 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Impact of translation on biomedical information extraction from real-life clinical notes
Jun 03, 2023
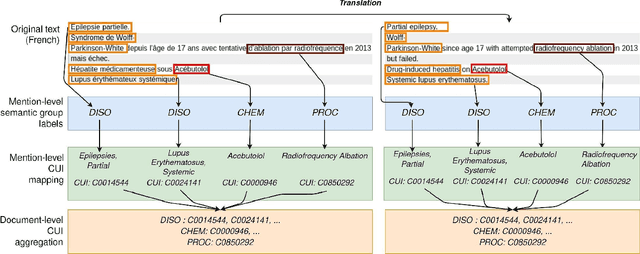
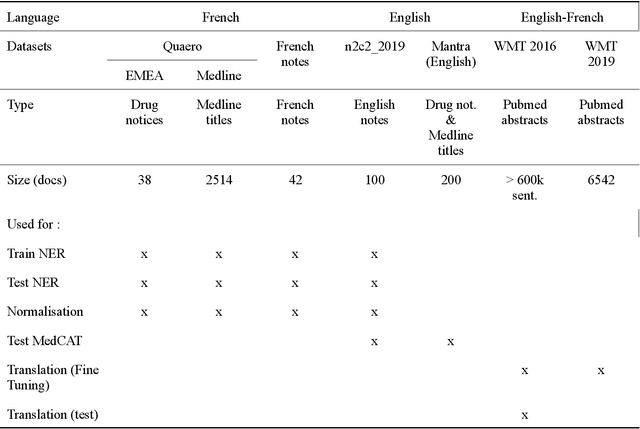
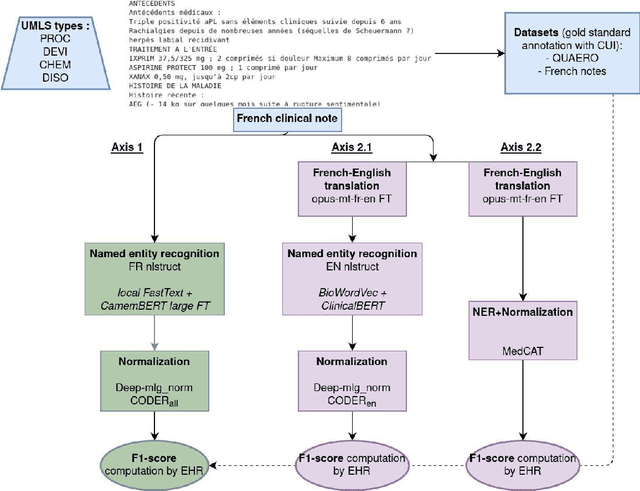
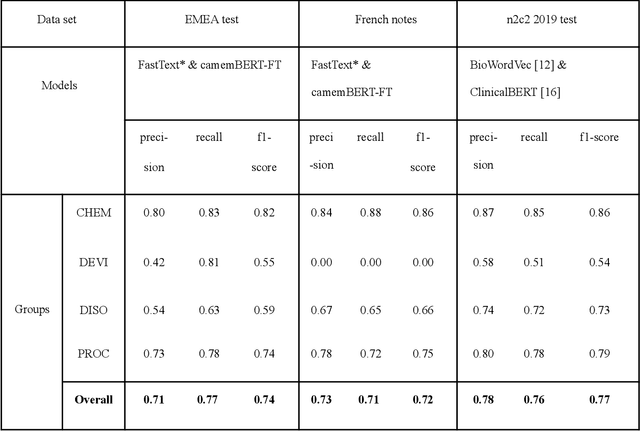
The objective of our study is to determine whether using English tools to extract and normalize French medical concepts on translations provides comparable performance to French models trained on a set of annotated French clinical notes. We compare two methods: a method involving French language models and a method involving English language models. For the native French method, the Named Entity Recognition (NER) and normalization steps are performed separately. For the translated English method, after the first translation step, we compare a two-step method and a terminology-oriented method that performs extraction and normalization at the same time. We used French, English and bilingual annotated datasets to evaluate all steps (NER, normalization and translation) of our algorithms. Concerning the results, the native French method performs better than the translated English one with a global f1 score of 0.51 [0.47;0.55] against 0.39 [0.34;0.44] and 0.38 [0.36;0.40] for the two English methods tested. In conclusion, despite the recent improvement of the translation models, there is a significant performance difference between the two approaches in favor of the native French method which is more efficient on French medical texts, even with few annotated documents.
Local-Global Temporal Fusion Network with an Attention Mechanism for Multiple and Multiclass Arrhythmia Classification
Aug 03, 2023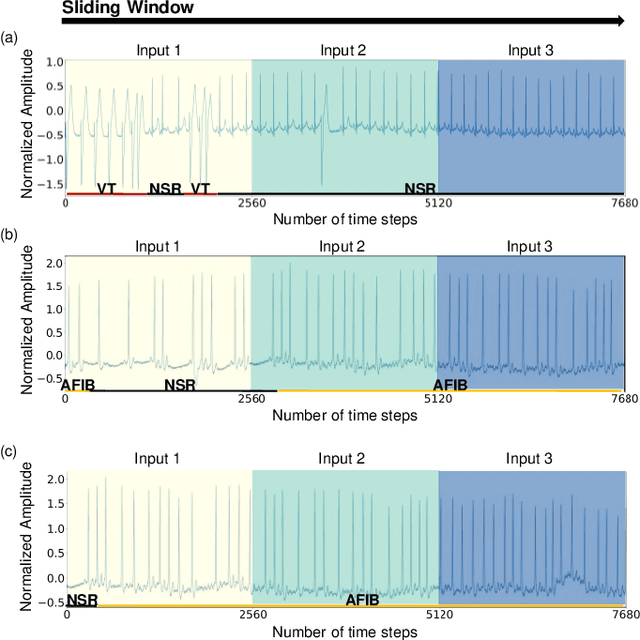
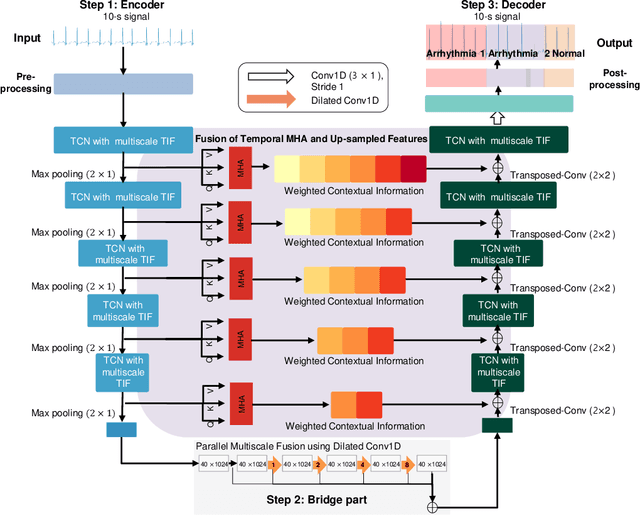
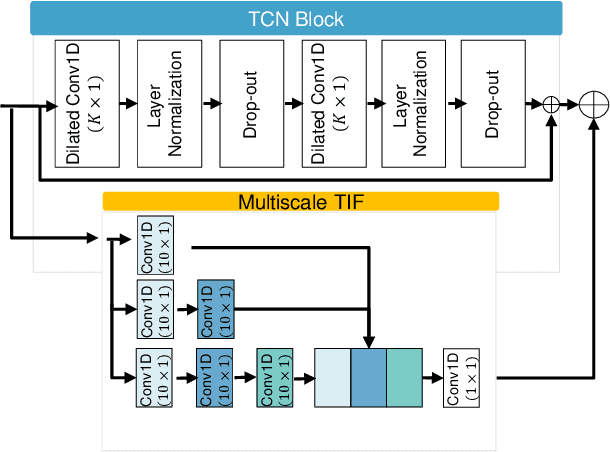
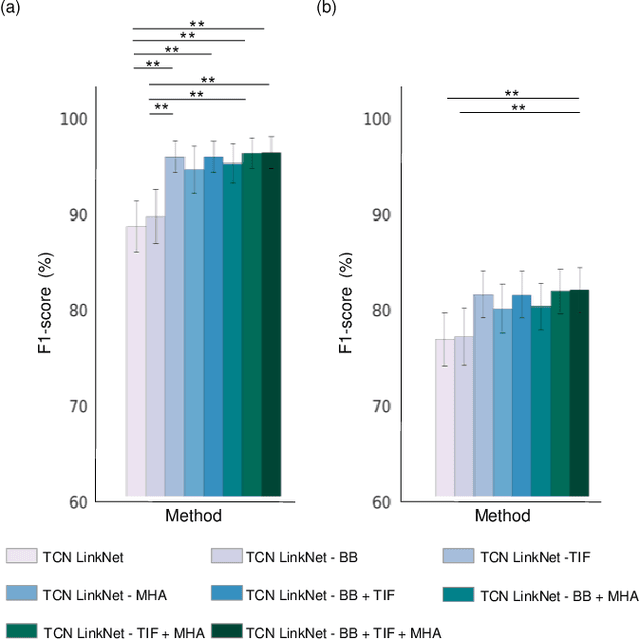
Clinical decision support systems (CDSSs) have been widely utilized to support the decisions made by cardiologists when detecting and classifying arrhythmia from electrocardiograms (ECGs). However, forming a CDSS for the arrhythmia classification task is challenging due to the varying lengths of arrhythmias. Although the onset time of arrhythmia varies, previously developed methods have not considered such conditions. Thus, we propose a framework that consists of (i) local temporal information extraction, (ii) global pattern extraction, and (iii) local-global information fusion with attention to perform arrhythmia detection and classification with a constrained input length. The 10-class and 4-class performances of our approach were assessed by detecting the onset and offset of arrhythmia as an episode and the duration of arrhythmia based on the MIT-BIH arrhythmia database (MITDB) and MIT-BIH atrial fibrillation database (AFDB), respectively. The results were statistically superior to those achieved by the comparison models. To check the generalization ability of the proposed method, an AFDB-trained model was tested on the MITDB, and superior performance was attained compared with that of a state-of-the-art model. The proposed method can capture local-global information and dynamics without incurring information losses. Therefore, arrhythmias can be recognized more accurately, and their occurrence times can be calculated; thus, the clinical field can create more accurate treatment plans by using the proposed method.
Fetal-BET: Brain Extraction Tool for Fetal MRI
Oct 02, 2023Fetal brain extraction is a necessary first step in most computational fetal brain MRI pipelines. However, it has been a very challenging task due to non-standard fetal head pose, fetal movements during examination, and vastly heterogeneous appearance of the developing fetal brain and the neighboring fetal and maternal anatomy across various sequences and scanning conditions. Development of a machine learning method to effectively address this task requires a large and rich labeled dataset that has not been previously available. As a result, there is currently no method for accurate fetal brain extraction on various fetal MRI sequences. In this work, we first built a large annotated dataset of approximately 72,000 2D fetal brain MRI images. Our dataset covers the three common MRI sequences including T2-weighted, diffusion-weighted, and functional MRI acquired with different scanners. Moreover, it includes normal and pathological brains. Using this dataset, we developed and validated deep learning methods, by exploiting the power of the U-Net style architectures, the attention mechanism, multi-contrast feature learning, and data augmentation for fast, accurate, and generalizable automatic fetal brain extraction. Our approach leverages the rich information from multi-contrast (multi-sequence) fetal MRI data, enabling precise delineation of the fetal brain structures. Evaluations on independent test data show that our method achieves accurate brain extraction on heterogeneous test data acquired with different scanners, on pathological brains, and at various gestational stages. This robustness underscores the potential utility of our deep learning model for fetal brain imaging and image analysis.
Multi-scale Promoted Self-adjusting Correlation Learning for Facial Action Unit Detection
Aug 15, 2023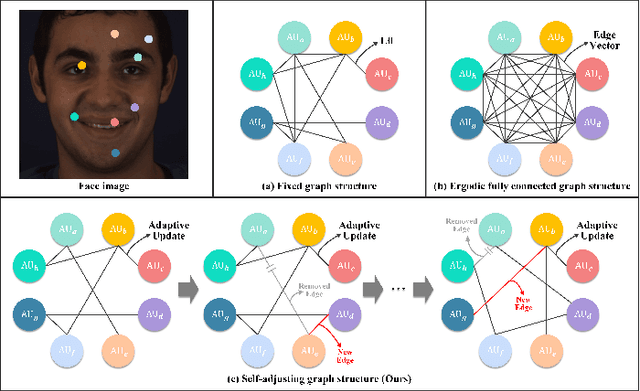
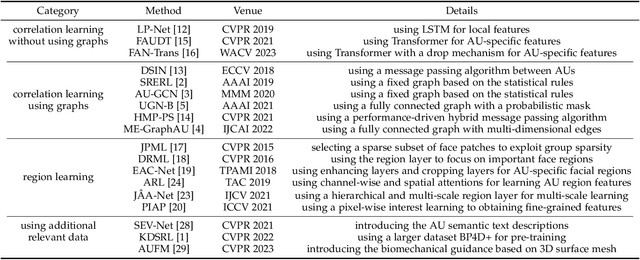
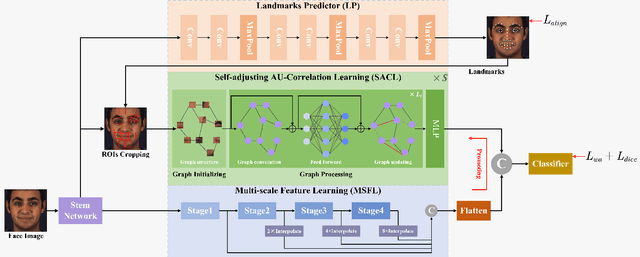
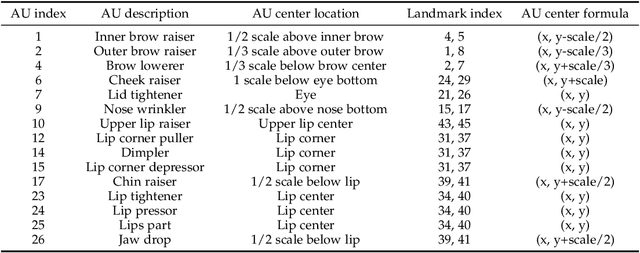
Facial Action Unit (AU) detection is a crucial task in affective computing and social robotics as it helps to identify emotions expressed through facial expressions. Anatomically, there are innumerable correlations between AUs, which contain rich information and are vital for AU detection. Previous methods used fixed AU correlations based on expert experience or statistical rules on specific benchmarks, but it is challenging to comprehensively reflect complex correlations between AUs via hand-crafted settings. There are alternative methods that employ a fully connected graph to learn these dependencies exhaustively. However, these approaches can result in a computational explosion and high dependency with a large dataset. To address these challenges, this paper proposes a novel self-adjusting AU-correlation learning (SACL) method with less computation for AU detection. This method adaptively learns and updates AU correlation graphs by efficiently leveraging the characteristics of different levels of AU motion and emotion representation information extracted in different stages of the network. Moreover, this paper explores the role of multi-scale learning in correlation information extraction, and design a simple yet effective multi-scale feature learning (MSFL) method to promote better performance in AU detection. By integrating AU correlation information with multi-scale features, the proposed method obtains a more robust feature representation for the final AU detection. Extensive experiments show that the proposed method outperforms the state-of-the-art methods on widely used AU detection benchmark datasets, with only 28.7\% and 12.0\% of the parameters and FLOPs of the best method, respectively. The code for this method is available at \url{https://github.com/linuxsino/Self-adjusting-AU}.
tieval: An Evaluation Framework for Temporal Information Extraction Systems
Jan 11, 2023
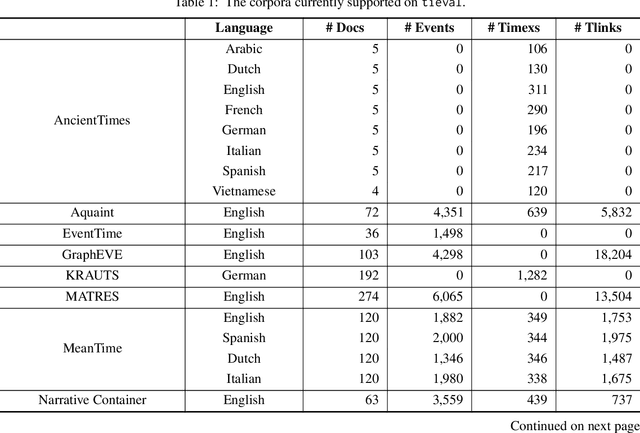

Temporal information extraction (TIE) has attracted a great deal of interest over the last two decades, leading to the development of a significant number of datasets. Despite its benefits, having access to a large volume of corpora makes it difficult when it comes to benchmark TIE systems. On the one hand, different datasets have different annotation schemes, thus hindering the comparison between competitors across different corpora. On the other hand, the fact that each corpus is commonly disseminated in a different format requires a considerable engineering effort for a researcher/practitioner to develop parsers for all of them. This constraint forces researchers to select a limited amount of datasets to evaluate their systems which consequently limits the comparability of the systems. Yet another obstacle that hinders the comparability of the TIE systems is the evaluation metric employed. While most research works adopt traditional metrics such as precision, recall, and $F_1$, a few others prefer temporal awareness -- a metric tailored to be more comprehensive on the evaluation of temporal systems. Although the reason for the absence of temporal awareness in the evaluation of most systems is not clear, one of the factors that certainly weights this decision is the necessity to implement the temporal closure algorithm in order to compute temporal awareness, which is not straightforward to implement neither is currently easily available. All in all, these problems have limited the fair comparison between approaches and consequently, the development of temporal extraction systems. To mitigate these problems, we have developed tieval, a Python library that provides a concise interface for importing different corpora and facilitates system evaluation. In this paper, we present the first public release of tieval and highlight its most relevant features.
Explaining Relation Classification Models with Semantic Extents
Aug 04, 2023In recent years, the development of large pretrained language models, such as BERT and GPT, significantly improved information extraction systems on various tasks, including relation classification. State-of-the-art systems are highly accurate on scientific benchmarks. A lack of explainability is currently a complicating factor in many real-world applications. Comprehensible systems are necessary to prevent biased, counterintuitive, or harmful decisions. We introduce semantic extents, a concept to analyze decision patterns for the relation classification task. Semantic extents are the most influential parts of texts concerning classification decisions. Our definition allows similar procedures to determine semantic extents for humans and models. We provide an annotation tool and a software framework to determine semantic extents for humans and models conveniently and reproducibly. Comparing both reveals that models tend to learn shortcut patterns from data. These patterns are hard to detect with current interpretability methods, such as input reductions. Our approach can help detect and eliminate spurious decision patterns during model development. Semantic extents can increase the reliability and security of natural language processing systems. Semantic extents are an essential step in enabling applications in critical areas like healthcare or finance. Moreover, our work opens new research directions for developing methods to explain deep learning models.
Neural Approaches to Entity-Centric Information Extraction
Apr 15, 2023

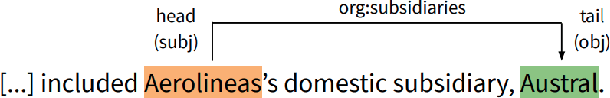
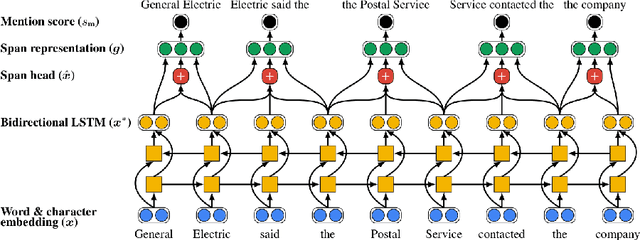
Artificial Intelligence (AI) has huge impact on our daily lives with applications such as voice assistants, facial recognition, chatbots, autonomously driving cars, etc. Natural Language Processing (NLP) is a cross-discipline of AI and Linguistics, dedicated to study the understanding of the text. This is a very challenging area due to unstructured nature of the language, with many ambiguous and corner cases. In this thesis we address a very specific area of NLP that involves the understanding of entities (e.g., names of people, organizations, locations) in text. First, we introduce a radically different, entity-centric view of the information in text. We argue that instead of using individual mentions in text to understand their meaning, we should build applications that would work in terms of entity concepts. Next, we present a more detailed model on how the entity-centric approach can be used for the entity linking task. In our work, we show that this task can be improved by considering performing entity linking at the coreference cluster level rather than each of the mentions individually. In our next work, we further study how information from Knowledge Base entities can be integrated into text. Finally, we analyze the evolution of the entities from the evolving temporal perspective.
Joint Information Extraction with Cross-Task and Cross-Instance High-Order Modeling
Dec 17, 2022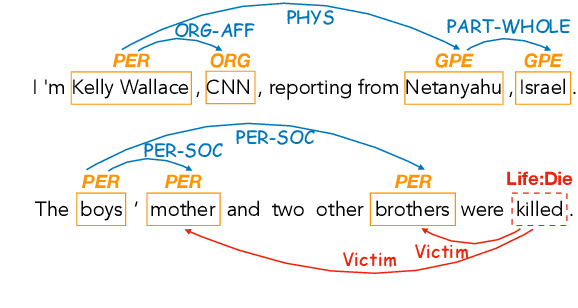
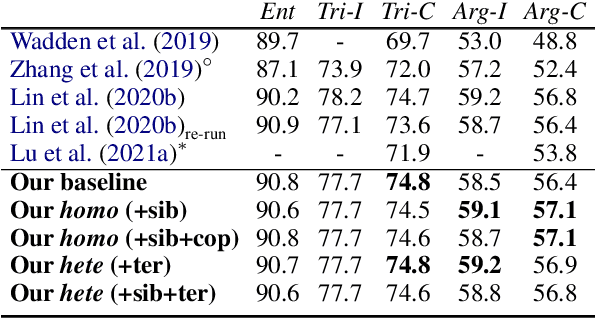
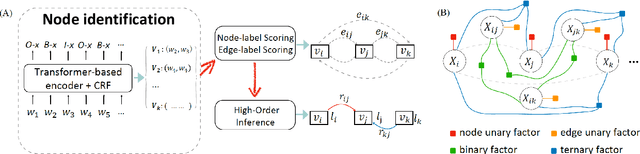
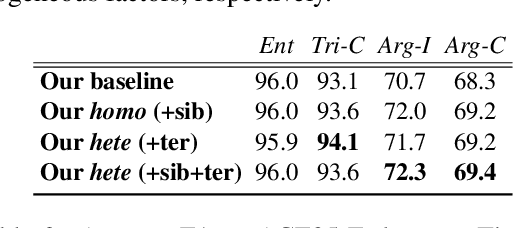
Prior works on Information Extraction (IE) typically predict different tasks and instances (e.g., event triggers, entities, roles, relations) independently, while neglecting their interactions and leading to model inefficiency. In this work, we introduce a joint IE framework, HighIE, that learns and predicts multiple IE tasks by integrating high-order cross-task and cross-instance dependencies. Specifically, we design two categories of high-order factors: homogeneous factors and heterogeneous factors. Then, these factors are utilized to jointly predict labels of all instances. To address the intractability problem of exact high-order inference, we incorporate a high-order neural decoder that is unfolded from a mean-field variational inference method. The experimental results show that our approach achieves consistent improvements on three IE tasks compared with our baseline and prior work.
DocILE Benchmark for Document Information Localization and Extraction
Feb 11, 2023

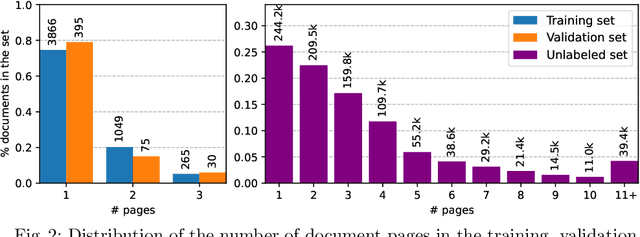

This paper introduces the DocILE benchmark with the largest dataset of business documents for the tasks of Key Information Localization and Extraction and Line Item Recognition. It contains 6.7k annotated business documents, 100k synthetically generated documents, and nearly~1M unlabeled documents for unsupervised pre-training. The dataset has been built with knowledge of domain- and task-specific aspects, resulting in the following key features: (i) annotations in 55 classes, which surpasses the granularity of previously published key information extraction datasets by a large margin; (ii) Line Item Recognition represents a highly practical information extraction task, where key information has to be assigned to items in a table; (iii) documents come from numerous layouts and the test set includes zero- and few-shot cases as well as layouts commonly seen in the training set. The benchmark comes with several baselines, including RoBERTa, LayoutLMv3 and DETR-based Table Transformer. These baseline models were applied to both tasks of the DocILE benchmark, with results shared in this paper, offering a quick starting point for future work. The dataset and baselines are available at https://github.com/rossumai/docile.
A Lightweight Recurrent Grouping Attention Network for Video Super-Resolution
Sep 25, 2023Effective aggregation of temporal information of consecutive frames is the core of achieving video super-resolution. Many scholars have utilized structures such as sliding windows and recurrent to gather spatio-temporal information of frames. However, although the performance of the constructed VSR models is improving, the size of the models is also increasing, exacerbating the demand on the equipment. Thus, to reduce the stress on the device, we propose a novel lightweight recurrent grouping attention network. The parameters of this model are only 0.878M, which is much lower than the current mainstream model for studying video super-resolution. We design forward feature extraction module and backward feature extraction module to collect temporal information between consecutive frames from two directions. Moreover, a new grouping mechanism is proposed to efficiently collect spatio-temporal information of the reference frame and its neighboring frames. The attention supplementation module is presented to further enhance the information gathering range of the model. The feature reconstruction module aims to aggregate information from different directions to reconstruct high-resolution features. Experiments demonstrate that our model achieves state-of-the-art performance on multiple datasets.