 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
A Semantic-Aware Multiple Access Scheme for Distributed, Dynamic 6G-Based Applications
Jan 12, 2024
The emergence of the semantic-aware paradigm presents opportunities for innovative services, especially in the context of 6G-based applications. Although significant progress has been made in semantic extraction techniques, the incorporation of semantic information into resource allocation decision-making is still in its early stages, lacking consideration of the requirements and characteristics of future systems. In response, this paper introduces a novel formulation for the problem of multiple access to the wireless spectrum. It aims to optimize the utilization-fairness trade-off, using the $\alpha$-fairness metric, while accounting for user data correlation by introducing the concepts of self- and assisted throughputs. Initially, the problem is analyzed to identify its optimal solution. Subsequently, a Semantic-Aware Multi-Agent Double and Dueling Deep Q-Learning (SAMA-D3QL) technique is proposed. This method is grounded in Model-free Multi-Agent Deep Reinforcement Learning (MADRL), enabling the user equipment to autonomously make decisions regarding wireless spectrum access based solely on their local individual observations. The efficiency of the proposed technique is evaluated through two scenarios: single-channel and multi-channel. The findings illustrate that, across a spectrum of $\alpha$ values, association matrices, and channels, SAMA-D3QL consistently outperforms alternative approaches. This establishes it as a promising candidate for facilitating the realization of future federated, dynamically evolving applications.
RESIN-EDITOR: A Schema-guided Hierarchical Event Graph Visualizer and Editor
Dec 05, 2023

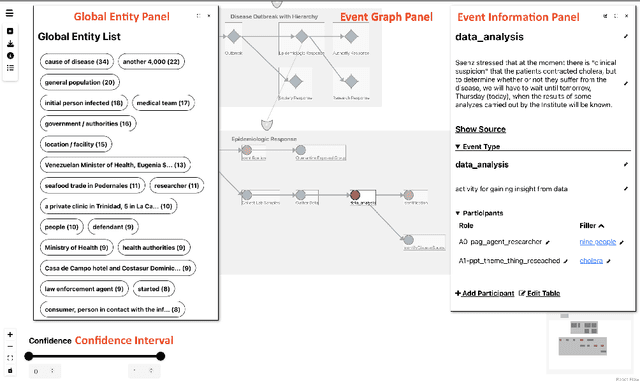
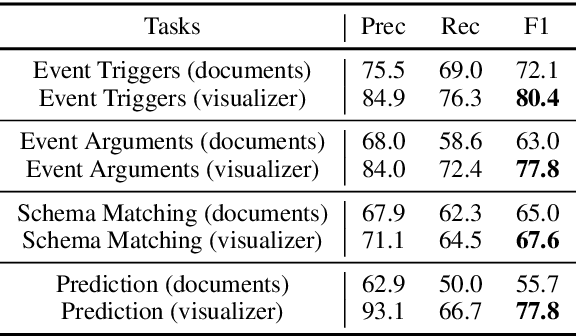
In this paper, we present RESIN-EDITOR, an interactive event graph visualizer and editor designed for analyzing complex events. Our RESIN-EDITOR system allows users to render and freely edit hierarchical event graphs extracted from multimedia and multi-document news clusters with guidance from human-curated event schemas. RESIN-EDITOR's unique features include hierarchical graph visualization, comprehensive source tracing, and interactive user editing, which is more powerful and versatile than existing Information Extraction (IE) visualization tools. In our evaluation of RESIN-EDITOR, we demonstrate ways in which our tool is effective in understanding complex events and enhancing system performance. The source code, a video demonstration, and a live website for RESIN-EDITOR have been made publicly available.
ESG Accountability Made Easy: DocQA at Your Service
Nov 30, 2023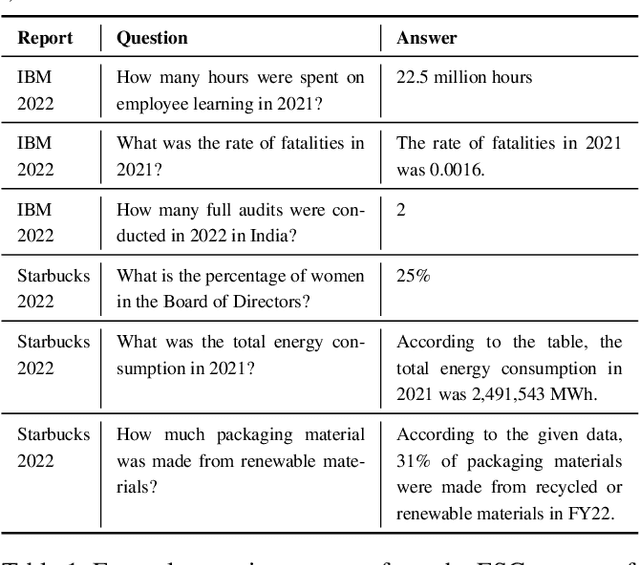
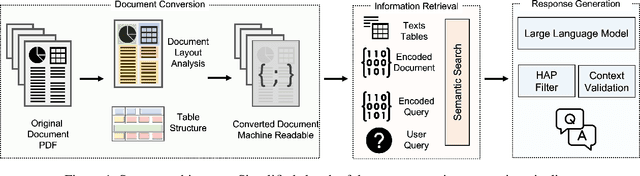
We present Deep Search DocQA. This application enables information extraction from documents via a question-answering conversational assistant. The system integrates several technologies from different AI disciplines consisting of document conversion to machine-readable format (via computer vision), finding relevant data (via natural language processing), and formulating an eloquent response (via large language models). Users can explore over 10,000 Environmental, Social, and Governance (ESG) disclosure reports from over 2000 corporations. The Deep Search platform can be accessed at: https://ds4sd.github.io.
An audio-quality-based multi-strategy approach for target speaker extraction in the MISP 2023 Challenge
Jan 08, 2024This paper describes our audio-quality-based multi-strategy approach for the audio-visual target speaker extraction (AVTSE) task in the Multi-modal Information based Speech Processing (MISP) 2023 Challenge. Specifically, our approach adopts different extraction strategies based on the audio quality, striking a balance between interference removal and speech preservation, which benifits the back-end automatic speech recognition (ASR) systems. Experiments show that our approach achieves a character error rate (CER) of 24.2% and 33.2% on the Dev and Eval set, respectively, obtaining the second place in the challenge.
ASF-YOLO: A Novel YOLO Model with Attentional Scale Sequence Fusion for Cell Instance Segmentation
Dec 11, 2023
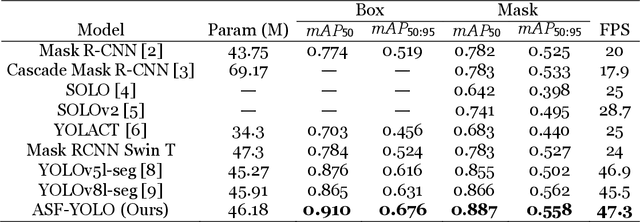
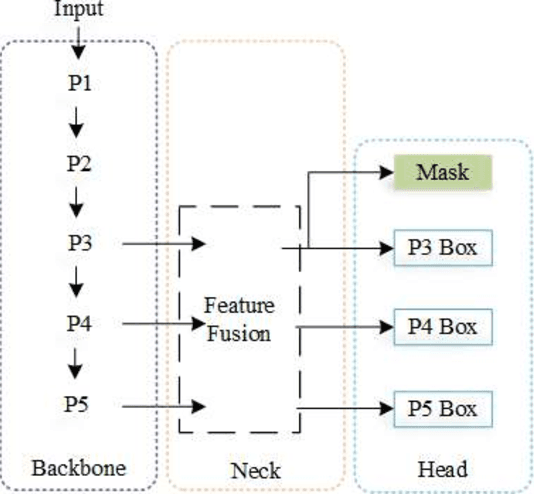
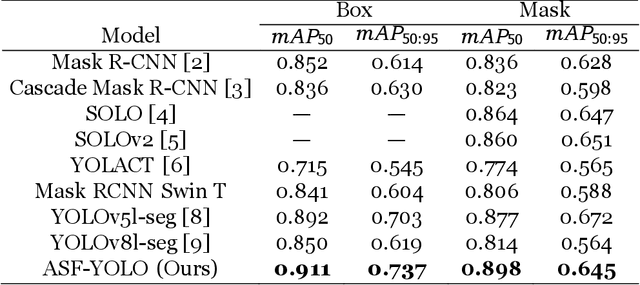
We propose a novel Attentional Scale Sequence Fusion based You Only Look Once (YOLO) framework (ASF-YOLO) which combines spatial and scale features for accurate and fast cell instance segmentation. Built on the YOLO segmentation framework, we employ the Scale Sequence Feature Fusion (SSFF) module to enhance the multi-scale information extraction capability of the network, and the Triple Feature Encoder (TPE) module to fuse feature maps of different scales to increase detailed information. We further introduce a Channel and Position Attention Mechanism (CPAM) to integrate both the SSFF and TPE modules, which focus on informative channels and spatial position-related small objects for improved detection and segmentation performance. Experimental validations on two cell datasets show remarkable segmentation accuracy and speed of the proposed ASF-YOLO model. It achieves a box mAP of 0.91, mask mAP of 0.887, and an inference speed of 47.3 FPS on the 2018 Data Science Bowl dataset, outperforming the state-of-the-art methods. The source code is available at https://github.com/mkang315/ASF-YOLO.
CrisisKAN: Knowledge-infused and Explainable Multimodal Attention Network for Crisis Event Classification
Jan 11, 2024Pervasive use of social media has become the emerging source for real-time information (like images, text, or both) to identify various events. Despite the rapid growth of image and text-based event classification, the state-of-the-art (SOTA) models find it challenging to bridge the semantic gap between features of image and text modalities due to inconsistent encoding. Also, the black-box nature of models fails to explain the model's outcomes for building trust in high-stakes situations such as disasters, pandemic. Additionally, the word limit imposed on social media posts can potentially introduce bias towards specific events. To address these issues, we proposed CrisisKAN, a novel Knowledge-infused and Explainable Multimodal Attention Network that entails images and texts in conjunction with external knowledge from Wikipedia to classify crisis events. To enrich the context-specific understanding of textual information, we integrated Wikipedia knowledge using proposed wiki extraction algorithm. Along with this, a guided cross-attention module is implemented to fill the semantic gap in integrating visual and textual data. In order to ensure reliability, we employ a model-specific approach called Gradient-weighted Class Activation Mapping (Grad-CAM) that provides a robust explanation of the predictions of the proposed model. The comprehensive experiments conducted on the CrisisMMD dataset yield in-depth analysis across various crisis-specific tasks and settings. As a result, CrisisKAN outperforms existing SOTA methodologies and provides a novel view in the domain of explainable multimodal event classification.
RadGraph2: Modeling Disease Progression in Radiology Reports via Hierarchical Information Extraction
Aug 09, 2023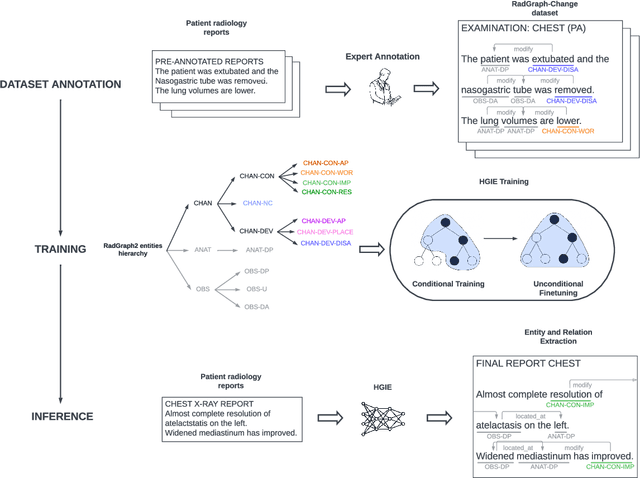
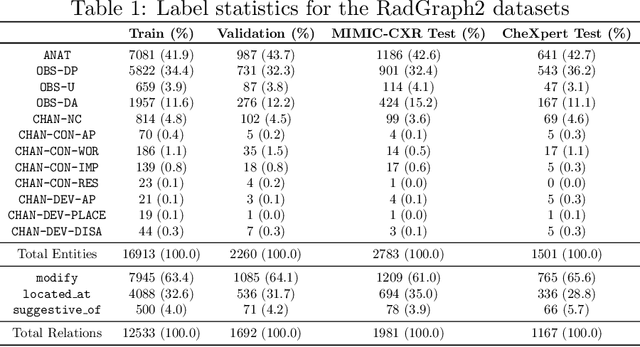
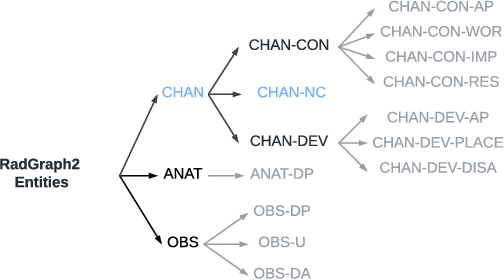
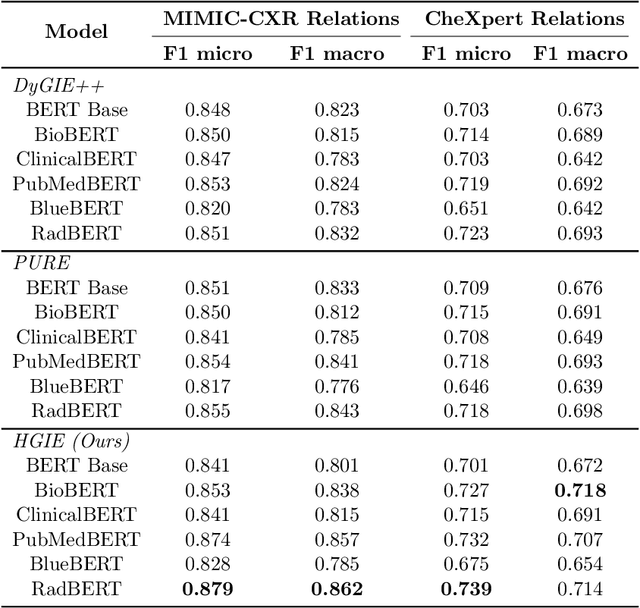
We present RadGraph2, a novel dataset for extracting information from radiology reports that focuses on capturing changes in disease state and device placement over time. We introduce a hierarchical schema that organizes entities based on their relationships and show that using this hierarchy during training improves the performance of an information extraction model. Specifically, we propose a modification to the DyGIE++ framework, resulting in our model HGIE, which outperforms previous models in entity and relation extraction tasks. We demonstrate that RadGraph2 enables models to capture a wider variety of findings and perform better at relation extraction compared to those trained on the original RadGraph dataset. Our work provides the foundation for developing automated systems that can track disease progression over time and develop information extraction models that leverage the natural hierarchy of labels in the medical domain.
Generator Born from Classifier
Dec 05, 2023In this paper, we make a bold attempt toward an ambitious task: given a pre-trained classifier, we aim to reconstruct an image generator, without relying on any data samples. From a black-box perspective, this challenge seems intractable, since it inevitably involves identifying the inverse function for a classifier, which is, by nature, an information extraction process. As such, we resort to leveraging the knowledge encapsulated within the parameters of the neural network. Grounded on the theory of Maximum-Margin Bias of gradient descent, we propose a novel learning paradigm, in which the generator is trained to ensure that the convergence conditions of the network parameters are satisfied over the generated distribution of the samples. Empirical validation from various image generation tasks substantiates the efficacy of our strategy.
DJCM: A Deep Joint Cascade Model for Singing Voice Separation and Vocal Pitch Estimation
Jan 08, 2024Singing voice separation and vocal pitch estimation are pivotal tasks in music information retrieval. Existing methods for simultaneous extraction of clean vocals and vocal pitches can be classified into two categories: pipeline methods and naive joint learning methods. However, the efficacy of these methods is limited by the following problems: On the one hand, pipeline methods train models for each task independently, resulting a mismatch between the data distributions at the training and testing time. On the other hand, naive joint learning methods simply add the losses of both tasks, possibly leading to a misalignment between the distinct objectives of each task. To solve these problems, we propose a Deep Joint Cascade Model (DJCM) for singing voice separation and vocal pitch estimation. DJCM employs a novel joint cascade model structure to concurrently train both tasks. Moreover, task-specific weights are used to align different objectives of both tasks. Experimental results show that DJCM achieves state-of-the-art performance on both tasks, with great improvements of 0.45 in terms of Signal-to-Distortion Ratio (SDR) for singing voice separation and 2.86% in terms of Overall Accuracy (OA) for vocal pitch estimation. Furthermore, extensive ablation studies validate the effectiveness of each design of our proposed model. The code of DJCM is available at https://github.com/Dream-High/DJCM .
Exploiting Polarized Material Cues for Robust Car Detection
Jan 05, 2024Car detection is an important task that serves as a crucial prerequisite for many automated driving functions. The large variations in lighting/weather conditions and vehicle densities of the scenes pose significant challenges to existing car detection algorithms to meet the highly accurate perception demand for safety, due to the unstable/limited color information, which impedes the extraction of meaningful/discriminative features of cars. In this work, we present a novel learning-based car detection method that leverages trichromatic linear polarization as an additional cue to disambiguate such challenging cases. A key observation is that polarization, characteristic of the light wave, can robustly describe intrinsic physical properties of the scene objects in various imaging conditions and is strongly linked to the nature of materials for cars (e.g., metal and glass) and their surrounding environment (e.g., soil and trees), thereby providing reliable and discriminative features for robust car detection in challenging scenes. To exploit polarization cues, we first construct a pixel-aligned RGB-Polarization car detection dataset, which we subsequently employ to train a novel multimodal fusion network. Our car detection network dynamically integrates RGB and polarization features in a request-and-complement manner and can explore the intrinsic material properties of cars across all learning samples. We extensively validate our method and demonstrate that it outperforms state-of-the-art detection methods. Experimental results show that polarization is a powerful cue for car detection.