized by an auxiliary learner to only preserve the components that follow the control signals of sequential actions, so the agent can be induced to learn the robust representation against distractions. We conduct extensive experiments on the DeepMind Control suite tasks with distractions while achieving the best performance over strong baselines. We also demonstrate the effectiveness of our method at disregarding task-irrelevant information by deploying SAR to real-world CARLA-based autonomous driving with natural distractions. Finally, we provide the analysis results of generalization drawn from the generalization decay and t-SNE visualization. Code and demo videos are available at https://github.com/DMU-XMU/SAR.git.
Résumé Parsing as Hierarchical Sequence Labeling: An Empirical Study
Sep 13, 2023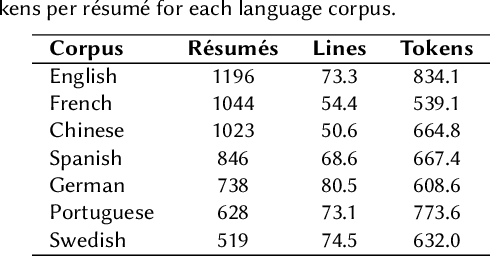
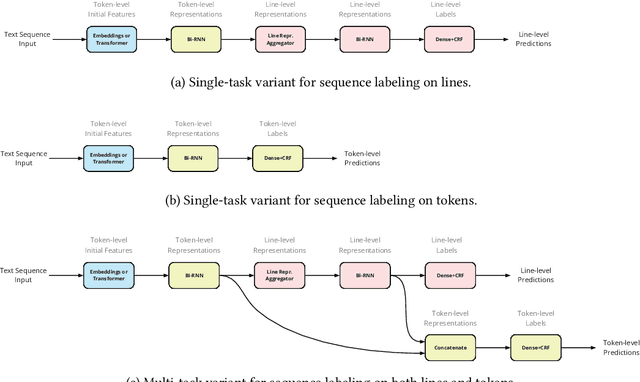
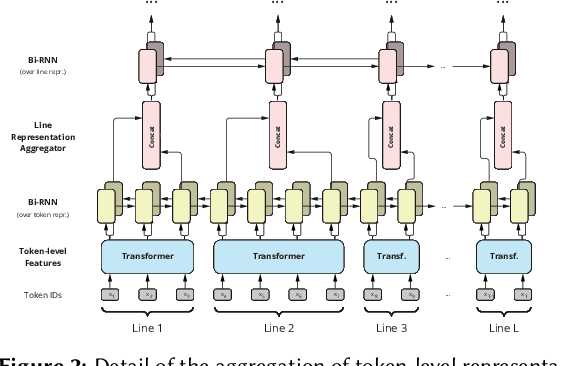
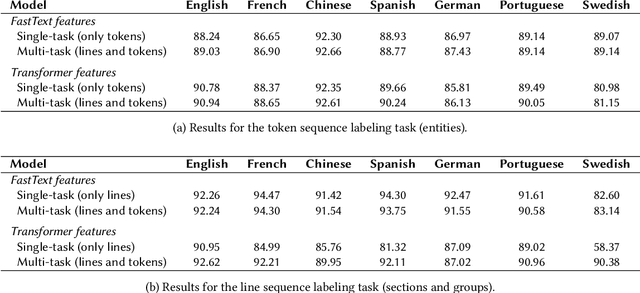
Extracting information from r\'esum\'es is typically formulated as a two-stage problem, where the document is first segmented into sections and then each section is processed individually to extract the target entities. Instead, we cast the whole problem as sequence labeling in two levels -- lines and tokens -- and study model architectures for solving both tasks simultaneously. We build high-quality r\'esum\'e parsing corpora in English, French, Chinese, Spanish, German, Portuguese, and Swedish. Based on these corpora, we present experimental results that demonstrate the effectiveness of the proposed models for the information extraction task, outperforming approaches introduced in previous work. We conduct an ablation study of the proposed architectures. We also analyze both model performance and resource efficiency, and describe the trade-offs for model deployment in the context of a production environment.
BitCoin: Bidirectional Tagging and Supervised Contrastive Learning based Joint Relational Triple Extraction Framework
Sep 21, 2023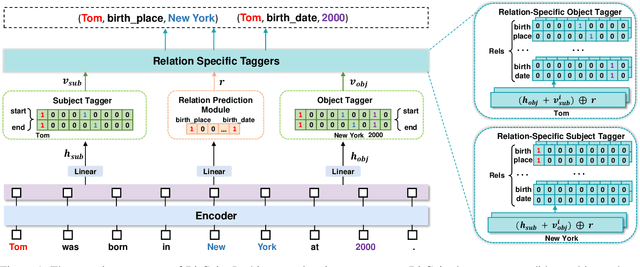
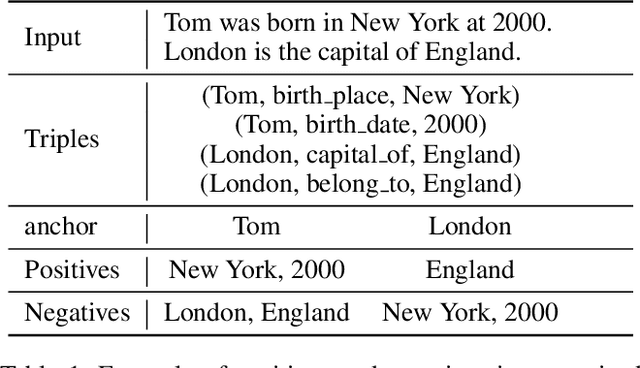

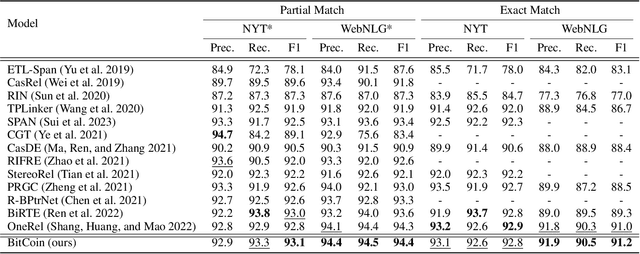
Relation triple extraction (RTE) is an essential task in information extraction and knowledge graph construction. Despite recent advancements, existing methods still exhibit certain limitations. They just employ generalized pre-trained models and do not consider the specificity of RTE tasks. Moreover, existing tagging-based approaches typically decompose the RTE task into two subtasks, initially identifying subjects and subsequently identifying objects and relations. They solely focus on extracting relational triples from subject to object, neglecting that once the extraction of a subject fails, it fails in extracting all triples associated with that subject. To address these issues, we propose BitCoin, an innovative Bidirectional tagging and supervised Contrastive learning based joint relational triple extraction framework. Specifically, we design a supervised contrastive learning method that considers multiple positives per anchor rather than restricting it to just one positive. Furthermore, a penalty term is introduced to prevent excessive similarity between the subject and object. Our framework implements taggers in two directions, enabling triples extraction from subject to object and object to subject. Experimental results show that BitCoin achieves state-of-the-art results on the benchmark datasets and significantly improves the F1 score on Normal, SEO, EPO, and multiple relation extraction tasks.
RexUIE: A Recursive Method with Explicit Schema Instructor for Universal Information Extraction
Apr 28, 2023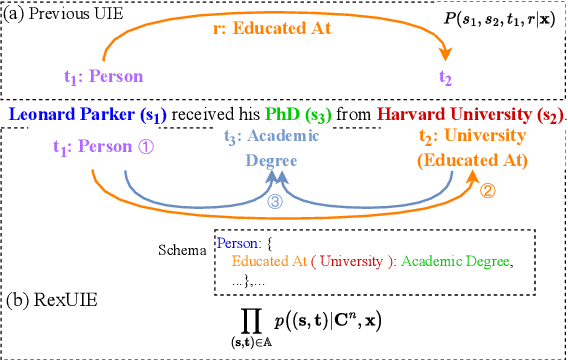
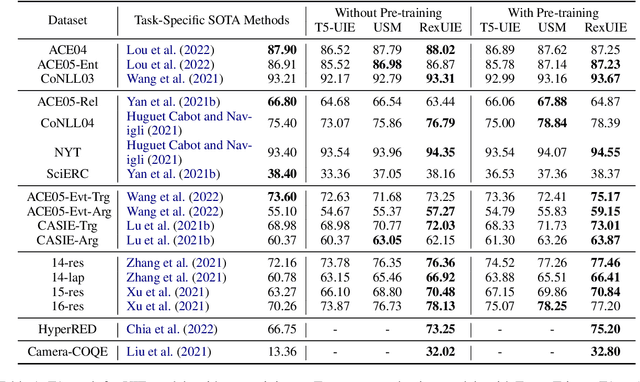
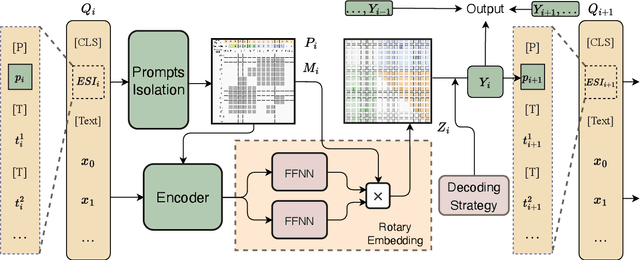
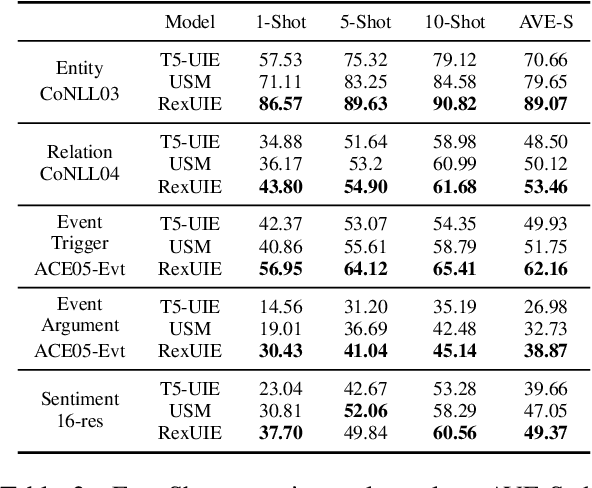
Universal Information Extraction (UIE) is an area of interest due to the challenges posed by varying targets, heterogeneous structures, and demand-specific schemas. However, previous works have only achieved limited success by unifying a few tasks, such as Named Entity Recognition (NER) and Relation Extraction (RE), which fall short of being authentic UIE models particularly when extracting other general schemas such as quadruples and quintuples. Additionally, these models used an implicit structural schema instructor, which could lead to incorrect links between types, hindering the model's generalization and performance in low-resource scenarios. In this paper, we redefine the authentic UIE with a formal formulation that encompasses almost all extraction schemas. To the best of our knowledge, we are the first to introduce UIE for any kind of schemas. In addition, we propose RexUIE, which is a Recursive Method with Explicit Schema Instructor for UIE. To avoid interference between different types, we reset the position ids and attention mask matrices. RexUIE shows strong performance under both full-shot and few-shot settings and achieves State-of-the-Art results on the tasks of extracting complex schemas.