 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Target Speaker Extraction by Directly Exploiting Contextual Information in the Time-Frequency Domain
Feb 27, 2024
In target speaker extraction, many studies rely on the speaker embedding which is obtained from an enrollment of the target speaker and employed as the guidance. However, solely using speaker embedding may not fully utilize the contextual information contained in the enrollment. In this paper, we directly exploit this contextual information in the time-frequency (T-F) domain. Specifically, the T-F representations of the enrollment and the mixed signal are interacted to compute the weighting matrices through an attention mechanism. These weighting matrices reflect the similarity among different frames of the T-F representations and are further employed to obtain the consistent T-F representations of the enrollment. These consistent representations are served as the guidance, allowing for better exploitation of the contextual information. Furthermore, the proposed method achieves the state-of-the-art performance on the benchmark dataset and shows its effectiveness in the complex scenarios.
Few-Shot Relation Extraction with Hybrid Visual Evidence
Mar 01, 2024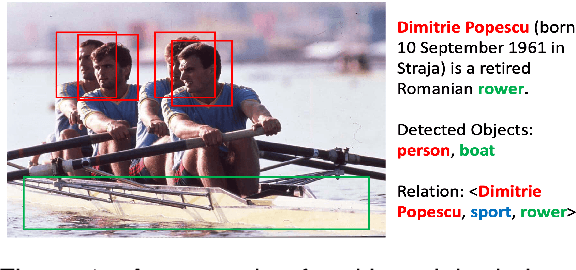

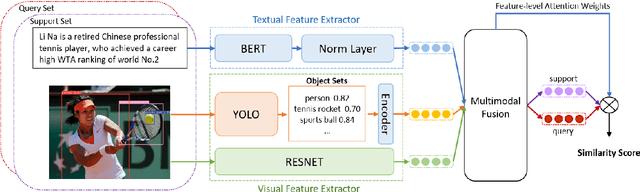

The goal of few-shot relation extraction is to predict relations between name entities in a sentence when only a few labeled instances are available for training. Existing few-shot relation extraction methods focus on uni-modal information such as text only. This reduces performance when there are no clear contexts between the name entities described in text. We propose a multi-modal few-shot relation extraction model (MFS-HVE) that leverages both textual and visual semantic information to learn a multi-modal representation jointly. The MFS-HVE includes semantic feature extractors and multi-modal fusion components. The MFS-HVE semantic feature extractors are developed to extract both textual and visual features. The visual features include global image features and local object features within the image. The MFS-HVE multi-modal fusion unit integrates information from various modalities using image-guided attention, object-guided attention, and hybrid feature attention to fully capture the semantic interaction between visual regions of images and relevant texts. Extensive experiments conducted on two public datasets demonstrate that semantic visual information significantly improves the performance of few-shot relation prediction.
* 16 pages, 5 figures
Magic-Me: Identity-Specific Video Customized Diffusion
Feb 14, 2024Creating content for a specific identity (ID) has shown significant interest in the field of generative models. In the field of text-to-image generation (T2I), subject-driven content generation has achieved great progress with the ID in the images controllable. However, extending it to video generation is not well explored. In this work, we propose a simple yet effective subject identity controllable video generation framework, termed Video Custom Diffusion (VCD). With a specified subject ID defined by a few images, VCD reinforces the identity information extraction and injects frame-wise correlation at the initialization stage for stable video outputs with identity preserved to a large extent. To achieve this, we propose three novel components that are essential for high-quality ID preservation: 1) an ID module trained with the cropped identity by prompt-to-segmentation to disentangle the ID information and the background noise for more accurate ID token learning; 2) a text-to-video (T2V) VCD module with 3D Gaussian Noise Prior for better inter-frame consistency and 3) video-to-video (V2V) Face VCD and Tiled VCD modules to deblur the face and upscale the video for higher resolution. Despite its simplicity, we conducted extensive experiments to verify that VCD is able to generate stable and high-quality videos with better ID over the selected strong baselines. Besides, due to the transferability of the ID module, VCD is also working well with finetuned text-to-image models available publically, further improving its usability. The codes are available at https://github.com/Zhen-Dong/Magic-Me.
BEFUnet: A Hybrid CNN-Transformer Architecture for Precise Medical Image Segmentation
Feb 13, 2024The accurate segmentation of medical images is critical for various healthcare applications. Convolutional neural networks (CNNs), especially Fully Convolutional Networks (FCNs) like U-Net, have shown remarkable success in medical image segmentation tasks. However, they have limitations in capturing global context and long-range relations, especially for objects with significant variations in shape, scale, and texture. While transformers have achieved state-of-the-art results in natural language processing and image recognition, they face challenges in medical image segmentation due to image locality and translational invariance issues. To address these challenges, this paper proposes an innovative U-shaped network called BEFUnet, which enhances the fusion of body and edge information for precise medical image segmentation. The BEFUnet comprises three main modules, including a novel Local Cross-Attention Feature (LCAF) fusion module, a novel Double-Level Fusion (DLF) module, and dual-branch encoder. The dual-branch encoder consists of an edge encoder and a body encoder. The edge encoder employs PDC blocks for effective edge information extraction, while the body encoder uses the Swin Transformer to capture semantic information with global attention. The LCAF module efficiently fuses edge and body features by selectively performing local cross-attention on features that are spatially close between the two modalities. This local approach significantly reduces computational complexity compared to global cross-attention while ensuring accurate feature matching. BEFUnet demonstrates superior performance over existing methods across various evaluation metrics on medical image segmentation datasets.
LLMs Accelerate Annotation for Medical Information Extraction
Dec 04, 2023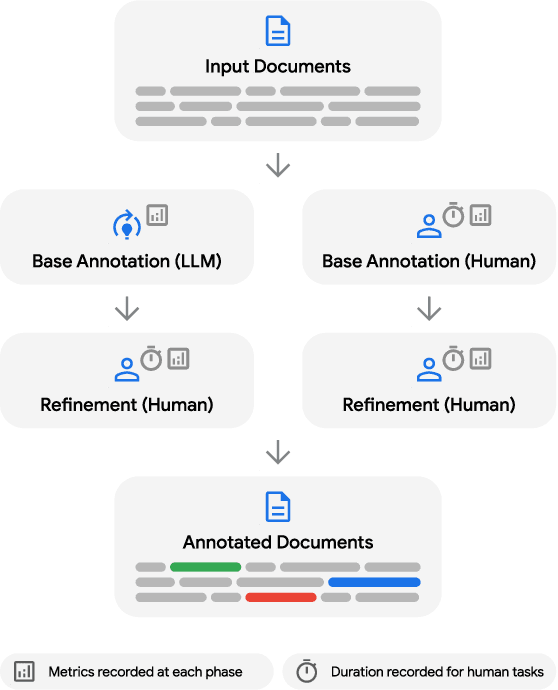
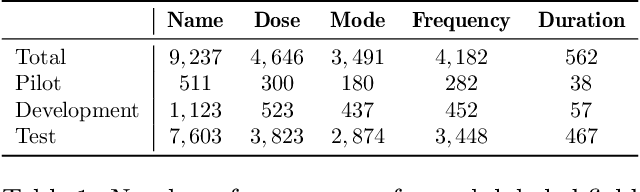
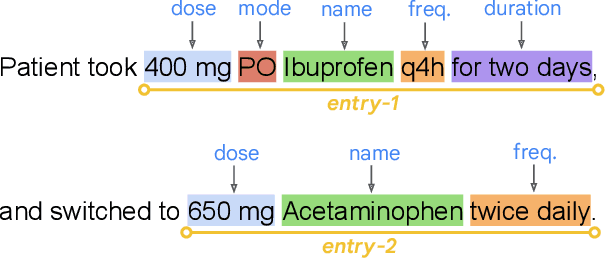
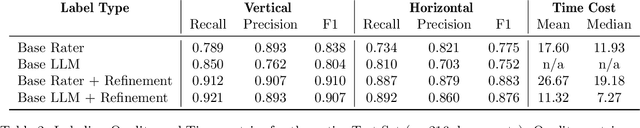
The unstructured nature of clinical notes within electronic health records often conceals vital patient-related information, making it challenging to access or interpret. To uncover this hidden information, specialized Natural Language Processing (NLP) models are required. However, training these models necessitates large amounts of labeled data, a process that is both time-consuming and costly when relying solely on human experts for annotation. In this paper, we propose an approach that combines Large Language Models (LLMs) with human expertise to create an efficient method for generating ground truth labels for medical text annotation. By utilizing LLMs in conjunction with human annotators, we significantly reduce the human annotation burden, enabling the rapid creation of labeled datasets. We rigorously evaluate our method on a medical information extraction task, demonstrating that our approach not only substantially cuts down on human intervention but also maintains high accuracy. The results highlight the potential of using LLMs to improve the utilization of unstructured clinical data, allowing for the swift deployment of tailored NLP solutions in healthcare.
EROS: Entity-Driven Controlled Policy Document Summarization
Feb 29, 2024
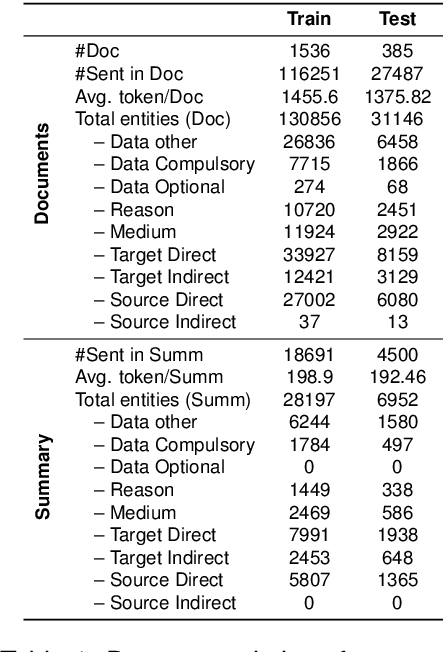
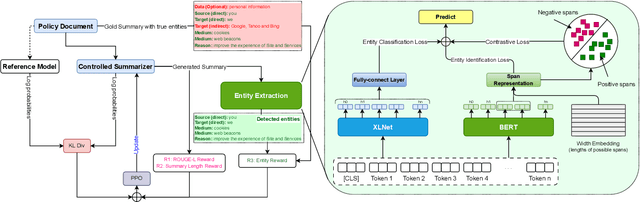
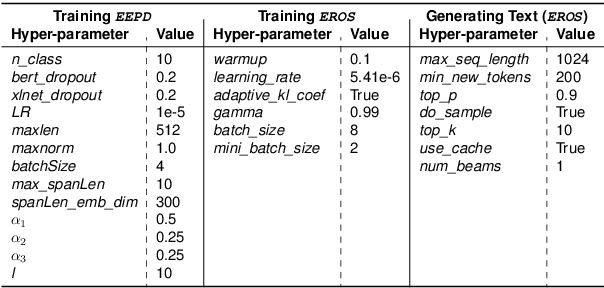
Privacy policy documents have a crucial role in educating individuals about the collection, usage, and protection of users' personal data by organizations. However, they are notorious for their lengthy, complex, and convoluted language especially involving privacy-related entities. Hence, they pose a significant challenge to users who attempt to comprehend organization's data usage policy. In this paper, we propose to enhance the interpretability and readability of policy documents by using controlled abstractive summarization -- we enforce the generated summaries to include critical privacy-related entities (e.g., data and medium) and organization's rationale (e.g.,target and reason) in collecting those entities. To achieve this, we develop PD-Sum, a policy-document summarization dataset with marked privacy-related entity labels. Our proposed model, EROS, identifies critical entities through a span-based entity extraction model and employs them to control the information content of the summaries using proximal policy optimization (PPO). Comparison shows encouraging improvement over various baselines. Furthermore, we furnish qualitative and human evaluations to establish the efficacy of EROS.
FusionVision: A comprehensive approach of 3D object reconstruction and segmentation from RGB-D cameras using YOLO and fast segment anything
Feb 29, 2024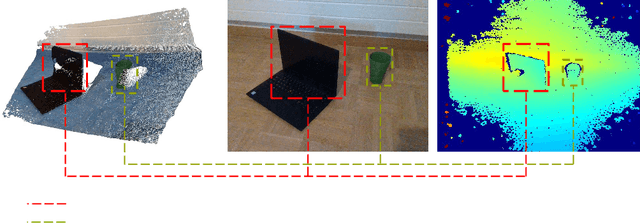



In the realm of computer vision, the integration of advanced techniques into the processing of RGB-D camera inputs poses a significant challenge, given the inherent complexities arising from diverse environmental conditions and varying object appearances. Therefore, this paper introduces FusionVision, an exhaustive pipeline adapted for the robust 3D segmentation of objects in RGB-D imagery. Traditional computer vision systems face limitations in simultaneously capturing precise object boundaries and achieving high-precision object detection on depth map as they are mainly proposed for RGB cameras. To address this challenge, FusionVision adopts an integrated approach by merging state-of-the-art object detection techniques, with advanced instance segmentation methods. The integration of these components enables a holistic (unified analysis of information obtained from both color \textit{RGB} and depth \textit{D} channels) interpretation of RGB-D data, facilitating the extraction of comprehensive and accurate object information. The proposed FusionVision pipeline employs YOLO for identifying objects within the RGB image domain. Subsequently, FastSAM, an innovative semantic segmentation model, is applied to delineate object boundaries, yielding refined segmentation masks. The synergy between these components and their integration into 3D scene understanding ensures a cohesive fusion of object detection and segmentation, enhancing overall precision in 3D object segmentation. The code and pre-trained models are publicly available at https://github.com/safouaneelg/FusionVision/.
Structured Entity Extraction Using Large Language Models
Feb 06, 2024Recent advances in machine learning have significantly impacted the field of information extraction, with Large Language Models (LLMs) playing a pivotal role in extracting structured information from unstructured text. This paper explores the challenges and limitations of current methodologies in structured entity extraction and introduces a novel approach to address these issues. We contribute to the field by first introducing and formalizing the task of Structured Entity Extraction (SEE), followed by proposing Approximate Entity Set OverlaP (AESOP) Metric designed to appropriately assess model performance on this task. Later, we propose a new model that harnesses the power of LLMs for enhanced effectiveness and efficiency through decomposing the entire extraction task into multiple stages. Quantitative evaluation and human side-by-side evaluation confirm that our model outperforms baselines, offering promising directions for future advancements in structured entity extraction.
CoRelation: Boosting Automatic ICD Coding Through Contextualized Code Relation Learning
Feb 24, 2024Automatic International Classification of Diseases (ICD) coding plays a crucial role in the extraction of relevant information from clinical notes for proper recording and billing. One of the most important directions for boosting the performance of automatic ICD coding is modeling ICD code relations. However, current methods insufficiently model the intricate relationships among ICD codes and often overlook the importance of context in clinical notes. In this paper, we propose a novel approach, a contextualized and flexible framework, to enhance the learning of ICD code representations. Our approach, unlike existing methods, employs a dependent learning paradigm that considers the context of clinical notes in modeling all possible code relations. We evaluate our approach on six public ICD coding datasets and the experimental results demonstrate the effectiveness of our approach compared to state-of-the-art baselines.
YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
Feb 29, 2024Today's deep learning methods focus on how to design the most appropriate objective functions so that the prediction results of the model can be closest to the ground truth. Meanwhile, an appropriate architecture that can facilitate acquisition of enough information for prediction has to be designed. Existing methods ignore a fact that when input data undergoes layer-by-layer feature extraction and spatial transformation, large amount of information will be lost. This paper will delve into the important issues of data loss when data is transmitted through deep networks, namely information bottleneck and reversible functions. We proposed the concept of programmable gradient information (PGI) to cope with the various changes required by deep networks to achieve multiple objectives. PGI can provide complete input information for the target task to calculate objective function, so that reliable gradient information can be obtained to update network weights. In addition, a new lightweight network architecture -- Generalized Efficient Layer Aggregation Network (GELAN), based on gradient path planning is designed. GELAN's architecture confirms that PGI has gained superior results on lightweight models. We verified the proposed GELAN and PGI on MS COCO dataset based object detection. The results show that GELAN only uses conventional convolution operators to achieve better parameter utilization than the state-of-the-art methods developed based on depth-wise convolution. PGI can be used for variety of models from lightweight to large. It can be used to obtain complete information, so that train-from-scratch models can achieve better results than state-of-the-art models pre-trained using large datasets, the comparison results are shown in Figure 1. The source codes are at: https://github.com/WongKinYiu/yolov9.