 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Open Information Extraction via Chunks
May 05, 2023

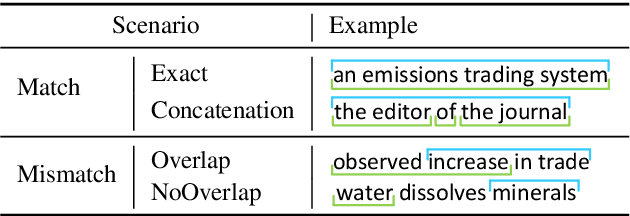
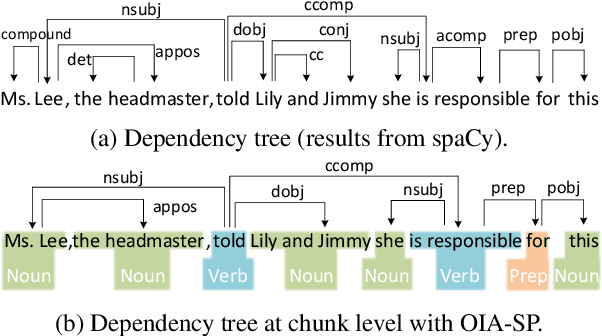
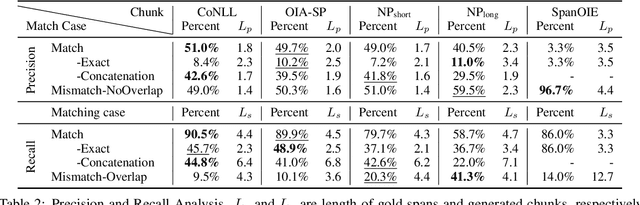
Open Information Extraction (OIE) aims to extract relational tuples from open-domain sentences. Existing OIE systems split a sentence into tokens and recognize token spans as tuple relations and arguments. We instead propose Sentence as Chunk sequence (SaC) and recognize chunk spans as tuple relations and arguments. We argue that SaC has better quantitative and qualitative properties for OIE than sentence as token sequence, and evaluate four choices of chunks (i.e., CoNLL chunks, simple phrases, NP chunks, and spans from SpanOIE) against gold OIE tuples. Accordingly, we propose a simple BERT-based model for sentence chunking, and propose Chunk-OIE for tuple extraction on top of SaC. Chunk-OIE achieves state-of-the-art results on multiple OIE datasets, showing that SaC benefits OIE task.
Adaptive Ordered Information Extraction with Deep Reinforcement Learning
Jun 19, 2023
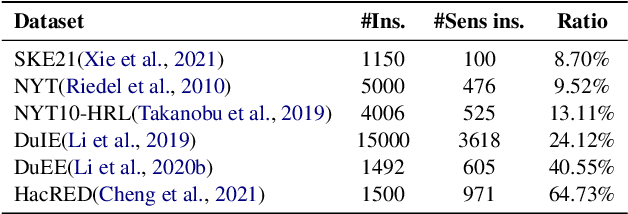
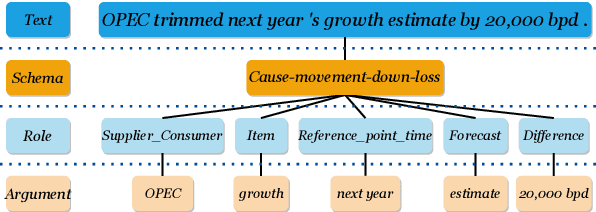
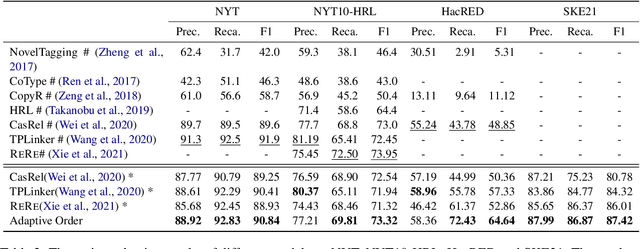
Information extraction (IE) has been studied extensively. The existing methods always follow a fixed extraction order for complex IE tasks with multiple elements to be extracted in one instance such as event extraction. However, we conduct experiments on several complex IE datasets and observe that different extraction orders can significantly affect the extraction results for a great portion of instances, and the ratio of sentences that are sensitive to extraction orders increases dramatically with the complexity of the IE task. Therefore, this paper proposes a novel adaptive ordered IE paradigm to find the optimal element extraction order for different instances, so as to achieve the best extraction results. We also propose an reinforcement learning (RL) based framework to generate optimal extraction order for each instance dynamically. Additionally, we propose a co-training framework adapted to RL to mitigate the exposure bias during the extractor training phase. Extensive experiments conducted on several public datasets demonstrate that our proposed method can beat previous methods and effectively improve the performance of various IE tasks, especially for complex ones.
LOKE: Linked Open Knowledge Extraction for Automated Knowledge Graph Construction
Nov 15, 2023While the potential of Open Information Extraction (Open IE) for Knowledge Graph Construction (KGC) may seem promising, we find that the alignment of Open IE extraction results with existing knowledge graphs to be inadequate. The advent of Large Language Models (LLMs), especially the commercially available OpenAI models, have reset expectations for what is possible with deep learning models and have created a new field called prompt engineering. We investigate the use of GPT models and prompt engineering for knowledge graph construction with the Wikidata knowledge graph to address a similar problem to Open IE, which we call Open Knowledge Extraction (OKE) using an approach we call the Linked Open Knowledge Extractor (LOKE, pronounced like "Loki"). We consider the entity linking task essential to construction of real world knowledge graphs. We merge the CaRB benchmark scoring approach with data from the TekGen dataset for the LOKE task. We then show that a well engineered prompt, paired with a naive entity linking approach (which we call LOKE-GPT), outperforms AllenAI's OpenIE 4 implementation on the OKE task, although it over-generates triples compared to the reference set due to overall triple scarcity in the TekGen set. Through an analysis of entity linkability in the CaRB dataset, as well as outputs from OpenIE 4 and LOKE-GPT, we see that LOKE-GPT and the "silver" TekGen triples show that the task is significantly different in content from OIE, if not structure. Through this analysis and a qualitative analysis of sentence extractions via all methods, we found that LOKE-GPT extractions are of high utility for the KGC task and suitable for use in semi-automated extraction settings.
Preserving Knowledge Invariance: Rethinking Robustness Evaluation of Open Information Extraction
May 23, 2023
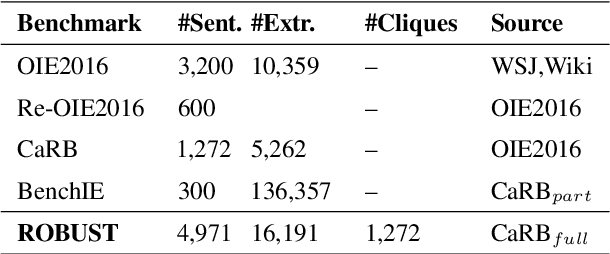
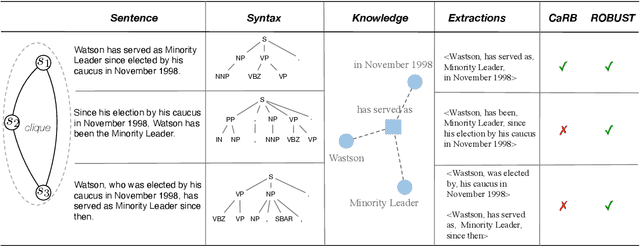
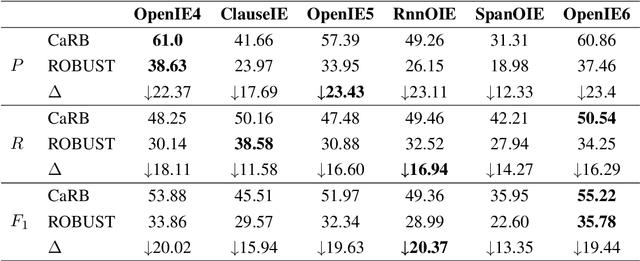
The robustness to distribution changes ensures that NLP models can be successfully applied in the realistic world, especially for information extraction tasks. However, most prior evaluation benchmarks have been devoted to validating pairwise matching correctness, ignoring the crucial measurement of robustness. In this paper, we present the first benchmark that simulates the evaluation of open information extraction models in the real world, where the syntactic and expressive distributions under the same knowledge meaning may drift variously. We design and annotate a large-scale testbed in which each example is a knowledge-invariant clique that consists of sentences with structured knowledge of the same meaning but with different syntactic and expressive forms. By further elaborating the robustness metric, a model is judged to be robust if its performance is consistently accurate on the overall cliques. We perform experiments on typical models published in the last decade as well as a popular large language model, the results show that the existing successful models exhibit a frustrating degradation, with a maximum drop of 23.43 F1 score. Our resources and code will be publicly available.
Visual Information Extraction in the Wild: Practical Dataset and End-to-end Solution
May 12, 2023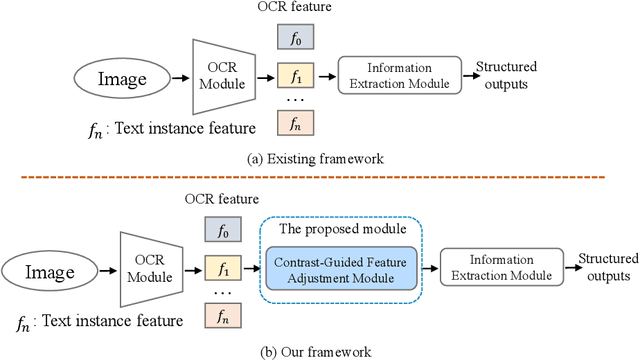

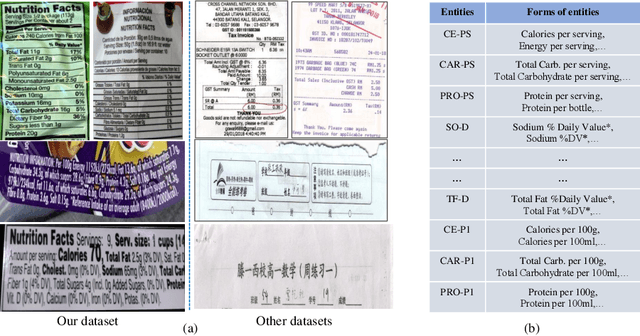
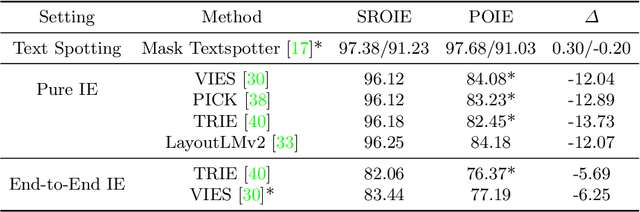
Visual information extraction (VIE), which aims to simultaneously perform OCR and information extraction in a unified framework, has drawn increasing attention due to its essential role in various applications like understanding receipts, goods, and traffic signs. However, as existing benchmark datasets for VIE mainly consist of document images without the adequate diversity of layout structures, background disturbs, and entity categories, they cannot fully reveal the challenges of real-world applications. In this paper, we propose a large-scale dataset consisting of camera images for VIE, which contains not only the larger variance of layout, backgrounds, and fonts but also much more types of entities. Besides, we propose a novel framework for end-to-end VIE that combines the stages of OCR and information extraction in an end-to-end learning fashion. Different from the previous end-to-end approaches that directly adopt OCR features as the input of an information extraction module, we propose to use contrastive learning to narrow the semantic gap caused by the difference between the tasks of OCR and information extraction. We evaluate the existing end-to-end methods for VIE on the proposed dataset and observe that the performance of these methods has a distinguishable drop from SROIE (a widely used English dataset) to our proposed dataset due to the larger variance of layout and entities. These results demonstrate our dataset is more practical for promoting advanced VIE algorithms. In addition, experiments demonstrate that the proposed VIE method consistently achieves the obvious performance gains on the proposed and SROIE datasets.
Contrastive Deep Nonnegative Matrix Factorization for Community Detection
Nov 04, 2023Recently, nonnegative matrix factorization (NMF) has been widely adopted for community detection, because of its better interpretability. However, the existing NMF-based methods have the following three problems: 1) they directly transform the original network into community membership space, so it is difficult for them to capture the hierarchical information; 2) they often only pay attention to the topology of the network and ignore its node attributes; 3) it is hard for them to learn the global structure information necessary for community detection. Therefore, we propose a new community detection algorithm, named Contrastive Deep Nonnegative Matrix Factorization (CDNMF). Firstly, we deepen NMF to strengthen its capacity for information extraction. Subsequently, inspired by contrastive learning, our algorithm creatively constructs network topology and node attributes as two contrasting views. Furthermore, we utilize a debiased negative sampling layer and learn node similarity at the community level, thereby enhancing the suitability of our model for community detection. We conduct experiments on three public real graph datasets and the proposed model has achieved better results than state-of-the-art methods. Code available at https://github.com/6lyc/CDNMF.git.
A Car Model Identification System for Streamlining the Automobile Sales Process
Oct 23, 2023
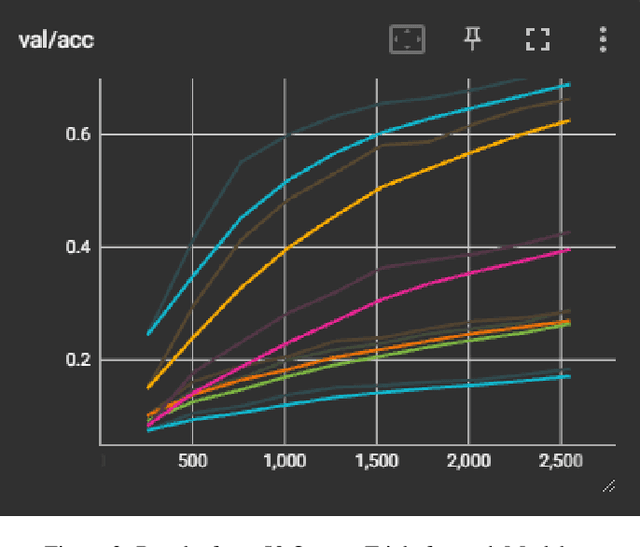
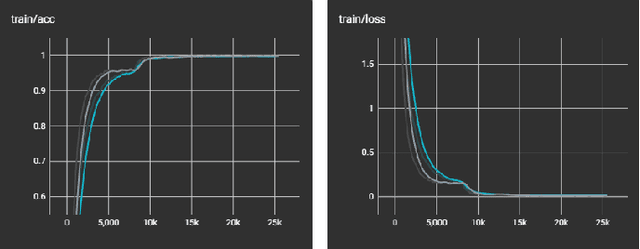
This project presents an automated solution for the efficient identification of car models and makes from images, aimed at streamlining the vehicle listing process on online car-selling platforms. Through a thorough exploration encompassing various efficient network architectures including Convolutional Neural Networks (CNNs), Vision Transformers (ViTs), and hybrid models, we achieved a notable accuracy of 81.97% employing the EfficientNet (V2 b2) architecture. To refine performance, a combination of strategies, including data augmentation, fine-tuning pretrained models, and extensive hyperparameter tuning, were applied. The trained model offers the potential for automating information extraction, promising enhanced user experiences across car-selling websites.
Fusing Temporal Graphs into Transformers for Time-Sensitive Question Answering
Oct 30, 2023Answering time-sensitive questions from long documents requires temporal reasoning over the times in questions and documents. An important open question is whether large language models can perform such reasoning solely using a provided text document, or whether they can benefit from additional temporal information extracted using other systems. We address this research question by applying existing temporal information extraction systems to construct temporal graphs of events, times, and temporal relations in questions and documents. We then investigate different approaches for fusing these graphs into Transformer models. Experimental results show that our proposed approach for fusing temporal graphs into input text substantially enhances the temporal reasoning capabilities of Transformer models with or without fine-tuning. Additionally, our proposed method outperforms various graph convolution-based approaches and establishes a new state-of-the-art performance on SituatedQA and three splits of TimeQA.
SIMARA: a database for key-value information extraction from full pages
Apr 26, 2023
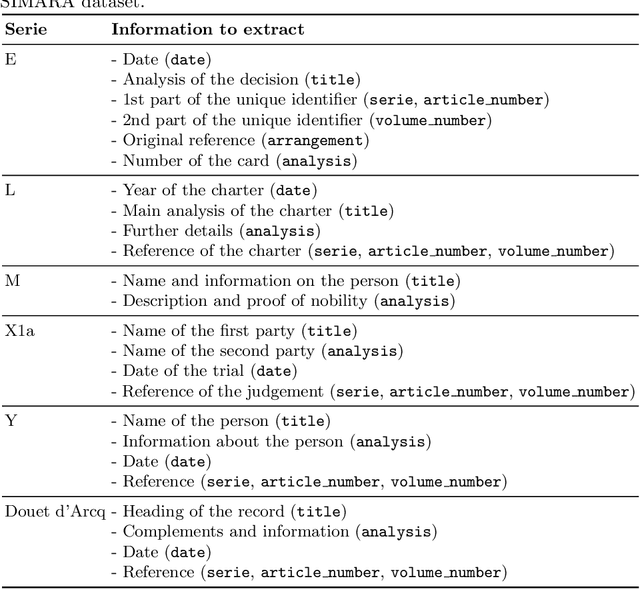

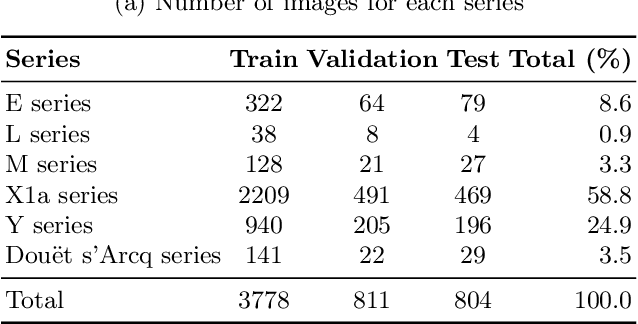
We propose a new database for information extraction from historical handwritten documents. The corpus includes 5,393 finding aids from six different series, dating from the 18th-20th centuries. Finding aids are handwritten documents that contain metadata describing older archives. They are stored in the National Archives of France and are used by archivists to identify and find archival documents. Each document is annotated at page-level, and contains seven fields to retrieve. The localization of each field is not available in such a way that this dataset encourages research on segmentation-free systems for information extraction. We propose a model based on the Transformer architecture trained for end-to-end information extraction and provide three sets for training, validation and testing, to ensure fair comparison with future works. The database is freely accessible at https://zenodo.org/record/7868059.
ChiMed-GPT: A Chinese Medical Large Language Model with Full Training Regime and Better Alignment to Human Preferences
Nov 10, 2023
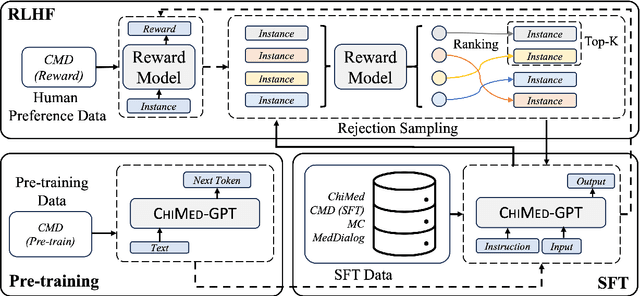

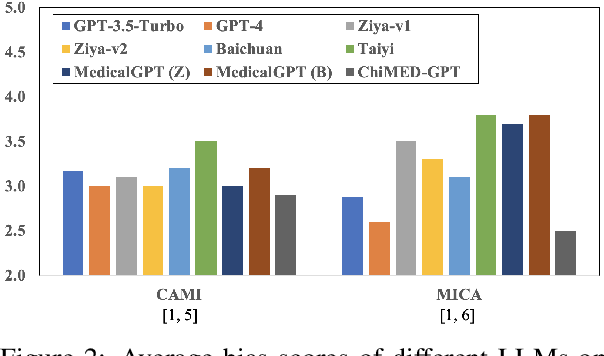
Recently, the increasing demand for superior medical services has highlighted the discrepancies in the medical infrastructure. With big data, especially texts, forming the foundation of medical services, there is an exigent need for effective natural language processing (NLP) solutions tailored to the healthcare domain. Conventional approaches leveraging pre-trained models present promising results in this domain and current large language models (LLMs) offer advanced foundation for medical text processing. However, most medical LLMs are trained only with supervised fine-tuning (SFT), even though it efficiently empowers LLMs to understand and respond to medical instructions but is ineffective in learning domain knowledge and aligning with human preference. Another engineering barrier that prevents current medical LLM from better text processing ability is their restricted context length (e.g., 2,048 tokens), making it hard for the LLMs to process long context, which is frequently required in the medical domain. In this work, we propose ChiMed-GPT, a new benchmark LLM designed explicitly for Chinese medical domain, with enlarged context length to 4,096 tokens and undergoes a comprehensive training regime with pre-training, SFT, and RLHF. Evaluations on real-world tasks including information extraction, question answering, and dialogue generation demonstrate ChiMed-GPT's superior performance over general domain LLMs. Furthermore, we analyze possible biases through prompting ChiMed-GPT to perform attitude scales regarding discrimination of patients, so as to contribute to further responsible development of LLMs in the medical domain. The code and model are released at https://github.com/synlp/ChiMed-GPT.