 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
PIVOINE: Instruction Tuning for Open-world Information Extraction
May 24, 2023
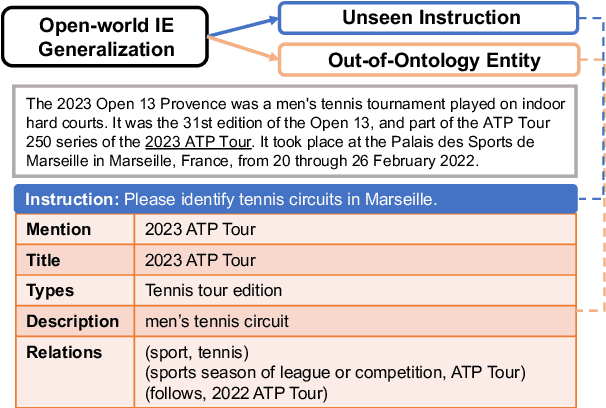

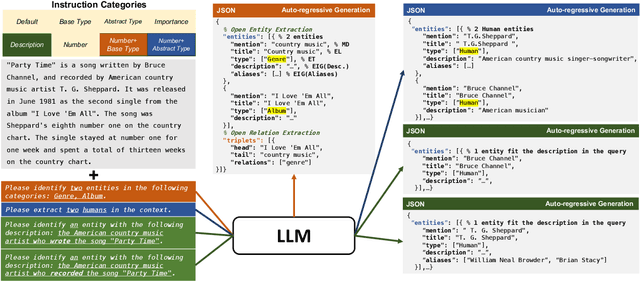
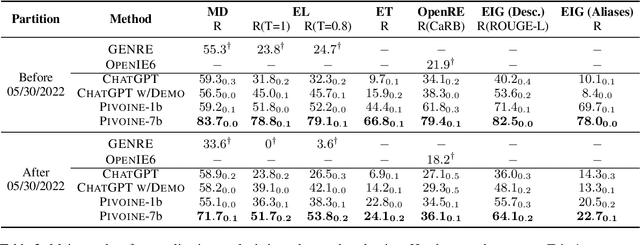
We consider the problem of Open-world Information Extraction (Open-world IE), which extracts comprehensive entity profiles from unstructured texts. Different from the conventional closed-world setting of Information Extraction (IE), Open-world IE considers a more general situation where entities and relations could be beyond a predefined ontology. More importantly, we seek to develop a large language model (LLM) that is able to perform Open-world IE to extract desirable entity profiles characterized by (possibly fine-grained) natural language instructions. We achieve this by finetuning LLMs using instruction tuning. In particular, we construct INSTRUCTOPENWIKI, a substantial instruction tuning dataset for Open-world IE enriched with a comprehensive corpus, extensive annotations, and diverse instructions. We finetune the pretrained BLOOM models on INSTRUCTOPENWIKI and obtain PIVOINE, an LLM for Open-world IE with strong instruction-following capabilities. Our experiments demonstrate that PIVOINE significantly outperforms traditional closed-world methods and other LLM baselines, displaying impressive generalization capabilities on both unseen instructions and out-of-ontology cases. Consequently, PIVOINE emerges as a promising solution to tackle the open-world challenge in IE effectively.
Leveraging Structured Information for Explainable Multi-hop Question Answering and Reasoning
Nov 07, 2023Neural models, including large language models (LLMs), achieve superior performance on multi-hop question-answering. To elicit reasoning capabilities from LLMs, recent works propose using the chain-of-thought (CoT) mechanism to generate both the reasoning chain and the answer, which enhances the model's capabilities in conducting multi-hop reasoning. However, several challenges still remain: such as struggling with inaccurate reasoning, hallucinations, and lack of interpretability. On the other hand, information extraction (IE) identifies entities, relations, and events grounded to the text. The extracted structured information can be easily interpreted by humans and machines (Grishman, 2019). In this work, we investigate constructing and leveraging extracted semantic structures (graphs) for multi-hop question answering, especially the reasoning process. Empirical results and human evaluations show that our framework: generates more faithful reasoning chains and substantially improves the QA performance on two benchmark datasets. Moreover, the extracted structures themselves naturally provide grounded explanations that are preferred by humans, as compared to the generated reasoning chains and saliency-based explanations.
InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction
Apr 17, 2023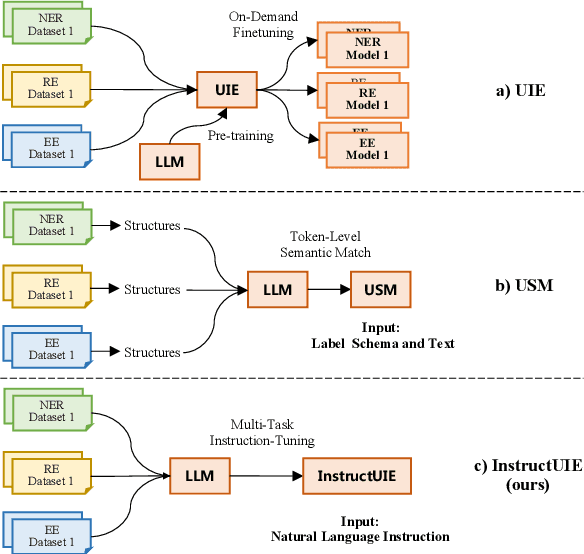
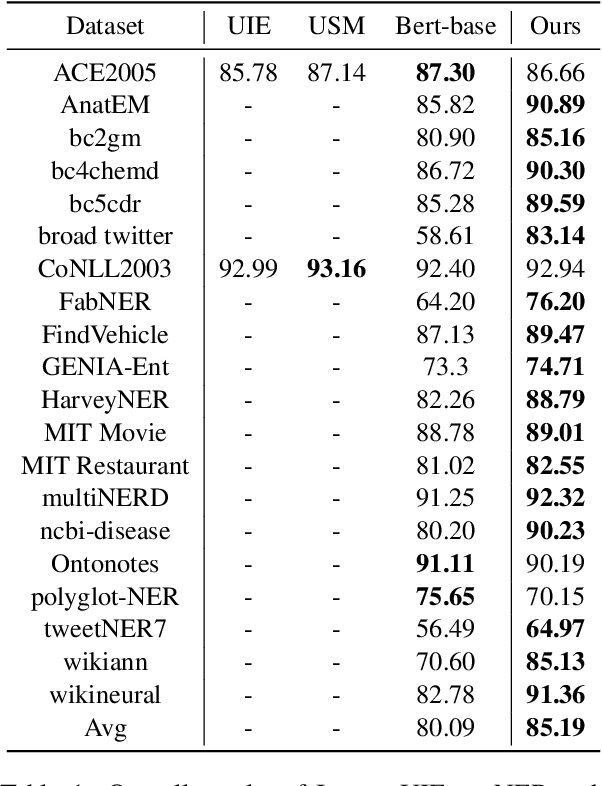
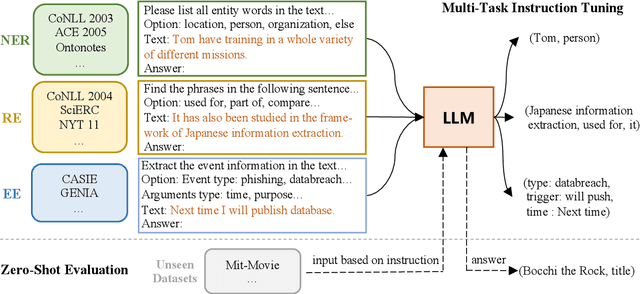
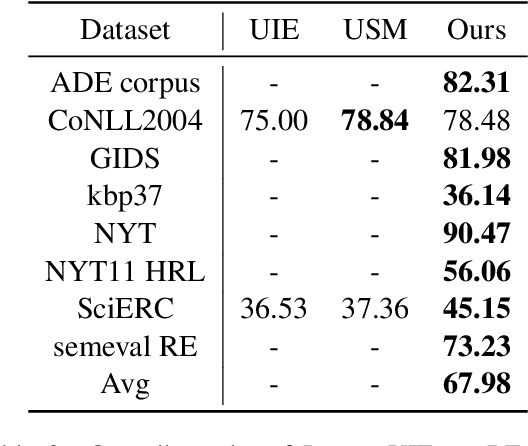
Large language models have unlocked strong multi-task capabilities from reading instructive prompts. However, recent studies have shown that existing large models still have difficulty with information extraction tasks. For example, gpt-3.5-turbo achieved an F1 score of 18.22 on the Ontonotes dataset, which is significantly lower than the state-of-the-art performance. In this paper, we propose InstructUIE, a unified information extraction framework based on instruction tuning, which can uniformly model various information extraction tasks and capture the inter-task dependency. To validate the proposed method, we introduce IE INSTRUCTIONS, a benchmark of 32 diverse information extraction datasets in a unified text-to-text format with expert-written instructions. Experimental results demonstrate that our method achieves comparable performance to Bert in supervised settings and significantly outperforms the state-of-the-art and gpt3.5 in zero-shot settings.
Chain of Thought with Explicit Evidence Reasoning for Few-shot Relation Extraction
Nov 10, 2023Few-shot relation extraction involves identifying the type of relationship between two specific entities within a text, using a limited number of annotated samples. A variety of solutions to this problem have emerged by applying meta-learning and neural graph techniques which typically necessitate a training process for adaptation. Recently, the strategy of in-context learning has been demonstrating notable results without the need of training. Few studies have already utilized in-context learning for zero-shot information extraction. Unfortunately, the evidence for inference is either not considered or implicitly modeled during the construction of chain-of-thought prompts. In this paper, we propose a novel approach for few-shot relation extraction using large language models, named CoT-ER, chain-of-thought with explicit evidence reasoning. In particular, CoT-ER first induces large language models to generate evidences using task-specific and concept-level knowledge. Then these evidences are explicitly incorporated into chain-of-thought prompting for relation extraction. Experimental results demonstrate that our CoT-ER approach (with 0% training data) achieves competitive performance compared to the fully-supervised (with 100% training data) state-of-the-art approach on the FewRel1.0 and FewRel2.0 datasets.
LOKE: Linked Open Knowledge Extraction for Automated Knowledge Graph Construction
Nov 15, 2023While the potential of Open Information Extraction (Open IE) for Knowledge Graph Construction (KGC) may seem promising, we find that the alignment of Open IE extraction results with existing knowledge graphs to be inadequate. The advent of Large Language Models (LLMs), especially the commercially available OpenAI models, have reset expectations for what is possible with deep learning models and have created a new field called prompt engineering. We investigate the use of GPT models and prompt engineering for knowledge graph construction with the Wikidata knowledge graph to address a similar problem to Open IE, which we call Open Knowledge Extraction (OKE) using an approach we call the Linked Open Knowledge Extractor (LOKE, pronounced like "Loki"). We consider the entity linking task essential to construction of real world knowledge graphs. We merge the CaRB benchmark scoring approach with data from the TekGen dataset for the LOKE task. We then show that a well engineered prompt, paired with a naive entity linking approach (which we call LOKE-GPT), outperforms AllenAI's OpenIE 4 implementation on the OKE task, although it over-generates triples compared to the reference set due to overall triple scarcity in the TekGen set. Through an analysis of entity linkability in the CaRB dataset, as well as outputs from OpenIE 4 and LOKE-GPT, we see that LOKE-GPT and the "silver" TekGen triples show that the task is significantly different in content from OIE, if not structure. Through this analysis and a qualitative analysis of sentence extractions via all methods, we found that LOKE-GPT extractions are of high utility for the KGC task and suitable for use in semi-automated extraction settings.
Resume Information Extraction via Post-OCR Text Processing
Jun 23, 2023Information extraction (IE), one of the main tasks of natural language processing (NLP), has recently increased importance in the use of resumes. In studies on the text to extract information from the CV, sentence classification was generally made using NLP models. In this study, it is aimed to extract information by classifying all of the text groups after pre-processing such as Optical Character Recognition (OCT) and object recognition with the YOLOv8 model of the resumes. The text dataset consists of 286 resumes collected for 5 different (education, experience, talent, personal and language) job descriptions in the IT industry. The dataset created for object recognition consists of 1198 resumes, which were collected from the open-source internet and labeled as sets of text. BERT, BERT-t, DistilBERT, RoBERTa and XLNet were used as models. F1 score variances were used to compare the model results. In addition, the YOLOv8 model has also been reported comparatively in itself. As a result of the comparison, DistilBERT was showed better results despite having a lower number of parameters than other models.
Universal Information Extraction with Meta-Pretrained Self-Retrieval
Jun 18, 2023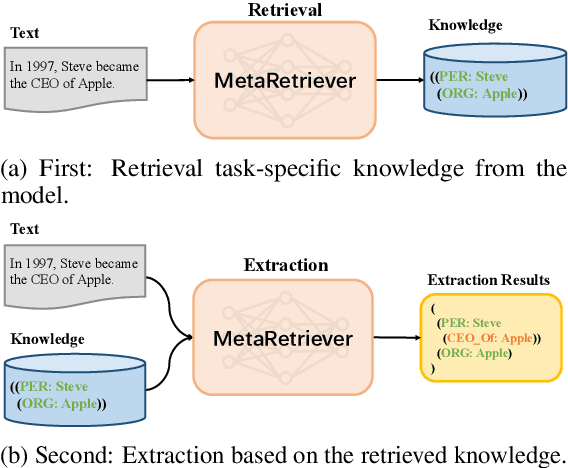
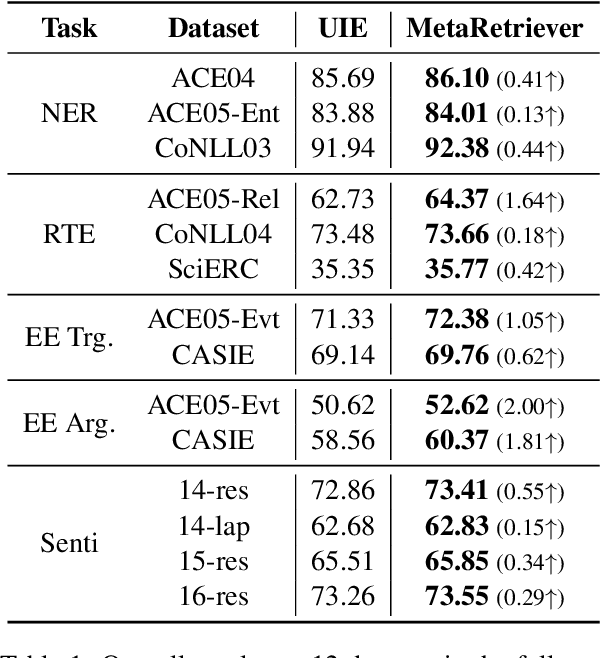

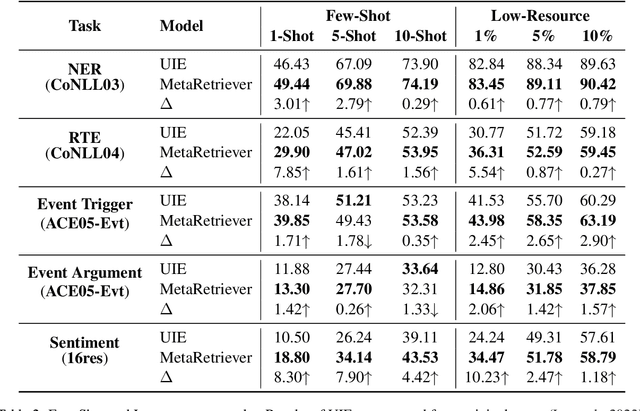
Universal Information Extraction~(Universal IE) aims to solve different extraction tasks in a uniform text-to-structure generation manner. Such a generation procedure tends to struggle when there exist complex information structures to be extracted. Retrieving knowledge from external knowledge bases may help models to overcome this problem but it is impossible to construct a knowledge base suitable for various IE tasks. Inspired by the fact that large amount of knowledge are stored in the pretrained language models~(PLM) and can be retrieved explicitly, in this paper, we propose MetaRetriever to retrieve task-specific knowledge from PLMs to enhance universal IE. As different IE tasks need different knowledge, we further propose a Meta-Pretraining Algorithm which allows MetaRetriever to quicktly achieve maximum task-specific retrieval performance when fine-tuning on downstream IE tasks. Experimental results show that MetaRetriever achieves the new state-of-the-art on 4 IE tasks, 12 datasets under fully-supervised, low-resource and few-shot scenarios.
Contrastive Deep Nonnegative Matrix Factorization for Community Detection
Nov 04, 2023Recently, nonnegative matrix factorization (NMF) has been widely adopted for community detection, because of its better interpretability. However, the existing NMF-based methods have the following three problems: 1) they directly transform the original network into community membership space, so it is difficult for them to capture the hierarchical information; 2) they often only pay attention to the topology of the network and ignore its node attributes; 3) it is hard for them to learn the global structure information necessary for community detection. Therefore, we propose a new community detection algorithm, named Contrastive Deep Nonnegative Matrix Factorization (CDNMF). Firstly, we deepen NMF to strengthen its capacity for information extraction. Subsequently, inspired by contrastive learning, our algorithm creatively constructs network topology and node attributes as two contrasting views. Furthermore, we utilize a debiased negative sampling layer and learn node similarity at the community level, thereby enhancing the suitability of our model for community detection. We conduct experiments on three public real graph datasets and the proposed model has achieved better results than state-of-the-art methods. Code available at https://github.com/6lyc/CDNMF.git.
Open Information Extraction via Chunks
May 05, 2023
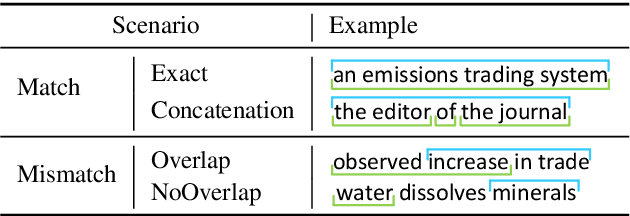
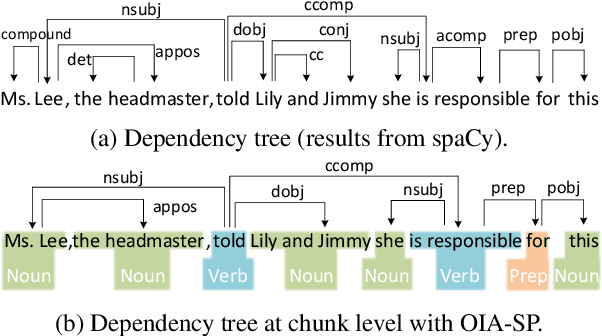
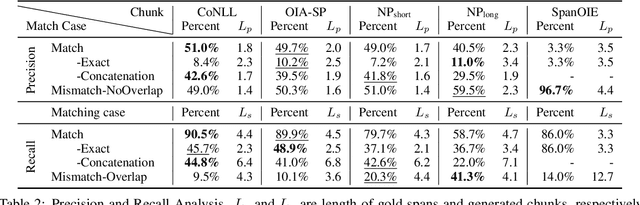
Open Information Extraction (OIE) aims to extract relational tuples from open-domain sentences. Existing OIE systems split a sentence into tokens and recognize token spans as tuple relations and arguments. We instead propose Sentence as Chunk sequence (SaC) and recognize chunk spans as tuple relations and arguments. We argue that SaC has better quantitative and qualitative properties for OIE than sentence as token sequence, and evaluate four choices of chunks (i.e., CoNLL chunks, simple phrases, NP chunks, and spans from SpanOIE) against gold OIE tuples. Accordingly, we propose a simple BERT-based model for sentence chunking, and propose Chunk-OIE for tuple extraction on top of SaC. Chunk-OIE achieves state-of-the-art results on multiple OIE datasets, showing that SaC benefits OIE task.
Fusing Temporal Graphs into Transformers for Time-Sensitive Question Answering
Oct 30, 2023Answering time-sensitive questions from long documents requires temporal reasoning over the times in questions and documents. An important open question is whether large language models can perform such reasoning solely using a provided text document, or whether they can benefit from additional temporal information extracted using other systems. We address this research question by applying existing temporal information extraction systems to construct temporal graphs of events, times, and temporal relations in questions and documents. We then investigate different approaches for fusing these graphs into Transformer models. Experimental results show that our proposed approach for fusing temporal graphs into input text substantially enhances the temporal reasoning capabilities of Transformer models with or without fine-tuning. Additionally, our proposed method outperforms various graph convolution-based approaches and establishes a new state-of-the-art performance on SituatedQA and three splits of TimeQA.