 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Reading Order Matters: Information Extraction from Visually-rich Documents by Token Path Prediction
Oct 17, 2023
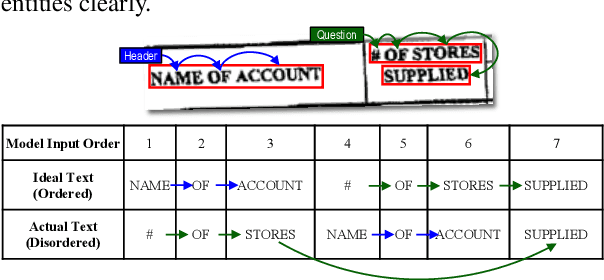
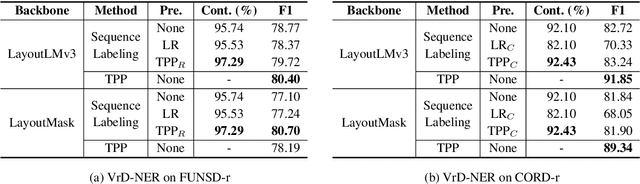

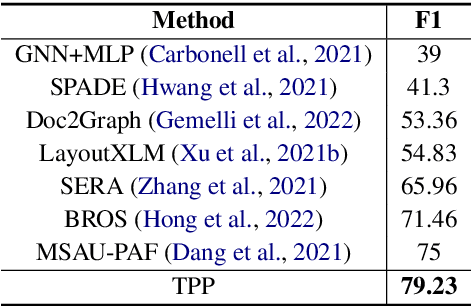
Recent advances in multimodal pre-trained models have significantly improved information extraction from visually-rich documents (VrDs), in which named entity recognition (NER) is treated as a sequence-labeling task of predicting the BIO entity tags for tokens, following the typical setting of NLP. However, BIO-tagging scheme relies on the correct order of model inputs, which is not guaranteed in real-world NER on scanned VrDs where text are recognized and arranged by OCR systems. Such reading order issue hinders the accurate marking of entities by BIO-tagging scheme, making it impossible for sequence-labeling methods to predict correct named entities. To address the reading order issue, we introduce Token Path Prediction (TPP), a simple prediction head to predict entity mentions as token sequences within documents. Alternative to token classification, TPP models the document layout as a complete directed graph of tokens, and predicts token paths within the graph as entities. For better evaluation of VrD-NER systems, we also propose two revised benchmark datasets of NER on scanned documents which can reflect real-world scenarios. Experiment results demonstrate the effectiveness of our method, and suggest its potential to be a universal solution to various information extraction tasks on documents.
AMuRD: Annotated Multilingual Receipts Dataset for Cross-lingual Key Information Extraction and Classification
Sep 18, 2023

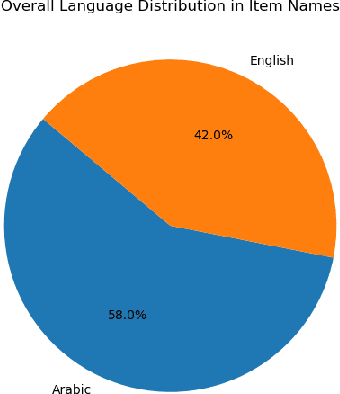

Key information extraction involves recognizing and extracting text from scanned receipts, enabling retrieval of essential content, and organizing it into structured documents. This paper presents a novel multilingual dataset for receipt extraction, addressing key challenges in information extraction and item classification. The dataset comprises $47,720$ samples, including annotations for item names, attributes like (price, brand, etc.), and classification into $44$ product categories. We introduce the InstructLLaMA approach, achieving an F1 score of $0.76$ and an accuracy of $0.68$ for key information extraction and item classification. We provide code, datasets, and checkpoints.\footnote{\url{https://github.com/Update-For-Integrated-Business-AI/AMuRD}}.
A Survey of Document-Level Information Extraction
Sep 23, 2023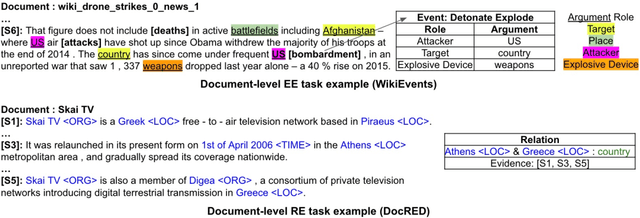
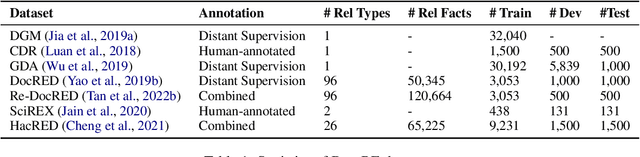
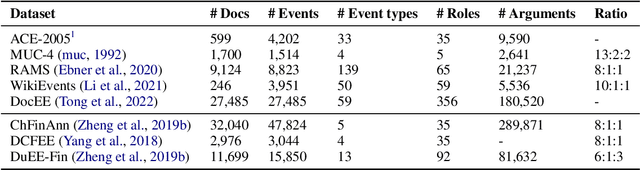
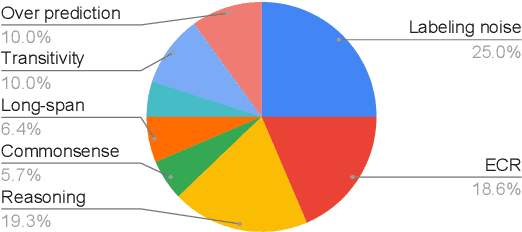
Document-level information extraction (IE) is a crucial task in natural language processing (NLP). This paper conducts a systematic review of recent document-level IE literature. In addition, we conduct a thorough error analysis with current state-of-the-art algorithms and identify their limitations as well as the remaining challenges for the task of document-level IE. According to our findings, labeling noises, entity coreference resolution, and lack of reasoning, severely affect the performance of document-level IE. The objective of this survey paper is to provide more insights and help NLP researchers to further enhance document-level IE performance.
Mastering the Task of Open Information Extraction with Large Language Models and Consistent Reasoning Environment
Oct 16, 2023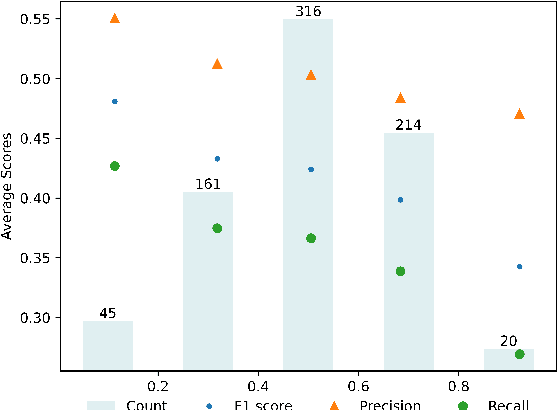
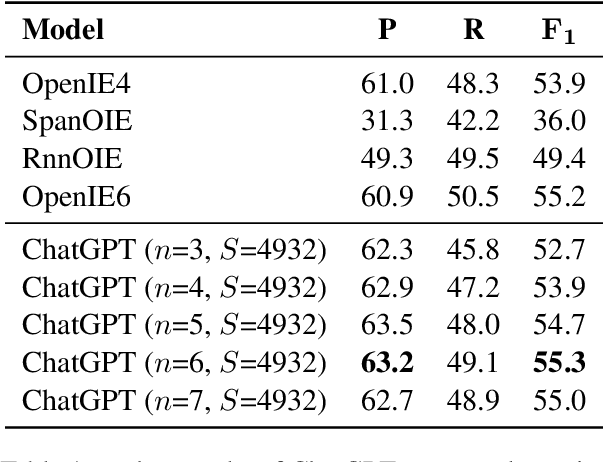
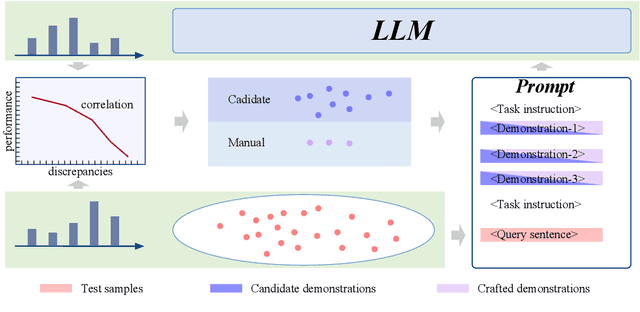

Open Information Extraction (OIE) aims to extract objective structured knowledge from natural texts, which has attracted growing attention to build dedicated models with human experience. As the large language models (LLMs) have exhibited remarkable in-context learning capabilities, a question arises as to whether the task of OIE can be effectively tackled with this paradigm? In this paper, we explore solving the OIE problem by constructing an appropriate reasoning environment for LLMs. Specifically, we first propose a method to effectively estimate the discrepancy of syntactic distribution between a LLM and test samples, which can serve as correlation evidence for preparing positive demonstrations. Upon the evidence, we introduce a simple yet effective mechanism to establish the reasoning environment for LLMs on specific tasks. Without bells and whistles, experimental results on the standard CaRB benchmark demonstrate that our $6$-shot approach outperforms state-of-the-art supervised method, achieving an $55.3$ $F_1$ score. Further experiments on TACRED and ACE05 show that our method can naturally generalize to other information extraction tasks, resulting in improvements of $5.7$ and $6.8$ $F_1$ scores, respectively.
Multimodal Question Answering for Unified Information Extraction
Oct 04, 2023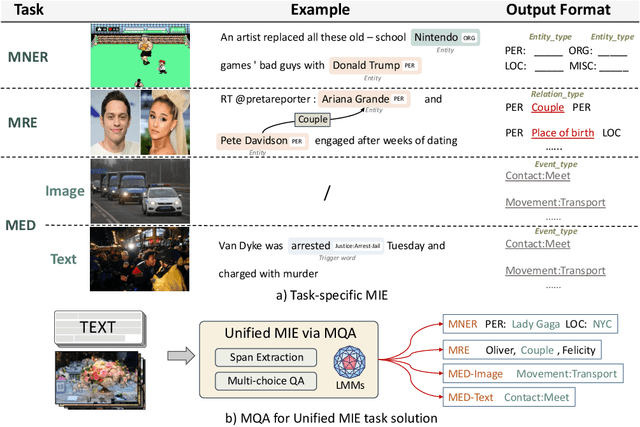
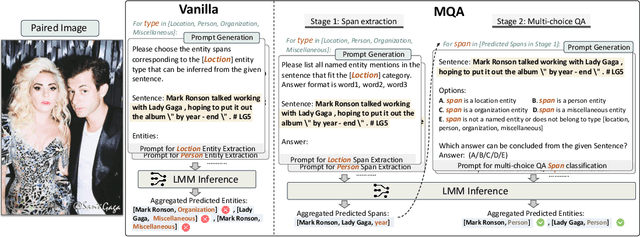
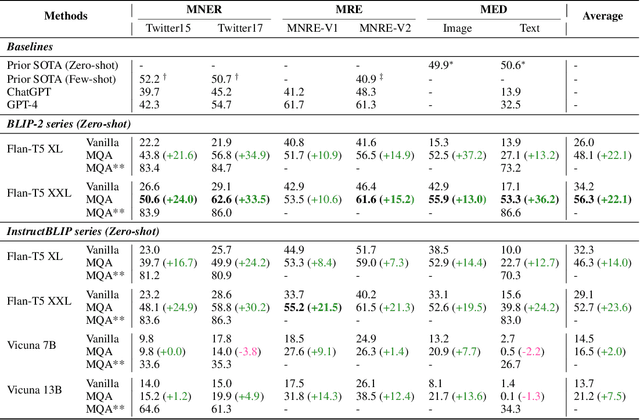

Multimodal information extraction (MIE) aims to extract structured information from unstructured multimedia content. Due to the diversity of tasks and settings, most current MIE models are task-specific and data-intensive, which limits their generalization to real-world scenarios with diverse task requirements and limited labeled data. To address these issues, we propose a novel multimodal question answering (MQA) framework to unify three MIE tasks by reformulating them into a unified span extraction and multi-choice QA pipeline. Extensive experiments on six datasets show that: 1) Our MQA framework consistently and significantly improves the performances of various off-the-shelf large multimodal models (LMM) on MIE tasks, compared to vanilla prompting. 2) In the zero-shot setting, MQA outperforms previous state-of-the-art baselines by a large margin. In addition, the effectiveness of our framework can successfully transfer to the few-shot setting, enhancing LMMs on a scale of 10B parameters to be competitive or outperform much larger language models such as ChatGPT and GPT-4. Our MQA framework can serve as a general principle of utilizing LMMs to better solve MIE and potentially other downstream multimodal tasks.
Open Information Extraction: A Review of Baseline Techniques, Approaches, and Applications
Oct 18, 2023

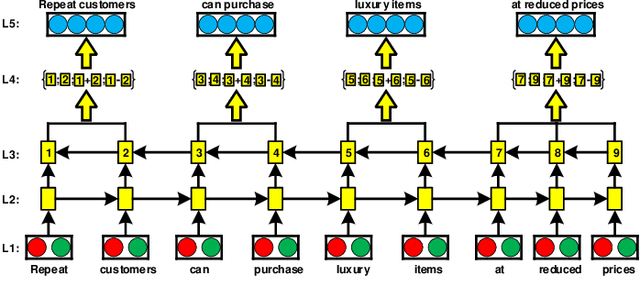
With the abundant amount of available online and offline text data, there arises a crucial need to extract the relation between phrases and summarize the main content of each document in a few words. For this purpose, there have been many studies recently in Open Information Extraction (OIE). OIE improves upon relation extraction techniques by analyzing relations across different domains and avoids requiring hand-labeling pre-specified relations in sentences. This paper surveys recent approaches of OIE and its applications on Knowledge Graph (KG), text summarization, and Question Answering (QA). Moreover, the paper describes OIE basis methods in relation extraction. It briefly discusses the main approaches and the pros and cons of each method. Finally, it gives an overview about challenges, open issues, and future work opportunities for OIE, relation extraction, and OIE applications.
Enhancing Complex Question Answering over Knowledge Graphs through Evidence Pattern Retrieval
Feb 03, 2024Information retrieval (IR) methods for KGQA consist of two stages: subgraph extraction and answer reasoning. We argue current subgraph extraction methods underestimate the importance of structural dependencies among evidence facts. We propose Evidence Pattern Retrieval (EPR) to explicitly model the structural dependencies during subgraph extraction. We implement EPR by indexing the atomic adjacency pattern of resource pairs. Given a question, we perform dense retrieval to obtain atomic patterns formed by resource pairs. We then enumerate their combinations to construct candidate evidence patterns. These evidence patterns are scored using a neural model, and the best one is selected to extract a subgraph for downstream answer reasoning. Experimental results demonstrate that the EPR-based approach has significantly improved the F1 scores of IR-KGQA methods by over 10 points on ComplexWebQuestions and achieves competitive performance on WebQuestionsSP.
Semantic Information Extraction for Text Data with Probability Graph
Sep 16, 2023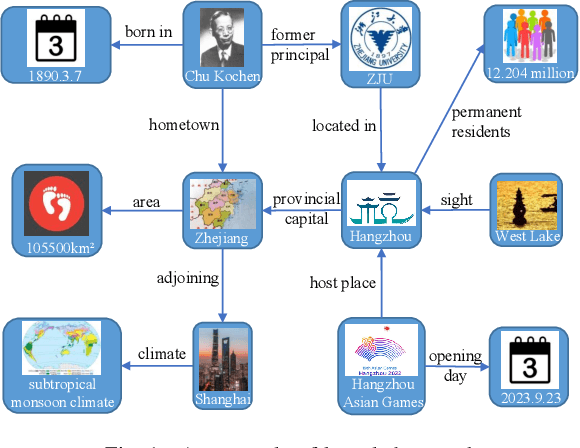
In this paper, the problem of semantic information extraction for resource constrained text data transmission is studied. In the considered model, a sequence of text data need to be transmitted within a communication resource-constrained network, which only allows limited data transmission. Thus, at the transmitter, the original text data is extracted with natural language processing techniques. Then, the extracted semantic information is captured in a knowledge graph. An additional probability dimension is introduced in this graph to capture the importance of each information. This semantic information extraction problem is posed as an optimization framework whose goal is to extract most important semantic information for transmission. To find an optimal solution for this problem, a Floyd's algorithm based solution coupled with an efficient sorting mechanism is proposed. Numerical results testify the effectiveness of the proposed algorithm with regards to two novel performance metrics including semantic uncertainty and semantic similarity.
An Autoregressive Text-to-Graph Framework for Joint Entity and Relation Extraction
Jan 02, 2024In this paper, we propose a novel method for joint entity and relation extraction from unstructured text by framing it as a conditional sequence generation problem. In contrast to conventional generative information extraction models that are left-to-right token-level generators, our approach is \textit{span-based}. It generates a linearized graph where nodes represent text spans and edges represent relation triplets. Our method employs a transformer encoder-decoder architecture with pointing mechanism on a dynamic vocabulary of spans and relation types. Our model can capture the structural characteristics and boundaries of entities and relations through span representations while simultaneously grounding the generated output in the original text thanks to the pointing mechanism. Evaluation on benchmark datasets validates the effectiveness of our approach, demonstrating competitive results. Code is available at https://github.com/urchade/ATG.
RSCNet: Dynamic CSI Compression for Cloud-based WiFi Sensing
Jan 19, 2024WiFi-enabled Internet-of-Things (IoT) devices are evolving from mere communication devices to sensing instruments, leveraging Channel State Information (CSI) extraction capabilities. Nevertheless, resource-constrained IoT devices and the intricacies of deep neural networks necessitate transmitting CSI to cloud servers for sensing. Although feasible, this leads to considerable communication overhead. In this context, this paper develops a novel Real-time Sensing and Compression Network (RSCNet) which enables sensing with compressed CSI; thereby reducing the communication overheads. RSCNet facilitates optimization across CSI windows composed of a few CSI frames. Once transmitted to cloud servers, it employs Long Short-Term Memory (LSTM) units to harness data from prior windows, thus bolstering both the sensing accuracy and CSI reconstruction. RSCNet adeptly balances the trade-off between CSI compression and sensing precision, thus streamlining real-time cloud-based WiFi sensing with reduced communication costs. Numerical findings demonstrate the gains of RSCNet over the existing benchmarks like SenseFi, showcasing a sensing accuracy of 97.4% with minimal CSI reconstruction error. Numerical results also show a computational analysis of the proposed RSCNet as a function of the number of CSI frames.