 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
YOIO: You Only Iterate Once by mining and fusing multiple necessary global information in the optical flow estimation
Jan 11, 2024
Occlusions pose a significant challenge to optical flow algorithms that even rely on global evidences. We consider an occluded point to be one that is imaged in the reference frame but not in the next. Estimating the motion of these points is extremely difficult, particularly in the two-frame setting. Previous work only used the current frame as the only input, which could not guarantee providing correct global reference information for occluded points, and had problems such as long calculation time and poor accuracy in predicting optical flow at occluded points. To enable both high accuracy and efficiency, We fully mine and utilize the spatiotemporal information provided by the frame pair, design a loopback judgment algorithm to ensure that correct global reference information is obtained, mine multiple necessary global information, and design an efficient refinement module that fuses these global information. Specifically, we propose a YOIO framework, which consists of three main components: an initial flow estimator, a multiple global information extraction module, and a unified refinement module. We demonstrate that optical flow estimates in the occluded regions can be significantly improved in only one iteration without damaging the performance in non-occluded regions. Compared with GMA, the optical flow prediction accuracy of this method in the occluded area is improved by more than 10%, and the occ_out area exceeds 15%, while the calculation time is 27% shorter. This approach, running up to 18.9fps with 436*1024 image resolution, obtains new state-of-the-art results on the challenging Sintel dataset among all published and unpublished approaches that can run in real-time, suggesting a new paradigm for accurate and efficient optical flow estimation.
LongFin: A Multimodal Document Understanding Model for Long Financial Domain Documents
Jan 26, 2024Document AI is a growing research field that focuses on the comprehension and extraction of information from scanned and digital documents to make everyday business operations more efficient. Numerous downstream tasks and datasets have been introduced to facilitate the training of AI models capable of parsing and extracting information from various document types such as receipts and scanned forms. Despite these advancements, both existing datasets and models fail to address critical challenges that arise in industrial contexts. Existing datasets primarily comprise short documents consisting of a single page, while existing models are constrained by a limited maximum length, often set at 512 tokens. Consequently, the practical application of these methods in financial services, where documents can span multiple pages, is severely impeded. To overcome these challenges, we introduce LongFin, a multimodal document AI model capable of encoding up to 4K tokens. We also propose the LongForms dataset, a comprehensive financial dataset that encapsulates several industrial challenges in financial documents. Through an extensive evaluation, we demonstrate the effectiveness of the LongFin model on the LongForms dataset, surpassing the performance of existing public models while maintaining comparable results on existing single-page benchmarks.
Efficient Data Learning for Open Information Extraction with Pre-trained Language Models
Oct 23, 2023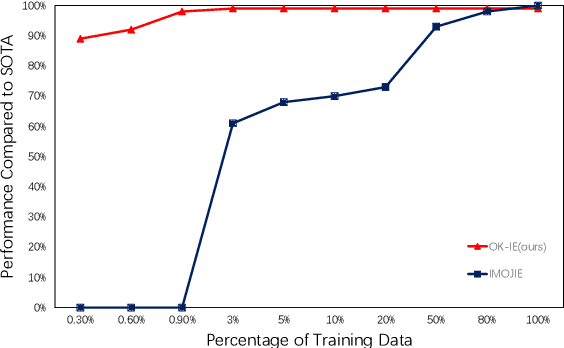
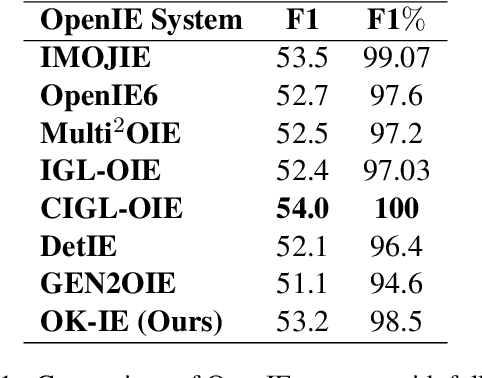

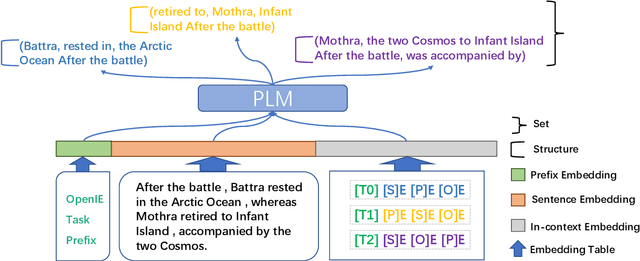
Open Information Extraction (OpenIE) is a fundamental yet challenging task in Natural Language Processing, which involves extracting all triples (subject, predicate, object) from a given sentence. While labeling-based methods have their merits, generation-based techniques offer unique advantages, such as the ability to generate tokens not present in the original sentence. However, these generation-based methods often require a significant amount of training data to learn the task form of OpenIE and substantial training time to overcome slow model convergence due to the order penalty. In this paper, we introduce a novel framework, OK-IE, that ingeniously transforms the task form of OpenIE into the pre-training task form of the T5 model, thereby reducing the need for extensive training data. Furthermore, we introduce an innovative concept of Anchor to control the sequence of model outputs, effectively eliminating the impact of order penalty on model convergence and significantly reducing training time. Experimental results indicate that, compared to previous SOTA methods, OK-IE requires only 1/100 of the training data (900 instances) and 1/120 of the training time (3 minutes) to achieve comparable results.
MuLMS: A Multi-Layer Annotated Text Corpus for Information Extraction in the Materials Science Domain
Oct 24, 2023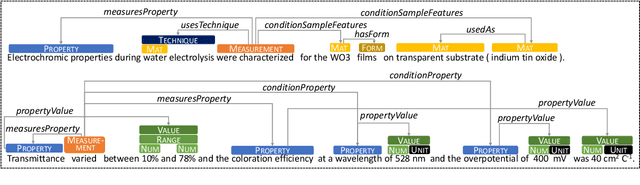

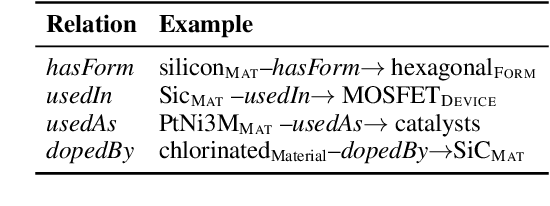
Keeping track of all relevant recent publications and experimental results for a research area is a challenging task. Prior work has demonstrated the efficacy of information extraction models in various scientific areas. Recently, several datasets have been released for the yet understudied materials science domain. However, these datasets focus on sub-problems such as parsing synthesis procedures or on sub-domains, e.g., solid oxide fuel cells. In this resource paper, we present MuLMS, a new dataset of 50 open-access articles, spanning seven sub-domains of materials science. The corpus has been annotated by domain experts with several layers ranging from named entities over relations to frame structures. We present competitive neural models for all tasks and demonstrate that multi-task training with existing related resources leads to benefits.
Concurrent Brainstorming & Hypothesis Satisfying: An Iterative Framework for Enhanced Retrieval-Augmented Generation (R2CBR3H-SR)
Jan 03, 2024Addressing the complexity of comprehensive information retrieval, this study introduces an innovative, iterative retrieval-augmented generation system. Our approach uniquely integrates a vector-space driven re-ranking mechanism with concurrent brainstorming to expedite the retrieval of highly relevant documents, thereby streamlining the generation of potential queries. This sets the stage for our novel hybrid process, which synergistically combines hypothesis formulation with satisfying decision-making strategy to determine content adequacy, leveraging a chain of thought-based prompting technique. This unified hypothesize-satisfied phase intelligently distills information to ascertain whether user queries have been satisfactorily addressed. Upon reaching this criterion, the system refines its output into a concise representation, maximizing conceptual density with minimal verbosity. The iterative nature of the workflow enhances process efficiency and accuracy. Crucially, the concurrency within the brainstorming phase significantly accelerates recursive operations, facilitating rapid convergence to solution satisfaction. Compared to conventional methods, our system demonstrates a marked improvement in computational time and cost-effectiveness. This research advances the state-of-the-art in intelligent retrieval systems, setting a new benchmark for resource-efficient information extraction and abstraction in knowledge-intensive applications.
Perceptual Musical Features for Interpretable Audio Tagging
Jan 04, 2024In the age of music streaming platforms, the task of automatically tagging music audio has garnered significant attention, driving researchers to devise methods aimed at enhancing performance metrics on standard datasets. Most recent approaches rely on deep neural networks, which, despite their impressive performance, possess opacity, making it challenging to elucidate their output for a given input. While the issue of interpretability has been emphasized in other fields like medicine, it has not received attention in music-related tasks. In this study, we explored the relevance of interpretability in the context of automatic music tagging. We constructed a workflow that incorporates three different information extraction techniques: a) leveraging symbolic knowledge, b) utilizing auxiliary deep neural networks, and c) employing signal processing to extract perceptual features from audio files. These features were subsequently used to train an interpretable machine-learning model for tag prediction. We conducted experiments on two datasets, namely the MTG-Jamendo dataset and the GTZAN dataset. Our method surpassed the performance of baseline models in both tasks and, in certain instances, demonstrated competitiveness with the current state-of-the-art. We conclude that there are use cases where the deterioration in performance is outweighed by the value of interpretability.
Fine-tuning and Utilization Methods of Domain-specific LLMs
Jan 01, 2024Recent releases of pre-trained Large Language Models (LLMs) have gained considerable traction, yet research on fine-tuning and employing domain-specific LLMs remains scarce. This study investigates approaches for fine-tuning and leveraging domain-specific LLMs, highlighting trends in LLMs, foundational models, and methods for domain-specific pre-training. Focusing on the financial sector, it details dataset selection, preprocessing, model choice, and considerations crucial for LLM fine-tuning in finance. Addressing the unique characteristics of financial data, the study explores the construction of domain-specific vocabularies and considerations for security and regulatory compliance. In the practical application of LLM fine-tuning, the study outlines the procedure and implementation for generating domain-specific LLMs in finance. Various financial cases, including stock price prediction, sentiment analysis of financial news, automated document processing, research, information extraction, and customer service enhancement, are exemplified. The study explores the potential of LLMs in the financial domain, identifies limitations, and proposes directions for improvement, contributing valuable insights for future research. Ultimately, it advances natural language processing technology in business, suggesting proactive LLM utilization in financial services across industries.
I2SRM: Intra- and Inter-Sample Relationship Modeling for Multimodal Information Extraction
Oct 10, 2023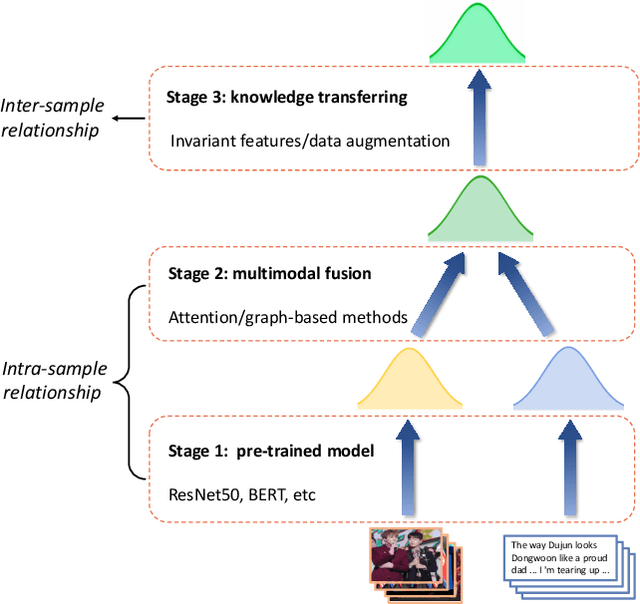
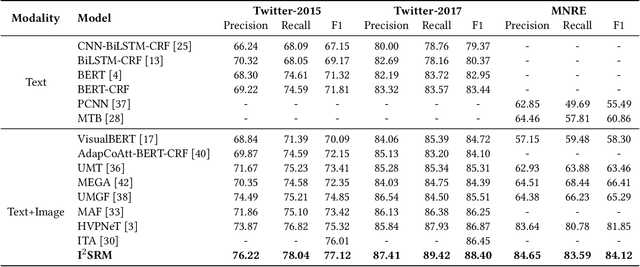
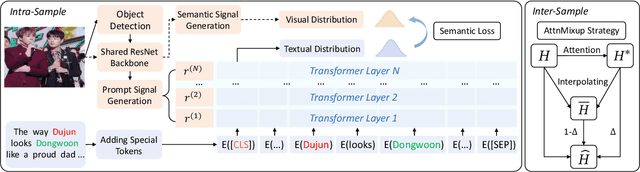
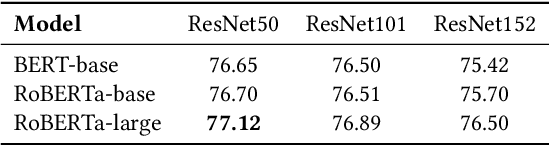
Multimodal information extraction is attracting research attention nowadays, which requires aggregating representations from different modalities. In this paper, we present the Intra- and Inter-Sample Relationship Modeling (I2SRM) method for this task, which contains two modules. Firstly, the intra-sample relationship modeling module operates on a single sample and aims to learn effective representations. Embeddings from textual and visual modalities are shifted to bridge the modality gap caused by distinct pre-trained language and image models. Secondly, the inter-sample relationship modeling module considers relationships among multiple samples and focuses on capturing the interactions. An AttnMixup strategy is proposed, which not only enables collaboration among samples but also augments data to improve generalization. We conduct extensive experiments on the multimodal named entity recognition datasets Twitter-2015 and Twitter-2017, and the multimodal relation extraction dataset MNRE. Our proposed method I2SRM achieves competitive results, 77.12% F1-score on Twitter-2015, 88.40% F1-score on Twitter-2017, and 84.12% F1-score on MNRE.
L3Cube-MahaSocialNER: A Social Media based Marathi NER Dataset and BERT models
Dec 30, 2023This work introduces the L3Cube-MahaSocialNER dataset, the first and largest social media dataset specifically designed for Named Entity Recognition (NER) in the Marathi language. The dataset comprises 18,000 manually labeled sentences covering eight entity classes, addressing challenges posed by social media data, including non-standard language and informal idioms. Deep learning models, including CNN, LSTM, BiLSTM, and Transformer models, are evaluated on the individual dataset with IOB and non-IOB notations. The results demonstrate the effectiveness of these models in accurately recognizing named entities in Marathi informal text. The L3Cube-MahaSocialNER dataset offers user-centric information extraction and supports real-time applications, providing a valuable resource for public opinion analysis, news, and marketing on social media platforms. We also show that the zero-shot results of the regular NER model are poor on the social NER test set thus highlighting the need for more social NER datasets. The datasets and models are publicly available at https://github.com/l3cube-pune/MarathiNLP
GraphViz2Vec: A Structure-aware Feature Generation Model to Improve Classification in GNNs
Jan 30, 2024GNNs are widely used to solve various tasks including node classification and link prediction. Most of the GNN architectures assume the initial embedding to be random or generated from popular distributions. These initial embeddings require multiple layers of transformation to converge into a meaningful latent representation. While number of layers allow accumulation of larger neighbourhood of a node it also introduce the problem of over-smoothing. In addition, GNNs are inept at representing structural information. For example, the output embedding of a node does not capture its triangles participation. In this paper, we presented a novel feature extraction methodology GraphViz2Vec that can capture the structural information of a node's local neighbourhood to create meaningful initial embeddings for a GNN model. These initial embeddings helps existing models achieve state-of-the-art results in various classification tasks. Further, these initial embeddings help the model to produce desired results with only two layers which in turn reduce the problem of over-smoothing. The initial encoding of a node is obtained from an image classification model trained on multiple energy diagrams of its local neighbourhood. These energy diagrams are generated with the induced sub-graph of the nodes traversed by multiple random walks. The generated encodings increase the performance of existing models on classification tasks (with a mean increase of $4.65\%$ and $2.58\%$ for the node and link classification tasks, respectively), with some models achieving state-of-the-art results.