 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
Agent-based Learning of Materials Datasets from Scientific Literature
Dec 18, 2023
Advancements in machine learning and artificial intelligence are transforming materials discovery. Yet, the availability of structured experimental data remains a bottleneck. The vast corpus of scientific literature presents a valuable and rich resource of such data. However, manual dataset creation from these resources is challenging due to issues in maintaining quality and consistency, scalability limitations, and the risk of human error and bias. Therefore, in this work, we develop a chemist AI agent, powered by large language models (LLMs), to overcome these challenges by autonomously creating structured datasets from natural language text, ranging from sentences and paragraphs to extensive scientific research articles. Our chemist AI agent, Eunomia, can plan and execute actions by leveraging the existing knowledge from decades of scientific research articles, scientists, the Internet and other tools altogether. We benchmark the performance of our approach in three different information extraction tasks with various levels of complexity, including solid-state impurity doping, metal-organic framework (MOF) chemical formula, and property relations. Our results demonstrate that our zero-shot agent, with the appropriate tools, is capable of attaining performance that is either superior or comparable to the state-of-the-art fine-tuned materials information extraction methods. This approach simplifies compilation of machine learning-ready datasets for various materials discovery applications, and significantly ease the accessibility of advanced natural language processing tools for novice users in natural language. The methodology in this work is developed as an open-source software on https://github.com/AI4ChemS/Eunomia.
Rethinking Cross-Attention for Infrared and Visible Image Fusion
Jan 22, 2024The salient information of an infrared image and the abundant texture of a visible image can be fused to obtain a comprehensive image. As can be known, the current fusion methods based on Transformer techniques for infrared and visible (IV) images have exhibited promising performance. However, the attention mechanism of the previous Transformer-based methods was prone to extract common information from source images without considering the discrepancy information, which limited fusion performance. In this paper, by reevaluating the cross-attention mechanism, we propose an alternate Transformer fusion network (ATFuse) to fuse IV images. Our ATFuse consists of one discrepancy information injection module (DIIM) and two alternate common information injection modules (ACIIM). The DIIM is designed by modifying the vanilla cross-attention mechanism, which can promote the extraction of the discrepancy information of the source images. Meanwhile, the ACIIM is devised by alternately using the vanilla cross-attention mechanism, which can fully mine common information and integrate long dependencies. Moreover, the successful training of ATFuse is facilitated by a proposed segmented pixel loss function, which provides a good trade-off for texture detail and salient structure preservation. The qualitative and quantitative results on public datasets indicate our ATFFuse is effective and superior compared to other state-of-the-art methods.
Evolutionary Multi-Objective Optimization of Large Language Model Prompts for Balancing Sentiments
Jan 18, 2024The advent of large language models (LLMs) such as ChatGPT has attracted considerable attention in various domains due to their remarkable performance and versatility. As the use of these models continues to grow, the importance of effective prompt engineering has come to the fore. Prompt optimization emerges as a crucial challenge, as it has a direct impact on model performance and the extraction of relevant information. Recently, evolutionary algorithms (EAs) have shown promise in addressing this issue, paving the way for novel optimization strategies. In this work, we propose a evolutionary multi-objective (EMO) approach specifically tailored for prompt optimization called EMO-Prompts, using sentiment analysis as a case study. We use sentiment analysis capabilities as our experimental targets. Our results demonstrate that EMO-Prompts effectively generates prompts capable of guiding the LLM to produce texts embodying two conflicting emotions simultaneously.
Consistency Guided Knowledge Retrieval and Denoising in LLMs for Zero-shot Document-level Relation Triplet Extraction
Jan 24, 2024Document-level Relation Triplet Extraction (DocRTE) is a fundamental task in information systems that aims to simultaneously extract entities with semantic relations from a document. Existing methods heavily rely on a substantial amount of fully labeled data. However, collecting and annotating data for newly emerging relations is time-consuming and labor-intensive. Recent advanced Large Language Models (LLMs), such as ChatGPT and LLaMA, exhibit impressive long-text generation capabilities, inspiring us to explore an alternative approach for obtaining auto-labeled documents with new relations. In this paper, we propose a Zero-shot Document-level Relation Triplet Extraction (ZeroDocRTE) framework, which generates labeled data by retrieval and denoising knowledge from LLMs, called GenRDK. Specifically, we propose a chain-of-retrieval prompt to guide ChatGPT to generate labeled long-text data step by step. To improve the quality of synthetic data, we propose a denoising strategy based on the consistency of cross-document knowledge. Leveraging our denoised synthetic data, we proceed to fine-tune the LLaMA2-13B-Chat for extracting document-level relation triplets. We perform experiments for both zero-shot document-level relation and triplet extraction on two public datasets. The experimental results illustrate that our GenRDK framework outperforms strong baselines.
PrIeD-KIE: Towards Privacy Preserved Document Key Information Extraction
Oct 05, 2023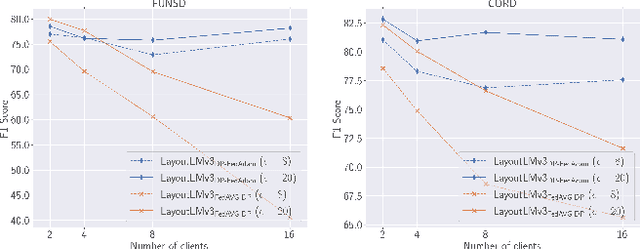

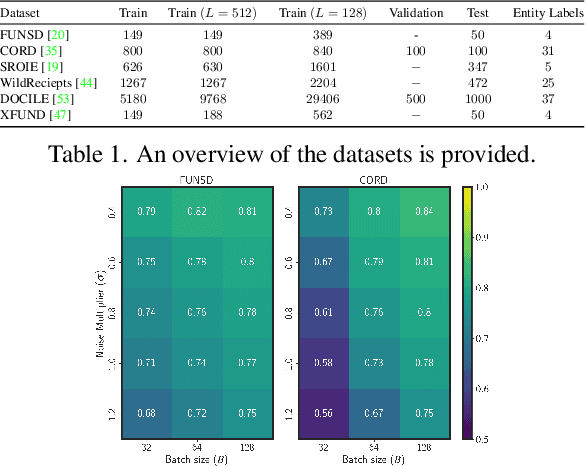
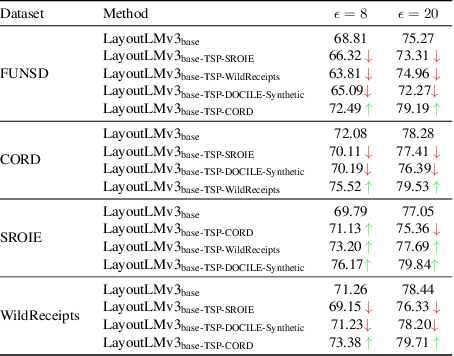
In this paper, we introduce strategies for developing private Key Information Extraction (KIE) systems by leveraging large pretrained document foundation models in conjunction with differential privacy (DP), federated learning (FL), and Differentially Private Federated Learning (DP-FL). Through extensive experimentation on six benchmark datasets (FUNSD, CORD, SROIE, WildReceipts, XFUND, and DOCILE), we demonstrate that large document foundation models can be effectively fine-tuned for the KIE task under private settings to achieve adequate performance while maintaining strong privacy guarantees. Moreover, by thoroughly analyzing the impact of various training and model parameters on model performance, we propose simple yet effective guidelines for achieving an optimal privacy-utility trade-off for the KIE task under global DP. Finally, we introduce FeAm-DP, a novel DP-FL algorithm that enables efficiently upscaling global DP from a standalone context to a multi-client federated environment. We conduct a comprehensive evaluation of the algorithm across various client and privacy settings, and demonstrate its capability to achieve comparable performance and privacy guarantees to standalone DP, even when accommodating an increasing number of participating clients. Overall, our study offers valuable insights into the development of private KIE systems, and highlights the potential of document foundation models for privacy-preserved Document AI applications. To the best of authors' knowledge, this is the first work that explores privacy preserved document KIE using document foundation models.
Edge-Enabled Real-time Railway Track Segmentation
Jan 21, 2024Accurate and rapid railway track segmentation can assist automatic train driving and is a key step in early warning to fixed or moving obstacles on the railway track. However, certain existing algorithms tailored for track segmentation often struggle to meet the requirements of real-time and efficiency on resource-constrained edge devices. Considering this challenge, we propose an edge-enabled real-time railway track segmentation algorithm, which is optimized to be suitable for edge applications by optimizing the network structure and quantizing the model after training. Initially, Ghost convolution is introduced to reduce the complexity of the backbone, thereby achieving the extraction of key information of the interested region at a lower cost. To further reduce the model complexity and calculation, a new lightweight detection head is proposed to achieve the best balance between accuracy and efficiency. Subsequently, we introduce quantization techniques to map the model's floating-point weights and activation values into lower bit-width fixed-point representations, reducing computational demands and memory footprint, ultimately accelerating the model's inference. Finally, we draw inspiration from GPU parallel programming principles to expedite the pre-processing and post-processing stages of the algorithm by doing parallel processing. The approach is evaluated with public and challenging dataset RailSem19 and tested on Jetson Nano. Experimental results demonstrate that our enhanced algorithm achieves an accuracy level of 83.3% while achieving a real-time inference rate of 25 frames per second when the input size is 480x480, thereby effectively meeting the requirements for real-time and high-efficiency operation.
Improving Information Extraction on Business Documents with Specific Pre-Training Tasks
Sep 11, 2023Transformer-based Language Models are widely used in Natural Language Processing related tasks. Thanks to their pre-training, they have been successfully adapted to Information Extraction in business documents. However, most pre-training tasks proposed in the literature for business documents are too generic and not sufficient to learn more complex structures. In this paper, we use LayoutLM, a language model pre-trained on a collection of business documents, and introduce two new pre-training tasks that further improve its capacity to extract relevant information. The first is aimed at better understanding the complex layout of documents, and the second focuses on numeric values and their order of magnitude. These tasks force the model to learn better-contextualized representations of the scanned documents. We further introduce a new post-processing algorithm to decode BIESO tags in Information Extraction that performs better with complex entities. Our method significantly improves extraction performance on both public (from 93.88 to 95.50 F1 score) and private (from 84.35 to 84.84 F1 score) datasets composed of expense receipts, invoices, and purchase orders.
* Conference: Document Analysis Systems. DAS 2022
Progressive Frequency-Aware Network for Laparoscopic Image Desmoking
Dec 19, 2023Laparoscopic surgery offers minimally invasive procedures with better patient outcomes, but smoke presence challenges visibility and safety. Existing learning-based methods demand large datasets and high computational resources. We propose the Progressive Frequency-Aware Network (PFAN), a lightweight GAN framework for laparoscopic image desmoking, combining the strengths of CNN and Transformer for progressive information extraction in the frequency domain. PFAN features CNN-based Multi-scale Bottleneck-Inverting (MBI) Blocks for capturing local high-frequency information and Locally-Enhanced Axial Attention Transformers (LAT) for efficiently handling global low-frequency information. PFAN efficiently desmokes laparoscopic images even with limited training data. Our method outperforms state-of-the-art approaches in PSNR, SSIM, CIEDE2000, and visual quality on the Cholec80 dataset and retains only 629K parameters. Our code and models are made publicly available at: https://github.com/jlzcode/PFAN.
Leveraging AI-derived Data for Carbon Accounting: Information Extraction from Alternative Sources
Nov 26, 2023Carbon accounting is a fundamental building block in our global path to emissions reduction and decarbonization, yet many challenges exist in achieving reliable and trusted carbon accounting measures. We motivate that carbon accounting not only needs to be more data-driven, but also more methodologically sound. We discuss the need for alternative, more diverse data sources that can play a significant role on our path to trusted carbon accounting procedures and elaborate on not only why, but how Artificial Intelligence (AI) in general and Natural Language Processing (NLP) in particular can unlock reasonable access to a treasure trove of alternative data sets in light of the recent advances in the field that better enable the utilization of unstructured data in this process. We present a case study of the recent developments on real-world data via an NLP-powered analysis using OpenAI's GPT API on financial and shipping data. We conclude the paper with a discussion on how these methods and approaches can be integrated into a broader framework for AI-enabled integrative carbon accounting.
Learning Disentangled Speech Representations with Contrastive Learning and Time-Invariant Retrieval
Jan 18, 2024Voice conversion refers to transferring speaker identity with well-preserved content. Better disentanglement of speech representations leads to better voice conversion. Recent studies have found that phonetic information from input audio has the potential ability to well represent content. Besides, the speaker-style modeling with pre-trained models making the process more complex. To tackle these issues, we introduce a new method named "CTVC" which utilizes disentangled speech representations with contrastive learning and time-invariant retrieval. Specifically, a similarity-based compression module is used to facilitate a more intimate connection between the frame-level hidden features and linguistic information at phoneme-level. Additionally, a time-invariant retrieval is proposed for timbre extraction based on multiple segmentations and mutual information. Experimental results demonstrate that "CTVC" outperforms previous studies and improves the sound quality and similarity of converted results.