 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Teamwork Is Not Always Good: An Empirical Study of Classifier Drift in Class-incremental Information Extraction
May 26, 2023
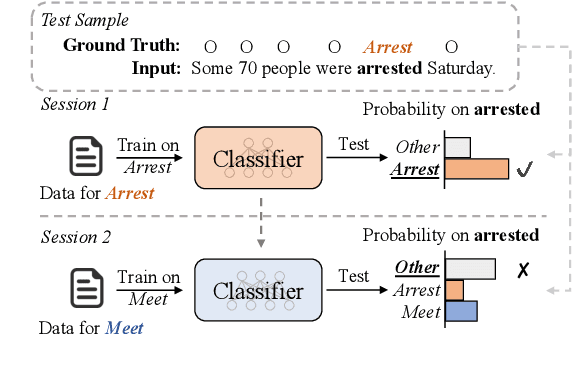
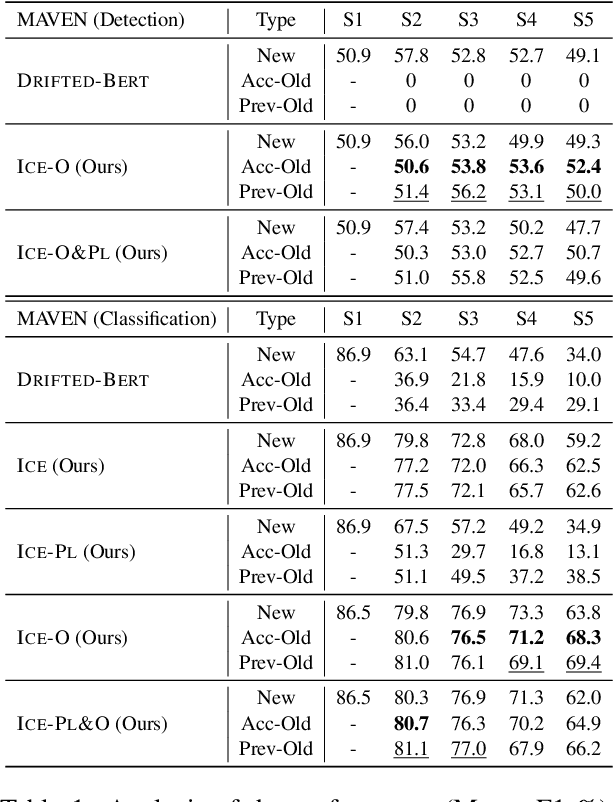
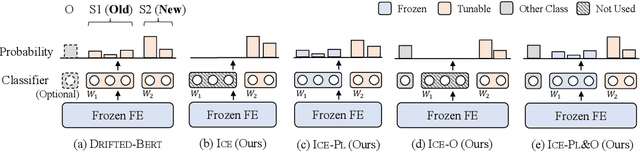
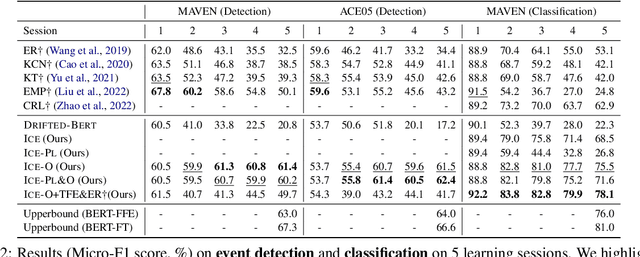
Class-incremental learning (CIL) aims to develop a learning system that can continually learn new classes from a data stream without forgetting previously learned classes. When learning classes incrementally, the classifier must be constantly updated to incorporate new classes, and the drift in decision boundary may lead to severe forgetting. This fundamental challenge, however, has not yet been studied extensively, especially in the setting where no samples from old classes are stored for rehearsal. In this paper, we take a closer look at how the drift in the classifier leads to forgetting, and accordingly, design four simple yet (super-) effective solutions to alleviate the classifier drift: an Individual Classifiers with Frozen Feature Extractor (ICE) framework where we individually train a classifier for each learning session, and its three variants ICE-PL, ICE-O, and ICE-PL&O which further take the logits of previously learned classes from old sessions or a constant logit of an Other class as a constraint to the learning of new classifiers. Extensive experiments and analysis on 6 class-incremental information extraction tasks demonstrate that our solutions, especially ICE-O, consistently show significant improvement over the previous state-of-the-art approaches with up to 44.7% absolute F-score gain, providing a strong baseline and insights for future research on class-incremental learning.
Evaluating ChatGPT's Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness
Apr 23, 2023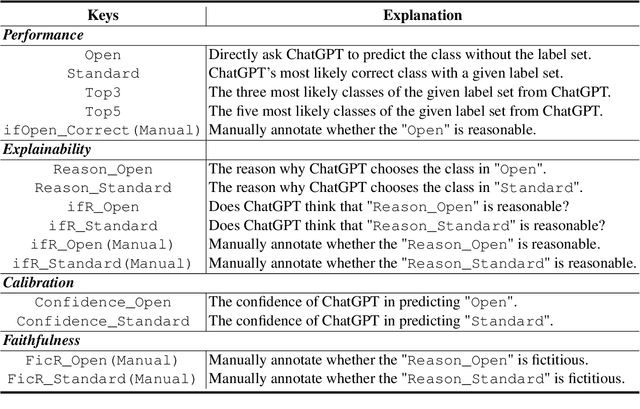
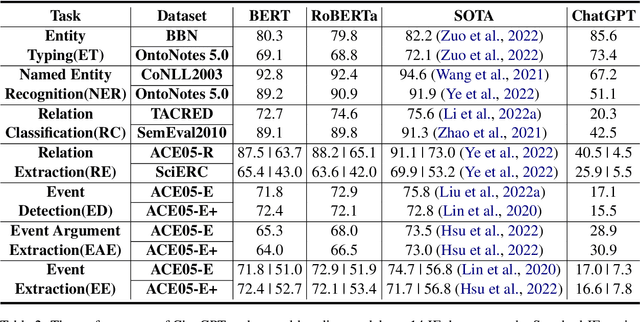
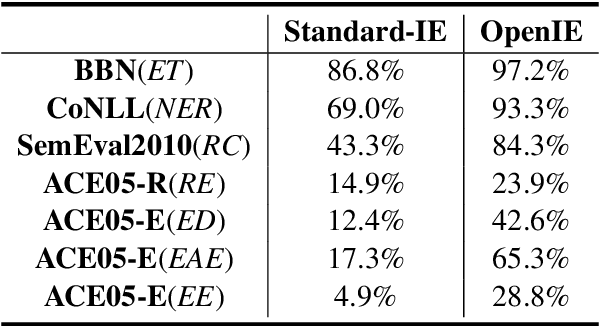
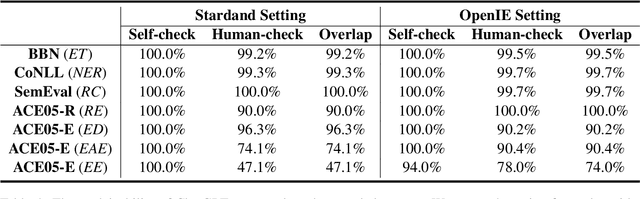
The capability of Large Language Models (LLMs) like ChatGPT to comprehend user intent and provide reasonable responses has made them extremely popular lately. In this paper, we focus on assessing the overall ability of ChatGPT using 7 fine-grained information extraction (IE) tasks. Specially, we present the systematically analysis by measuring ChatGPT's performance, explainability, calibration, and faithfulness, and resulting in 15 keys from either the ChatGPT or domain experts. Our findings reveal that ChatGPT's performance in Standard-IE setting is poor, but it surprisingly exhibits excellent performance in the OpenIE setting, as evidenced by human evaluation. In addition, our research indicates that ChatGPT provides high-quality and trustworthy explanations for its decisions. However, there is an issue of ChatGPT being overconfident in its predictions, which resulting in low calibration. Furthermore, ChatGPT demonstrates a high level of faithfulness to the original text in the majority of cases. We manually annotate and release the test sets of 7 fine-grained IE tasks contains 14 datasets to further promote the research. The datasets and code are available at https://github.com/pkuserc/ChatGPT_for_IE.
Taking a PEEK into YOLOv5 for Satellite Component Recognition via Entropy-based Visual Explanations
Nov 03, 2023The escalating risk of collisions and the accumulation of space debris in Low Earth Orbit (LEO) has reached critical concern due to the ever increasing number of spacecraft. Addressing this crisis, especially in dealing with non-cooperative and unidentified space debris, is of paramount importance. This paper contributes to efforts in enabling autonomous swarms of small chaser satellites for target geometry determination and safe flight trajectory planning for proximity operations in LEO. Our research explores on-orbit use of the You Only Look Once v5 (YOLOv5) object detection model trained to detect satellite components. While this model has shown promise, its inherent lack of interpretability hinders human understanding, a critical aspect of validating algorithms for use in safety-critical missions. To analyze the decision processes, we introduce Probabilistic Explanations for Entropic Knowledge extraction (PEEK), a method that utilizes information theoretic analysis of the latent representations within the hidden layers of the model. Through both synthetic in hardware-in-the-loop experiments, PEEK illuminates the decision-making processes of the model, helping identify its strengths, limitations and biases.
StructChart: Perception, Structuring, Reasoning for Visual Chart Understanding
Sep 20, 2023
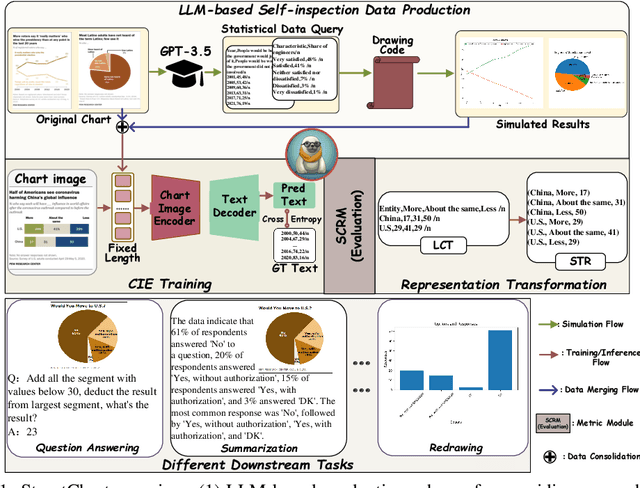
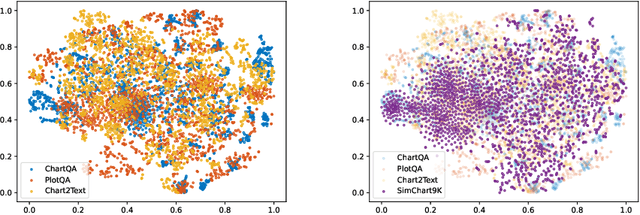
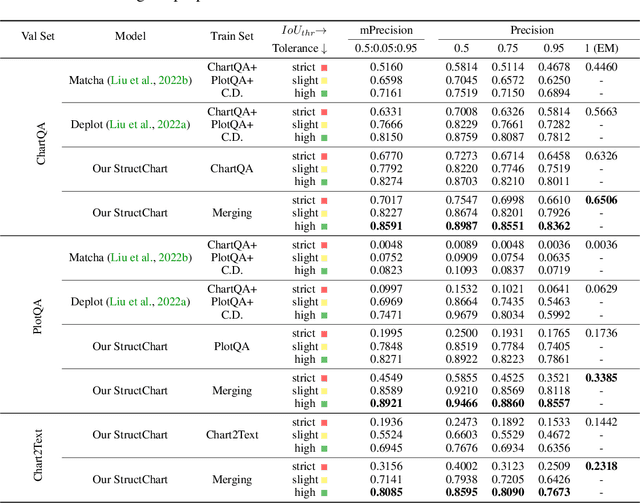
Charts are common in literature across different scientific fields, conveying rich information easily accessible to readers. Current chart-related tasks focus on either chart perception which refers to extracting information from the visual charts, or performing reasoning given the extracted data, e.g. in a tabular form. In this paper, we aim to establish a unified and label-efficient learning paradigm for joint perception and reasoning tasks, which can be generally applicable to different downstream tasks, beyond the question-answering task as specifically studied in peer works. Specifically, StructChart first reformulates the chart information from the popular tubular form (specifically linearized CSV) to the proposed Structured Triplet Representations (STR), which is more friendly for reducing the task gap between chart perception and reasoning due to the employed structured information extraction for charts. We then propose a Structuring Chart-oriented Representation Metric (SCRM) to quantitatively evaluate the performance for the chart perception task. To enrich the dataset for training, we further explore the possibility of leveraging the Large Language Model (LLM), enhancing the chart diversity in terms of both chart visual style and its statistical information. Extensive experiments are conducted on various chart-related tasks, demonstrating the effectiveness and promising potential for a unified chart perception-reasoning paradigm to push the frontier of chart understanding.
Applications of Sequential Learning for Medical Image Classification
Sep 26, 2023Purpose: The aim of this work is to develop a neural network training framework for continual training of small amounts of medical imaging data and create heuristics to assess training in the absence of a hold-out validation or test set. Materials and Methods: We formulated a retrospective sequential learning approach that would train and consistently update a model on mini-batches of medical images over time. We address problems that impede sequential learning such as overfitting, catastrophic forgetting, and concept drift through PyTorch convolutional neural networks (CNN) and publicly available Medical MNIST and NIH Chest X-Ray imaging datasets. We begin by comparing two methods for a sequentially trained CNN with and without base pre-training. We then transition to two methods of unique training and validation data recruitment to estimate full information extraction without overfitting. Lastly, we consider an example of real-life data that shows how our approach would see mainstream research implementation. Results: For the first experiment, both approaches successfully reach a ~95% accuracy threshold, although the short pre-training step enables sequential accuracy to plateau in fewer steps. The second experiment comparing two methods showed better performance with the second method which crosses the ~90% accuracy threshold much sooner. The final experiment showed a slight advantage with a pre-training step that allows the CNN to cross ~60% threshold much sooner than without pre-training. Conclusion: We have displayed sequential learning as a serviceable multi-classification technique statistically comparable to traditional CNNs that can acquire data in small increments feasible for clinically realistic scenarios.
Informed Named Entity Recognition Decoding for Generative Language Models
Aug 15, 2023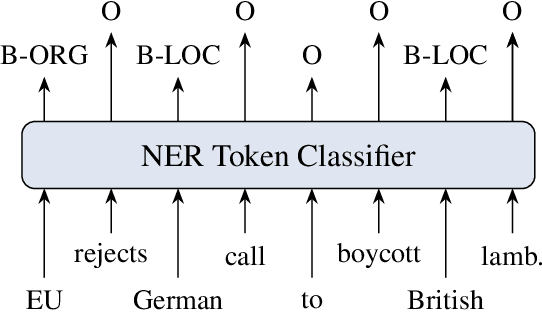

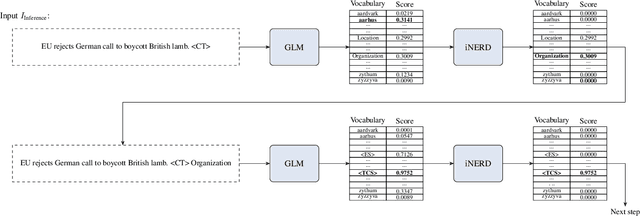
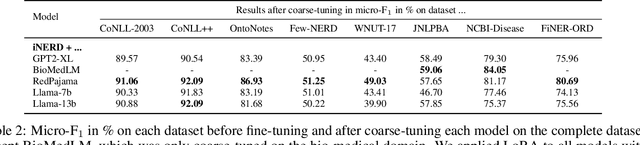
Ever-larger language models with ever-increasing capabilities are by now well-established text processing tools. Alas, information extraction tasks such as named entity recognition are still largely unaffected by this progress as they are primarily based on the previous generation of encoder-only transformer models. Here, we propose a simple yet effective approach, Informed Named Entity Recognition Decoding (iNERD), which treats named entity recognition as a generative process. It leverages the language understanding capabilities of recent generative models in a future-proof manner and employs an informed decoding scheme incorporating the restricted nature of information extraction into open-ended text generation, improving performance and eliminating any risk of hallucinations. We coarse-tune our model on a merged named entity corpus to strengthen its performance, evaluate five generative language models on eight named entity recognition datasets, and achieve remarkable results, especially in an environment with an unknown entity class set, demonstrating the adaptability of the approach.
A Knowledge-enhanced Two-stage Generative Framework for Medical Dialogue Information Extraction
Jul 30, 2023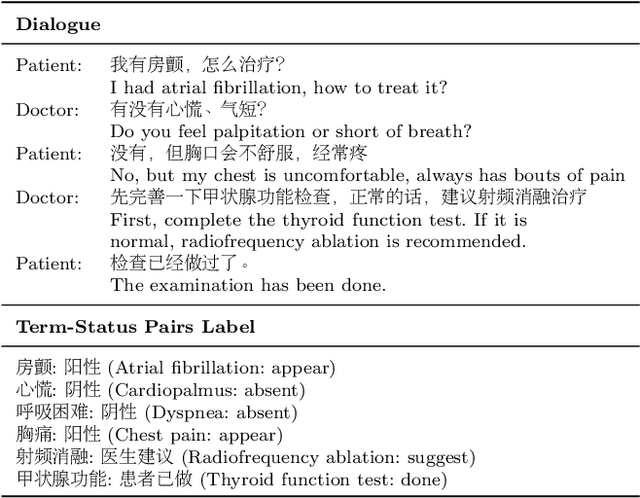
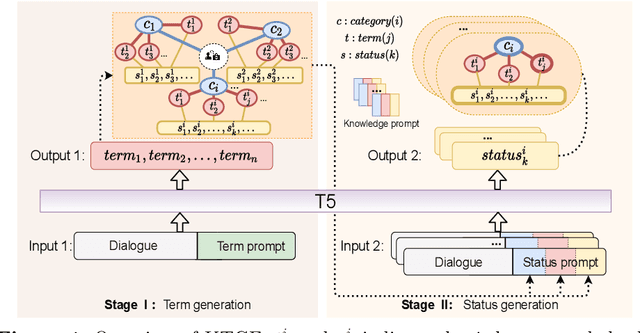
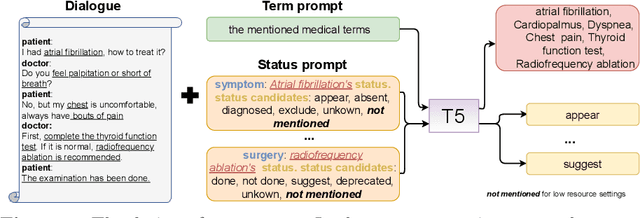
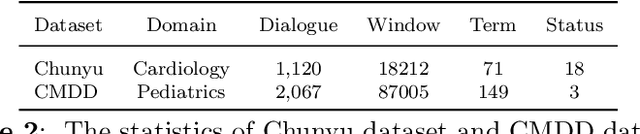
This paper focuses on term-status pair extraction from medical dialogues (MD-TSPE), which is essential in diagnosis dialogue systems and the automatic scribe of electronic medical records (EMRs). In the past few years, works on MD-TSPE have attracted increasing research attention, especially after the remarkable progress made by generative methods. However, these generative methods output a whole sequence consisting of term-status pairs in one stage and ignore integrating prior knowledge, which demands a deeper understanding to model the relationship between terms and infer the status of each term. This paper presents a knowledge-enhanced two-stage generative framework (KTGF) to address the above challenges. Using task-specific prompts, we employ a single model to complete the MD-TSPE through two phases in a unified generative form: we generate all terms the first and then generate the status of each generated term. In this way, the relationship between terms can be learned more effectively from the sequence containing only terms in the first phase, and our designed knowledge-enhanced prompt in the second phase can leverage the category and status candidates of the generated term for status generation. Furthermore, our proposed special status ``not mentioned" makes more terms available and enriches the training data in the second phase, which is critical in the low-resource setting. The experiments on the Chunyu and CMDD datasets show that the proposed method achieves superior results compared to the state-of-the-art models in the full training and low-resource settings.
OceanBench: The Sea Surface Height Edition
Sep 27, 2023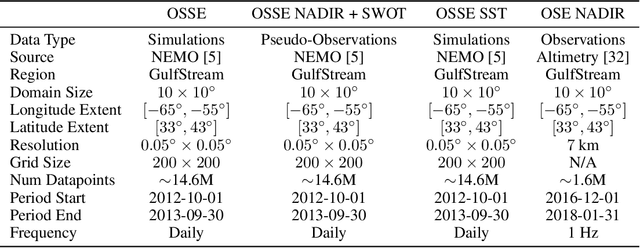
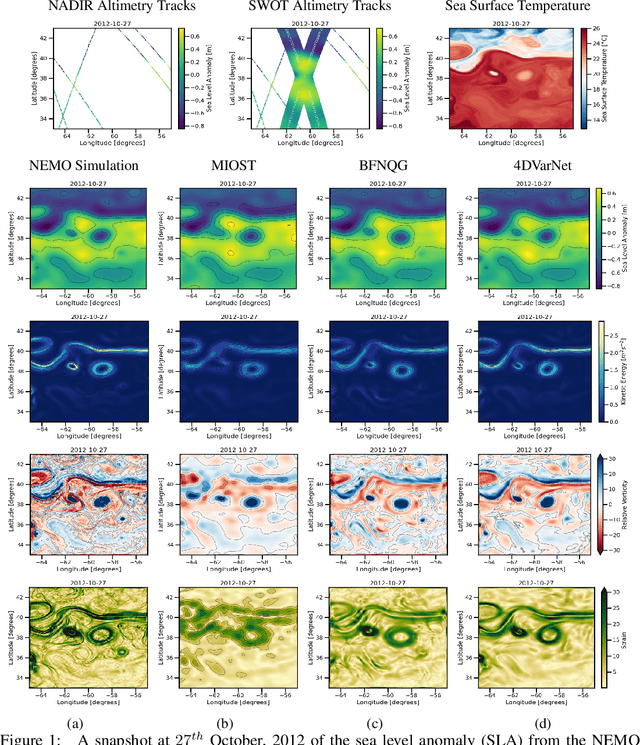
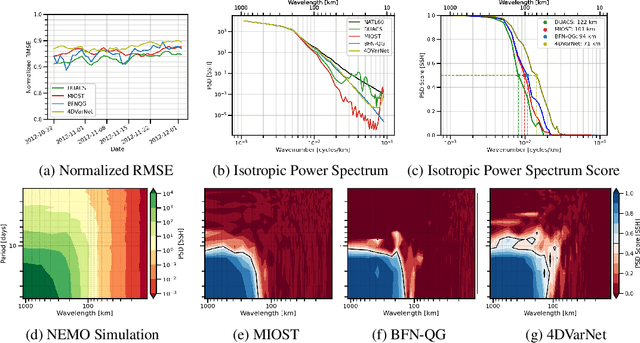

The ocean profoundly influences human activities and plays a critical role in climate regulation. Our understanding has improved over the last decades with the advent of satellite remote sensing data, allowing us to capture essential quantities over the globe, e.g., sea surface height (SSH). However, ocean satellite data presents challenges for information extraction due to their sparsity and irregular sampling, signal complexity, and noise. Machine learning (ML) techniques have demonstrated their capabilities in dealing with large-scale, complex signals. Therefore we see an opportunity for ML models to harness the information contained in ocean satellite data. However, data representation and relevant evaluation metrics can be the defining factors when determining the success of applied ML. The processing steps from the raw observation data to a ML-ready state and from model outputs to interpretable quantities require domain expertise, which can be a significant barrier to entry for ML researchers. OceanBench is a unifying framework that provides standardized processing steps that comply with domain-expert standards. It provides plug-and-play data and pre-configured pipelines for ML researchers to benchmark their models and a transparent configurable framework for researchers to customize and extend the pipeline for their tasks. In this work, we demonstrate the OceanBench framework through a first edition dedicated to SSH interpolation challenges. We provide datasets and ML-ready benchmarking pipelines for the long-standing problem of interpolating observations from simulated ocean satellite data, multi-modal and multi-sensor fusion issues, and transfer-learning to real ocean satellite observations. The OceanBench framework is available at github.com/jejjohnson/oceanbench and the dataset registry is available at github.com/quentinf00/oceanbench-data-registry.
Black-Box Analysis: GPTs Across Time in Legal Textual Entailment Task
Sep 11, 2023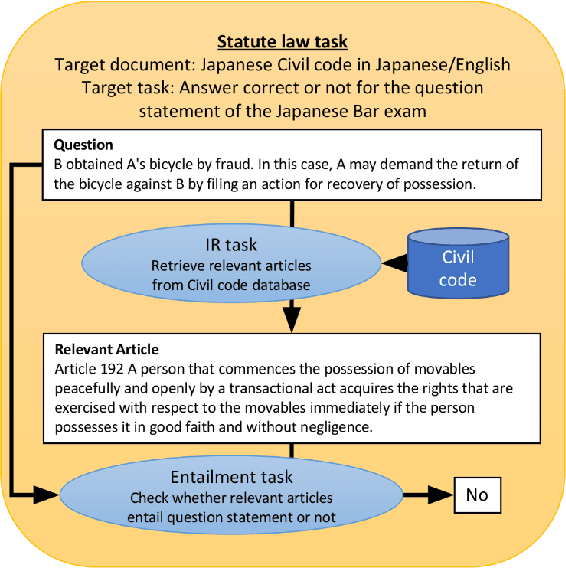
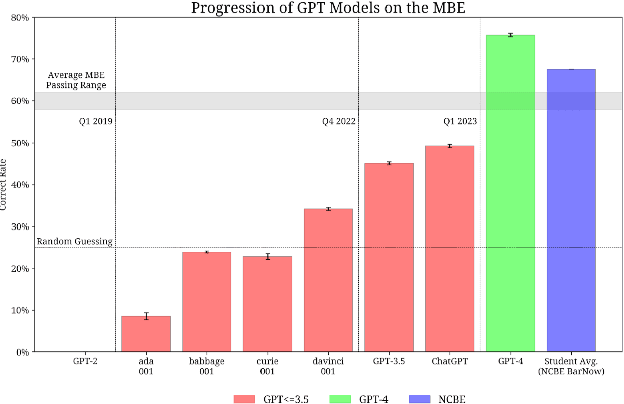
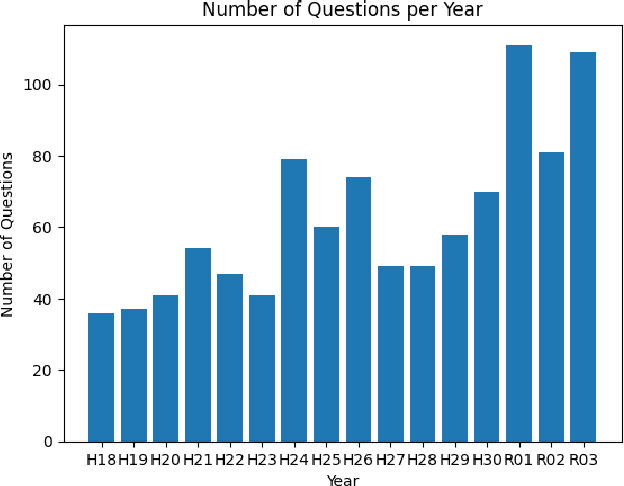
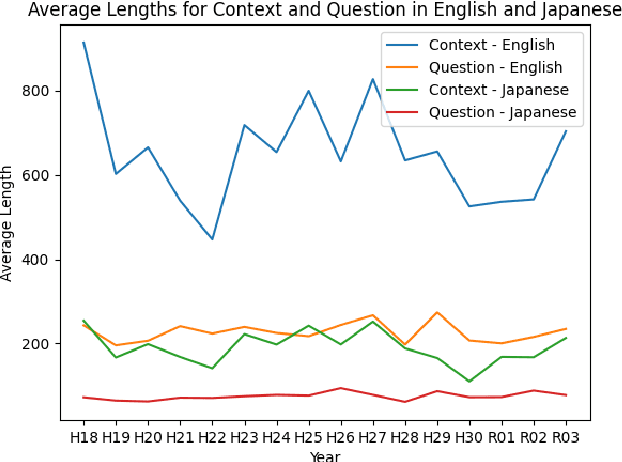
The evolution of Generative Pre-trained Transformer (GPT) models has led to significant advancements in various natural language processing applications, particularly in legal textual entailment. We present an analysis of GPT-3.5 (ChatGPT) and GPT-4 performances on COLIEE Task 4 dataset, a prominent benchmark in this domain. The study encompasses data from Heisei 18 (2006) to Reiwa 3 (2021), exploring the models' abilities to discern entailment relationships within Japanese statute law across different periods. Our preliminary experimental results unveil intriguing insights into the models' strengths and weaknesses in handling legal textual entailment tasks, as well as the patterns observed in model performance. In the context of proprietary models with undisclosed architectures and weights, black-box analysis becomes crucial for evaluating their capabilities. We discuss the influence of training data distribution and the implications on the models' generalizability. This analysis serves as a foundation for future research, aiming to optimize GPT-based models and enable their successful adoption in legal information extraction and entailment applications.
Copyright Violations and Large Language Models
Oct 20, 2023Language models may memorize more than just facts, including entire chunks of texts seen during training. Fair use exemptions to copyright laws typically allow for limited use of copyrighted material without permission from the copyright holder, but typically for extraction of information from copyrighted materials, rather than {\em verbatim} reproduction. This work explores the issue of copyright violations and large language models through the lens of verbatim memorization, focusing on possible redistribution of copyrighted text. We present experiments with a range of language models over a collection of popular books and coding problems, providing a conservative characterization of the extent to which language models can redistribute these materials. Overall, this research highlights the need for further examination and the potential impact on future developments in natural language processing to ensure adherence to copyright regulations. Code is at \url{https://github.com/coastalcph/CopyrightLLMs}.