 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
DocTr: Document Transformer for Structured Information Extraction in Documents
Jul 16, 2023

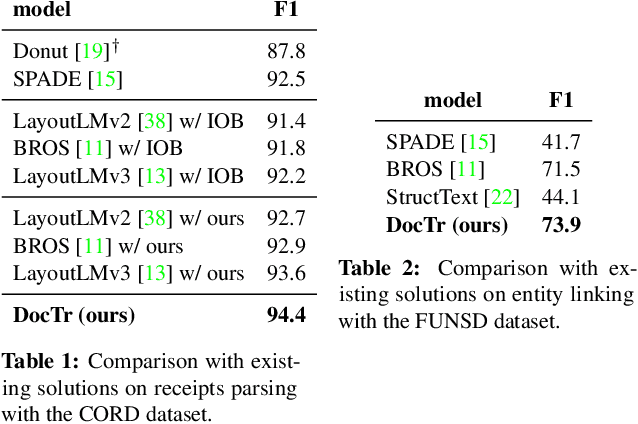
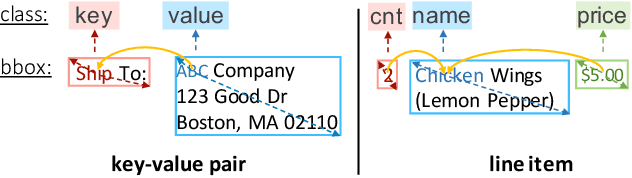
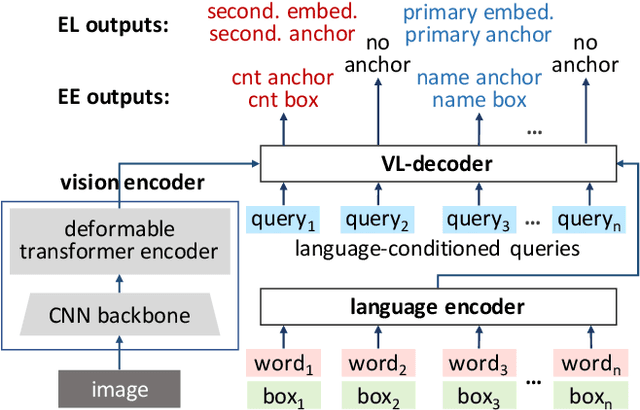
We present a new formulation for structured information extraction (SIE) from visually rich documents. It aims to address the limitations of existing IOB tagging or graph-based formulations, which are either overly reliant on the correct ordering of input text or struggle with decoding a complex graph. Instead, motivated by anchor-based object detectors in vision, we represent an entity as an anchor word and a bounding box, and represent entity linking as the association between anchor words. This is more robust to text ordering, and maintains a compact graph for entity linking. The formulation motivates us to introduce 1) a DOCument TRansformer (DocTr) that aims at detecting and associating entity bounding boxes in visually rich documents, and 2) a simple pre-training strategy that helps learn entity detection in the context of language. Evaluations on three SIE benchmarks show the effectiveness of the proposed formulation, and the overall approach outperforms existing solutions.
Uncertainty Estimation on Sequential Labeling via Uncertainty Transmission
Nov 15, 2023Sequential labeling is a task predicting labels for each token in a sequence, such as Named Entity Recognition (NER). NER tasks aim to extract entities and predict their labels given a text, which is important in information extraction. Although previous works have shown great progress in improving NER performance, uncertainty estimation on NER (UE-NER) is still underexplored but essential. This work focuses on UE-NER, which aims to estimate uncertainty scores for the NER predictions. Previous uncertainty estimation models often overlook two unique characteristics of NER: the connection between entities (i.e., one entity embedding is learned based on the other ones) and wrong span cases in the entity extraction subtask. Therefore, we propose a Sequential Labeling Posterior Network (SLPN) to estimate uncertainty scores for the extracted entities, considering uncertainty transmitted from other tokens. Moreover, we have defined an evaluation strategy to address the specificity of wrong-span cases. Our SLPN has achieved significant improvements on two datasets, such as a 5.54-point improvement in AUPR on the MIT-Restaurant dataset.
CARE: Extracting Experimental Findings From Clinical Literature
Nov 16, 2023Extracting fine-grained experimental findings from literature can provide massive utility for scientific applications. Prior work has focused on developing annotation schemas and datasets for limited aspects of this problem, leading to simpler information extraction datasets which do not capture the real-world complexity and nuance required for this task. Focusing on biomedicine, this work presents CARE (Clinical Aggregation-oriented Result Extraction) -- a new IE dataset for the task of extracting clinical findings. We develop a new annotation schema capturing fine-grained findings as n-ary relations between entities and attributes, which includes phenomena challenging for current IE systems such as discontinuous entity spans, nested relations, and variable arity n-ary relations. Using this schema, we collect extensive annotations for 700 abstracts from two sources: clinical trials and case reports. We also benchmark the performance of various state-of-the-art IE systems on our dataset, including extractive models and generative LLMs in fully supervised and limited data settings. Our results demonstrate the difficulty of our dataset -- even SOTA models such as GPT4 struggle, particularly on relation extraction. We release our annotation schema and CARE to encourage further research on extracting and aggregating scientific findings from literature.
Chain of Thought with Explicit Evidence Reasoning for Few-shot Relation Extraction
Nov 15, 2023Few-shot relation extraction involves identifying the type of relationship between two specific entities within a text, using a limited number of annotated samples. A variety of solutions to this problem have emerged by applying meta-learning and neural graph techniques which typically necessitate a training process for adaptation. Recently, the strategy of in-context learning has been demonstrating notable results without the need of training. Few studies have already utilized in-context learning for zero-shot information extraction. Unfortunately, the evidence for inference is either not considered or implicitly modeled during the construction of chain-of-thought prompts. In this paper, we propose a novel approach for few-shot relation extraction using large language models, named CoT-ER, chain-of-thought with explicit evidence reasoning. In particular, CoT-ER first induces large language models to generate evidences using task-specific and concept-level knowledge. Then these evidences are explicitly incorporated into chain-of-thought prompting for relation extraction. Experimental results demonstrate that our CoT-ER approach (with 0% training data) achieves competitive performance compared to the fully-supervised (with 100% training data) state-of-the-art approach on the FewRel1.0 and FewRel2.0 datasets.
A Framework of Full-Process Generation Design for Park Green Spaces Based on Remote Sensing Segmentation-GAN-Diffusion
Dec 17, 2023The development of generative design driven by artificial intelligence algorithms is speedy. There are two research gaps in the current research: 1) Most studies only focus on the relationship between design elements and pay little attention to the external information of the site; 2) GAN and other traditional generative algorithms generate results with low resolution and insufficient details. To address these two problems, we integrate GAN, Stable diffusion multimodal large-scale image pre-training model to construct a full-process park generative design method: 1) First, construct a high-precision remote sensing object extraction system for automated extraction of urban environmental information; 2) Secondly, use GAN to construct a park design generation system based on the external environment, which can quickly infer and generate design schemes from urban environmental information; 3) Finally, introduce Stable Diffusion to optimize the design plan, fill in details, and expand the resolution of the plan by 64 times. This method can achieve a fully unmanned design automation workflow. The research results show that: 1) The relationship between the inside and outside of the site will affect the algorithm generation results. 2) Compared with traditional GAN algorithms, Stable diffusion significantly improve the information richness of the generated results.
Comparison of pipeline, sequence-to-sequence, and GPT models for end-to-end relation extraction: experiments with the rare disease use-case
Nov 22, 2023
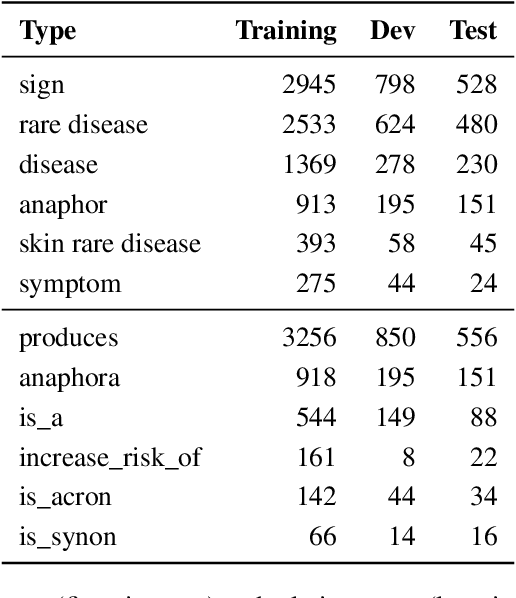


End-to-end relation extraction (E2ERE) is an important and realistic application of natural language processing (NLP) in biomedicine. In this paper, we aim to compare three prevailing paradigms for E2ERE using a complex dataset focused on rare diseases involving discontinuous and nested entities. We use the RareDis information extraction dataset to evaluate three competing approaches (for E2ERE): NER $\rightarrow$ RE pipelines, joint sequence to sequence models, and generative pre-trained transformer (GPT) models. We use comparable state-of-the-art models and best practices for each of these approaches and conduct error analyses to assess their failure modes. Our findings reveal that pipeline models are still the best, while sequence-to-sequence models are not far behind; GPT models with eight times as many parameters are worse than even sequence-to-sequence models and lose to pipeline models by over 10 F1 points. Partial matches and discontinuous entities caused many NER errors contributing to lower overall E2E performances. We also verify these findings on a second E2ERE dataset for chemical-protein interactions. Although generative LM-based methods are more suitable for zero-shot settings, when training data is available, our results show that it is better to work with more conventional models trained and tailored for E2ERE. More innovative methods are needed to marry the best of the both worlds from smaller encoder-decoder pipeline models and the larger GPT models to improve E2ERE. As of now, we see that well designed pipeline models offer substantial performance gains at a lower cost and carbon footprint for E2ERE. Our contribution is also the first to conduct E2ERE for the RareDis dataset.
GMTR: Graph Matching Transformers
Nov 14, 2023Vision transformers (ViTs) have recently been used for visual matching beyond object detection and segmentation. However, the original grid dividing strategy of ViTs neglects the spatial information of the keypoints, limiting the sensitivity to local information. Therefore, we propose \textbf{QueryTrans} (Query Transformer), which adopts a cross-attention module and keypoints-based center crop strategy for better spatial information extraction. We further integrate the graph attention module and devise a transformer-based graph matching approach \textbf{GMTR} (Graph Matching TRansformers) whereby the combinatorial nature of GM is addressed by a graph transformer neural GM solver. On standard GM benchmarks, GMTR shows competitive performance against the SOTA frameworks. Specifically, on Pascal VOC, GMTR achieves $\mathbf{83.6\%}$ accuracy, $\mathbf{0.9\%}$ higher than the SOTA framework. On Spair-71k, GMTR shows great potential and outperforms most of the previous works. Meanwhile, on Pascal VOC, QueryTrans improves the accuracy of NGMv2 from $80.1\%$ to $\mathbf{83.3\%}$, and BBGM from $79.0\%$ to $\mathbf{84.5\%}$. On Spair-71k, QueryTrans improves NGMv2 from $80.6\%$ to $\mathbf{82.5\%}$, and BBGM from $82.1\%$ to $\mathbf{83.9\%}$. Source code will be made publicly available.
DONUT-hole: DONUT Sparsification by Harnessing Knowledge and Optimizing Learning Efficiency
Nov 09, 2023This paper introduces DONUT-hole, a sparse OCR-free visual document understanding (VDU) model that addresses the limitations of its predecessor model, dubbed DONUT. The DONUT model, leveraging a transformer architecture, overcoming the challenges of separate optical character recognition (OCR) and visual semantic understanding (VSU) components. However, its deployment in production environments and edge devices is hindered by high memory and computational demands, particularly in large-scale request services. To overcome these challenges, we propose an optimization strategy based on knowledge distillation and model pruning. Our paradigm to produce DONUT-hole, reduces the model denisty by 54\% while preserving performance. We also achieve a global representational similarity index between DONUT and DONUT-hole based on centered kernel alignment (CKA) metric of 0.79. Moreover, we evaluate the effectiveness of DONUT-hole in the document image key information extraction (KIE) task, highlighting its potential for developing more efficient VDU systems for logistic companies.
When does In-context Learning Fall Short and Why? A Study on Specification-Heavy Tasks
Nov 15, 2023
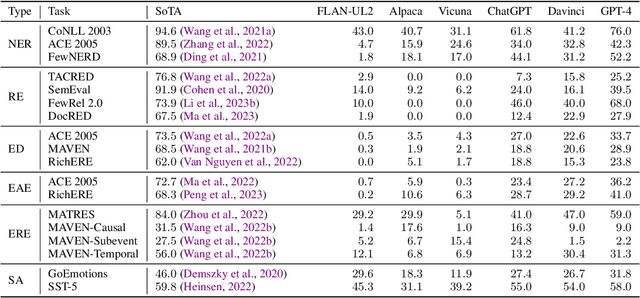


In-context learning (ICL) has become the default method for using large language models (LLMs), making the exploration of its limitations and understanding the underlying causes crucial. In this paper, we find that ICL falls short of handling specification-heavy tasks, which are tasks with complicated and extensive task specifications, requiring several hours for ordinary humans to master, such as traditional information extraction tasks. The performance of ICL on these tasks mostly cannot reach half of the state-of-the-art results. To explore the reasons behind this failure, we conduct comprehensive experiments on 18 specification-heavy tasks with various LLMs and identify three primary reasons: inability to specifically understand context, misalignment in task schema comprehension with humans, and inadequate long-text understanding ability. Furthermore, we demonstrate that through fine-tuning, LLMs can achieve decent performance on these tasks, indicating that the failure of ICL is not an inherent flaw of LLMs, but rather a drawback of existing alignment methods that renders LLMs incapable of handling complicated specification-heavy tasks via ICL. To substantiate this, we perform dedicated instruction tuning on LLMs for these tasks and observe a notable improvement. We hope the analyses in this paper could facilitate advancements in alignment methods enabling LLMs to meet more sophisticated human demands.
Evaluating LLMs on Document-Based QA: Exact Answer Selection and Numerical Extraction using Cogtale dataset
Nov 18, 2023Document-based Question-Answering (QA) tasks are crucial for precise information retrieval. While some existing work focus on evaluating large language model's performance on retrieving and answering questions from documents, assessing the LLMs' performance on QA types that require exact answer selection from predefined options and numerical extraction is yet to be fully assessed. In this paper, we specifically focus on this underexplored context and conduct empirical analysis of LLMs (GPT-4 and GPT 3.5) on question types, including single-choice, yes-no, multiple-choice, and number extraction questions from documents. We use the Cogtale dataset for evaluation, which provide human expert-tagged responses, offering a robust benchmark for precision and factual grounding. We found that LLMs, particularly GPT-4, can precisely answer many single-choice and yes-no questions given relevant context, demonstrating their efficacy in information retrieval tasks. However, their performance diminishes when confronted with multiple-choice and number extraction formats, lowering the overall performance of the model on this task, indicating that these models may not be reliable for the task. This limits the applications of LLMs on applications demanding precise information extraction from documents, such as meta-analysis tasks. However, these findings hinge on the assumption that the retrievers furnish pertinent context necessary for accurate responses, emphasizing the need for further research on the efficacy of retriever mechanisms in enhancing question-answering performance. Our work offers a framework for ongoing dataset evaluation, ensuring that LLM applications for information retrieval and document analysis continue to meet evolving standards.