 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Fusing Temporal Graphs into Transformers for Time-Sensitive Question Answering
Oct 30, 2023
Answering time-sensitive questions from long documents requires temporal reasoning over the times in questions and documents. An important open question is whether large language models can perform such reasoning solely using a provided text document, or whether they can benefit from additional temporal information extracted using other systems. We address this research question by applying existing temporal information extraction systems to construct temporal graphs of events, times, and temporal relations in questions and documents. We then investigate different approaches for fusing these graphs into Transformer models. Experimental results show that our proposed approach for fusing temporal graphs into input text substantially enhances the temporal reasoning capabilities of Transformer models with or without fine-tuning. Additionally, our proposed method outperforms various graph convolution-based approaches and establishes a new state-of-the-art performance on SituatedQA and three splits of TimeQA.
A Car Model Identification System for Streamlining the Automobile Sales Process
Oct 23, 2023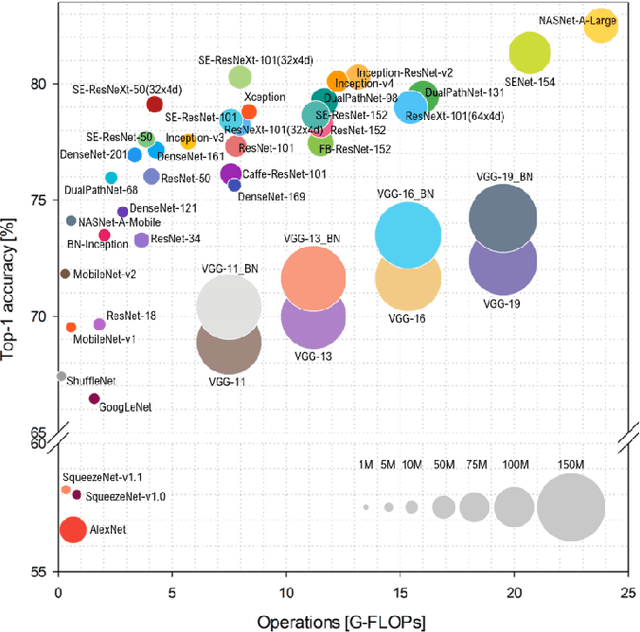
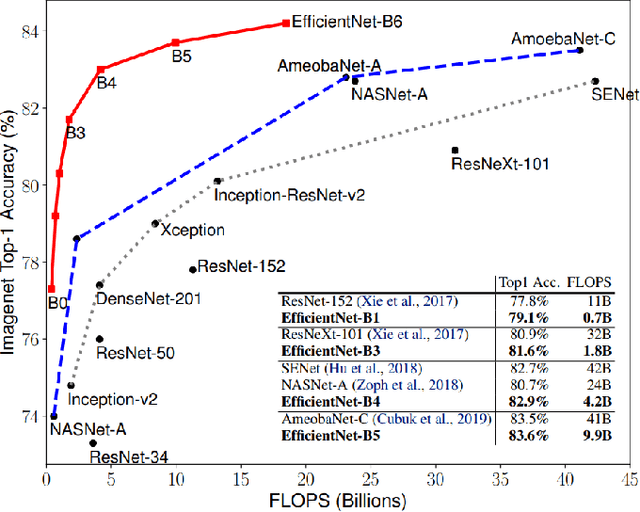
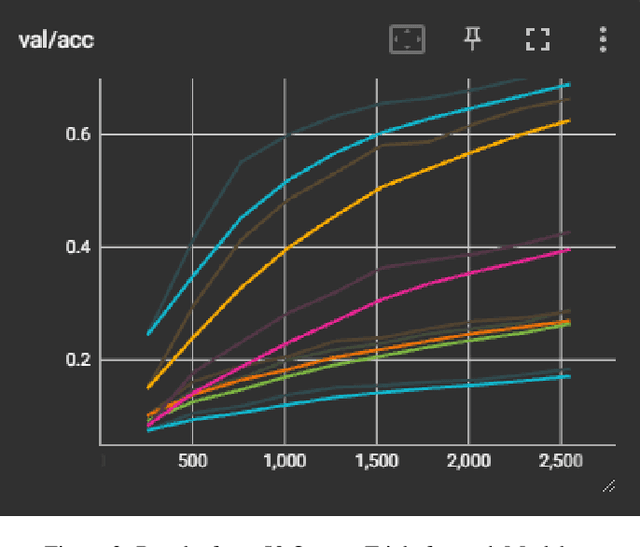
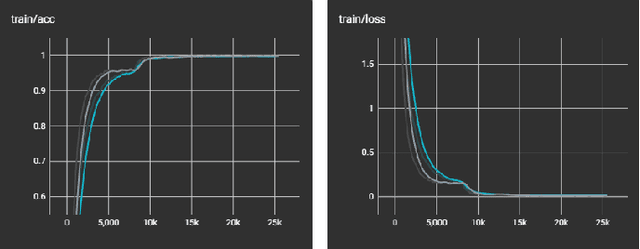
This project presents an automated solution for the efficient identification of car models and makes from images, aimed at streamlining the vehicle listing process on online car-selling platforms. Through a thorough exploration encompassing various efficient network architectures including Convolutional Neural Networks (CNNs), Vision Transformers (ViTs), and hybrid models, we achieved a notable accuracy of 81.97% employing the EfficientNet (V2 b2) architecture. To refine performance, a combination of strategies, including data augmentation, fine-tuning pretrained models, and extensive hyperparameter tuning, were applied. The trained model offers the potential for automating information extraction, promising enhanced user experiences across car-selling websites.
Deciphering 'What' and 'Where' Visual Pathways from Spectral Clustering of Layer-Distributed Neural Representations
Dec 11, 2023We present an approach for analyzing grouping information contained within a neural network's activations, permitting extraction of spatial layout and semantic segmentation from the behavior of large pre-trained vision models. Unlike prior work, our method conducts a wholistic analysis of a network's activation state, leveraging features from all layers and obviating the need to guess which part of the model contains relevant information. Motivated by classic spectral clustering, we formulate this analysis in terms of an optimization objective involving a set of affinity matrices, each formed by comparing features within a different layer. Solving this optimization problem using gradient descent allows our technique to scale from single images to dataset-level analysis, including, in the latter, both intra- and inter-image relationships. Analyzing a pre-trained generative transformer provides insight into the computational strategy learned by such models. Equating affinity with key-query similarity across attention layers yields eigenvectors encoding scene spatial layout, whereas defining affinity by value vector similarity yields eigenvectors encoding object identity. This result suggests that key and query vectors coordinate attentional information flow according to spatial proximity (a `where' pathway), while value vectors refine a semantic category representation (a `what' pathway).
ChiMed-GPT: A Chinese Medical Large Language Model with Full Training Regime and Better Alignment to Human Preferences
Nov 10, 2023
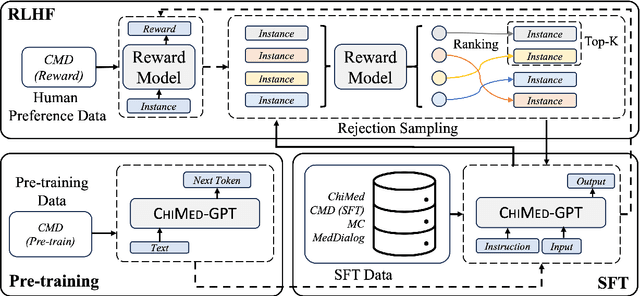

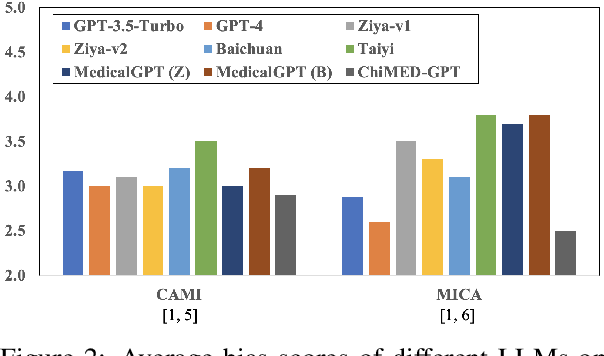
Recently, the increasing demand for superior medical services has highlighted the discrepancies in the medical infrastructure. With big data, especially texts, forming the foundation of medical services, there is an exigent need for effective natural language processing (NLP) solutions tailored to the healthcare domain. Conventional approaches leveraging pre-trained models present promising results in this domain and current large language models (LLMs) offer advanced foundation for medical text processing. However, most medical LLMs are trained only with supervised fine-tuning (SFT), even though it efficiently empowers LLMs to understand and respond to medical instructions but is ineffective in learning domain knowledge and aligning with human preference. Another engineering barrier that prevents current medical LLM from better text processing ability is their restricted context length (e.g., 2,048 tokens), making it hard for the LLMs to process long context, which is frequently required in the medical domain. In this work, we propose ChiMed-GPT, a new benchmark LLM designed explicitly for Chinese medical domain, with enlarged context length to 4,096 tokens and undergoes a comprehensive training regime with pre-training, SFT, and RLHF. Evaluations on real-world tasks including information extraction, question answering, and dialogue generation demonstrate ChiMed-GPT's superior performance over general domain LLMs. Furthermore, we analyze possible biases through prompting ChiMed-GPT to perform attitude scales regarding discrimination of patients, so as to contribute to further responsible development of LLMs in the medical domain. The code and model are released at https://github.com/synlp/ChiMed-GPT.
BioInstruct: Instruction Tuning of Large Language Models for Biomedical Natural Language Processing
Oct 30, 2023Large language models (LLMs) has achieved a great success in many natural language processing (NLP) tasks. This is achieved by pretraining of LLMs on vast amount of data and then instruction tuning to specific domains. However, only a few instructions in the biomedical domain have been published. To address this issue, we introduce BioInstruct, a customized task-specific instruction dataset containing more than 25,000 examples. This dataset was generated attractively by prompting a GPT-4 language model with a three-seed-sample of 80 human-curated instructions. By fine-tuning LLMs using the BioInstruct dataset, we aim to optimize the LLM's performance in biomedical natural language processing (BioNLP). We conducted instruction tuning on the LLaMA LLMs (1\&2, 7B\&13B) and evaluated them on BioNLP applications, including information extraction, question answering, and text generation. We also evaluated how instructions contributed to model performance using multi-tasking learning principles.
Dance of Channel and Sequence: An Efficient Attention-Based Approach for Multivariate Time Series Forecasting
Dec 11, 2023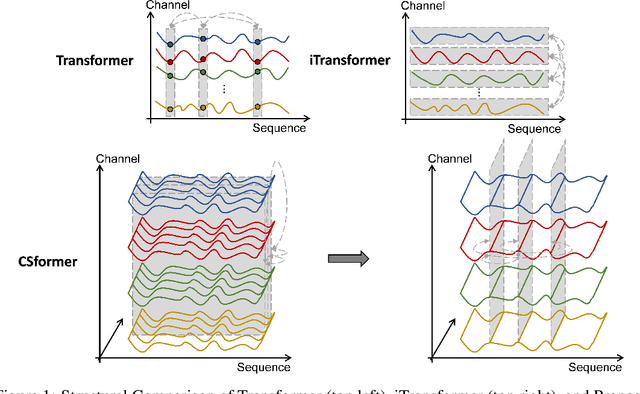

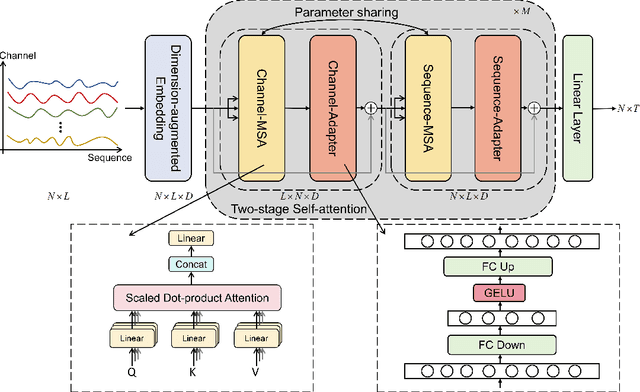
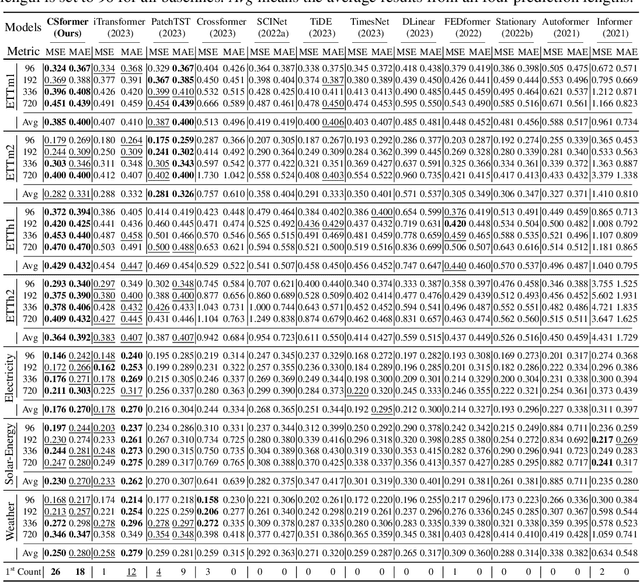
In recent developments, predictive models for multivariate time series analysis have exhibited commendable performance through the adoption of the prevalent principle of channel independence. Nevertheless, it is imperative to acknowledge the intricate interplay among channels, which fundamentally influences the outcomes of multivariate predictions. Consequently, the notion of channel independence, while offering utility to a certain extent, becomes increasingly impractical, leading to information degradation. In response to this pressing concern, we present CSformer, an innovative framework characterized by a meticulously engineered two-stage self-attention mechanism. This mechanism is purposefully designed to enable the segregated extraction of sequence-specific and channel-specific information, while sharing parameters to promote synergy and mutual reinforcement between sequences and channels. Simultaneously, we introduce sequence adapters and channel adapters, ensuring the model's ability to discern salient features across various dimensions. Rigorous experimentation, spanning multiple real-world datasets, underscores the robustness of our approach, consistently establishing its position at the forefront of predictive performance across all datasets. This augmentation substantially enhances the capacity for feature extraction inherent to multivariate time series data, facilitating a more comprehensive exploitation of the available information.
Preserving Knowledge Invariance: Rethinking Robustness Evaluation of Open Information Extraction
May 23, 2023
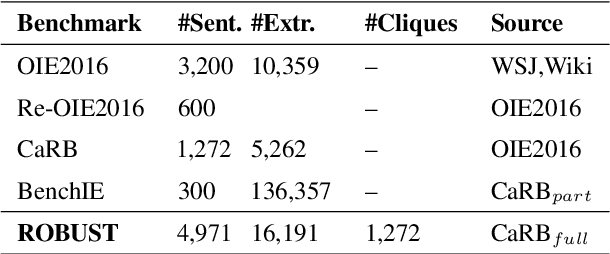
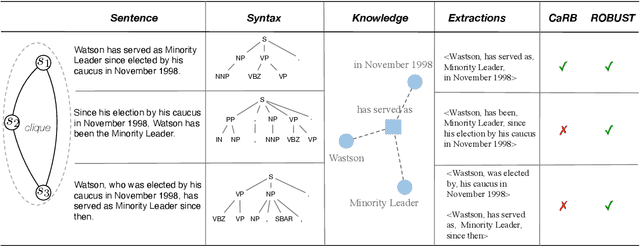
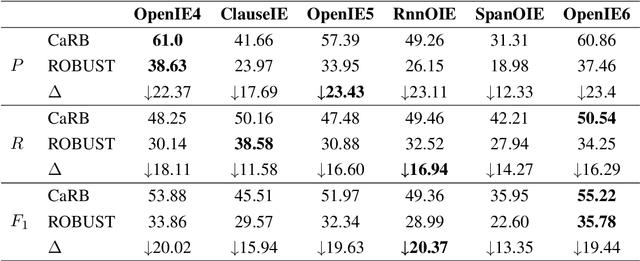
The robustness to distribution changes ensures that NLP models can be successfully applied in the realistic world, especially for information extraction tasks. However, most prior evaluation benchmarks have been devoted to validating pairwise matching correctness, ignoring the crucial measurement of robustness. In this paper, we present the first benchmark that simulates the evaluation of open information extraction models in the real world, where the syntactic and expressive distributions under the same knowledge meaning may drift variously. We design and annotate a large-scale testbed in which each example is a knowledge-invariant clique that consists of sentences with structured knowledge of the same meaning but with different syntactic and expressive forms. By further elaborating the robustness metric, a model is judged to be robust if its performance is consistently accurate on the overall cliques. We perform experiments on typical models published in the last decade as well as a popular large language model, the results show that the existing successful models exhibit a frustrating degradation, with a maximum drop of 23.43 F1 score. Our resources and code will be publicly available.
Visual Information Extraction in the Wild: Practical Dataset and End-to-end Solution
May 12, 2023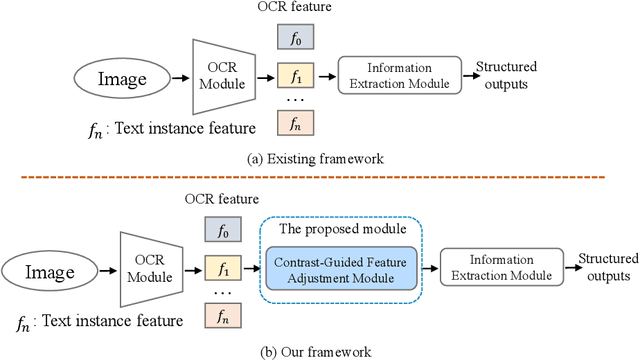

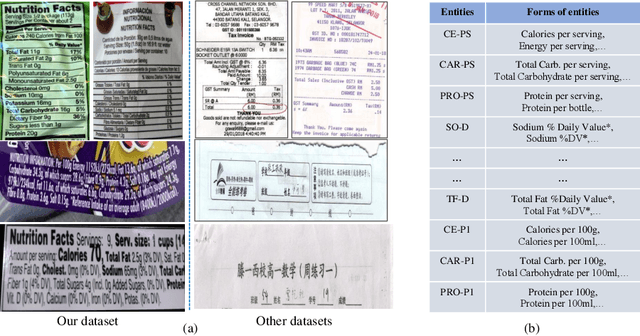
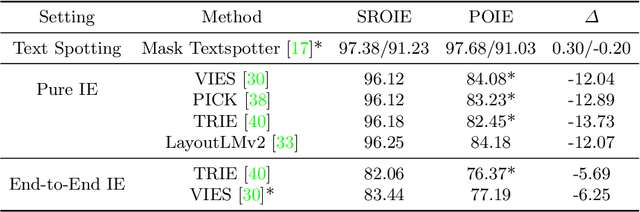
Visual information extraction (VIE), which aims to simultaneously perform OCR and information extraction in a unified framework, has drawn increasing attention due to its essential role in various applications like understanding receipts, goods, and traffic signs. However, as existing benchmark datasets for VIE mainly consist of document images without the adequate diversity of layout structures, background disturbs, and entity categories, they cannot fully reveal the challenges of real-world applications. In this paper, we propose a large-scale dataset consisting of camera images for VIE, which contains not only the larger variance of layout, backgrounds, and fonts but also much more types of entities. Besides, we propose a novel framework for end-to-end VIE that combines the stages of OCR and information extraction in an end-to-end learning fashion. Different from the previous end-to-end approaches that directly adopt OCR features as the input of an information extraction module, we propose to use contrastive learning to narrow the semantic gap caused by the difference between the tasks of OCR and information extraction. We evaluate the existing end-to-end methods for VIE on the proposed dataset and observe that the performance of these methods has a distinguishable drop from SROIE (a widely used English dataset) to our proposed dataset due to the larger variance of layout and entities. These results demonstrate our dataset is more practical for promoting advanced VIE algorithms. In addition, experiments demonstrate that the proposed VIE method consistently achieves the obvious performance gains on the proposed and SROIE datasets.
Investigating Deep-Learning NLP for Automating the Extraction of Oncology Efficacy Endpoints from Scientific Literature
Nov 03, 2023Benchmarking drug efficacy is a critical step in clinical trial design and planning. The challenge is that much of the data on efficacy endpoints is stored in scientific papers in free text form, so extraction of such data is currently a largely manual task. Our objective is to automate this task as much as possible. In this study we have developed and optimised a framework to extract efficacy endpoints from text in scientific papers, using a machine learning approach. Our machine learning model predicts 25 classes associated with efficacy endpoints and leads to high F1 scores (harmonic mean of precision and recall) of 96.4% on the test set, and 93.9% and 93.7% on two case studies. These methods were evaluated against - and showed strong agreement with - subject matter experts and show significant promise in the future of automating the extraction of clinical endpoints from free text. Clinical information extraction from text data is currently a laborious manual task which scales poorly and is prone to human error. Demonstrating the ability to extract efficacy endpoints automatically shows great promise for accelerating clinical trial design moving forwards.
Data-Free Distillation of Language Model by Text-to-Text Transfer
Nov 03, 2023Data-Free Knowledge Distillation (DFKD) plays a vital role in compressing the model when original training data is unavailable. Previous works for DFKD in NLP mainly focus on distilling encoder-only structures like BERT on classification tasks, which overlook the notable progress of generative language modeling. In this work, we propose a novel DFKD framework, namely DFKD-T$^{3}$, where the pretrained generative language model can also serve as a controllable data generator for model compression. This novel framework DFKD-T$^{3}$ leads to an end-to-end learnable text-to-text framework to transform the general domain corpus to compression-friendly task data, targeting to improve both the \textit{specificity} and \textit{diversity}. Extensive experiments show that our method can boost the distillation performance in various downstream tasks such as sentiment analysis, linguistic acceptability, and information extraction. Furthermore, we show that the generated texts can be directly used for distilling other language models and outperform the SOTA methods, making our method more appealing in a general DFKD setting. Our code is available at https://gitee.com/mindspore/models/tree/master/research/nlp/DFKD\_T3.