 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Product Information Extraction using ChatGPT
Jun 23, 2023
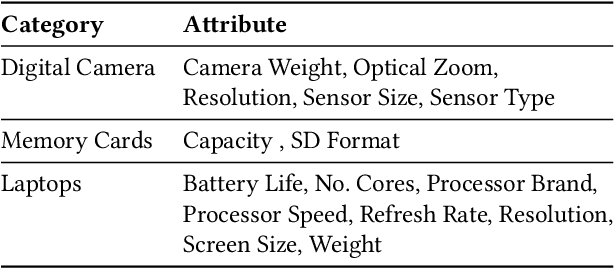
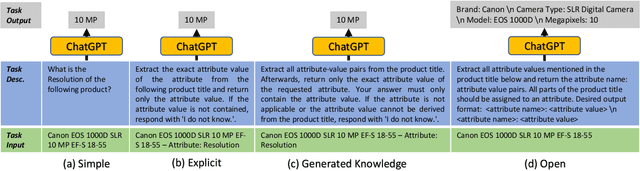
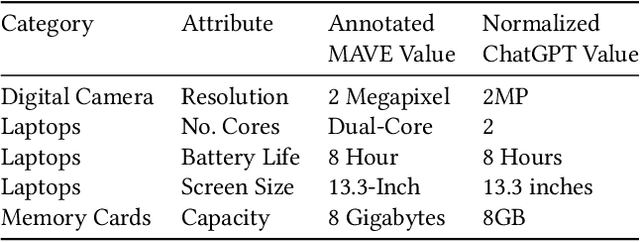
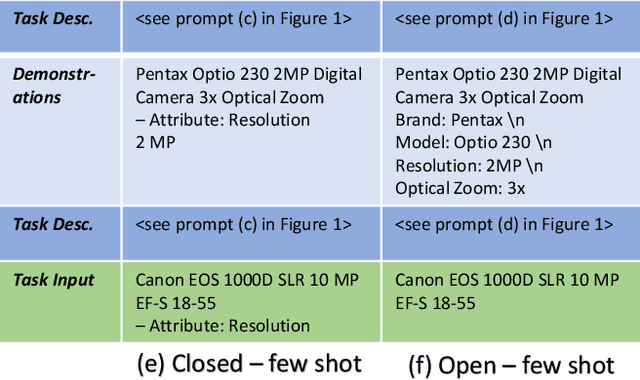
Structured product data in the form of attribute/value pairs is the foundation of many e-commerce applications such as faceted product search, product comparison, and product recommendation. Product offers often only contain textual descriptions of the product attributes in the form of titles or free text. Hence, extracting attribute/value pairs from textual product descriptions is an essential enabler for e-commerce applications. In order to excel, state-of-the-art product information extraction methods require large quantities of task-specific training data. The methods also struggle with generalizing to out-of-distribution attributes and attribute values that were not a part of the training data. Due to being pre-trained on huge amounts of text as well as due to emergent effects resulting from the model size, Large Language Models like ChatGPT have the potential to address both of these shortcomings. This paper explores the potential of ChatGPT for extracting attribute/value pairs from product descriptions. We experiment with different zero-shot and few-shot prompt designs. Our results show that ChatGPT achieves a performance similar to a pre-trained language model but requires much smaller amounts of training data and computation for fine-tuning.
GSAP-NER: A Novel Task, Corpus, and Baseline for Scholarly Entity Extraction Focused on Machine Learning Models and Datasets
Nov 16, 2023Named Entity Recognition (NER) models play a crucial role in various NLP tasks, including information extraction (IE) and text understanding. In academic writing, references to machine learning models and datasets are fundamental components of various computer science publications and necessitate accurate models for identification. Despite the advancements in NER, existing ground truth datasets do not treat fine-grained types like ML model and model architecture as separate entity types, and consequently, baseline models cannot recognize them as such. In this paper, we release a corpus of 100 manually annotated full-text scientific publications and a first baseline model for 10 entity types centered around ML models and datasets. In order to provide a nuanced understanding of how ML models and datasets are mentioned and utilized, our dataset also contains annotations for informal mentions like "our BERT-based model" or "an image CNN". You can find the ground truth dataset and code to replicate model training at https://data.gesis.org/gsap/gsap-ner.
Relation Extraction Model Based on Semantic Enhancement Mechanism
Nov 05, 2023Relational extraction is one of the basic tasks related to information extraction in the field of natural language processing, and is an important link and core task in the fields of information extraction, natural language understanding, and information retrieval. None of the existing relation extraction methods can effectively solve the problem of triple overlap. The CasAug model proposed in this paper based on the CasRel framework combined with the semantic enhancement mechanism can solve this problem to a certain extent. The CasAug model enhances the semantics of the identified possible subjects by adding a semantic enhancement mechanism, First, based on the semantic coding of possible subjects, pre-classify the possible subjects, and then combine the subject lexicon to calculate the semantic similarity to obtain the similar vocabulary of possible subjects. According to the similar vocabulary obtained, each word in different relations is calculated through the attention mechanism. For the contribution of the possible subject, finally combine the relationship pre-classification results to weight the enhanced semantics of each relationship to find the enhanced semantics of the possible subject, and send the enhanced semantics combined with the possible subject to the object and relationship extraction module. Complete the final relation triplet extraction. The experimental results show that, compared with the baseline model, the CasAug model proposed in this paper has improved the effect of relation extraction, and CasAug's ability to deal with overlapping problems and extract multiple relations is also better than the baseline model, indicating that the semantic enhancement mechanism proposed in this paper It can further reduce the judgment of redundant relations and alleviate the problem of triple overlap.
Enhancing Document Information Analysis with Multi-Task Pre-training: A Robust Approach for Information Extraction in Visually-Rich Documents
Oct 25, 2023This paper introduces a deep learning model tailored for document information analysis, emphasizing document classification, entity relation extraction, and document visual question answering. The proposed model leverages transformer-based models to encode all the information present in a document image, including textual, visual, and layout information. The model is pre-trained and subsequently fine-tuned for various document image analysis tasks. The proposed model incorporates three additional tasks during the pre-training phase, including reading order identification of different layout segments in a document image, layout segments categorization as per PubLayNet, and generation of the text sequence within a given layout segment (text block). The model also incorporates a collective pre-training scheme where losses of all the tasks under consideration, including pre-training and fine-tuning tasks with all datasets, are considered. Additional encoder and decoder blocks are added to the RoBERTa network to generate results for all tasks. The proposed model achieved impressive results across all tasks, with an accuracy of 95.87% on the RVL-CDIP dataset for document classification, F1 scores of 0.9306, 0.9804, 0.9794, and 0.8742 on the FUNSD, CORD, SROIE, and Kleister-NDA datasets respectively for entity relation extraction, and an ANLS score of 0.8468 on the DocVQA dataset for visual question answering. The results highlight the effectiveness of the proposed model in understanding and interpreting complex document layouts and content, making it a promising tool for document analysis tasks.
Image Restoration with Point Spread Function Regularization and Active Learning
Oct 31, 2023Large-scale astronomical surveys can capture numerous images of celestial objects, including galaxies and nebulae. Analysing and processing these images can reveal intricate internal structures of these objects, allowing researchers to conduct comprehensive studies on their morphology, evolution, and physical properties. However, varying noise levels and point spread functions can hamper the accuracy and efficiency of information extraction from these images. To mitigate these effects, we propose a novel image restoration algorithm that connects a deep learning-based restoration algorithm with a high-fidelity telescope simulator. During the training stage, the simulator generates images with different levels of blur and noise to train the neural network based on the quality of restored images. After training, the neural network can directly restore images obtained by the telescope, as represented by the simulator. We have tested the algorithm using real and simulated observation data and have found that it effectively enhances fine structures in blurry images and increases the quality of observation images. This algorithm can be applied to large-scale sky survey data, such as data obtained by LSST, Euclid, and CSST, to further improve the accuracy and efficiency of information extraction, promoting advances in the field of astronomical research.
Optimized measurements of chaotic dynamical systems via the information bottleneck
Nov 08, 2023Deterministic chaos permits a precise notion of a "perfect measurement" as one that, when obtained repeatedly, captures all of the information created by the system's evolution with minimal redundancy. Finding an optimal measurement is challenging, and has generally required intimate knowledge of the dynamics in the few cases where it has been done. We establish an equivalence between a perfect measurement and a variant of the information bottleneck. As a consequence, we can employ machine learning to optimize measurement processes that efficiently extract information from trajectory data. We obtain approximately optimal measurements for multiple chaotic maps and lay the necessary groundwork for efficient information extraction from general time series.
ChiMed-GPT: A Chinese Medical Large Language Model with Full Training Regime and Better Alignment to Human Preferences
Nov 23, 2023
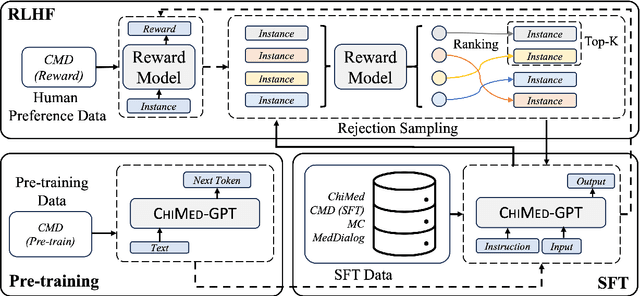

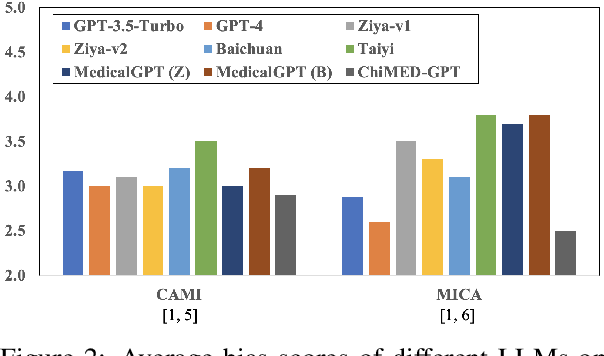
Recently, the increasing demand for superior medical services has highlighted the discrepancies in the medical infrastructure. With big data, especially texts, forming the foundation of medical services, there is an exigent need for effective natural language processing (NLP) solutions tailored to the healthcare domain. Conventional approaches leveraging pre-trained models present promising results in this domain and current large language models (LLMs) offer advanced foundation for medical text processing. However, most medical LLMs are trained only with supervised fine-tuning (SFT), even though it efficiently empowers LLMs to understand and respond to medical instructions but is ineffective in learning domain knowledge and aligning with human preference. Another engineering barrier that prevents current medical LLM from better text processing ability is their restricted context length (e.g., 2,048 tokens), making it hard for the LLMs to process long context, which is frequently required in the medical domain. In this work, we propose ChiMed-GPT, a new benchmark LLM designed explicitly for Chinese medical domain, with enlarged context length to 4,096 tokens and undergoes a comprehensive training regime with pre-training, SFT, and RLHF. Evaluations on real-world tasks including information extraction, question answering, and dialogue generation demonstrate ChiMed-GPT's superior performance over general domain LLMs. Furthermore, we analyze possible biases through prompting ChiMed-GPT to perform attitude scales regarding discrimination of patients, so as to contribute to further responsible development of LLMs in the medical domain. The code and model are released at https://github.com/synlp/ChiMed-GPT.
Schema-Driven Information Extraction from Heterogeneous Tables
May 23, 2023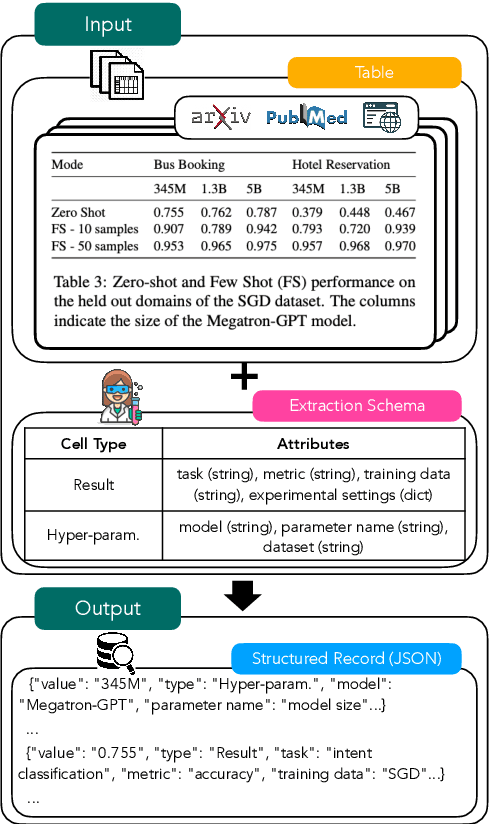
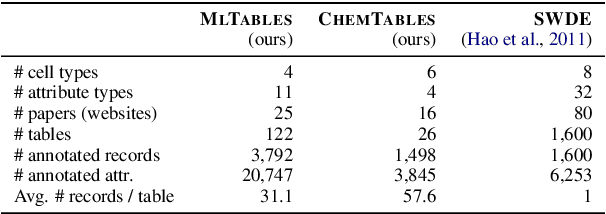
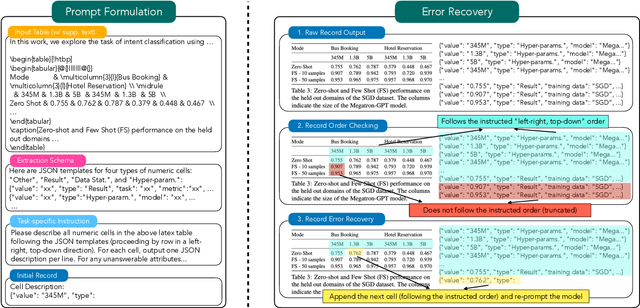
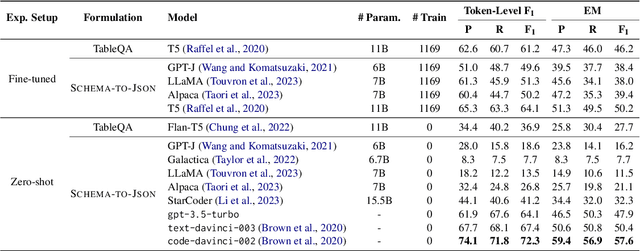
In this paper, we explore the question of whether language models (LLMs) can support cost-efficient information extraction from complex tables. We introduce schema-driven information extraction, a new task that uses LLMs to transform tabular data into structured records following a human-authored schema. To assess various LLM's capabilities on this task, we develop a benchmark composed of tables from three diverse domains: machine learning papers, chemistry tables, and webpages. Accompanying the benchmark, we present InstrucTE, a table extraction method based on instruction-tuned LLMs. This method necessitates only a human-constructed extraction schema, and incorporates an error-recovery strategy. Notably, InstrucTE demonstrates competitive performance without task-specific labels, achieving an F1 score ranging from 72.3 to 95.7. Moreover, we validate the feasibility of distilling more compact table extraction models to minimize extraction costs and reduce API reliance. This study paves the way for the future development of instruction-following models for cost-efficient table extraction.
An Attention-Based Denoising Framework for Personality Detection in Social Media Texts
Nov 16, 2023In social media networks, users produce a large amount of text content anytime, providing researchers with a valuable approach to digging for personality-related information. Personality detection based on user-generated texts is a universal method that can be used to build user portraits. The presence of noise in social media texts hinders personality detection. However, previous studies have not fully addressed this challenge. Inspired by the scanning reading technique, we propose an attention-based information extraction mechanism (AIEM) for long texts, which is applied to quickly locate valuable pieces of information, and focus more attention on the deep semantics of key pieces. Then, we provide a novel attention-based denoising framework (ADF) for personality detection tasks and achieve state-of-the-art performance on two commonly used datasets. Notably, we obtain an average accuracy improvement of 10.2% on the gold standard Twitter-Myers-Briggs Type Indicator (Twitter-MBTI) dataset. We made our code publicly available on GitHub. We shed light on how AIEM works to magnify personality-related signals.
DocTr: Document Transformer for Structured Information Extraction in Documents
Jul 16, 2023
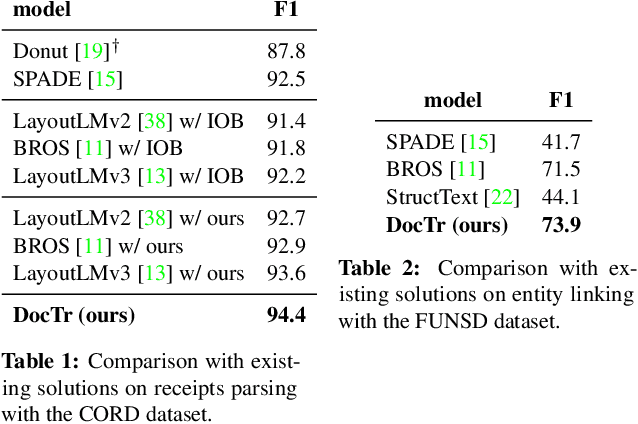
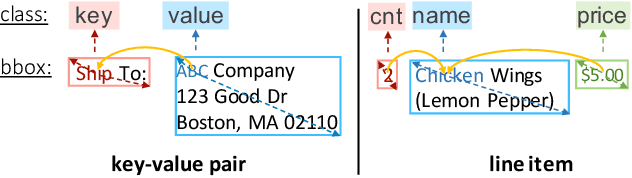
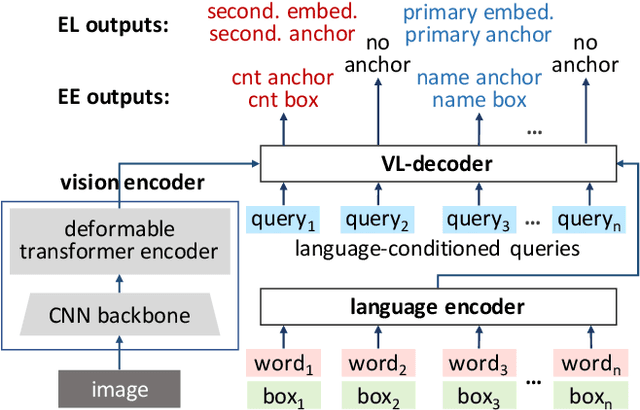
We present a new formulation for structured information extraction (SIE) from visually rich documents. It aims to address the limitations of existing IOB tagging or graph-based formulations, which are either overly reliant on the correct ordering of input text or struggle with decoding a complex graph. Instead, motivated by anchor-based object detectors in vision, we represent an entity as an anchor word and a bounding box, and represent entity linking as the association between anchor words. This is more robust to text ordering, and maintains a compact graph for entity linking. The formulation motivates us to introduce 1) a DOCument TRansformer (DocTr) that aims at detecting and associating entity bounding boxes in visually rich documents, and 2) a simple pre-training strategy that helps learn entity detection in the context of language. Evaluations on three SIE benchmarks show the effectiveness of the proposed formulation, and the overall approach outperforms existing solutions.