 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Data Efficient Training of a U-Net Based Architecture for Structured Documents Localization
Oct 02, 2023

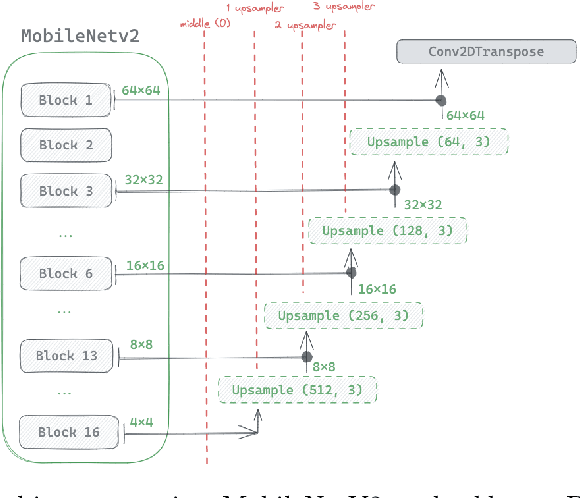


Structured documents analysis and recognition are essential for modern online on-boarding processes, and document localization is a crucial step to achieve reliable key information extraction. While deep-learning has become the standard technique used to solve document analysis problems, real-world applications in industry still face the limited availability of labelled data and of computational resources when training or fine-tuning deep-learning models. To tackle these challenges, we propose SDL-Net: a novel U-Net like encoder-decoder architecture for the localization of structured documents. Our approach allows pre-training the encoder of SDL-Net on a generic dataset containing samples of various document classes, and enables fast and data-efficient fine-tuning of decoders to support the localization of new document classes. We conduct extensive experiments on a proprietary dataset of structured document images to demonstrate the effectiveness and the generalization capabilities of the proposed approach.
CVE-driven Attack Technique Prediction with Semantic Information Extraction and a Domain-specific Language Model
Sep 06, 2023
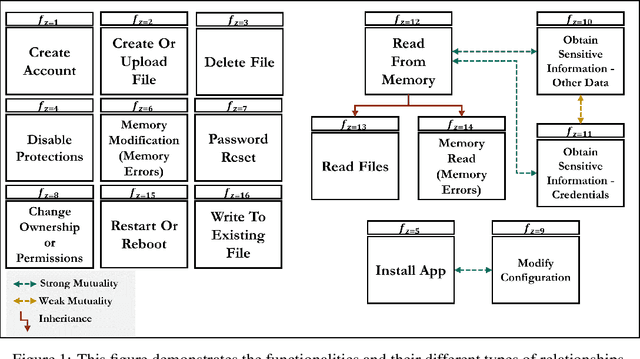
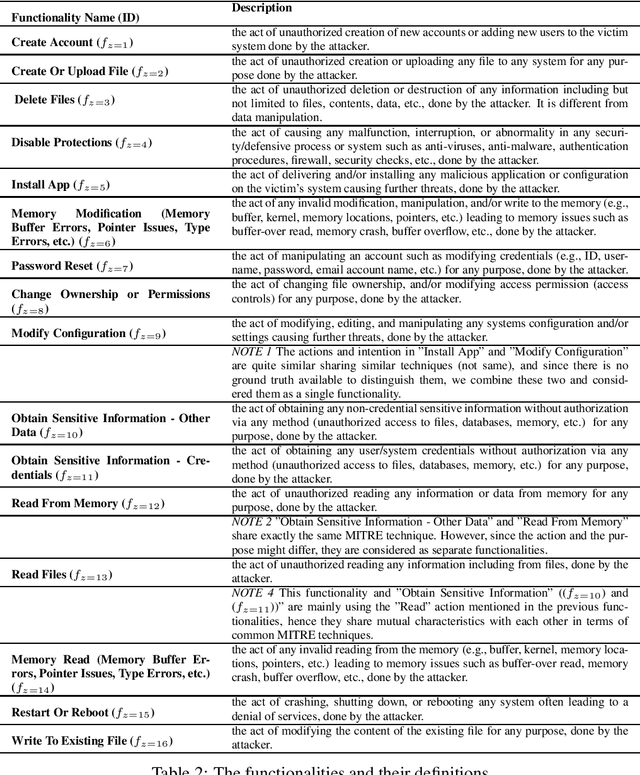

This paper addresses a critical challenge in cybersecurity: the gap between vulnerability information represented by Common Vulnerabilities and Exposures (CVEs) and the resulting cyberattack actions. CVEs provide insights into vulnerabilities, but often lack details on potential threat actions (tactics, techniques, and procedures, or TTPs) within the ATT&CK framework. This gap hinders accurate CVE categorization and proactive countermeasure initiation. The paper introduces the TTPpredictor tool, which uses innovative techniques to analyze CVE descriptions and infer plausible TTP attacks resulting from CVE exploitation. TTPpredictor overcomes challenges posed by limited labeled data and semantic disparities between CVE and TTP descriptions. It initially extracts threat actions from unstructured cyber threat reports using Semantic Role Labeling (SRL) techniques. These actions, along with their contextual attributes, are correlated with MITRE's attack functionality classes. This automated correlation facilitates the creation of labeled data, essential for categorizing novel threat actions into threat functionality classes and TTPs. The paper presents an empirical assessment, demonstrating TTPpredictor's effectiveness with accuracy rates of approximately 98% and F1-scores ranging from 95% to 98% in precise CVE classification to ATT&CK techniques. TTPpredictor outperforms state-of-the-art language model tools like ChatGPT. Overall, this paper offers a robust solution for linking CVEs to potential attack techniques, enhancing cybersecurity practitioners' ability to proactively identify and mitigate threats.
Modeling Entities as Semantic Points for Visual Information Extraction in the Wild
Mar 29, 2023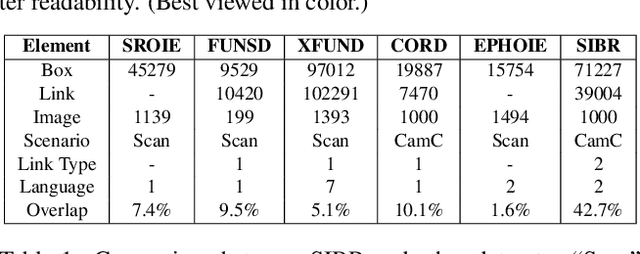
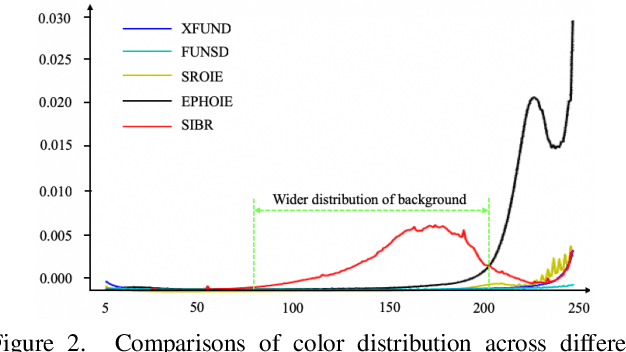
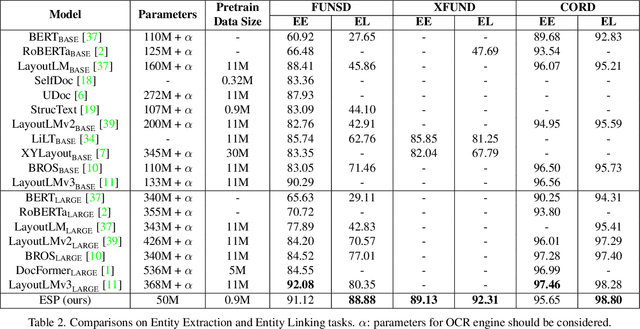
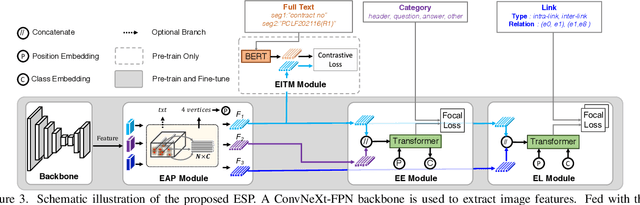
Recently, Visual Information Extraction (VIE) has been becoming increasingly important in both the academia and industry, due to the wide range of real-world applications. Previously, numerous works have been proposed to tackle this problem. However, the benchmarks used to assess these methods are relatively plain, i.e., scenarios with real-world complexity are not fully represented in these benchmarks. As the first contribution of this work, we curate and release a new dataset for VIE, in which the document images are much more challenging in that they are taken from real applications, and difficulties such as blur, partial occlusion, and printing shift are quite common. All these factors may lead to failures in information extraction. Therefore, as the second contribution, we explore an alternative approach to precisely and robustly extract key information from document images under such tough conditions. Specifically, in contrast to previous methods, which usually either incorporate visual information into a multi-modal architecture or train text spotting and information extraction in an end-to-end fashion, we explicitly model entities as semantic points, i.e., center points of entities are enriched with semantic information describing the attributes and relationships of different entities, which could largely benefit entity labeling and linking. Extensive experiments on standard benchmarks in this field as well as the proposed dataset demonstrate that the proposed method can achieve significantly enhanced performance on entity labeling and linking, compared with previous state-of-the-art models. Dataset is available at https://www.modelscope.cn/datasets/damo/SIBR/summary.
Natural Disaster Analysis using Satellite Imagery and Social-Media Data for Emergency Response Situations
Nov 16, 2023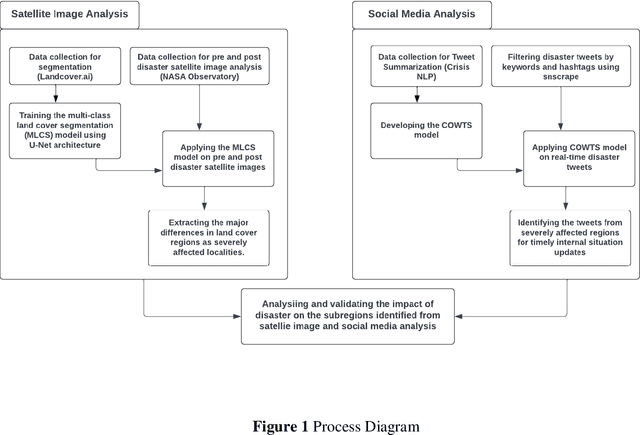


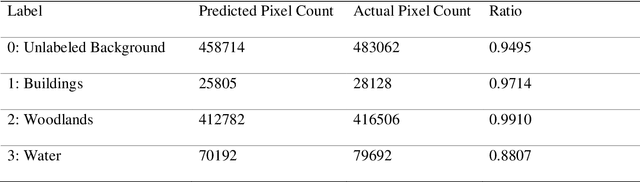
Disaster Management is one of the most promising research areas because of its significant economic, environmental and social repercussions. This research focuses on analyzing different types of data (pre and post satellite images and twitter data) related to disaster management for in-depth analysis of location-wise emergency requirements. This research has been divided into two stages, namely, satellite image analysis and twitter data analysis followed by integration using location. The first stage involves pre and post disaster satellite image analysis of the location using multi-class land cover segmentation technique based on U-Net architecture. The second stage focuses on mapping the region with essential information about the disaster situation and immediate requirements for relief operations. The severely affected regions are demarcated and twitter data is extracted using keywords respective to that location. The extraction of situational information from a large corpus of raw tweets adopts Content Word based Tweet Summarization (COWTS) technique. An integration of these modules using real-time location-based mapping and frequency analysis technique gathers multi-dimensional information in the advent of disaster occurrence such as the Kerala and Mississippi floods that were analyzed and validated as test cases. The novelty of this research lies in the application of segmented satellite images for disaster relief using highlighted land cover changes and integration of twitter data by mapping these region-specific filters for obtaining a complete overview of the disaster.
Advancing Italian Biomedical Information Extraction with Large Language Models: Methodological Insights and Multicenter Practical Application
Jun 08, 2023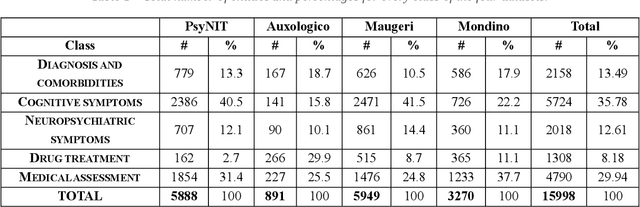
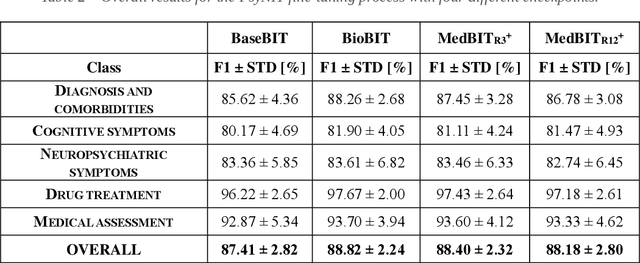
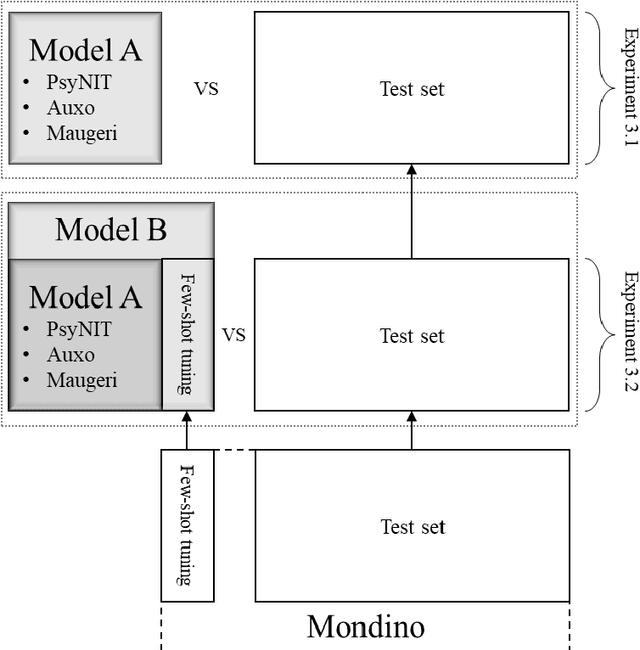
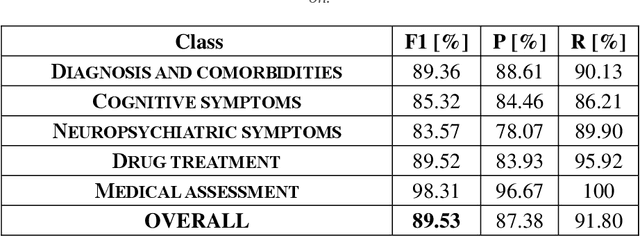
The introduction of computerized medical records in hospitals has reduced burdensome operations like manual writing and information fetching. However, the data contained in medical records are still far underutilized, primarily because extracting them from unstructured textual medical records takes time and effort. Information Extraction, a subfield of Natural Language Processing, can help clinical practitioners overcome this limitation, using automated text-mining pipelines. In this work, we created the first Italian neuropsychiatric Named Entity Recognition dataset, PsyNIT, and used it to develop a Large Language Model for this task. Moreover, we conducted several experiments with three external independent datasets to implement an effective multicenter model, with overall F1-score 84.77%, Precision 83.16%, Recall 86.44%. The lessons learned are: (i) the crucial role of a consistent annotation process and (ii) a fine-tuning strategy that combines classical methods with a "few-shot" approach. This allowed us to establish methodological guidelines that pave the way for future implementations in this field and allow Italian hospitals to tap into important research opportunities.
One Signal-Noise Separation based Wiener Filter for Magnetogastrogram
Nov 12, 2023Magnetogastrogram (MGG) signal frequency is about 0.05 Hz, the low-frequency environmental noise interference is serious and can be several times stronger in magnitude than the signals of interest and may severely impede the extraction of relevant information. Wiener filter is one classic denoising solution for biomagnetic applications. Since the reference channels are usually placed not far enough from the biomagnetic sources under test, they will inevitably detect the signals and the Wiener filters may produce ill-conditioned solutions. Considering the solutions to improve the signal-to-noise ratio (SNR) of Wiener filter output, there are few methods to separate the signals from the noises of the reference signal at the filter input. In this paper, a new signal processing framework called signal-noise separation based Wiener filter (SNSWF) is proposed that it separates the main noise as the input signal of the filter to improve the output SNR of Wiener filter. The filter was successfully applied to the noise suppression for MGG signal detection. Using the SNSWF, the filter SNR is 16.7 dB better than the classic Wiener filter.
CARLG: Leveraging Contextual Clues and Role Correlations for Improving Document-level Event Argument Extraction
Oct 08, 2023
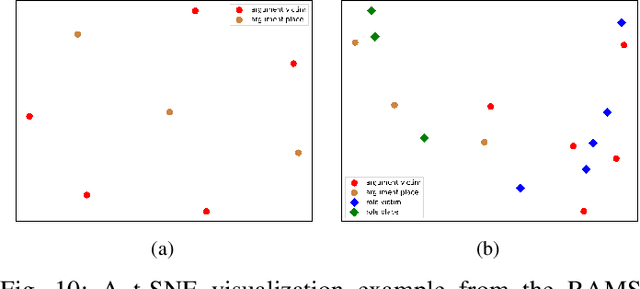
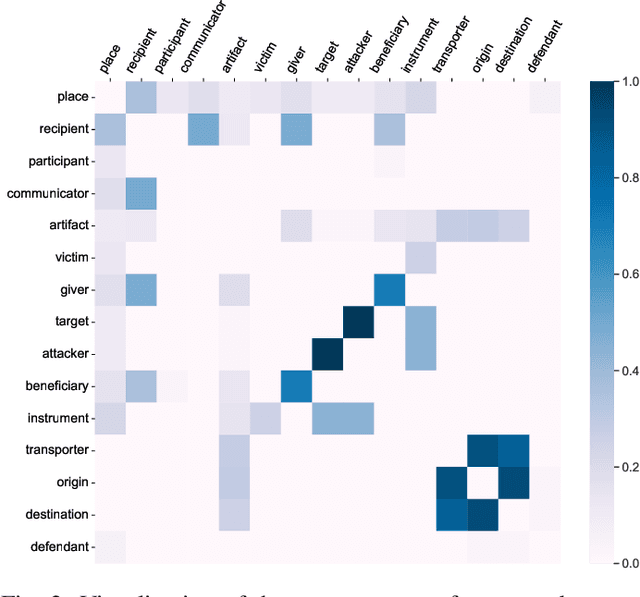
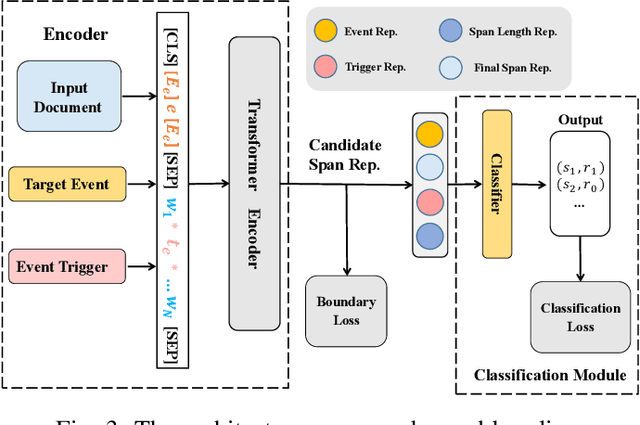
Document-level event argument extraction (EAE) is a crucial but challenging subtask in information extraction. Most existing approaches focus on the interaction between arguments and event triggers, ignoring two critical points: the information of contextual clues and the semantic correlations among argument roles. In this paper, we propose the CARLG model, which consists of two modules: Contextual Clues Aggregation (CCA) and Role-based Latent Information Guidance (RLIG), effectively leveraging contextual clues and role correlations for improving document-level EAE. The CCA module adaptively captures and integrates contextual clues by utilizing context attention weights from a pre-trained encoder. The RLIG module captures semantic correlations through role-interactive encoding and provides valuable information guidance with latent role representation. Notably, our CCA and RLIG modules are compact, transplantable and efficient, which introduce no more than 1% new parameters and can be easily equipped on other span-base methods with significant performance boost. Extensive experiments on the RAMS, WikiEvents, and MLEE datasets demonstrate the superiority of the proposed CARLG model. It outperforms previous state-of-the-art approaches by 1.26 F1, 1.22 F1, and 1.98 F1, respectively, while reducing the inference time by 31%. Furthermore, we provide detailed experimental analyses based on the performance gains and illustrate the interpretability of our model.
Burning the Adversarial Bridges: Robust Windows Malware Detection Against Binary-level Mutations
Oct 05, 2023Toward robust malware detection, we explore the attack surface of existing malware detection systems. We conduct root-cause analyses of the practical binary-level black-box adversarial malware examples. Additionally, we uncover the sensitivity of volatile features within the detection engines and exhibit their exploitability. Highlighting volatile information channels within the software, we introduce three software pre-processing steps to eliminate the attack surface, namely, padding removal, software stripping, and inter-section information resetting. Further, to counter the emerging section injection attacks, we propose a graph-based section-dependent information extraction scheme for software representation. The proposed scheme leverages aggregated information within various sections in the software to enable robust malware detection and mitigate adversarial settings. Our experimental results show that traditional malware detection models are ineffective against adversarial threats. However, the attack surface can be largely reduced by eliminating the volatile information. Therefore, we propose simple-yet-effective methods to mitigate the impacts of binary manipulation attacks. Overall, our graph-based malware detection scheme can accurately detect malware with an area under the curve score of 88.32\% and a score of 88.19% under a combination of binary manipulation attacks, exhibiting the efficiency of our proposed scheme.
SpACNN-LDVAE: Spatial Attention Convolutional Latent Dirichlet Variational Autoencoder for Hyperspectral Pixel Unmixing
Nov 17, 2023The Hyperspectral Unxming problem is to find the pure spectral signal of the underlying materials (endmembers) and their proportions (abundances). The proposed method builds upon the recently proposed method, Latent Dirichlet Variational Autoencoder (LDVAE). It assumes that abundances can be encoded as Dirichlet Distributions while mixed pixels and endmembers are represented by Multivariate Normal Distributions. However, LDVAE does not leverage spatial information present in an HSI; we propose an Isotropic CNN encoder with spatial attention to solve the hyperspectral unmixing problem. We evaluated our model on Samson, Hydice Urban, Cuprite, and OnTech-HSI-Syn-21 datasets. Our model also leverages the transfer learning paradigm for Cuprite Dataset, where we train the model on synthetic data and evaluate it on real-world data. We are able to observe the improvement in the results for the endmember extraction and abundance estimation by incorporating the spatial information. Code can be found at https://github.com/faisalqureshi/cnn-ldvae