 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
EnrichEvent: Enriching Social Data with Contextual Information for Emerging Event Extraction
Aug 16, 2023
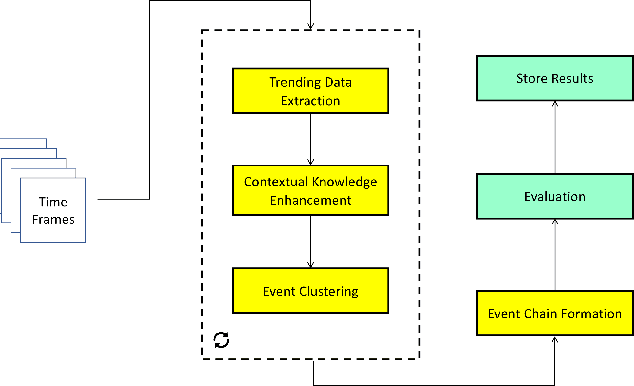
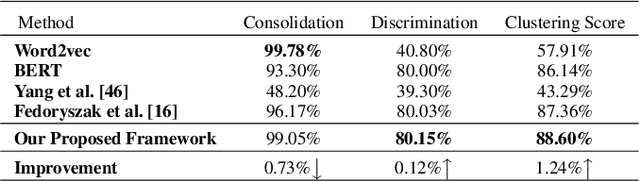
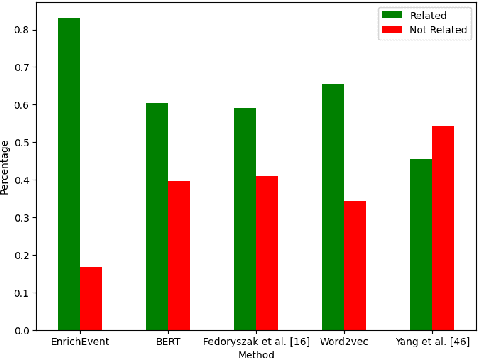
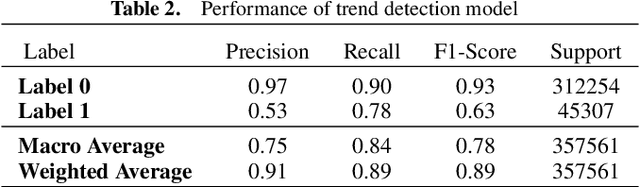
Social platforms have emerged as crucial platforms for disseminating information and discussing real-life social events, which offers an excellent opportunity for researchers to design and implement novel event detection frameworks. However, most existing approaches merely exploit keyword burstiness or network structures to detect unspecified events. Thus, they often fail to identify unspecified events regarding the challenging nature of events and social data. Social data, e.g., tweets, is characterized by misspellings, incompleteness, word sense ambiguation, and irregular language, as well as variation in aspects of opinions. Moreover, extracting discriminative features and patterns for evolving events by exploiting the limited structural knowledge is almost infeasible. To address these challenges, in this thesis, we propose a novel framework, namely EnrichEvent, that leverages the lexical and contextual representations of streaming social data. In particular, we leverage contextual knowledge, as well as lexical knowledge, to detect semantically related tweets and enhance the effectiveness of the event detection approaches. Eventually, our proposed framework produces cluster chains for each event to show the evolving variation of the event through time. We conducted extensive experiments to evaluate our framework, validating its high performance and effectiveness in detecting and distinguishing unspecified social events.
The Multimodal Information Based Speech Processing (MISP) 2023 Challenge: Audio-Visual Target Speaker Extraction
Sep 15, 2023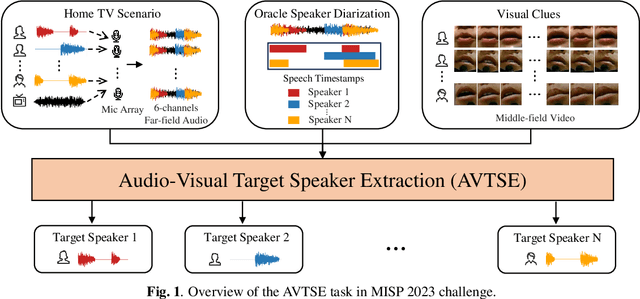
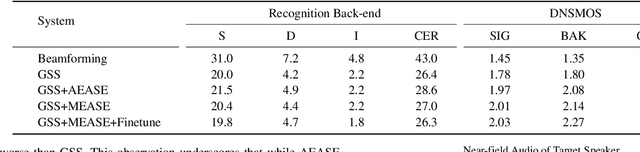
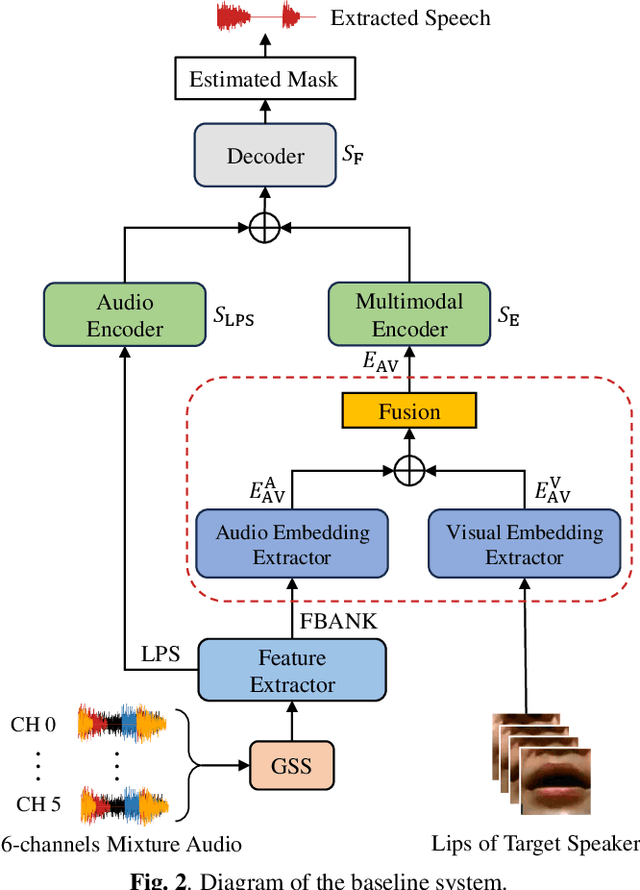
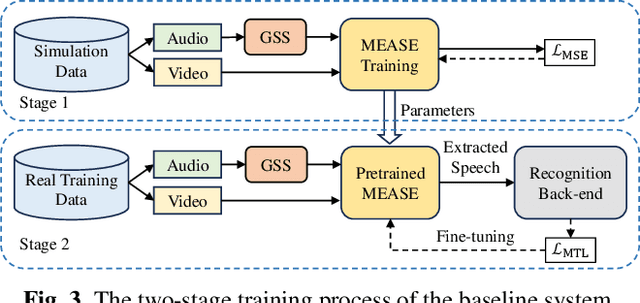
Previous Multimodal Information based Speech Processing (MISP) challenges mainly focused on audio-visual speech recognition (AVSR) with commendable success. However, the most advanced back-end recognition systems often hit performance limits due to the complex acoustic environments. This has prompted a shift in focus towards the Audio-Visual Target Speaker Extraction (AVTSE) task for the MISP 2023 challenge in ICASSP 2024 Signal Processing Grand Challenges. Unlike existing audio-visual speech enhance-ment challenges primarily focused on simulation data, the MISP 2023 challenge uniquely explores how front-end speech processing, combined with visual clues, impacts back-end tasks in real-world scenarios. This pioneering effort aims to set the first benchmark for the AVTSE task, offering fresh insights into enhancing the ac-curacy of back-end speech recognition systems through AVTSE in challenging and real acoustic environments. This paper delivers a thorough overview of the task setting, dataset, and baseline system of the MISP 2023 challenge. It also includes an in-depth analysis of the challenges participants may encounter. The experimental results highlight the demanding nature of this task, and we look forward to the innovative solutions participants will bring forward.
Large Scale Genealogical Information Extraction From Handwritten Quebec Parish Records
Apr 27, 2023This paper presents a complete workflow designed for extracting information from Quebec handwritten parish registers. The acts in these documents contain individual and family information highly valuable for genetic, demographic and social studies of the Quebec population. From an image of parish records, our workflow is able to identify the acts and extract personal information. The workflow is divided into successive steps: page classification, text line detection, handwritten text recognition, named entity recognition and act detection and classification. For all these steps, different machine learning models are compared. Once the information is extracted, validation rules designed by experts are then applied to standardize the extracted information and ensure its consistency with the type of act (birth, marriage, and death). This validation step is able to reject records that are considered invalid or merged. The full workflow has been used to process over two million pages of Quebec parish registers from the 19-20th centuries. On a sample comprising 65% of registers, 3.2 million acts were recognized. Verification of the birth and death acts from this sample shows that 74% of them are considered complete and valid. These records will be integrated into the BALSAC database and linked together to recreate family and genealogical relations at large scale.
EntropyRank: Unsupervised Keyphrase Extraction via Side-Information Optimization for Language Model-based Text Compression
Aug 29, 2023We propose an unsupervised method to extract keywords and keyphrases from texts based on a pre-trained language model (LM) and Shannon's information maximization. Specifically, our method extracts phrases having the highest conditional entropy under the LM. The resulting set of keyphrases turns out to solve a relevant information-theoretic problem: if provided as side information, it leads to the expected minimal binary code length in compressing the text using the LM and an entropy encoder. Alternately, the resulting set is an approximation via a causal LM to the set of phrases that minimize the entropy of the text when conditioned upon it. Empirically, the method provides results comparable to the most commonly used methods in various keyphrase extraction benchmark challenges.
Automatic Error Analysis for Document-level Information Extraction
Sep 15, 2022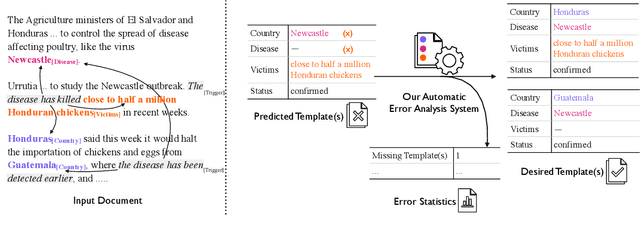
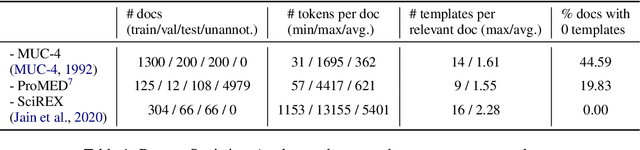
Document-level information extraction (IE) tasks have recently begun to be revisited in earnest using the end-to-end neural network techniques that have been successful on their sentence-level IE counterparts. Evaluation of the approaches, however, has been limited in a number of dimensions. In particular, the precision/recall/F1 scores typically reported provide few insights on the range of errors the models make. We build on the work of Kummerfeld and Klein (2013) to propose a transformation-based framework for automating error analysis in document-level event and (N-ary) relation extraction. We employ our framework to compare two state-of-the-art document-level template-filling approaches on datasets from three domains; and then, to gauge progress in IE since its inception 30 years ago, vs. four systems from the MUC-4 (1992) evaluation.
* Accepted to ACL 2022 Main Conference. First three authors contributed equally to this work
Video Infringement Detection via Feature Disentanglement and Mutual Information Maximization
Sep 13, 2023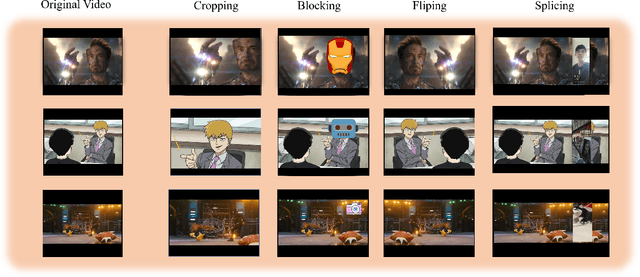
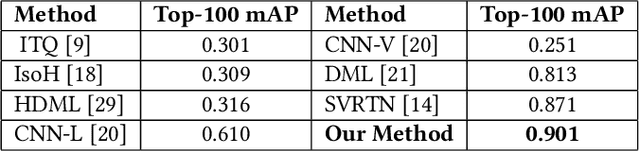
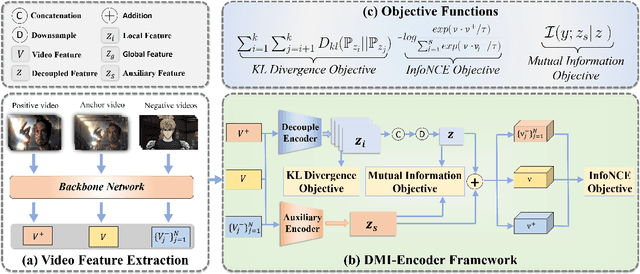
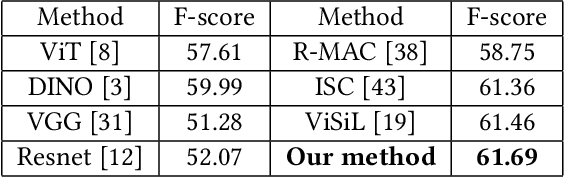
The self-media era provides us tremendous high quality videos. Unfortunately, frequent video copyright infringements are now seriously damaging the interests and enthusiasm of video creators. Identifying infringing videos is therefore a compelling task. Current state-of-the-art methods tend to simply feed high-dimensional mixed video features into deep neural networks and count on the networks to extract useful representations. Despite its simplicity, this paradigm heavily relies on the original entangled features and lacks constraints guaranteeing that useful task-relevant semantics are extracted from the features. In this paper, we seek to tackle the above challenges from two aspects: (1) We propose to disentangle an original high-dimensional feature into multiple sub-features, explicitly disentangling the feature into exclusive lower-dimensional components. We expect the sub-features to encode non-overlapping semantics of the original feature and remove redundant information. (2) On top of the disentangled sub-features, we further learn an auxiliary feature to enhance the sub-features. We theoretically analyzed the mutual information between the label and the disentangled features, arriving at a loss that maximizes the extraction of task-relevant information from the original feature. Extensive experiments on two large-scale benchmark datasets (i.e., SVD and VCSL) demonstrate that our method achieves 90.1% TOP-100 mAP on the large-scale SVD dataset and also sets the new state-of-the-art on the VCSL benchmark dataset. Our code and model have been released at https://github.com/yyyooooo/DMI/, hoping to contribute to the community.
TRIE++: Towards End-to-End Information Extraction from Visually Rich Documents
Jul 14, 2022
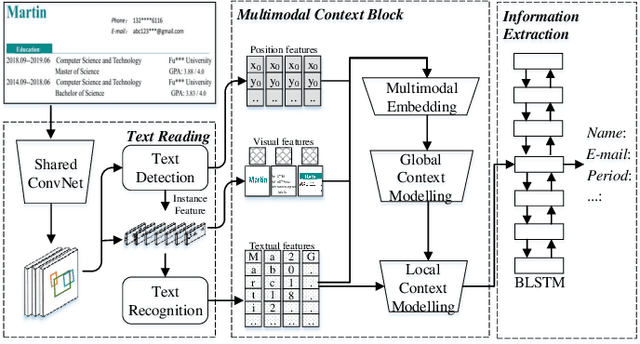
Recently, automatically extracting information from visually rich documents (e.g., tickets and resumes) has become a hot and vital research topic due to its widespread commercial value. Most existing methods divide this task into two subparts: the text reading part for obtaining the plain text from the original document images and the information extraction part for extracting key contents. These methods mainly focus on improving the second, while neglecting that the two parts are highly correlated. This paper proposes a unified end-to-end information extraction framework from visually rich documents, where text reading and information extraction can reinforce each other via a well-designed multi-modal context block. Specifically, the text reading part provides multi-modal features like visual, textual and layout features. The multi-modal context block is developed to fuse the generated multi-modal features and even the prior knowledge from the pre-trained language model for better semantic representation. The information extraction part is responsible for generating key contents with the fused context features. The framework can be trained in an end-to-end trainable manner, achieving global optimization. What is more, we define and group visually rich documents into four categories across two dimensions, the layout and text type. For each document category, we provide or recommend the corresponding benchmarks, experimental settings and strong baselines for remedying the problem that this research area lacks the uniform evaluation standard. Extensive experiments on four kinds of benchmarks (from fixed layout to variable layout, from full-structured text to semi-unstructured text) are reported, demonstrating the proposed method's effectiveness. Data, source code and models are available.
Coordinate-based neural representations for computational adaptive optics in widefield microscopy
Jul 07, 2023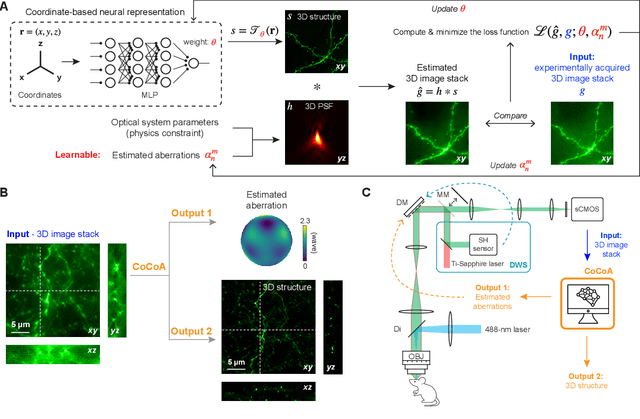
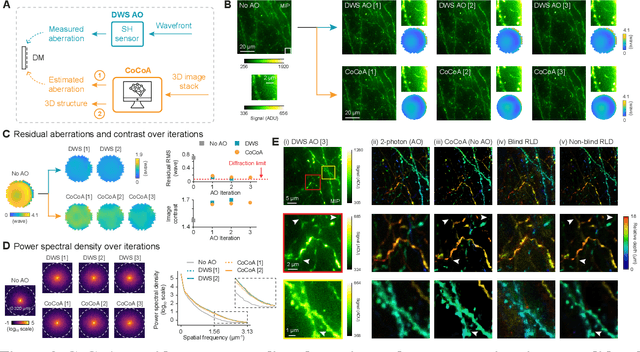
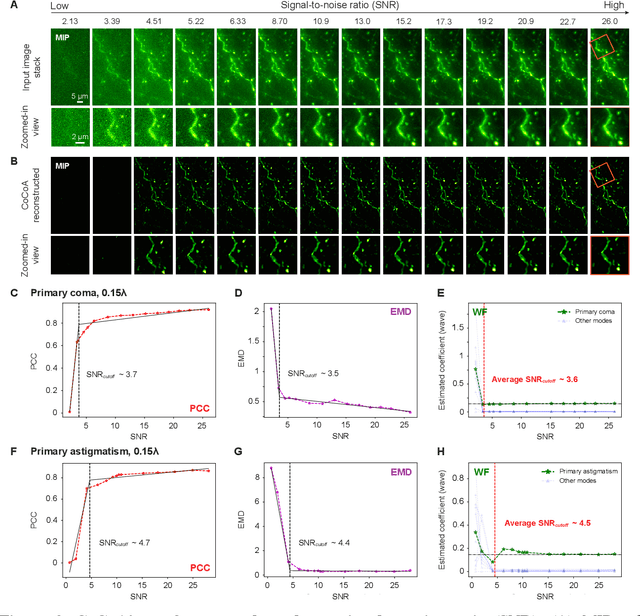
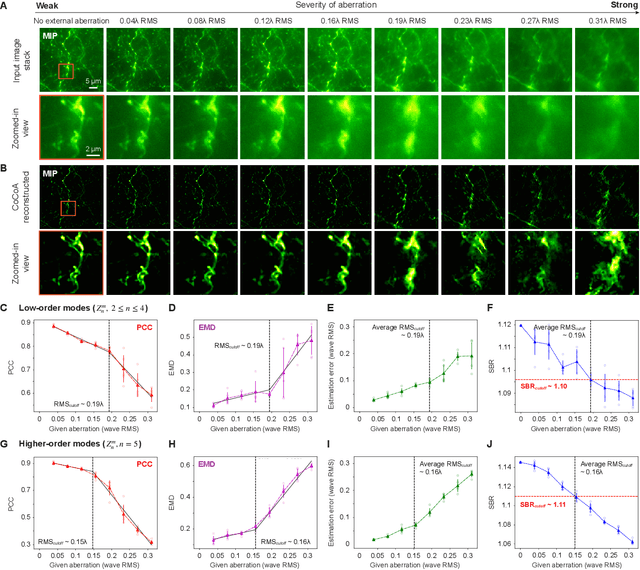
Widefield microscopy is widely used for non-invasive imaging of biological structures at subcellular resolution. When applied to complex specimen, its image quality is degraded by sample-induced optical aberration. Adaptive optics can correct wavefront distortion and restore diffraction-limited resolution but require wavefront sensing and corrective devices, increasing system complexity and cost. Here, we describe a self-supervised machine learning algorithm, CoCoA, that performs joint wavefront estimation and three-dimensional structural information extraction from a single input 3D image stack without the need for external training dataset. We implemented CoCoA for widefield imaging of mouse brain tissues and validated its performance with direct-wavefront-sensing-based adaptive optics. Importantly, we systematically explored and quantitatively characterized the limiting factors of CoCoA's performance. Using CoCoA, we demonstrated the first in vivo widefield mouse brain imaging using machine-learning-based adaptive optics. Incorporating coordinate-based neural representations and a forward physics model, the self-supervised scheme of CoCoA should be applicable to microscopy modalities in general.
A Human-in-the-Loop Approach for Information Extraction from Privacy Policies under Data Scarcity
May 24, 2023
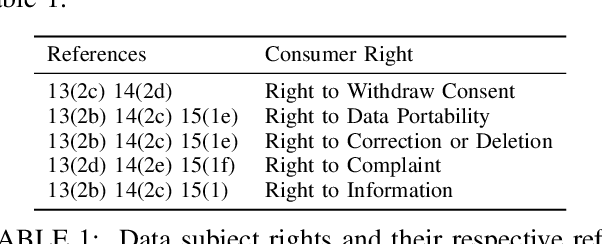
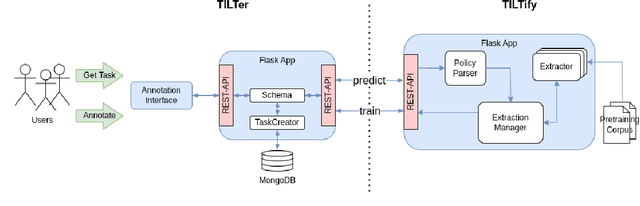
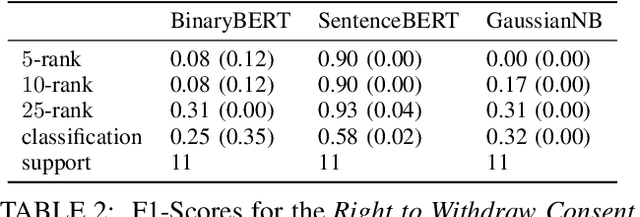
Machine-readable representations of privacy policies are door openers for a broad variety of novel privacy-enhancing and, in particular, transparency-enhancing technologies (TETs). In order to generate such representations, transparency information needs to be extracted from written privacy policies. However, respective manual annotation and extraction processes are laborious and require expert knowledge. Approaches for fully automated annotation, in turn, have so far not succeeded due to overly high error rates in the specific domain of privacy policies. In the end, a lack of properly annotated privacy policies and respective machine-readable representations persists and enduringly hinders the development and establishment of novel technical approaches fostering policy perception and data subject informedness. In this work, we present a prototype system for a `Human-in-the-Loop' approach to privacy policy annotation that integrates ML-generated suggestions and ultimately human annotation decisions. We propose an ML-based suggestion system specifically tailored to the constraint of data scarcity prevalent in the domain of privacy policy annotation. On this basis, we provide meaningful predictions to users thereby streamlining the annotation process. Additionally, we also evaluate our approach through a prototypical implementation to show that our ML-based extraction approach provides superior performance over other recently used extraction models for legal documents.
Speech Emotion Recognition with Distilled Prosodic and Linguistic Affect Representations
Sep 09, 2023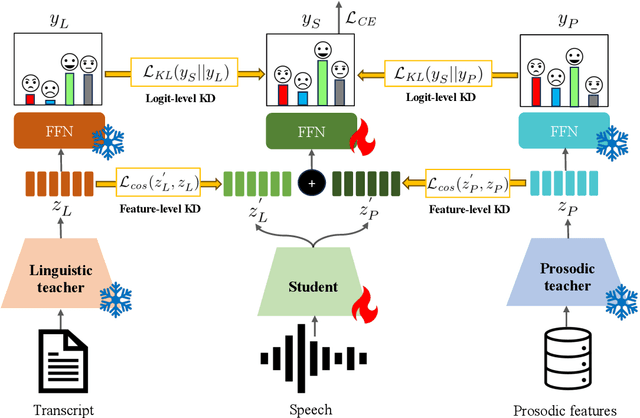
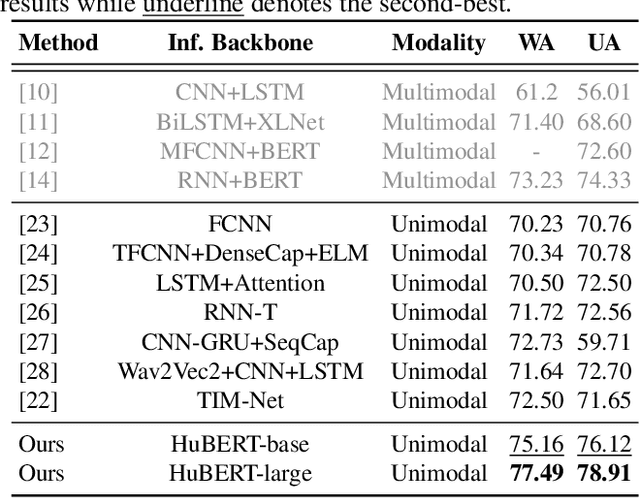
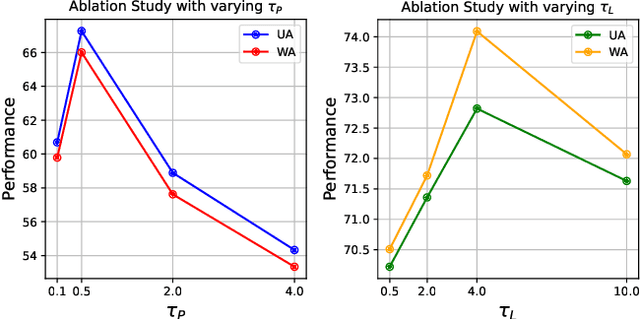
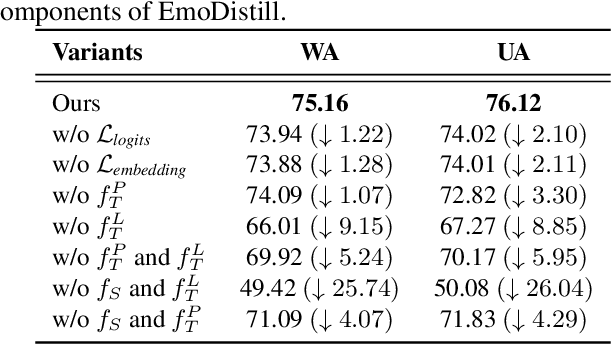
We propose EmoDistill, a novel speech emotion recognition (SER) framework that leverages cross-modal knowledge distillation during training to learn strong linguistic and prosodic representations of emotion from speech. During inference, our method only uses a stream of speech signals to perform unimodal SER thus reducing computation overhead and avoiding run-time transcription and prosodic feature extraction errors. During training, our method distills information at both embedding and logit levels from a pair of pre-trained Prosodic and Linguistic teachers that are fine-tuned for SER. Experiments on the IEMOCAP benchmark demonstrate that our method outperforms other unimodal and multimodal techniques by a considerable margin, and achieves state-of-the-art performance of 77.49% unweighted accuracy and 78.91% weighted accuracy. Detailed ablation studies demonstrate the impact of each component of our method.