 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Perceptual Musical Features for Interpretable Audio Tagging
Dec 18, 2023
In the age of music streaming platforms, the task of automatically tagging music audio has garnered significant attention, driving researchers to devise methods aimed at enhancing performance metrics on standard datasets. Most recent approaches rely on deep neural networks, which, despite their impressive performance, possess opacity, making it challenging to elucidate their output for a given input. While the issue of interpretability has been emphasized in other fields like medicine, it has not received attention in music-related tasks. In this study, we explored the relevance of interpretability in the context of automatic music tagging. We constructed a workflow that incorporates three different information extraction techniques: a) leveraging symbolic knowledge, b) utilizing auxiliary deep neural networks, and c) employing signal processing to extract perceptual features from audio files. These features were subsequently used to train an interpretable machine-learning model for tag prediction. We conducted experiments on two datasets, namely the MTG-Jamendo dataset and the GTZAN dataset. Our method surpassed the performance of baseline models in both tasks and, in certain instances, demonstrated competitiveness with the current state-of-the-art. We conclude that there are use cases where the deterioration in performance is outweighed by the value of interpretability.
Encoder-minimal and Decoder-minimal Framework for Remote Sensing Image Dehazing
Dec 13, 2023Haze obscures remote sensing images, hindering valuable information extraction. To this end, we propose RSHazeNet, an encoder-minimal and decoder-minimal framework for efficient remote sensing image dehazing. Specifically, regarding the process of merging features within the same level, we develop an innovative module called intra-level transposed fusion module (ITFM). This module employs adaptive transposed self-attention to capture comprehensive context-aware information, facilitating the robust context-aware feature fusion. Meanwhile, we present a cross-level multi-view interaction module (CMIM) to enable effective interactions between features from various levels, mitigating the loss of information due to the repeated sampling operations. In addition, we propose a multi-view progressive extraction block (MPEB) that partitions the features into four distinct components and employs convolution with varying kernel sizes, groups, and dilation factors to facilitate view-progressive feature learning. Extensive experiments demonstrate the superiority of our proposed RSHazeNet. We release the source code and all pre-trained models at \url{https://github.com/chdwyb/RSHazeNet}.
Lazy-k: Decoding for Constrained Token Classification
Dec 06, 2023We explore the possibility of improving probabilistic models in structured prediction. Specifically, we combine the models with constrained decoding approaches in the context of token classification for information extraction. The decoding methods search for constraint-satisfying label-assignments while maximizing the total probability. To do this, we evaluate several existing approaches, as well as propose a novel decoding method called Lazy-$k$. Our findings demonstrate that constrained decoding approaches can significantly improve the models' performances, especially when using smaller models. The Lazy-$k$ approach allows for more flexibility between decoding time and accuracy. The code for using Lazy-$k$ decoding can be found here: https://github.com/ArthurDevNL/lazyk.
RadGraph2: Modeling Disease Progression in Radiology Reports via Hierarchical Information Extraction
Aug 09, 2023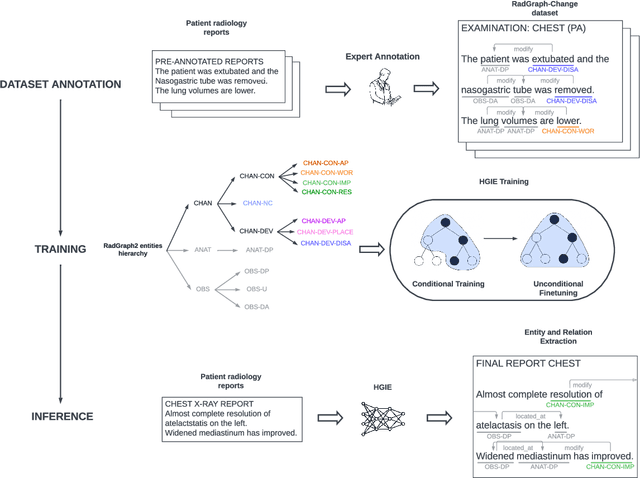
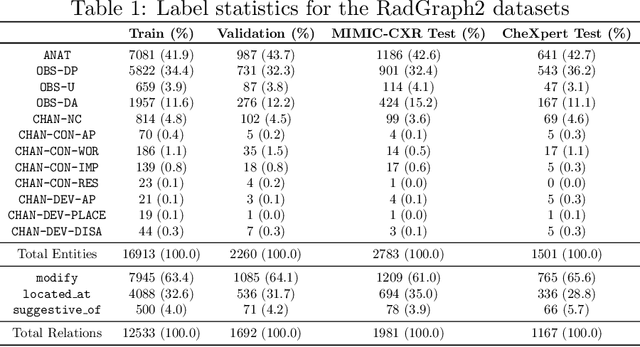
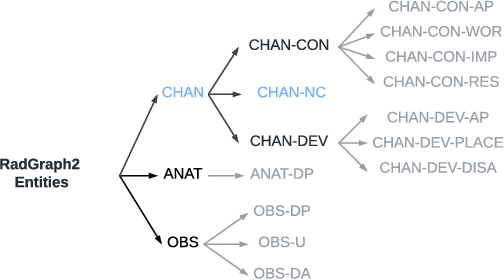
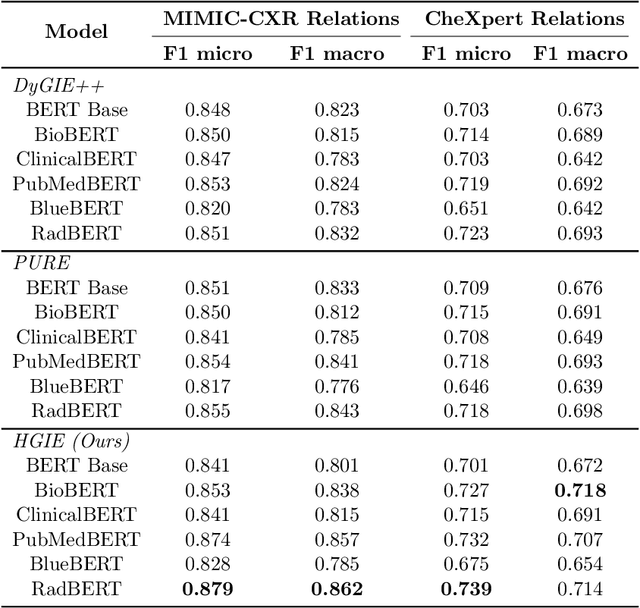
We present RadGraph2, a novel dataset for extracting information from radiology reports that focuses on capturing changes in disease state and device placement over time. We introduce a hierarchical schema that organizes entities based on their relationships and show that using this hierarchy during training improves the performance of an information extraction model. Specifically, we propose a modification to the DyGIE++ framework, resulting in our model HGIE, which outperforms previous models in entity and relation extraction tasks. We demonstrate that RadGraph2 enables models to capture a wider variety of findings and perform better at relation extraction compared to those trained on the original RadGraph dataset. Our work provides the foundation for developing automated systems that can track disease progression over time and develop information extraction models that leverage the natural hierarchy of labels in the medical domain.
Unsupervised Extractive Summarization with Learnable Length Control Strategies
Dec 18, 2023Unsupervised extractive summarization is an important technique in information extraction and retrieval. Compared with supervised method, it does not require high-quality human-labelled summaries for training and thus can be easily applied for documents with different types, domains or languages. Most of existing unsupervised methods including TextRank and PACSUM rely on graph-based ranking on sentence centrality. However, this scorer can not be directly applied in end-to-end training, and the positional-related prior assumption is often needed for achieving good summaries. In addition, less attention is paid to length-controllable extractor, where users can decide to summarize texts under particular length constraint. This paper introduces an unsupervised extractive summarization model based on a siamese network, for which we develop a trainable bidirectional prediction objective between the selected summary and the original document. Different from the centrality-based ranking methods, our extractive scorer can be trained in an end-to-end manner, with no other requirement of positional assumption. In addition, we introduce a differentiable length control module by approximating 0-1 knapsack solver for end-to-end length-controllable extracting. Experiments show that our unsupervised method largely outperforms the centrality-based baseline using a same sentence encoder. In terms of length control ability, via our trainable knapsack module, the performance consistently outperforms the strong baseline without utilizing end-to-end training. Human evaluation further evidences that our method performs the best among baselines in terms of relevance and consistency.
ESG Accountability Made Easy: DocQA at Your Service
Nov 30, 2023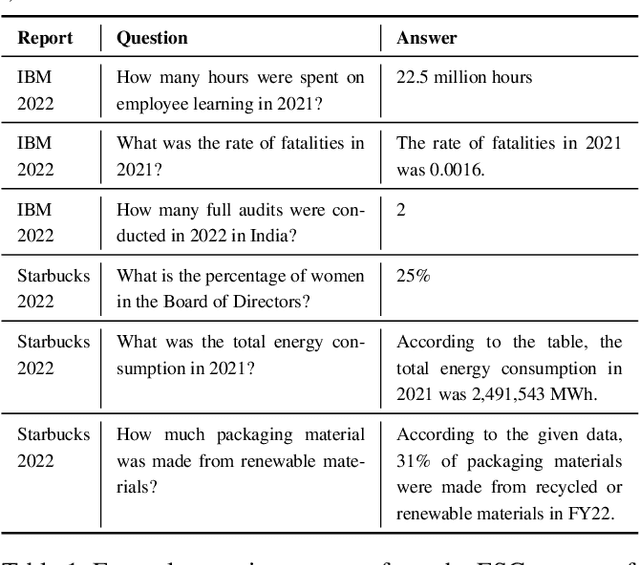
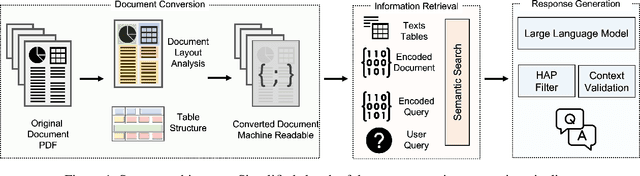
We present Deep Search DocQA. This application enables information extraction from documents via a question-answering conversational assistant. The system integrates several technologies from different AI disciplines consisting of document conversion to machine-readable format (via computer vision), finding relevant data (via natural language processing), and formulating an eloquent response (via large language models). Users can explore over 10,000 Environmental, Social, and Governance (ESG) disclosure reports from over 2000 corporations. The Deep Search platform can be accessed at: https://ds4sd.github.io.
RESIN-EDITOR: A Schema-guided Hierarchical Event Graph Visualizer and Editor
Dec 05, 2023

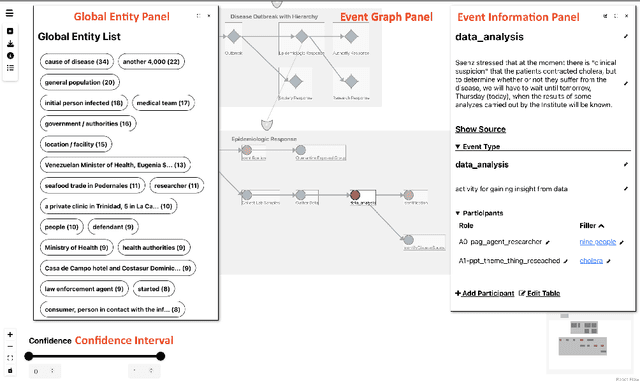
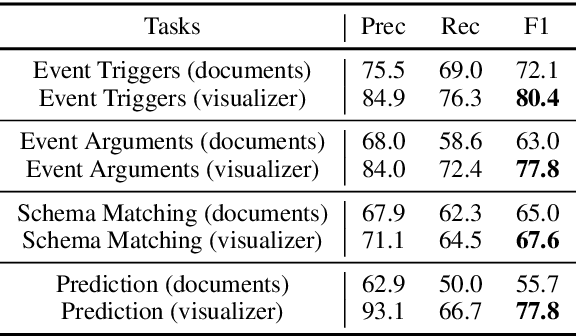
In this paper, we present RESIN-EDITOR, an interactive event graph visualizer and editor designed for analyzing complex events. Our RESIN-EDITOR system allows users to render and freely edit hierarchical event graphs extracted from multimedia and multi-document news clusters with guidance from human-curated event schemas. RESIN-EDITOR's unique features include hierarchical graph visualization, comprehensive source tracing, and interactive user editing, which is more powerful and versatile than existing Information Extraction (IE) visualization tools. In our evaluation of RESIN-EDITOR, we demonstrate ways in which our tool is effective in understanding complex events and enhancing system performance. The source code, a video demonstration, and a live website for RESIN-EDITOR have been made publicly available.
MT4CrossOIE: Multi-stage Tuning for Cross-lingual Open Information Extraction
Aug 12, 2023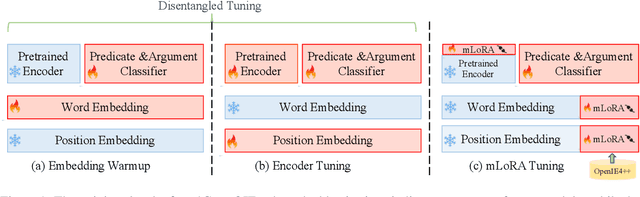

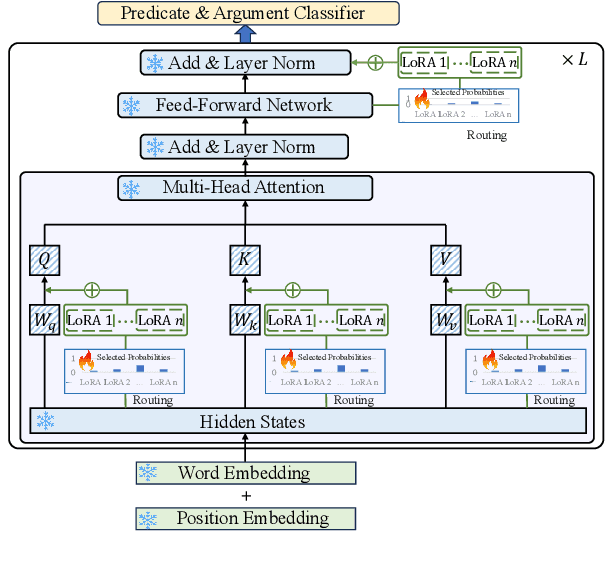
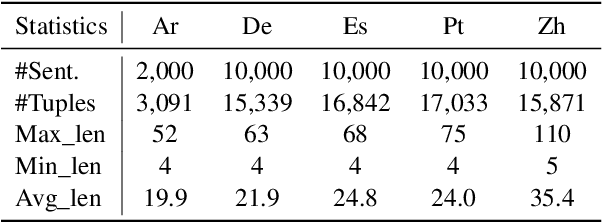
Cross-lingual open information extraction aims to extract structured information from raw text across multiple languages. Previous work uses a shared cross-lingual pre-trained model to handle the different languages but underuses the potential of the language-specific representation. In this paper, we propose an effective multi-stage tuning framework called MT4CrossIE, designed for enhancing cross-lingual open information extraction by injecting language-specific knowledge into the shared model. Specifically, the cross-lingual pre-trained model is first tuned in a shared semantic space (e.g., embedding matrix) in the fixed encoder and then other components are optimized in the second stage. After enough training, we freeze the pre-trained model and tune the multiple extra low-rank language-specific modules using mixture-of-LoRAs for model-based cross-lingual transfer. In addition, we leverage two-stage prompting to encourage the large language model (LLM) to annotate the multi-lingual raw data for data-based cross-lingual transfer. The model is trained with multi-lingual objectives on our proposed dataset OpenIE4++ by combing the model-based and data-based transfer techniques. Experimental results on various benchmarks emphasize the importance of aggregating multiple plug-in-and-play language-specific modules and demonstrate the effectiveness of MT4CrossIE in cross-lingual OIE\footnote{\url{https://github.com/CSJianYang/Multilingual-Multimodal-NLP}}.
A Semantic-Aware Multiple Access Scheme for Distributed, Dynamic 6G-Based Applications
Jan 12, 2024The emergence of the semantic-aware paradigm presents opportunities for innovative services, especially in the context of 6G-based applications. Although significant progress has been made in semantic extraction techniques, the incorporation of semantic information into resource allocation decision-making is still in its early stages, lacking consideration of the requirements and characteristics of future systems. In response, this paper introduces a novel formulation for the problem of multiple access to the wireless spectrum. It aims to optimize the utilization-fairness trade-off, using the $\alpha$-fairness metric, while accounting for user data correlation by introducing the concepts of self- and assisted throughputs. Initially, the problem is analyzed to identify its optimal solution. Subsequently, a Semantic-Aware Multi-Agent Double and Dueling Deep Q-Learning (SAMA-D3QL) technique is proposed. This method is grounded in Model-free Multi-Agent Deep Reinforcement Learning (MADRL), enabling the user equipment to autonomously make decisions regarding wireless spectrum access based solely on their local individual observations. The efficiency of the proposed technique is evaluated through two scenarios: single-channel and multi-channel. The findings illustrate that, across a spectrum of $\alpha$ values, association matrices, and channels, SAMA-D3QL consistently outperforms alternative approaches. This establishes it as a promising candidate for facilitating the realization of future federated, dynamically evolving applications.
ASF-YOLO: A Novel YOLO Model with Attentional Scale Sequence Fusion for Cell Instance Segmentation
Dec 11, 2023
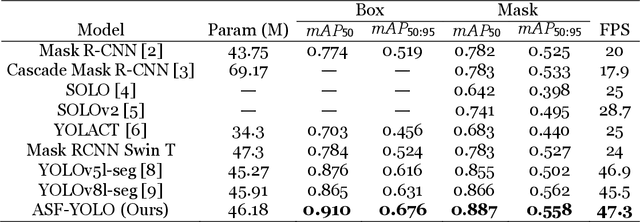
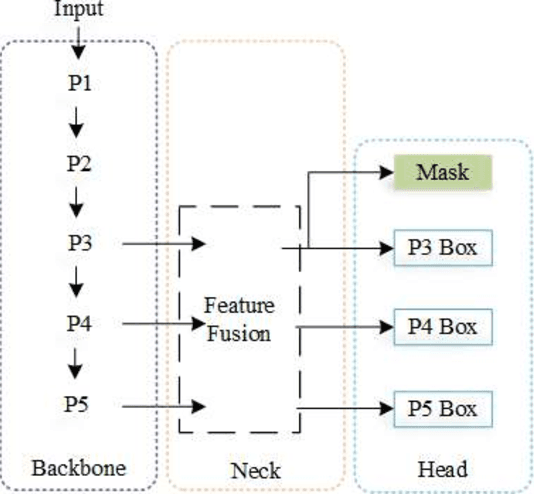
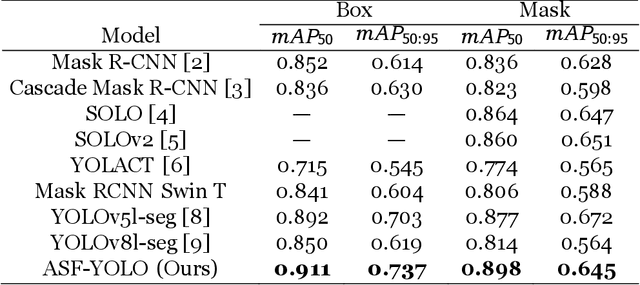
We propose a novel Attentional Scale Sequence Fusion based You Only Look Once (YOLO) framework (ASF-YOLO) which combines spatial and scale features for accurate and fast cell instance segmentation. Built on the YOLO segmentation framework, we employ the Scale Sequence Feature Fusion (SSFF) module to enhance the multi-scale information extraction capability of the network, and the Triple Feature Encoder (TPE) module to fuse feature maps of different scales to increase detailed information. We further introduce a Channel and Position Attention Mechanism (CPAM) to integrate both the SSFF and TPE modules, which focus on informative channels and spatial position-related small objects for improved detection and segmentation performance. Experimental validations on two cell datasets show remarkable segmentation accuracy and speed of the proposed ASF-YOLO model. It achieves a box mAP of 0.91, mask mAP of 0.887, and an inference speed of 47.3 FPS on the 2018 Data Science Bowl dataset, outperforming the state-of-the-art methods. The source code is available at https://github.com/mkang315/ASF-YOLO.