 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
HyperPIE: Hyperparameter Information Extraction from Scientific Publications
Dec 17, 2023
Automatic extraction of information from publications is key to making scientific knowledge machine readable at a large scale. The extracted information can, for example, facilitate academic search, decision making, and knowledge graph construction. An important type of information not covered by existing approaches is hyperparameters. In this paper, we formalize and tackle hyperparameter information extraction (HyperPIE) as an entity recognition and relation extraction task. We create a labeled data set covering publications from a variety of computer science disciplines. Using this data set, we train and evaluate BERT-based fine-tuned models as well as five large language models: GPT-3.5, GALACTICA, Falcon, Vicuna, and WizardLM. For fine-tuned models, we develop a relation extraction approach that achieves an improvement of 29% F1 over a state-of-the-art baseline. For large language models, we develop an approach leveraging YAML output for structured data extraction, which achieves an average improvement of 5.5% F1 in entity recognition over using JSON. With our best performing model we extract hyperparameter information from a large number of unannotated papers, and analyze patterns across disciplines. All our data and source code is publicly available at https://github.com/IllDepence/hyperpie
Rethinking the Evaluation of Pre-trained Text-and-Layout Models from an Entity-Centric Perspective
Feb 04, 2024Recently developed pre-trained text-and-layout models (PTLMs) have shown remarkable success in multiple information extraction tasks on visually-rich documents. However, the prevailing evaluation pipeline may not be sufficiently robust for assessing the information extraction ability of PTLMs, due to inadequate annotations within the benchmarks. Therefore, we claim the necessary standards for an ideal benchmark to evaluate the information extraction ability of PTLMs. We then introduce EC-FUNSD, an entity-centric benckmark designed for the evaluation of semantic entity recognition and entity linking on visually-rich documents. This dataset contains diverse formats of document layouts and annotations of semantic-driven entities and their relations. Moreover, this dataset disentangles the falsely coupled annotation of segment and entity that arises from the block-level annotation of FUNSD. Experiment results demonstrate that state-of-the-art PTLMs exhibit overfitting tendencies on the prevailing benchmarks, as their performance sharply decrease when the dataset bias is removed.
Creating a Fine Grained Entity Type Taxonomy Using LLMs
Feb 19, 2024In this study, we investigate the potential of GPT-4 and its advanced iteration, GPT-4 Turbo, in autonomously developing a detailed entity type taxonomy. Our objective is to construct a comprehensive taxonomy, starting from a broad classification of entity types - including objects, time, locations, organizations, events, actions, and subjects - similar to existing manually curated taxonomies. This classification is then progressively refined through iterative prompting techniques, leveraging GPT-4's internal knowledge base. The result is an extensive taxonomy comprising over 5000 nuanced entity types, which demonstrates remarkable quality upon subjective evaluation. We employed a straightforward yet effective prompting strategy, enabling the taxonomy to be dynamically expanded. The practical applications of this detailed taxonomy are diverse and significant. It facilitates the creation of new, more intricate branches through pattern-based combinations and notably enhances information extraction tasks, such as relation extraction and event argument extraction. Our methodology not only introduces an innovative approach to taxonomy creation but also opens new avenues for applying such taxonomies in various computational linguistics and AI-related fields.
AutoIE: An Automated Framework for Information Extraction from Scientific Literature
Jan 30, 2024In the rapidly evolving field of scientific research, efficiently extracting key information from the burgeoning volume of scientific papers remains a formidable challenge. This paper introduces an innovative framework designed to automate the extraction of vital data from scientific PDF documents, enabling researchers to discern future research trajectories more readily. AutoIE uniquely integrates four novel components: (1) A multi-semantic feature fusion-based approach for PDF document layout analysis; (2) Advanced functional block recognition in scientific texts; (3) A synergistic technique for extracting and correlating information on molecular sieve synthesis; (4) An online learning paradigm tailored for molecular sieve literature. Our SBERT model achieves high Marco F1 scores of 87.19 and 89.65 on CoNLL04 and ADE datasets. In addition, a practical application of AutoIE in the petrochemical molecular sieve synthesis domain demonstrates its efficacy, evidenced by an impressive 78\% accuracy rate. This research paves the way for enhanced data management and interpretation in molecular sieve synthesis. It is a valuable asset for seasoned experts and newcomers in this specialized field.
OS-FPI: A Coarse-to-Fine One-Stream Network for UAV Geo-Localization
Mar 10, 2024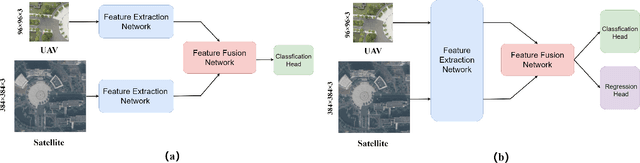
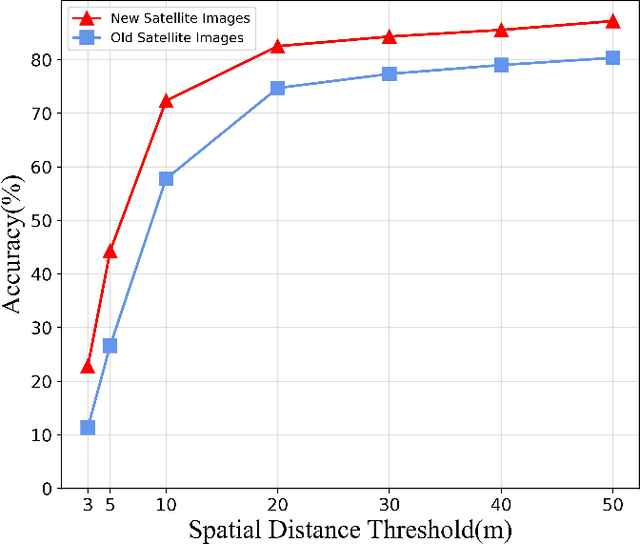
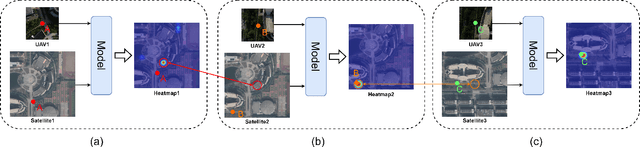
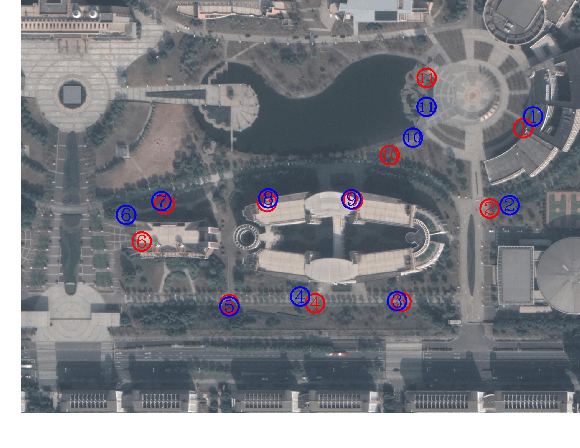
The geo-localization and navigation technology of unmanned aerial vehicles (UAVs) in denied environments is currently a prominent research area. Prior approaches mainly employed a two-stream network with non-shared weights to extract features from UAV and satellite images separately, followed by related modeling to obtain the response map. However, the two-stream network extracts UAV and satellite features independently. This approach significantly affects the efficiency of feature extraction and increases the computational load. To address these issues, we propose a novel coarse-to-fine one-stream network (OS-FPI). Our approach allows information exchange between UAV and satellite features during early image feature extraction. To improve the model's performance, the framework retains feature maps generated at different stages of the feature extraction process for the feature fusion network, and establishes additional connections between UAV and satellite feature maps in the feature fusion network. Additionally, the framework introduces offset prediction to further refine and optimize the model's prediction results based on the classification tasks. Our proposed model, boasts a similar inference speed to FPI while significantly reducing the number of parameters. It can achieve better performance with fewer parameters under the same conditions. Moreover, it achieves state-of-the-art performance on the UL14 dataset. Compared to previous models, our model achieved a significant 10.92-point improvement on the RDS metric, reaching 76.25. Furthermore, its performance in meter-level localization accuracy is impressive, with 182.62% improvement in 3-meter accuracy, 164.17% improvement in 5-meter accuracy, and 137.43% improvement in 10-meter accuracy.
SSF-Net: Spatial-Spectral Fusion Network with Spectral Angle Awareness for Hyperspectral Object Tracking
Mar 09, 2024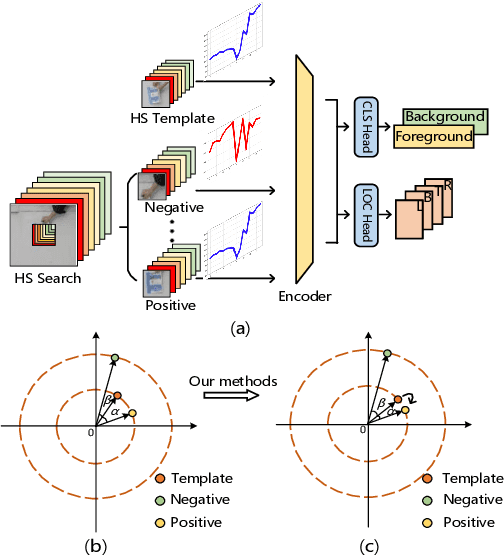
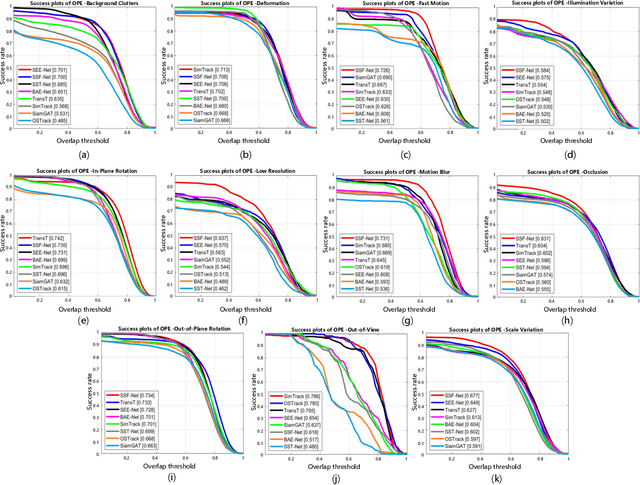
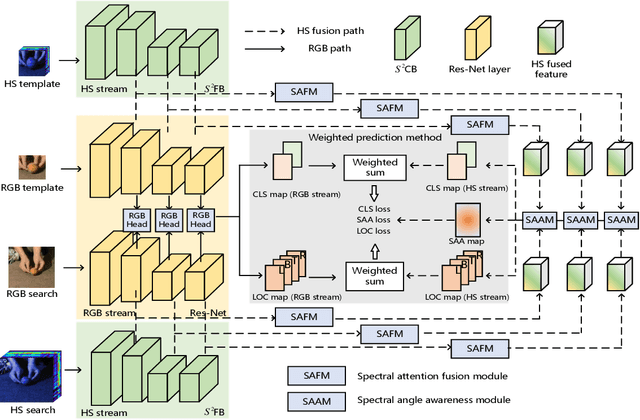
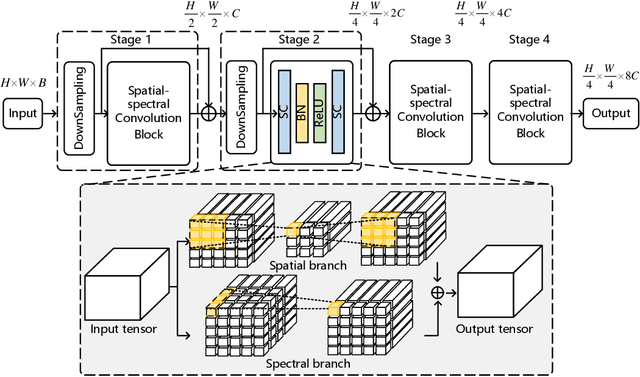
Hyperspectral video (HSV) offers valuable spatial, spectral, and temporal information simultaneously, making it highly suitable for handling challenges such as background clutter and visual similarity in object tracking. However, existing methods primarily focus on band regrouping and rely on RGB trackers for feature extraction, resulting in limited exploration of spectral information and difficulties in achieving complementary representations of object features. In this paper, a spatial-spectral fusion network with spectral angle awareness (SST-Net) is proposed for hyperspectral (HS) object tracking. Firstly, to address the issue of insufficient spectral feature extraction in existing networks, a spatial-spectral feature backbone ($S^2$FB) is designed. With the spatial and spectral extraction branch, a joint representation of texture and spectrum is obtained. Secondly, a spectral attention fusion module (SAFM) is presented to capture the intra- and inter-modality correlation to obtain the fused features from the HS and RGB modalities. It can incorporate the visual information into the HS spectral context to form a robust representation. Thirdly, to ensure a more accurate response of the tracker to the object position, a spectral angle awareness module (SAAM) investigates the region-level spectral similarity between the template and search images during the prediction stage. Furthermore, we develop a novel spectral angle awareness loss (SAAL) to offer guidance for the SAAM based on similar regions. Finally, to obtain the robust tracking results, a weighted prediction method is considered to combine the HS and RGB predicted motions of objects to leverage the strengths of each modality. Extensive experiments on the HOTC dataset demonstrate the effectiveness of the proposed SSF-Net, compared with state-of-the-art trackers.
Fine Tuning Named Entity Extraction Models for the Fantasy Domain
Feb 16, 2024Named Entity Recognition (NER) is a sequence classification Natural Language Processing task where entities are identified in the text and classified into predefined categories. It acts as a foundation for most information extraction systems. Dungeons and Dragons (D&D) is an open-ended tabletop fantasy game with its own diverse lore. DnD entities are domain-specific and are thus unrecognizable by even the state-of-the-art off-the-shelf NER systems as the NER systems are trained on general data for pre-defined categories such as: person (PERS), location (LOC), organization (ORG), and miscellaneous (MISC). For meaningful extraction of information from fantasy text, the entities need to be classified into domain-specific entity categories as well as the models be fine-tuned on a domain-relevant corpus. This work uses available lore of monsters in the D&D domain to fine-tune Trankit, which is a prolific NER framework that uses a pre-trained model for NER. Upon this training, the system acquires the ability to extract monster names from relevant domain documents under a novel NER tag. This work compares the accuracy of the monster name identification against; the zero-shot Trankit model and two FLAIR models. The fine-tuned Trankit model achieves an 87.86% F1 score surpassing all the other considered models.
Are LLMs Ready for Real-World Materials Discovery?
Feb 07, 2024Large Language Models (LLMs) create exciting possibilities for powerful language processing tools to accelerate research in materials science. While LLMs have great potential to accelerate materials understanding and discovery, they currently fall short in being practical materials science tools. In this position paper, we show relevant failure cases of LLMs in materials science that reveal current limitations of LLMs related to comprehending and reasoning over complex, interconnected materials science knowledge. Given those shortcomings, we outline a framework for developing Materials Science LLMs (MatSci-LLMs) that are grounded in materials science knowledge and hypothesis generation followed by hypothesis testing. The path to attaining performant MatSci-LLMs rests in large part on building high-quality, multi-modal datasets sourced from scientific literature where various information extraction challenges persist. As such, we describe key materials science information extraction challenges which need to be overcome in order to build large-scale, multi-modal datasets that capture valuable materials science knowledge. Finally, we outline a roadmap for applying future MatSci-LLMs for real-world materials discovery via: 1. Automated Knowledge Base Generation; 2. Automated In-Silico Material Design; and 3. MatSci-LLM Integrated Self-Driving Materials Laboratories.
Online Adaptation of Language Models with a Memory of Amortized Contexts
Mar 07, 2024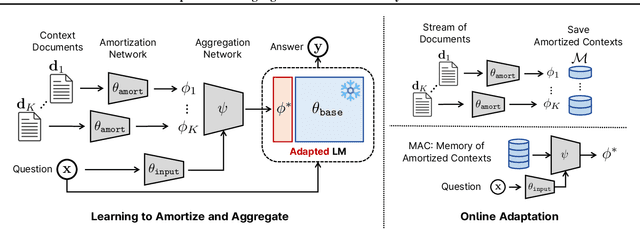
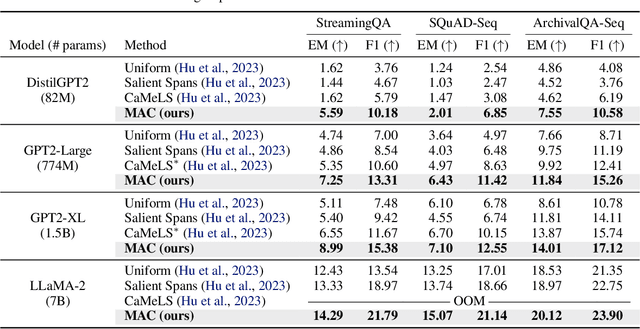

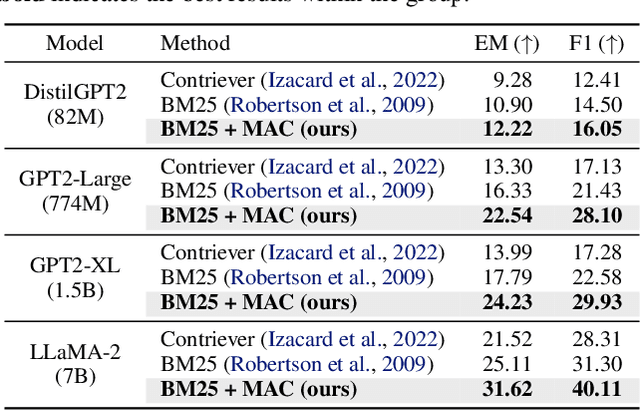
Due to the rapid generation and dissemination of information, large language models (LLMs) quickly run out of date despite enormous development costs. Due to this crucial need to keep models updated, online learning has emerged as a critical necessity when utilizing LLMs for real-world applications. However, given the ever-expanding corpus of unseen documents and the large parameter space of modern LLMs, efficient adaptation is essential. To address these challenges, we propose Memory of Amortized Contexts (MAC), an efficient and effective online adaptation framework for LLMs with strong knowledge retention. We propose an amortized feature extraction and memory-augmentation approach to compress and extract information from new documents into compact modulations stored in a memory bank. When answering questions, our model attends to and extracts relevant knowledge from this memory bank. To learn informative modulations in an efficient manner, we utilize amortization-based meta-learning, which substitutes the optimization process with a single forward pass of the encoder. Subsequently, we learn to choose from and aggregate selected documents into a single modulation by conditioning on the question, allowing us to adapt a frozen language model during test time without requiring further gradient updates. Our experiment demonstrates the superiority of MAC in multiple aspects, including online adaptation performance, time, and memory efficiency. Code is available at: https://github.com/jihoontack/MAC.
Punctuation Restoration Improves Structure Understanding without Supervision
Feb 13, 2024Unsupervised learning objectives like language modeling and de-noising constitute a significant part in producing pre-trained models that perform various downstream applications from natural language understanding to conversational tasks. However, despite impressive conversational capabilities of recent large language model, their abilities to capture syntactic or semantic structure within text lag behind. We hypothesize that the mismatch between linguistic performance and competence in machines is attributable to insufficient transfer of linguistic structure knowledge to computational systems with currently popular pre-training objectives. We show that punctuation restoration transfers to improvements in in- and out-of-distribution performance on structure-related tasks like named entity recognition, open information extraction, chunking, and part-of-speech tagging. Punctuation restoration is an effective learning objective that can improve structure understanding and yield a more robust structure-aware representations of natural language.